AI Agent评估工程是关键,LLM-as-a-Judge实现自动化评测,驱动模型自我完善。
原文标题:评估工程正成为下一轮 Agent 演进的重点
原文作者:阿里云开发者
冷月清谈:
LLM-as-a-Judge通过让大模型扮演裁判角色,学习人类主观偏好,实现大规模、低成本的数据标注、实时验证及模型优化反馈。实践中,奖励模型(如ModelScope的RM-Gallery)和基于云监控2.0的SQL/SPL大模型调用都展示了自动化评估能力。阿里云CIO蒋林泉提出的RIDE方法论中,Execute环节也强调了当前大模型度量和评测缺乏标准范式的挑战与机遇。最终,这些评估实践有助于构建数据采集-自动化评估-数据集构建-后训练的数据飞轮,驱动Agent持续改进与产品竞争力提升。
怜星夜思:
2、评估工程从规则匹配到语义匹配,再到现在的模型自动化评估,看起来人类在评估中的直接参与越来越少。未来是不是真的能彻底摆脱人工评估?哪些环节人类的“品味”和经验还是不可替代的?
3、文章里提的“数据飞轮”概念很棒,通过自动化评估构建数据集再进行训练。但这个飞轮要真正跑起来,需要哪些基础设施和团队协作才能实现?小型团队有没有可能玩得转?
原文内容

一、导读
在传统软件工程中,测试是保障质量与稳定性的核心环节。它验证系统的确定性逻辑:基于预设的规则,验证输入的可靠性。而 AI 系统的核心能力不再是执行预设的规则,而是基于概率模型进行推理和生成。结果的不确定性、语义的多义性、以及上下文的敏感性,使得原有测试方法难以刻画模型行为。这一转变,促使评估工程成为下一轮 Agent 演进的重点。
评估工程,贯穿整个 AI 生命周期,它的目标是定义、采集并量化 Agent 的表现质量,涵盖输出正确度、可解释性、偏好一致性与安全性。从架构角度看,评估工程是 AI 工程体系中最靠近“人类判断”的一环,既涉及指标体系的定义,又包含算法层的建模与反馈机制。随着 SFT(监督微调)、RLHF(基于人类反馈的强化学习)、LLM-as-a-Judge(模型裁决评估)以及 Reward Model(奖励模型)等技术或范式逐渐成熟,评估工程正从经验驱动走向体系化、工程化和自动化。
阿里云 CIO 蒋林泉曾分享过:在落地大模型技术过程中总结过一套方法论,叫 RIDE,即 Reorganize(重组组织与生产关系)、Identify(识别业务痛点与 AI 机会)、Define(定义指标与运营体系)、和 Execute(推进数据建设与工程落地)。其中,Execute 中提到了评估工程重要性的核心原因,即这一轮大模型最关键的区别在于:度量数据和评测均没有标准的范式。这就意味着,这既是提升产品力的难点,同时也是产品竞争力的护城河。
在 AI 领域里经常提到一个词叫“品味”,这里讲的“品味”,其实就是如何设计评估工程,即对 Agent 的输出进行评价。如果没有评估,就很难理解不同的模型会如何影响我们的用例。
二、从确定性到不确定性
在传统的软件工程中,测试覆盖率和准确率是评价质量的指标。传统软件工程的测试体系建立在三个假设上:
-
系统状态是可预测且有限的。
-
故障是离散的、可复现的。
-
测试集可以覆盖主要路径,从而保证回归稳定性。
这些假设使测试活动可以高度自动化:编写单元测试、执行、检测结果是否匹配。测试的目标是消灭 bug。在这种逻辑下,质量的度量接近“零缺陷工程”,并且保障可重复性与向前兼容性。
AI 系统的不确定性,源自三个方面:
-
模型架构的不确定性:Transformer 等生成模型通过概率分布预测下一个 token,本身就是多解问题的生成器。
-
数据驱动的不完全性:模型的世界认知取决于训练数据的分布,一旦语境超出训练覆盖范围,输出结果就会失去稳定性。
-
交互环境的开放性:用户输入多样、上下文动态变化,任务目标模糊或多义。
