Spring AI Alibaba DeepResearch是Java驱动的全自动智能研究系统,集成多Agent协作、RAG与报告生成,实现信息搜集、分析与报告自动产出,并支持Spring生态与可观测性。
原文标题:基于Spring AI Alibaba 的 DeepResearch 架构与实践
原文作者:阿里云开发者
冷月清谈:
系统核心能力体现在其推理链路、Java技术栈、Spring生态集成、可观测性(支持Langfuse)、以及可溯源输出等方面,尤其适合对长期稳定运行有要求的企业级场景。
DeepResearch的架构包含11个核心节点,协同完成任务规划与执行。例如,CoordinatorNode负责任务类型识别,BackgroundInvestigationNode和ResearcherNode利用搜索引擎收集信息,PlannerNode进行任务拆解,CoderNode处理数据分析,而ReporterNode则负责整合内容生成报告。这些节点共同支持了多模型配置、提示词工程、多Agent协作、LLM反思机制、任务规划、Graph工作流搭建、工具及自定义MCP配置、RAG专业知识库、链路可观测和报告内容在线可视化等关键技术点。
特别值得关注的是其RAG(Retrieval Augmented Generation)功能。它采用策略模式,支持多源数据检索(知识库、用户文件),结合混合检索策略(如关键词+向量)和可插拔的设计,并通过倒数排序融合(RRF)算法智能整合并重排序检索结果,从而提升信息检索的全面性和准确性。RAG的实现基于Spring AI框架,围绕VectorStore和RetrievalAugmentationAdvisor接口构建,支持多种向量存储类型和灵活的数据摄取方式。
在工具支持方面,系统集成了Tavily、Serp、百度、阿里云AI搜索等多种搜索引擎,并通过JinaCrawler增强内容抓取与处理。SearchFilterService服务可根据黑白名单对搜索结果进行过滤和排序,确保信息质量。同时,DeepResearch支持集成额外的MCP(Model Context Protocol)服务,以增强研究者和代码节点的能力,灵活扩展系统功能。
报告生成是系统的另一大亮点,它能将多智能体协作的成果动态生成结构清晰的综合报告,支持Markdown、PDF等多种导出格式,并提供交互式HTML预览和RESTful API接口进行全生命周期管理。报告存储服务支持Redis和内存两种方式,保障了报告的持久化与高效访问。
此外,系统还具备连续对话能力,通过SessionContextService管理会话上下文,确保LLM在多轮交互中能够“记住”之前的对话和报告内容,提供连贯性响应。
文章最后提供了Docker和IDEA+Docker中间件+前端启动两种部署方式,方便用户快速上手与参与社区。
怜星夜思:
2、文章里提到RAG功能支持多种数据源和混合检索策略,甚至用了RRF算法进行结果融合。在实际应用场景中,尤其是在不同行业(比如医疗、金融、法律)面对的专业知识库和数据格式差异巨大的情况下,这种多源RAG如何保证检索的准确性和召回率?对于一些高度领域化的查询,RRF融合算法的效果总是最优的吗,有没有可能需要针对特定领域做更多定制化开发?
3、DeepResearch提供了一个“动态报告生成与存储”功能,支持多种导出格式和交互式HTML预览。从用户的角度来看,这种灵活性意味着什么?在企业内部知识管理、项目汇报或者对外宣传中,这块功能能带来哪些创新的应用场景?有没有什么建议,可以让报告功能在用户体验上更上一层楼?
