范浩强团队RT-VLA:单张4090实现VLA大模型30fps,让机器人实时控制触手可及。
原文标题:单张4090跑到30fps,范浩强团队让VLA实时跑起来了
原文作者:机器之心
冷月清谈:
为实现这一目标,研究团队深入分析了Pi0模型的结构与计算流程,通过融合、并行优化等底层技术,将推理时间从100多毫秒大幅缩减至27毫秒(双视角),显著优于传统自动优化方案。所有优化后的代码已在GitHub开源,方便开发者“开箱即用”。
这项实时运行能力有效解决了机器人VLA大模型在实时控制中面临的延迟痛点。例如,机器人能够以不足200毫秒的端到端反应时间成功抓取自由下落的笔,表现堪比人类。
在此基础上,研究者设计了一套基于GPU的机器人控制框架,赋予机器人三种不同速度的“反应神经”:超快反应(480Hz,力传感器)、视觉反应(30Hz,摄像头)和智能思考(<1Hz,语言规划)。该框架最高有望实现480Hz的机器人控制信号生成。展望未来,该研究为VLA模型在边缘计算算力下追求更快“眼睛”、更大“大脑”和更极限“反应”速度的可能性打开了大门,引领机器人实现“又聪明又快”的全面具身智能。
怜星夜思:
2、这个“超快反应”的480Hz控制框架听起来很厉害,但如果机器人反应速度这么快,会不会在人机协作或者复杂环境中带来一些潜在的安全隐患?比如突然的快速动作,人类来不及预判或规避,这个问题要怎么平衡好效率和安全呢?
3、文章提到未来可能把VLA模型从3B扩展到7B甚至更大的模型。模型大了,虽然“聪明”了,但保持实时性肯定更难吧?除了文中说的那些优化,大家觉得为了在更大模型上实现实时高性能,还会遇到哪些新的技术挑战,或者需要引入哪些新的优化思路呢?
原文内容

VLA(Visual-Language-Action)大模型到底能跑多快?在这篇 RT-VLA(Real-time VLA)论文中,来自 Dexmal 原力灵机(由范浩强等人联合创立的具身智能公司)的研究者公布了一个反直觉的发现:它可以非常快!
具体而言,对于常用的 Pi0 级别的模型(30 亿参数),在单张消费级显卡 RTX 4090 上最快可以跑到 30fps。这和大家对于 VLA 模型动辄要几十甚至上百毫秒的刻板印象形成鲜明对比。
为实现这点,研究者深入分析 Pi0 的模型结构,通过一系列优化把用时从开始的 100+ ms 进行数倍缩减(针对双视角,甚至已经达到 27ms),显著强于 openpi 里采用的基于 jax 的自动优化的结果。
此外,研究者基于现有结果探讨了未来的“实时”运行的 VLA 结构,设计出一个有潜力最高实现 480Hz 闭环控制的算法框架。目前,优化后的代码已在 GitHub 开源,全部实现均打包为一个只依赖于 torch 和 triton 的单一文件,大家可在自己的项目里 “开箱即用”。这是 Dexmal 原力灵机继 之后的又一开源代码工作。

-
论文名称:Running VLAs at Real-time Speed
-
论文链接:https://arxiv.org/abs/2510.26742
-
GitHub:https://github.com/Dexmal/realtime-vla
解决什么痛点?
现在机器人 VLA 大模型动辄几十亿参数,虽然有不错的泛化能力,但是延迟问题总是绕不过。即使是在高端推理显卡上,高达百毫秒级别的推理时间让机器人的实时控制困难重重,就像一个人看见东西后要愣一下才做出动作。
如果我们能够把模型运行到和相机一样快的频率(25fps、30fps 甚至 50fps),那么就可以在完全不丢帧的情况下处理视觉信息,让 VLA 模型的实时运行成为可能。
如何实现?