这使得 AI 系统的故障模式不同于 bug。它是一种漂移,表现为输出分布的偏移、语义理解的失准、或行为策略的不一致。因此,对 Agent 而言,评估不再仅仅是部署前的一个阶段,而是由后训练、持续监控、自动化评估与治理,所构成的评估工程。
三、用魔法打败魔法
评估工程经历了从规则匹配、语义匹配、模型评估的演进过程,每个阶段都是对“什么是更好的答案”这一核心问题的重新定义。
阶段一:规则匹配
在自然语言处理早期,评估主要基于规则化的重合度指标。典型代表是机器翻译的 BLEU(Bilingual Evaluation Understudy) 和用于文本摘要的 ROUGE(Recall-Oriented Understudy for Gisting Evaluation)。它们的核心思路是通过比较模型输出与人工参考答案的重合程度来计分,从而度量生成结果的“接近度”。
但这种方法对于评估需要捕捉语义、风格、语气和创造力等细微差别的现代生成式 AI 模型来说,存在根本性的不足。一个模型生成的文本可能在措辞上与参考答案完全不同,但在语义上却更准确、更具洞察力。BLEU、ROUGE无法识别这种情况,甚至可能给予低分。
阶段二:语义匹配
当模型具备语义理解能力后,评估进入语义层次。BERTScore(基于 BERT 表示的文本生成质量评估指标) 和 COMET(跨语言优化的翻译质量评估指标)等方法引入了向量空间语义匹配。通过计算生成文本与参考答案在嵌入空间中的余弦相似度,评估输出的语义接近度。这使得模型可以被奖励为生成不同但合理的答案。
例如:
参考答案:“猫坐在垫子上。”
模型输出:“垫子上有一只猫。”
在语义匹配指标下,这种输出会得到高分,而不是被视为错误。但这一阶段的评估仍有两个局限:
-
仍需参考答案:难以适用于开放式的生成或对话;
-
无法表达偏好:无法判断哪种答案更自然、更符合用户习惯。
语义指标的价值在于:它让我们开始从答案正确性转向语义合理性,但仍然没触及行为一致性这一核心问题。
阶段三:模型自动化评估
随着大模型迈过拐点,评估方法进入第三阶段,LLM-as-a-Judge,其核心思想是让模型学习人类的主观偏好,即利用一个功能强大的大型语言模型(通常是前沿模型)来扮演裁判的角色,对另一个 AI 模型(或应用)的输出进行评分、排序或选择,即用魔法打败魔法。
-
工作机制:向裁判 LLM 提供一个精心设计的提示词。这个提示通常包含:
-
被评估模型的输出。
-
产生该输出的原始输入或问题。
-
一套明确的评估标准或评分指南,用自然语言描述,例如“请评估以下回答的帮助性、事实准确性和礼貌程度”。裁判 LLM 随后会根据这些信息,生成一个分数、一个判断(如回答 A 优于回答 B)或一段详细的评估反馈。
-
核心应用场景:
-
数据标注:大规模、低成本地为数据集进行标注,合成检测数据,用于监督式微调或创建新的评估基准。
-
实时验证:在应用中充当护栏,在输出返回给最终用户之前,实时检查其是否存在幻觉、违反政策或包含有害内容。
-
为模型优化提供反馈:生成详细、可解释的反馈,指导模型的迭代改进。例如,其中一个 LLM 根据一套伦理原则来评估和修正另一个 LLM 的输出,从而实现模型的自我完善。
从一个更深层次的视角来看,LLM-as-a-Judge 范式能够将高级的、主观的人类偏好(通过自然语言评分指南表达)编译成一个可扩展、自动化且可重复执行的评估函数。这个过程将原本属于定性评估的艺术,转变为一门可以系统化实施的工程学科。其逻辑在于,该范式接收了抽象的、定性的输入(如评估回答的创造力),并将其转化为结构化的、定量的输出(如一个1到5的分数)。这种转化过程使得那些以往只能依赖昂贵且缓慢的人工评估才能衡量的复杂、主观标准,现在可以通过工程化的方式进行系统性评估。
无论是面向 SFT(监督微调),还是 RLHF(基于人类反馈的强化学习),LLM-as-a-Judge 都是一个更高效的对齐人类偏好的评估方案。