原文内容

本文作者:Spring AI Alibaba 社区贡献者
一、引言与概述
我们基于 SpringAI Alibaba Graph 构建了一套 Java 版本的 DeepResearch 系统,实现了从信息搜集、分析到结构化报告生成的全自动流程。
系统主要具备以下能力:
-
推理链路: 通过多轮信息收集,自动构建从资料到结论的分析过程。
-
Java 技术栈:适合对长期稳定运行有要求的场景。
-
Spring 生态集成:可直接使用 Spring Boot、Spring Cloud 等组件,提升开发与集成效率。
-
可观测性:支持 Spring AI Alibaba Graph 的可观测,提供Langfuse平台观测实现,能够清晰的查看调用链路,便于调试和运维。
-
可溯源输出:搜索到的相关内容,配有原始信息来源,便于验证。
二、整体架构概览
系统节点图

三、核心功能与节点实现
任务规划
共有11个节点,功能如下:
-
CoordinatorNode(协调节点):根据用户提问信息,识别任务类型走接下来的流程,非任务类型直接结束; -
RewriteAndMultiQueryNode(重写和扩展节点):优化用户提问信息,并扩展为多个语义; -
BackgroundInvestigationNode(背景调查节点):利用搜索引擎查询问题相关资讯,可根据主题类型(学术研究、生活旅游、百科、数据分析、通用研究)定向查找对应内容; -
PlannerNode(规划节点):将任务拆解为几个步骤; -
InformationNode(信息节点):判断搜寻的内容是否充足; -
HumanFeedbackNode(人类节点):支持用户新增反馈内容; -
ResearchTeamNode(研究组节点):异步并行执行ReseacherNode、CoderNode,等待返回结果; -
ReseacherNode(研究者节点):调用搜索引擎,可根据主题类型查找对应内容; -
CoderNode(数据处理节点):调用python处理工具,进行数据分析; -
RagNode(Rag节点):针对用户上传的文件,针对提问进行检索出相关内容; -
ReporterNode(报告节点):整合上述所有节点整理的内容,生成对应的报告;
在上述节点的支撑下,引入了如下技术点:多模型配置、提示词工程、多Agent写协作、LLM反思机制、任务规划、Graph(节点并行、流式输出、人类反馈)工作流搭建、工具及自定义MCP配置、RAG专业知识库、链路可观测、报告内容在线可视化。
RAG
1、功能说明
spring-ai-alibaba-deepresearch 项目集成的 RAG 功能,并非依赖单一的检索方式,而是通过策略模式,灵活地从多种异构数据源中检索信息,并将检索结果进行智能融合与重排序,最终为语言模型提供最相关的上下文信息。RAG功能总体来说包含两个核心阶段:
deepresearch项目的RAG具体功能点如下:
RAG功能支持灵活设置,主要配置项包括:
-
RAG 启用/禁用: 通过
spring.ai.alibaba.deepresearch.rag.enabled属性可以控制 RAG 功能的开启与关闭。 -
向量存储类型: 支持两种向量存储类型:
-
simple: 使用SimpleVectorStore,数据可以持久化到本地文件,通过storage-path配置存储路径。
-
elasticsearch: 使用ElasticsearchVectorStore,将向量存储在 Elasticsearch 数据库中,可通过uris、username、password和index-name等属性进行配置。