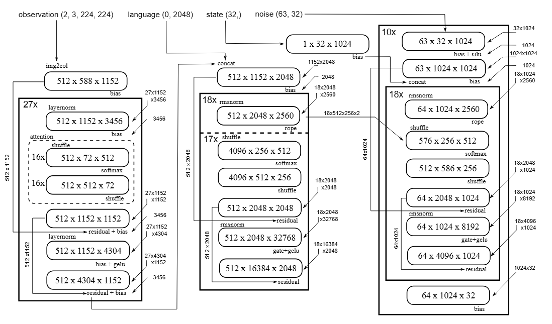
Pi0 模型计算流程图示,它主要包括 1 个视觉编码器,1 个编码器和 1 个解码器;所有这些又可进一步分解为一系列的矩阵乘法和标量运算。
对于 Transformer 这类模型,当它进行单次推理(比如只处理一个问题或一张图片)时,其内部计算过程实际上是由一长串零碎的 “矩阵计算小任务” 组成;而像 Pi0 这种采用 “流匹配” 技术的模型,需要反复迭代十次才能得出最终结果,每一次迭代本身就包含几十层计算。这样算下来,整个推理过程涉及数百层、上千个操作。任务如此零碎,让计算优化变得异常困难。
本文研究者通过深入分析模型推理过程中的计算问题,融合和并行优化每一个计算步骤,清除了推理方面的大部分障碍,再加上其他方面的优化,最终把整个 VLA 模型跑进了所需的时间之内。
这就像给了 VLA 大模型一份 “高性能 AI 大脑调校指南” ;它通过一系列深入的底层优化,把笨重的 AI 大模型变成能跑实时任务的 “闪电侠”,并在此基础上,构想出一个能同时具备条件反射、视觉反馈和智能思考的下一代机器人控制系统。
效果展示
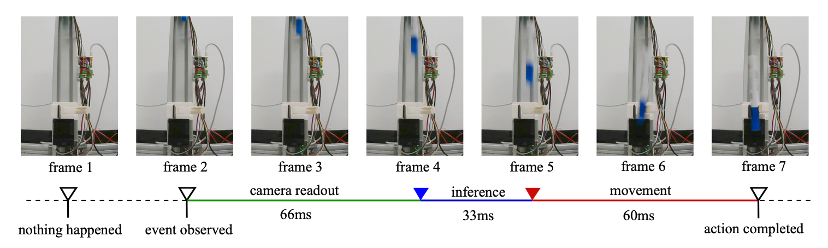
上图所示的任务是抓取一支自由下落的笔。 这个任务对反应时间的要求极为苛刻。机器人观察到笔开始下落后,必须在极短的时间内做出反应并在正确的时间启动抓取动作,快一点或者慢一点都会导致任务失败。
最终呈现的效果是 从 “看到笔” 到 “执行抓取” 的端到端总反应时间被缩短到 200 毫秒以内,这大概对应到一个 30 cm 左右的最短下落距离。而人类在这个任务上的一般表现也不过如此。
下一步规划
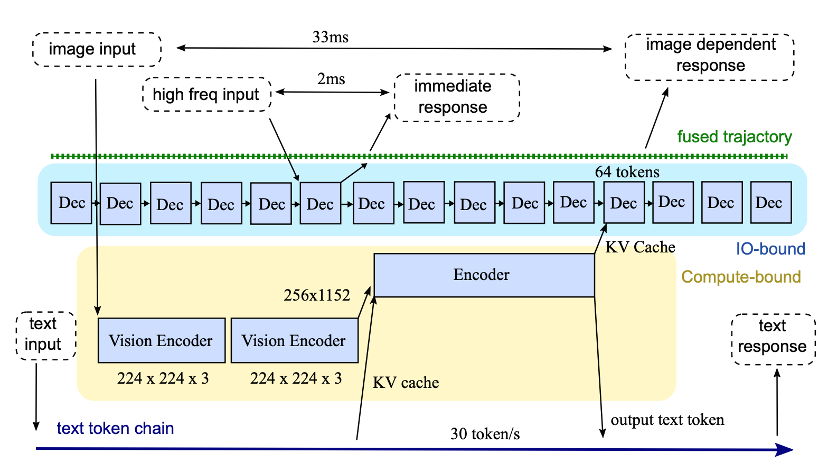
基于上述取得的成果,研究者设计了一套完整的、围绕 GPU 打造的机器人控制框架,它能驱动 VLA 大模型,像 “直播” 一样对机器人进行流式的实时控制,让机器人拥有 3 种不同速度的 “反应神经”:
-
超快反应(480Hz):处理来自力传感器等高速信号。就像你的手一碰到烫的东西会瞬间缩回,不需要经过大脑思考。这部分由模型的 “解码器” 负责,能每秒生成 480 次控制指令。
-
视觉反应(30Hz):处理来自摄像头的画面。就像你看着球飞过来,用眼睛跟踪并判断落点。这部分由模型的 “编码器” 负责。
-
智能思考(<1Hz):处理语言理解和任务规划。就像你在执行任务时,还能分心听一下队友的指令或者自己琢磨一下策略。这部分速度最慢,但赋予了机器人更高的智能。
通过分析与实验,这个框架下一步规划最高能以 480Hz 的频率生成机器人控制信号;这个速度,已经摸到了实现基于力反馈进行控制的门槛。
未来展望
机器人有没有可能达到 “又聪明又快” 的效果?这篇文章只是一个起点。针对未来不断增加中的边缘计算算力,研究者展望了更进一步的可能性:
-
“眼睛” 最快能有多快?从 30fps 到 60fps,甚至 120fps,是否有更多的任务变得可行?
-
“大脑” 最大能有多大?在实时性约束下,我们是否可以从 3B 模型,走向 7B,13B 模型,甚至更大模型?
-
“反应” 速度的极限在哪里?在 VLA 框架下,我们是否还可以建立亚毫秒、甚至微秒级的反馈回路?
从这篇文章出发,一个能够参与实时控制 VLA 的世界的大门正在被打开。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com