四、模型自动化评估的实践-奖励模型
在 RLHF 场景中,奖励模型(Reward Model, RM)已经成为一种主流自动化评估工具的重要构成,并且出现了专门评估奖励模型的基准,如海外的 RewardBench[1] 和国内高校联合发布的 RM Bench[2],用来测不同 RM 的效果、比较谁能更好地预测人类偏好。下方将介绍 ModelScope 近期开源的奖励模型——RM-Gallery,项目地址:
https://github.com/modelscope/RM-Gallery/
RM-Gallery 是一个集奖励模型训练、构建与应用于一体的一站式平台,支持任务级与原子级奖励模型的高吞吐、容错实现,助力奖励模型全流程落地。

RM-Gallery 提供基于 RL 的推理奖励模型训练框架,兼容主流框架(如 Verl),并提供集成 RM-Gallery 的示例。在 RM Bench 上,经过80步训练,准确率由基线模型(Qwen2.5-14B)的约55.8%提升至约62.5%。

RM-Gallery 的几个关键特性包括:
-
支持任务级别和更细粒度的原子级奖励模型。
-
提供标准化接口、丰富内置模型库(例如数学正确性、代码质量、对齐、安全等)供直接使用或者定制。
-
支持训练流程(使用偏好数据、对比损失、RL 机制等)来提升奖励模型性能。
-
支持将这些奖励模型用于多个应用场景:比如“Best-of-N 选择”“数据修正”“后训练 / RLHF”场景。
所以,从功能来看,它是基于奖励模型,即用于衡量大模型输出好坏、优先级、偏好一致性等,打造成一个可训练、可复用、可部署的用于评估工程的基础设施平台。
五、模型自动化评估的实践-云监控2.0
除了奖励模型,也有越来越多的企业选择在数据层(SQL 或 SPL 环境)中直接调用大模型来执行自动化评估。这种方式最大的优势在于能把模型/Agent 的自动化评估纳入了传统数据处理流水线,使得评估与数据分析、A/B 测试、观测天然融合,形成数据采集->自动化评估(包括数据预处理、评估和数据后处理)->构建新的数据集->后训练的数据飞轮。
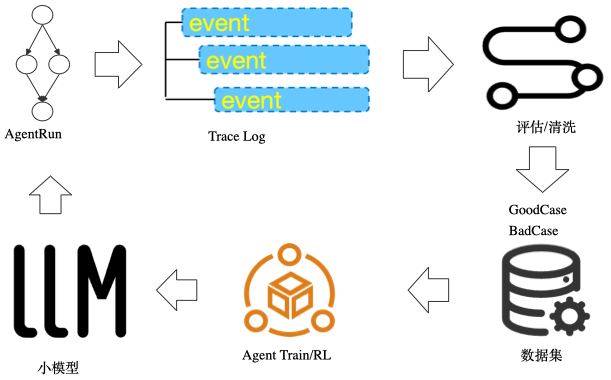
但这种方案对端到端的丝滑体验提出了较高的要求,同时对数据采集的稳定性、可追溯性和成本可控也有一定要求。孤岛式的协作流程会降低团队积极性,影响运转效率,对反馈质量也无益处。所谓飞轮,最重要的是能形成低损耗、自校正的循环系统。
以下我们基于阿里云云监控2.0提供的一站式评估能力,并将评估过程拆解为数据采集、数据预处理、评估执行、数据后处理四个阶段,来分享具体的实施过程。
需要强调的是,不同于奖励模型,云监控2.0提供的 LLM-as-a-Judge,是在 SQL/SPL 中调用大模型实现的,具有不需要训练评估模型、可按任务随时修改评估规则、可原生嵌入企业数据的特点,适合轻量场景与快速验证。
一站式的数据采集
评估的可靠性始于输入数据的质量。大模型的评判结果极度依赖上下文,因此采集阶段的任务不仅是收集样本,而是要保证模型在评估时能看到正确、完整且有代表性的输入输出对。一旦输入数据不一致、上下文缺失或标识混乱,后续所有指标都将失真。
云监控2.0提供自研无侵入探针,兼容 Opentelementry 协议,以 OpenTelemetry Python Agent 为底座,增强大模型领域语义规范与数据采集,提供多种性能诊断数据,全方位自监控保障稳定高可用,开源采集器 LoongCollector 可实时采集增量日志到服务端,性能强,无缝把大模型推理日志进行集中采集和存储,解决数据孤岛的问题。
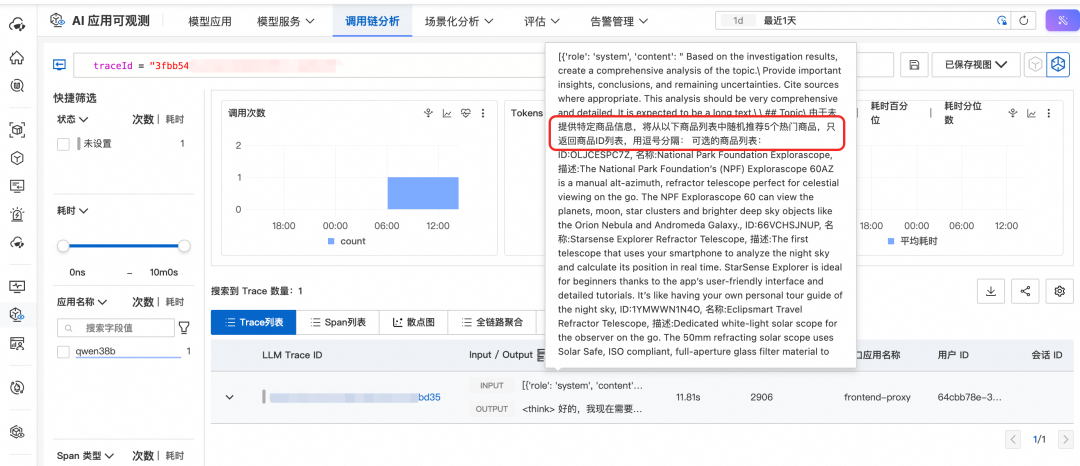