-
数据摄取: 项目支持多种数据加载方式:
-
启动时加载: 应用程序启动时,自动从
classpath:/data/目录加载文件。 -
定时扫描: 通过 cron 表达式 (
cron: "0 */5 * * * *") 定时扫描指定目录 (directory),并将处理后的文件归档到另一个目录 (archive-directory)。 -
手动上传: 提供 REST API 接口 (
/api/rag/data/upload),允许用户通过文件上传的方式手动摄取文档数据。 -
api接入:也支持通过api等形式接入第三方知识库的数据。
-
RAG 管道: RAG 管道(pipeline)功能允许在检索前和检索后对查询或文档进行处理。
-
query-expansion-enabled: 启用查询扩展功能,为原始问题生成多个相关查询,以提高检索覆盖率。 -
query-translation-enabled: 启用查询翻译功能,将查询翻译成指定语言 (query-translation-language)。 -
post-processing-select-first-enabled: 启用后处理功能,仅选择检索到的第一个文档作为最终结果。
2、实现方式
该 RAG 功能的实现基于 Spring AI 框架,主要围绕 VectorStore 和 RetrievalAugmentationAdvisor 两个核心接口构建。
-
数据摄取流程:
-
RagDataAutoConfiguration类在应用启动时或通过定时任务触发数据加载。
-
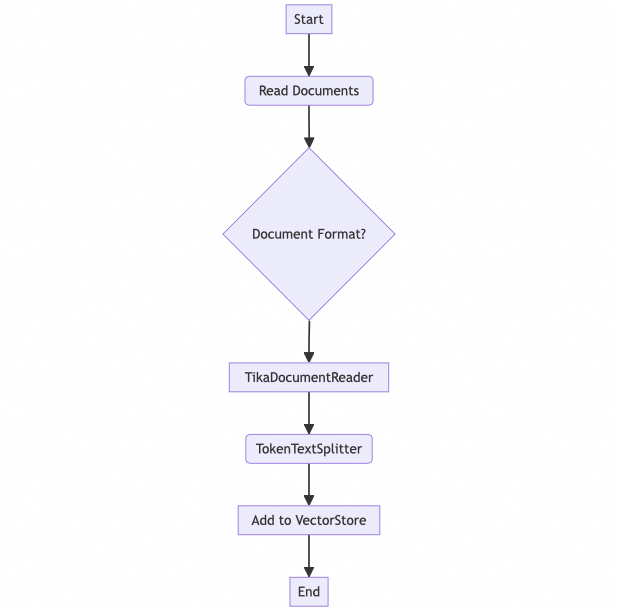
VectorStoreDataIngestionService服务负责处理实际的文档摄取工作。它使用 TikaDocumentReader 来读取多种格式的文档(如 PDF, DOCX, MD),然后利用 TokenTextSplitter 将文档分割成小块,最后将这些文档块添加到配置好的 VectorStore 中。
-
向量存储配置:
-
RagVectorStoreConfiguration 根据spring.ai.alibaba.deepresearch.rag.vector-store-type的值,动态创建 SimpleVectorStore 或 ElasticsearchVectorStore bean。
-
RAG 管道和顾问:
-
RagAdvisorConfiguration类负责配置 RAG 管道。它创建一个RetrievalAugmentationAdvisor bean,并将VectorStoreDocumentRetriever 作为其文档检索器。
-
根据
RagProperties的配置,MultiQueryExpander(查询扩展)、TranslationQueryTransformer(查询翻译)和DocumentSelectFirstProcess(后处理) 等组件被选择性地添加到 RAG 管道中。
-
RagNode 是一个 NodeAction,它将 RAG 功能集成到主应用程序的工作流中。
-
在 RagNode 的 apply 方法中,它从状态中获取用户查询,然后通过 ChatClient 调用配置好的 RetrievalAugmentationAdvisor。RetrievalAugmentationAdvisor 会根据查询从 VectorStore中检索相关文档,并利用这些文档来增强大语言模型的响应,最后将生成的增强结果放入状态中。
-
DeepResearchConfiguration类则负责将
