Cursor 2.0 发布,自研Composer模型与多智能体并行,代码开发提速4倍,开启AI编码新范式。
原文标题:Cursor 2.0发布:自研代码模型 Composer 上线,8 个代理并行,速度提升 4 倍
原文作者:AI前线
冷月清谈:
Cursor 2.0还提供多代理界面,最多支持8个代理并行在隔离工作区中运行。它在底层代码智能栈做了大量优化,如LSP加速诊断与导航,尤其针对Python和TypeScript,以降低处理大型仓库或多文件改动时的延迟。该版本的设计理念也弱化了“手动查看/编写代码”的过程,转而强调通过提示词让代码代理来替用户执行工作,但部分用户可能仍偏爱终端编程的简洁高效体验。此外,Cursor 2.0新增了内置浏览器和语音模式,前者允许用户在IDE内运行和测试代码并将DOM信息反馈给模型,后者则提供了语音转文字控制功能,方便用户启动或管理代理会话。
怜星夜思:
2、Cursor 2.0搞了个“炼蛊模式”,可以支持8个代理并行工作。听起来很酷,但真实开发中,同时并行这么多代理去写代码,大家觉得是会提高效率还是反而会带来更多的管理和冲突问题?有没有人担心这种模式下,开发者最终会失去对代码的“掌控感”?
3、文章提到Cursor 2.0的设计理念是弱化手动写代码,强调用提示词驱动代理。这跟现在很多AI编程助手的发展方向一致。大家觉得未来编程真的会变成一种“提示词工程”吗?如果真是这样,我们这些“敲键盘”的码农,技能栈需要怎么调整才能不被淘汰?
原文内容



Cursor 2.0发布:自研代码模型Composer上线,8个代理并行,速度提升4倍
Anysphere今天发布了Cursor 2.0,更新了UI界面,并在这个版本中推出了其首个自研、商用闭源的代码大模型Composer。
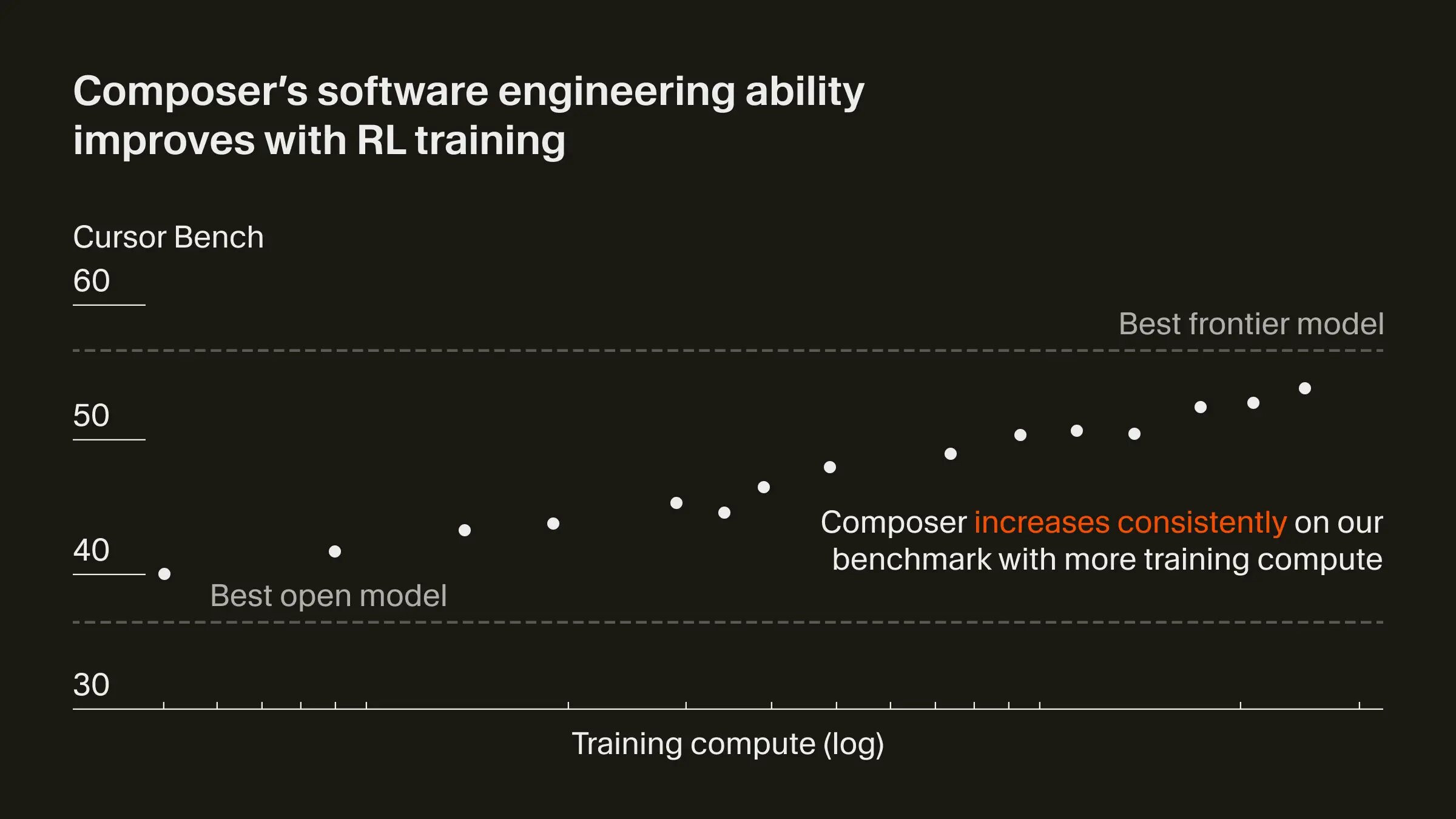
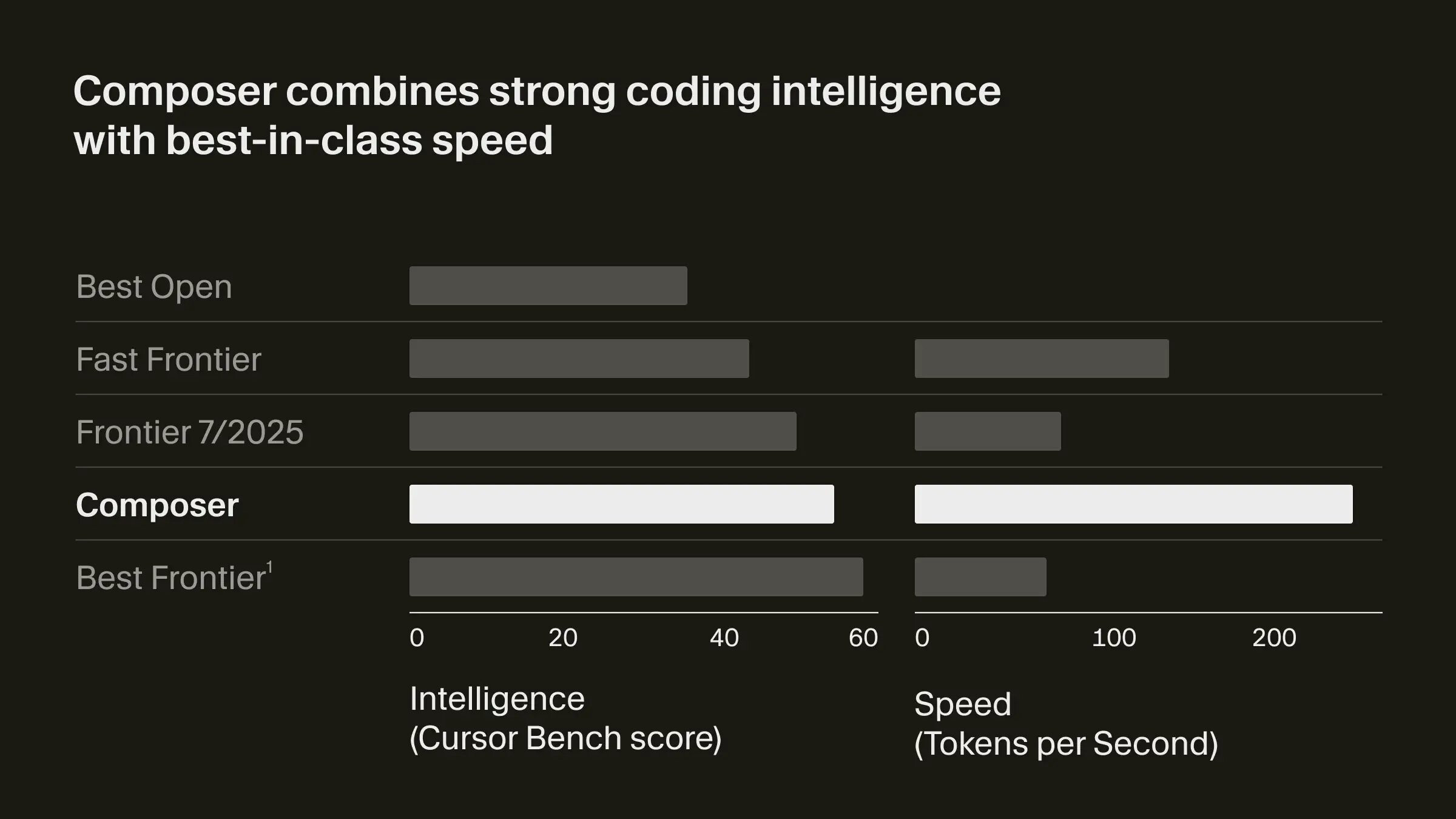
Composer的最大亮点在于其速度设计目标。他们在公告中称其速度“比同等智能的模型快4倍”。模型还专为Agentic工作流训练,支持由自主编码代理协同进行的规划、编写、测试与代码审阅。