因此,第一步我们需要将 Agent 接入云监控2.0,创建 Project 和对应的 Logstore,采集 Agent 的运行数据 TraceLog,用于评估的数据输入。以下我们为一个电商领域的智能找挑应用创建一个 Project 和 Logstore。

采集智能找挑应用的用户和模型之间的输入和输出数据。
在线数据预处理的能力
大模型的输出受 Prompt 极大影响。如果评估 Prompt 拼接不当,哪怕内容相同,也可能导致评估结果偏差数倍。预处理阶段的任务,是在 SQL/SPL 环境中建立一个稳定、模板化的 Prompt 构建机制,确保不同样本、不同任务类型之间的输入一致性。
云监控2.0基于 SQL/SPL 强大的数据处理能力,完成提取/去重/关联登陆等操作。提取操作可以只评估关键的信息,把重复的信息进行压缩,减少 LLM Judger 的负载、关联把相关数据合并在一起进行评估。此外,云监控2.0内置多种常见的评估模版,覆盖 Rag 评估、Agent 评估、通用评估、工具评估、语义评估等。以 Rag 评估为例,提供了 Rag 召回的语料有重复、语料多样性、语料是否和用户问题相关、是否和答案相关等模板。
因此,创建完源 Project 和 Logstore 后,我们开始选取评估模板,在过滤语句中,选择哪些数据做评估,进行任务创建。

下方创建了3个评估任务,分别是:
-
语义评估 semantic_extraction;
-
通用评估 幻觉 hallucination;
-
通用评估 准确性 accuracy;

评估任务创建成功后,会在目标 SLS Project 中创建出定时 SQL 任务,周期性查询日志库中的数据,根据评估任务中内置的评估模板计算查询到的日志数据的评估分数。
内置的评估模板默认使用 Qwen-max 作为裁判模型,用户也可以采用自定义评估,支持接入自有模型作为裁判模型。以下 SQL 是基于自定义评估模板,对数据进行总结。评估指令可以在 SQL 中指定。需要配置待处理的数据、评估模板、采用的裁判模型等。
(* and id: 999and type: dca)| set
session velox_use_io_executor = true;
with t1 as(
select
__time__,
"sentence1" as trans, -- 此处是待处理数据
'{{query}}' as targets, --此处是评估模板中的占位符
'{"model":"<QWEN_MODEL>","input":{"messages":[{"role":"system","content":"<SYSTEM_PROMPT>"},{"role":"user","content":"<USER_PROMPT>"}]}}' as body_template, --此处为访问百炼的body模板
cast('请用一句话对以下内容进行总结:{{query}}' as varchar) as eval_prompt --此处为评估模板,包含了指令信息和占位符
FROM log
),
t1_1 as(
select
__time__,
body_template,
eval_prompt,
replace(eval_prompt, targets, trans) as eval_content,
trans
FROM t1
),
t2 as(
select
__time__,
body_template,
eval_content,
trans
FROM t1_1
),
t3 as(
select
__time__,
trans as oldeval,
body_template,
replace(
replace(
replace(
replace(
replace(
replace(replace(eval_content, chr(92), '\\'), '"', '\"'),