RagNode添加到整个StateGraph中,实现了 RAG 功能作为工作流中的一个可执行节点。
3、架构和流程图
架构图
deepresearch 的RAG实现在深度整合了Spring AI的能力之外,还进行了扩展。核心是 HybridRagProcessor 接口及其默认实现 DefaultHybridRagProcessor。
下面是 deepresearch 模块RAG功能的扩展架构图,使用Mermaid绘制:
代码段
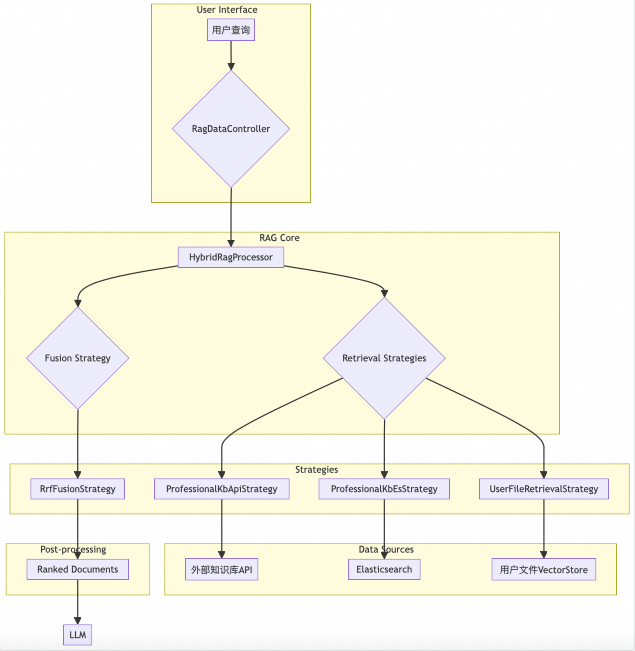
架构解析:
**RagDataController**):负责处理外部请求,例如用户上传文件进行知识库构建。
**HybridRagProcessor**):这是RAG流程的“大脑”,负责协调整个检索和融合过程。它接收查询请求,然后调用注册的各种检索策略。
**RetrievalStrategy**):
-
ProfessionalKbApiStrategy:通过API接口从专业的知识库(如DashScope的知识库)中检索文档。 -
ProfessionalKbEsStrategy:使用自定义的RrfHybridElasticsearchRetriever从Elasticsearch中进行混合检索。这种检索方式结合了传统关键词搜索和向量相似度搜索的优点。 -
UserFileRetrievalStrategy:从用户上传并存储在向量数据库中的文件里检索相关内容。
**FusionStrategy**):
-
RrfFusionStrategy:实现了RRF算法。它接收来自所有检索策略返回的文档列表,根据每个文档在不同列表中的排名计算一个综合得分,并据此对所有文档进行重新排序。
流程图
为了更直观地理解其工作流程,下面是RAG功能的处理流程图:
数据摄取流程
RAG 节点查询流程
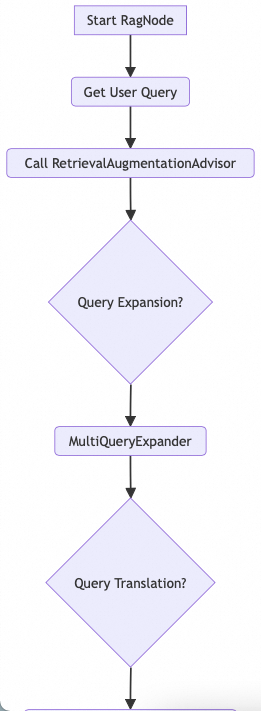
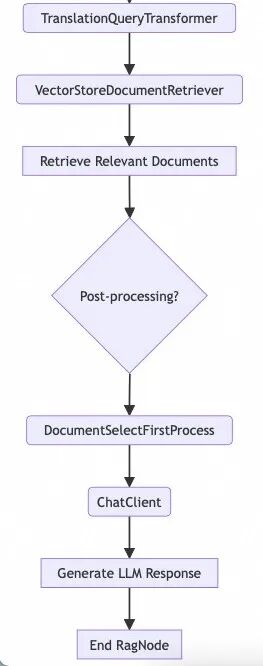
工作流程:
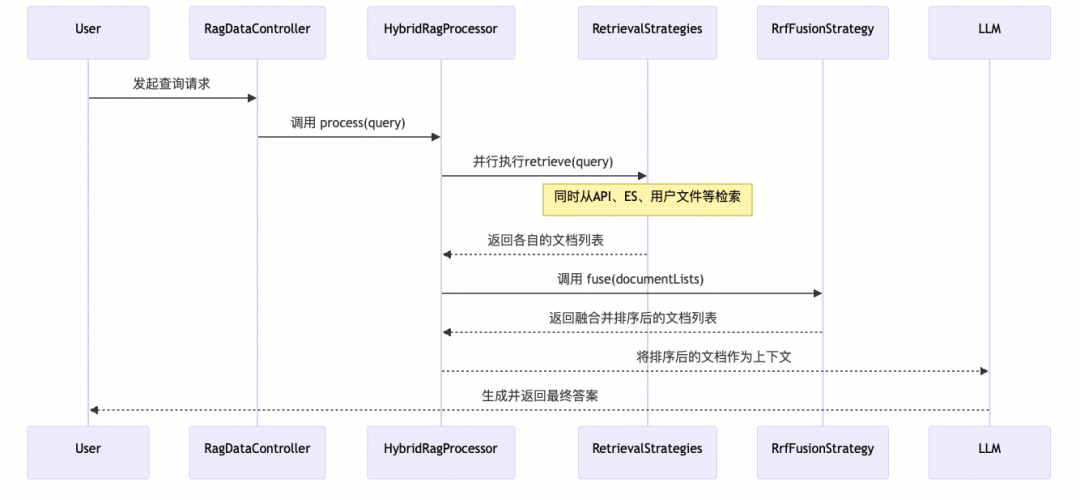
流程解析:
2. HybridRagProcessor接收到查询后,会并发地调用所有已注册的RetrievalStrategy。
RetrievalStrategy根据自身的逻辑从对应的数据源(API、ES、文件)检索文档,并返回一个有序的文档列表。
4. HybridRagProcessor将所有策略返回的文档列表集合起来,传递给RrfFusionStrategy。
5. RrfFusionStrategy对这些列表进行融合与重排序,生成一个最终的高度相关的文档列表。
4、总结
spring-ai-alibaba-deepresearch模块中的RAG功能通过将检索和融合过程抽象为策略接口,实现了高度的灵活性和可定制性。其混合检索的能力,特别是结合了RRF算法的多路召回融合机制,能够有效整合来自不同数据源的信息,显著提升信息检索的全面性和准确性,为构建企业级、高可用的RAG应用提供了坚实的基础。
tools搜索能力+MCP
通用搜索工具
在背景调查节点(BackgroundInvestigationNode)和研究者节点(ResearcherNode)中,大语言模型(LLM)会根据用户输入的问题自动制定相应的搜索方案,并通过调用外部搜索工具获取相关信息。目前系统支持四种搜索工具:Tavily、Serp、百度搜索以及阿里云AI搜索。用户还可选择启用 JinaCrawler 服务,该服务能够对搜索结果中提取的链接进行进一步抓取和处理,通过 Jina 提供的解析能力增强原始搜索返回的内容。