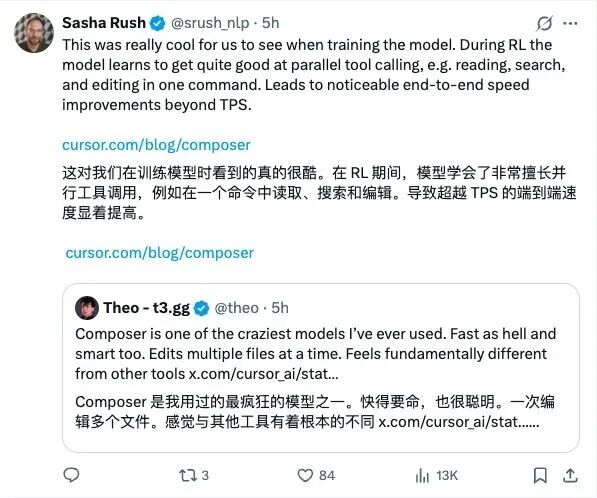
Cursor 研究科学家 Sasha Rush 在X上介绍:Composer 是一款经强化学习(RL)训练的混合专家(MoE)模型,“我们用RL训练了一个大型MoE,让它在真实世界编码中既强又快。”团队对模型与开发环境进行协同设计,使之能在生产规模下高效运行。
但他们的表述里有个关键细节始终不清楚:究竟是从零训练,还是基于已有的开源权重(如Qwen、GLM)继续训练?Sasha Rush一直在Hacker News回答提问,但至今都回避了关于底座模型的直接问题。有人直问“Composer是否只是对开源基础模型的微调?”她的答复是:“我们的主要精力放在强化学习的后训练阶段。我们认为,这是让模型成为强互动智能体的最佳路径。”
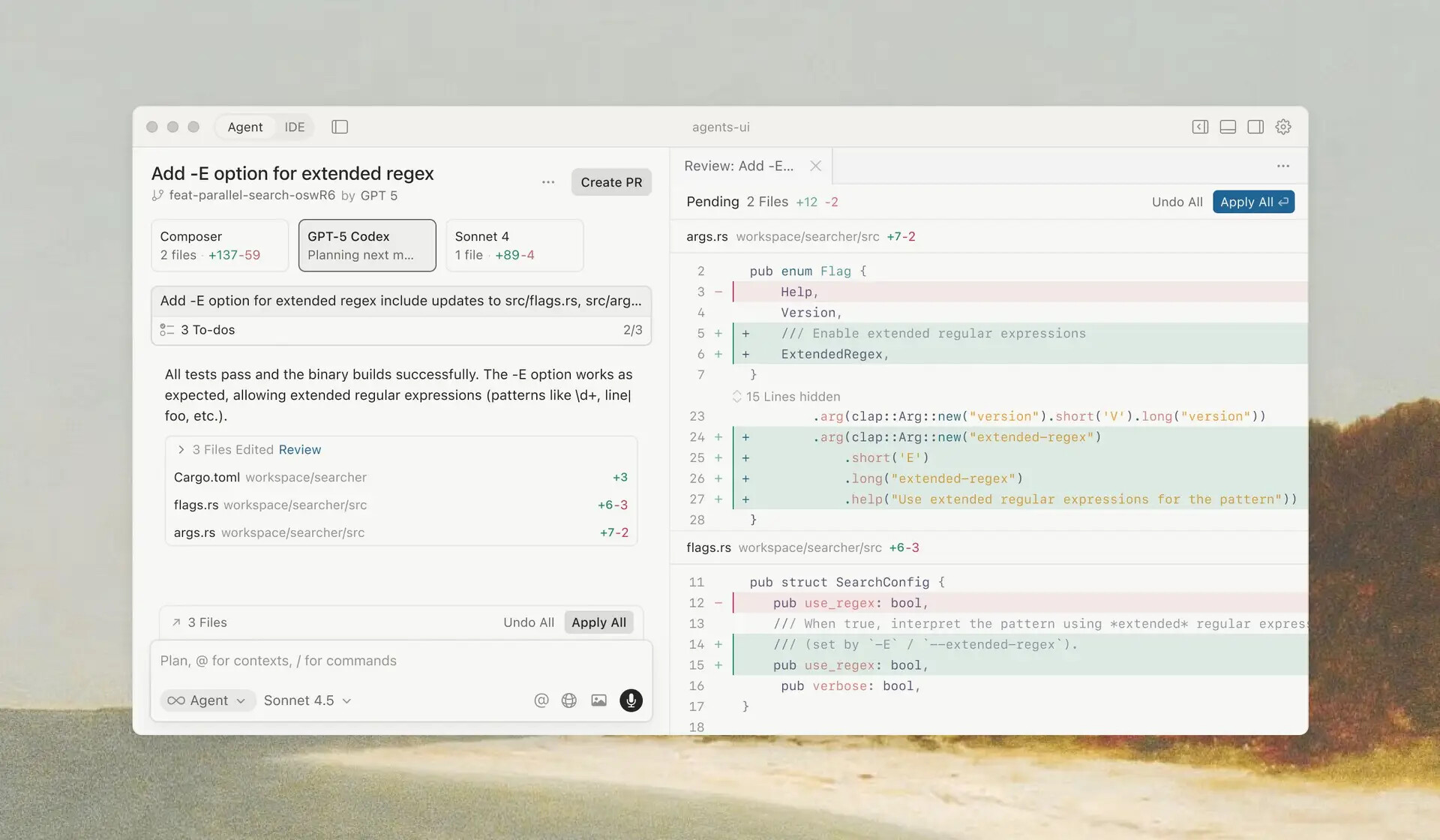
另外,Cursor 2.0提供多代理界面,最多支持8个代理并行(简直是炼蛊模式),每个代理在隔离工作区(git worktree或远程机器)中运行。并且在底层代码智能栈做了大量优化(如LSP加速诊断与导航,尤其面向Python、TypeScript),降低Composer处理大型仓库或多文件改动时的延迟。
尽管如此,Cursor 2.0的界面却让人联想起Web端的Codex。它延续了大约半年前由Claude Code带来的趋势:弱化了“手动查看/编写代码”的过程,转而强调通过提示词让代码代理来替你执行工作。不过,对于一位Claude Code的重度用户来说,他可能更青睐于在终端中编程那种简洁高效的体验。
Cursor 2.0还带来了内置浏览器和语音模式两大新功能。内置浏览器允许用户直接在IDE内运行和测试代码,同时将DOM信息反馈给模型。(这简直是“套娃”!Cursor本身是Electron架构,现在又在其中嵌入了一个Chromium浏览器。)而语音模式则提供了语音转文字控制功能,方便用户启动或管理代理会话。