chr(8),
'\b'
),
chr(12),
'\f'
),
chr(10),
'\n'
),
chr(13),
'\r'
),
chr(9),
'\t'
) as eval,
trans
FROM t2
),
t4 as(
select
__time__,
replace(
replace(
replace(body_template, '<QWEN_MODEL>', 'qwen-turbo'),
'<SYSTEM_PROMPT>',
'You are a helpful assistant.'
),
'<USER_PROMPT>',
eval
) as body,
oldeval,
trans
FROM t3
),
t5 as(
select
__time__,
http_call(
'https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation',
'POST',
'{ "Content-Type":"application/json"}',
'',
body,
60 * 1000
) as response,
body,
oldeval,
trans
FROM t4
),
t6 as (
select
__time__,
oldeval,
body,
response.code,
response.header,
response.body body_res,
response.error_msg as error,
trans
FROM t5
)
select
__time__,
trans as "原文",
replace(
replace(
json_extract_scalar(body_res, '$.output.text'),
'```json',
' '
),
'```',
' '
) as "总结信息",
error,
json_extract_scalar(body_res, '$.usage.total_tokens') as "消耗的token"
FROM t6
实时评估能力
云监控2.0在 SQL/SPL 中提供评估算子,和预处理计算无缝衔接。其中,评估算子无缝集成 Qwen 等最先进的大模型,提升 LLM Judger 的评估能力。下方是通用评估模板中的准确性 accuracy,我们可以看到 Qwen 大模型对每个评估任务给出了评分。

后处理统计
评估的终点不是得分,而是决策依据。大模型输出可能带解释文本、情感分析或维度化分数,需要被结构化、聚合、再加工。如果缺少后处理,评估数据只是噪声;有了后处理,它才会成为可监控的系统指标。
云监控2.0基于 SPL/SQL 对评估结果进行二次加工统计。例如进行 A/B 测试,对比不同 Prompt 模板的效果、对比不同模型的效果。
此外,对于非评分类的语义搜索,支持对评估对象和评估结果进行精准筛选。并通过语义聚类功能,对评估结果进行聚类分析,发现高频的 Pattern,以及离群点。效果如下。

经过以上步骤,可以搭建起一个端到端的自动化评估系统,导出偏好数据集,再导入相关的后训练平台,就能开启数据采集->自动化评估(包括数据预处理、评估和数据后处理)->构建新的数据集->后训练的数据飞轮。
有关 AI 评估更详细的内容,可下载《AI 原生应用架构白皮书》,阅读第9章 AI 评估。
白皮书下载地址:https://developer.aliyun.com/ebook/8479
[1]https://allenai.org/blog/rewardbench-the-first-benchmark-leaderboard-for-reward-models-used-in-rlhf-1d4d7d04a90b
[2]https://arxiv.org/html/2410.16184v1