用户需在 application.yml 配置文件中提前配置相应搜索工具所需的 API Key 或相关环境变量,以便正常调用搜索服务。
搜索功能主要由SearchFilterService(搜索过滤服务)实现。该服务根据用户配置选择合适的 SearchService 执行搜索,并对返回的结果依据黑白名单规则进行排序与过滤。系统提供了LocalConfigSearchFilterService作为这一服务的实现类,支持从 JSON 配置文件中读取网站黑白名单。该配置文件为一个 JSON 数组,每个数组元素为包含host和weight字段的对象。
其中weight的取值范围为 -1 到 1:数值越高,表示对应网站的可信度越高;而取值为负数则表示该网站不可信——即使搜索工具返回了来自该网站的结果,系统也会将其过滤,确保不会传递给 LLM 模型用于后续生成答案。
MCP
DeepResearch 支持用户集成额外的 MCP(Model Context Protocol)服务,以增强研究者节点(ResearcherNode)和代码节点(CoderNode)的处理能力。用户可以通过以下两种方式配置 MCP 服务:
-
静态配置文件方式:在
mcp-config.json中预先定义 MCP 服务器信息。 -
动态请求方式:在每次向
/chat/stream接口发送请求时,通过mcp_settings字段实时携带 MCP 服务定义。
启用MCP服务需要将配置文件的spring.ai.mcp.client.enabled和spring.ai.alibaba.deepresearch.mcp.enabled字段设置为true。
有效的 MCP 服务配置示例如下:
{
"researchAgent": {
"mcp-servers": [
{
"url": "https://mcp.amap.com?key=${AMAP_API_KEY}",
"sse-endpoint": "/sse",
"description": "高德地图位置服务",
"enabled": true
}
]
},
"coderAgent": {
"mcp-servers": []
}
}
当用户通过 API 传递自定义的 MCP 配置时,后端会利用 McpProviderFactory 将配置内容动态组装为 AsyncMcpToolCallbackProvider,供 ChatClient 在会话中调用相应的 MCP 工具和服务。这一机制使用户能够灵活扩展系统功能,并在运行时按需引入外部服务。
结果生成
1、功能说明
spring-ai-alibaba-deepresearch 项目的核心能力之一是将多智能体协作的最终研究成果,动态生成为一份结构清晰、内容详实的综合报告。为了便于用户查阅、归档和分享,项目提供了一套完整的报告生成、管理与导出功能。
该功能主要包含以下核心特性:
-
动态报告生成与存储:在每个研究任务(由唯一的
threadId标识)完成后,系统会自动捕获最终结论,并将其作为一份报告持久化存储。 -
多种导出格式:为了适应不同场景的需求,报告支持导出为多种主流文档格式,包括 Markdown 和 PDF。
-
交互式HTML预览:除了静态文件导出,系统还提供了一个实时流式接口,可以将报告内容动态渲染为一个可交互的 HTML 页面,提供更丰富的展现形式。
-
RESTful API 接口:功能通过一套标准的 RESTful API 暴露,允许用户和外部系统对报告进行全生命周期的管理,包括查询、检查存在性、删除、导出以及获取下载链接。
2、实现方式
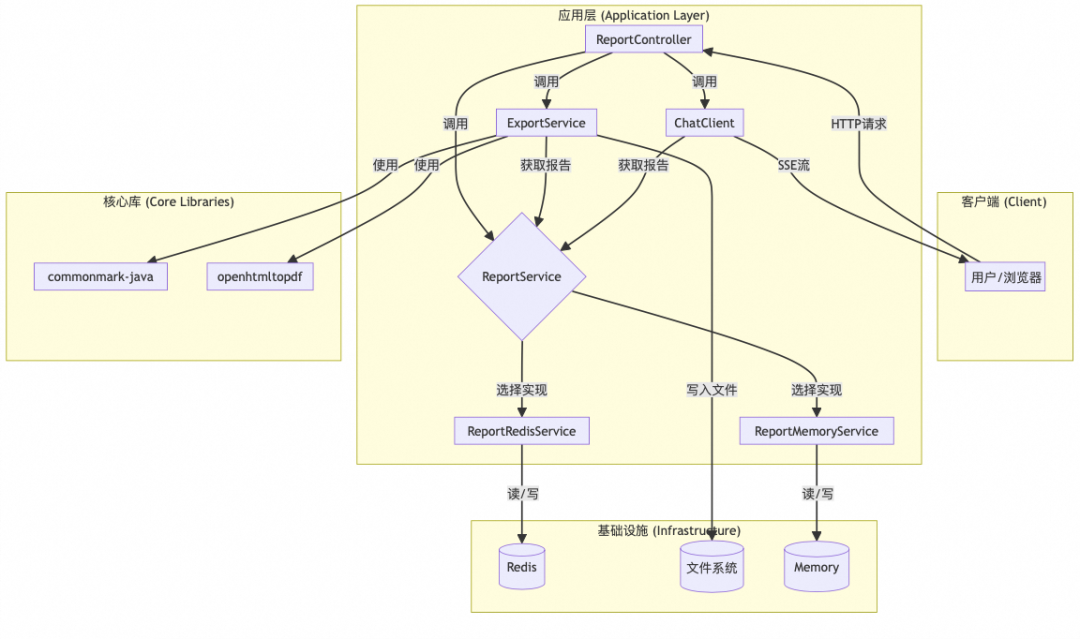
该功能的实现主要围绕 ReportService(报告管理)和 ExportService(报告导出)两个核心服务展开,并通过 ReportController 暴露为 API 接口。
-
ReportService: 报告的存储和管理接口,包括saveReport、getReport、existsReport和deleteReport等核心方法。 -
ReportRedisService: 这是ReportService的默认实现,使用 Redis 作为后端存储。每份报告以字符串形式存储,并使用report:{threadId}作为键(Key),保证了高效的读写性能和持久化能力。 -
ReportMemoryService: 这是ReportService的另一个实现,使用内存中的ConcurrentHashMap来存储报告。它主要用于开发、测试或在没有 Redis 环境下的快速启动。当 Redis 未启用时,该服务会自动生效。
-
ExportService: 这是负责格式转换和文件生成的核心服务。它从
ReportService获取原始报告内容(Markdown 格式),然后执行相应的转换逻辑。 -
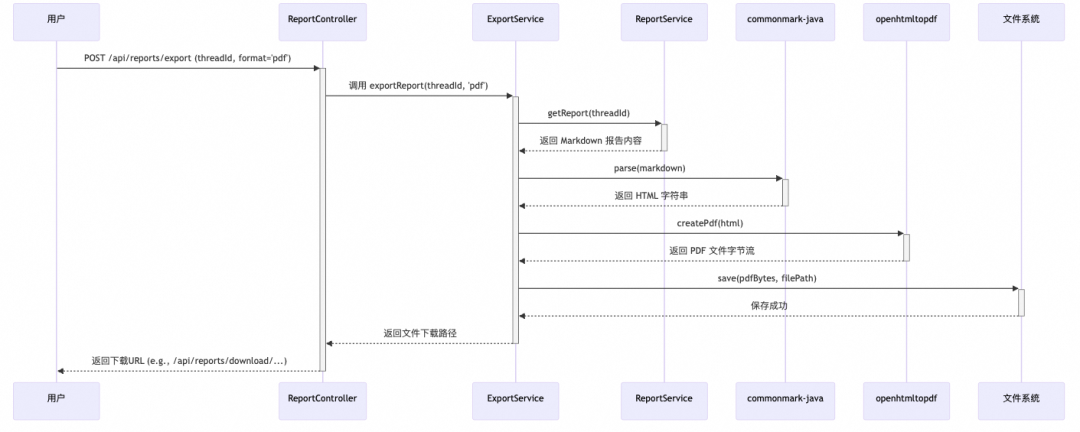
Markdown 导出: 从
ReportService获取报告字符串,并利用FileOperationUtil工具类将其保存为一个.md文件。
-
从
ReportService获取原始 Markdown 报告。 -
使用
commonmark-java库将 Markdown 文本解析并渲染为 HTML 字符串。为了更好地支持 GitHub Flavored Markdown (GFM),还集成了commonmark-ext-gfm-tables扩展来处理表格。 -
使用
openhtmltopdf库接收上一步生成的 HTML,并将其转换为 PDF 文档。该库能够处理复杂的 CSS 样式和布局,为了正确显示中文字符,项目中已预置并加载了兼容 CJK 的字体。 -
最终生成的 PDF 文件被保存到临时目录中,并准备好供用户下载。
-
GET /api/reports/{threadId}: 根据线程 ID 获取原始报告内容。
-
POST /api/reports/export: 触发异步导出任务,支持指定format(pdf/md)。 -
GET /api/reports/download/{threadId}:提供已导出文件的下载。 -
GET /api/reports/interactive-html/{threadId}: 基于报告内容,通过大语言模型流式生成交互式 HTML 响应。
连续对话能力
在当前的DeepResearch架构中,为了支持用户进行多轮交互并基于上下文进行连续提问,系统实现了会话上下文管理功能。该功能确保在同一个用户会话中,用户之前的问题以及工作流上几次运行输出的报告,能够作为历史上下文信息,被有效地注入到本次工作流的特定节点
(BackgroundInvestigationNode和CoordinatorNode)的模型请求中。
核心机制:
-
会话标识 (
GraphId): 用户的每一次请求都会被分配一个唯一的GraphId对象。该对象包含两个关键属性:
-
sessionId: 用于标识一个长期的用户会话。同一对话窗口的多次请求会共享同一个sessionId,从而关联起连续的对话上下文。 -
threadId: 用于标识单次独立的请求或工作流执行。每次请求通常拥有一个唯一的threadId,用于区分同一会话内的不同交互回合。
-
上下文获取与服务 (
SessionContextService): 该功能的核心由SessionContextService(会话上下文服务)接口及其实现承担。其主要职责是: -
根据当前请求的
sessionId,获取与该会话相关的最近数次请求的完整历史记录(SessionHistory)。 -
上下文应用: 在工作流执行过程中,
BackgroundInvestigationNode(背景调查节点)和CoordinatorNode(协调节点)会调用SessionContextService。服务返回的SessionHistory会被作为历史消息添加到发送给大语言模型(LLM)的请求中。这使得LLM能够“记住”之前的对话和报告内容,从而做出具有连贯性和上下文感知的响应。
框架目前提供了一个默认的、基于内存的实现——InMemorySessionContextService。该实现将会话历史临时存储在应用内存中,适用于开发、测试或轻量级部署场景。其特点是速度快,但存在数据易丢失(如应用重启后)和难以横向扩展的限制。根据实际生产环境的需求,可以编写自己的SessionContextService实现类。
1、架构和流程图
下图展示了动态报告生成与导出功能的整体架构和组件间的交互关系:
为了更直观地理解其工作流程,下面是报告导出功能(以 PDF 为例)的处理流程图:
2、总结
spring-ai-alibaba-deepresearch项目的动态报告生成与导出功能,通过将核心业务逻辑(报告管理、格式转换)与 API 接口解耦,构建了一个清晰、可扩展的模块。它不仅提供了多样的导出选项以满足不同用户的需求,还通过集成开源的第三方库(commonmark 和 openhtmltopdf)确保了高质量的文档输出。同时,通过提供 Redis 和 内存 两种存储实现,并利用 Spring Boot 的条件化配置自动切换,兼顾了生产环境的可靠性和开发测试的便捷性。这套功能极大地提升了用户使用的便利性和交互体验,是整个应用闭环中不可或缺的重要一环。
四、使用方式与部署方式
方式一:Docker部署完整项目
构建说明
docker 部署需在本地安装最版本的 docker 软件,安装方式参考官方文档
(https://www.docker.com/)
docker 部署的方式为 docker 多阶段构建:
-
第一阶段 - 前端构建 (frontend-builder)
-
使用 Node.js 21 Alpine 镜像
-
安装 pnpm 包管理器
-
复制前端项目文件并安装依赖
-
执行
pnpm build-only命令构建前端项目
-
第二阶段 - 后端构建 (backend-builder)
-
使用 Dragonwell JDK 17 Ubuntu 镜像
-
安装 Maven
-
复制 Maven 配置文件和项目源码
-
执行
mvn clean install构建后端项目
-
第三阶段 - 运行时镜像
-
基于 Dragonwell JDK 17 Ubuntu 镜像
-
安装 Nginx 和 Supervisor
-
从构建阶段复制编译产物:
-
后端 JAR 包复制到
/app/app.jar -
前端构建产物复制到
/var/www/html/ui/
部署说明
在项目根目录下执行以下命令:
$ # 第一步 : 在 dockerConfig目录下创建.env 配置文件,并且填写具体的环境变量
$ cd spring-ai-alibaba-deepresearch
$ docker build -t spring-ai-deepresearch .
$ docker run --env-file ./dockerConfig/.env -p 8080:80 --name deepresearch -d spring-ai-deepresearch
.env 配置文件内容:
# 百炼apiKey,地址:https://bailian.console.aliyun.com/
AI_DASHSCOPE_API_KEY=<AI_DASHSCOPE_API_KEY>
# 报告导出地址,填写本地路径
AI_DEEPRESEARCH_EXPORT_PATH=<AI_DEEPRESEARCH_EXPORT_PATH>
# tavily 搜索,地址:https://www.tavily.com/
TAVILY_API_KEY=<TAVILY_API_KEY>
# langfuse 监控,地址:https://langfuse.com/
YOUR_BASE64_ENCODED_CREDENTIALS=<YOUR_BASE64_ENCODED_CREDENTIALS>
当容器正确启动之后访问 :http://localhost:8081/
方式二:
Idea启动后端服务+Docker启动中间件+前端启动
要求:
-
docker
-
JDK17及以上
-
Node 16及以上
启动中间件
cd spring-ai-alibaba-deepresearch
docker compose -f docker-compose-middleware.yml up -d
这里中间件只启动了 redis 和 elasticsearch。
启动后端项目
首先,编译项目
cd spring-ai-alibaba-deepresearch
mvn clean install -DskipTests
接着,配置 IDEA环境变量
Edit Configurations -> 选择 DeepResearch 项目 -> Modify options -> Environment variables -> 配置具体的环境变量

最后,启动后端项目。
启动前端项目
下载依赖,并且启动前端项目
cd spring-ai-alibaba-deepresearch/ui-vue3
pnpm install
pnpm run dev
前端项目配置说明:
-
.env 配置文件的
VITE_BASE_URL配置为请求后端 URL
-
可以配置后端具体地址,例如:
http://127.0.0.1:8080; -
可以配置相对路径,例如:
/deep-research,这个时候就需要前端代理转发到后端,在vite.config.ts 文件进行配置代理;
-
代理配置,当.env 配置文件使用相对路径,则需要配置代理。例如:
'/deep-research': {
target: 'http://localhost:8080',
changeOrigin: true,
rewrite: (path) => path.replace(/^\/deep-research/, '')
}
最后,访问前端项目:http://localhost:5173/ui
五、社区参与方式
-
Github 项目地址:https://github.com/alibaba/spring-ai-alibaba
-
欢迎 PR / Issues / Feature Request
-
社区交流方式(Github 及 DeepResearch 用户群)
-
yingzi:https://github.com/GTyingzi
-
zhouyou:https://github.com/zhouyou9505
-
NOBODY:https://github.com/SCMRCORE
-
xiaohai-78:https://github.com/xiaohai-78
-
VLSMB:https://github.com/VLSMB
-
disaster1-tesk:https://github.com/disaster1-tesk
-
Allen Hu:https://github.com/big-mouth-cn
-
Makoto:https://github.com/zxuexingzhijie
-
sixiyida:https://github.com/sixiyida
-
Gfangxin:https://github.com/Gfangxin
-
AliciaHu:https://github.com/AliciaHu
-
swl:https://github.com/hbsjz-swl
-
huangzhen:https://github.com/james-huangzhen
-
Tfh-Yqf:https://github.com/Tfh-Yqf
-
anyin-xyz:https://github.com/anyin-xyz
-
zhou youkang:https://github.com/mengnankkkk
-
supermonkeyguys:https://github.com/supermonkeyguys
-
yuluo-yx:https://github.com/yuluo-yx
-
Ken Liu:https://github.com/chickenlj
-
co63ox:https://github.com/co63oc