豆包语音AI方案,小说文本一键生成高品质多人有声剧,配音与后期全自动,带来沉浸式听书体验,大幅降低制作成本。
原文标题:小说一键转有声剧!豆包语音团队提出「AI多人有声剧」方案,沉浸感拉满了
原文作者:机器之心
冷月清谈:
除了卓越的语音生成能力,此方案还创新实现了全自动AI后期制作。它能高效预测并添加人声特效、动作音效(基于AED技术精准对齐)、环境音(智能淡入淡出),以及智能匹配与剧情情绪同步的背景音乐。为确保最终听感,方案还包含智能动态混音策略,能够实时分析人声能量,利用侧链压缩技术自适应平衡背景音乐与环境音量,保证对白始终清晰突出,并进行内容感知的动态范围与响度标准化处理,确保成品在不同设备上都能提供一致、自然、专业的听感。目前,首批由该方案制作的有声剧已在番茄小说App上线,预示着有声内容生产迈入了智能化、高效率的新阶段。
怜星夜思:
2、听了AI生成的有声剧片段,确实很厉害!但大家觉得AI在情感表达的细腻程度和“灵魂感”上,真的能完全媲美真人吗?哪些地方AI可能永远无法替代?
3、如果AI能这么轻松地把各种小说变成有声剧,那对于版权保护会不会带来新的挑战?比如未经授权的作品被AI使用,或者说AI生成的内容版权归属怎么界定?
原文内容
机器之心编辑部
「东州市第一监狱,犯人屠国安被狱警带到了招待室。
门一开,他看到有人背对着他,对方短发,身形纤瘦,姿态挺拔,在他的记忆里,并没有这样的熟人。」
这段文字源自一本知名的刑侦小说《遮云》,而下面这段音频是对应章节的「有声」版本,先听听:
在音频最开始的一分钟里,我们就听到了人物对白和旁白解说,脚步、开门、坐下、手铐晃动和递名片的声音,背景音乐等多种元素。相比于单纯地阅读文字,听书的沉浸感确实强了不少。
如果说,这段声情并茂的朗读音频都是由 AI 生成的呢?很多读者可能会感到惊讶:「不知不觉,AI 讲书的水准已经进化到这个地步了?」
是的,这段「AI 讲书」背后的配音和后期,来自豆包语音团队近日发布的「AI 多人有声剧」自动化方案。该方案不仅支持多角色、高表现力的 TTS 演播,同时也实现了全自动 AI 后期的链路。
也就是说,从小说文本到高质量的多人有声剧成品,全部由 AI 端到端完成。这意味着,基于该方案的有声书生产制作成本和周期大幅降低。目前,首批由该方案端到端创作的有声剧已经在番茄小说 App 上线。
具体而言,这套方案基于新升级的多角色 Seed-TTS-2.0 模型,配合 AI 自动音乐、音效、特效和智能混音,在听感效果上已经能够媲美行业一流水准的真人有声剧。
当然,开篇的 Demo 只是该方案的众多成果之一,让我们再欣赏一些高光片段:
把小说变成多人有声剧,总共分几步?
小说作品通常具有充满戏剧性的情节和极具感染力的台词,而将这些小说的文字内容转化为有声剧,同样受到了很多读者的欢迎。
传统多人有声剧的制作周期较长,一般会持续数月。立项后需要先经过人工切分画本并校准,设计配音角色表,并完成十几甚至几十个声优录制。随后,后期人员会精修音频,并在此基础上进行音效、音乐和混音处理,完成母带制作,最终输出为专业的有声剧成品。
而豆包语音团队提出的这套新方案,使得有声书生产的制作成本和周期大幅降低。方案首先利用端到端多角色语音模型合成 TTS 音轨,基于音频和后期画本预测模型,进一步生成带后期的有声剧。后期音效包含特效、音乐、音效、环境音,通过智能混音技术平衡音轨,最终生产出完整的成品多人有声剧。
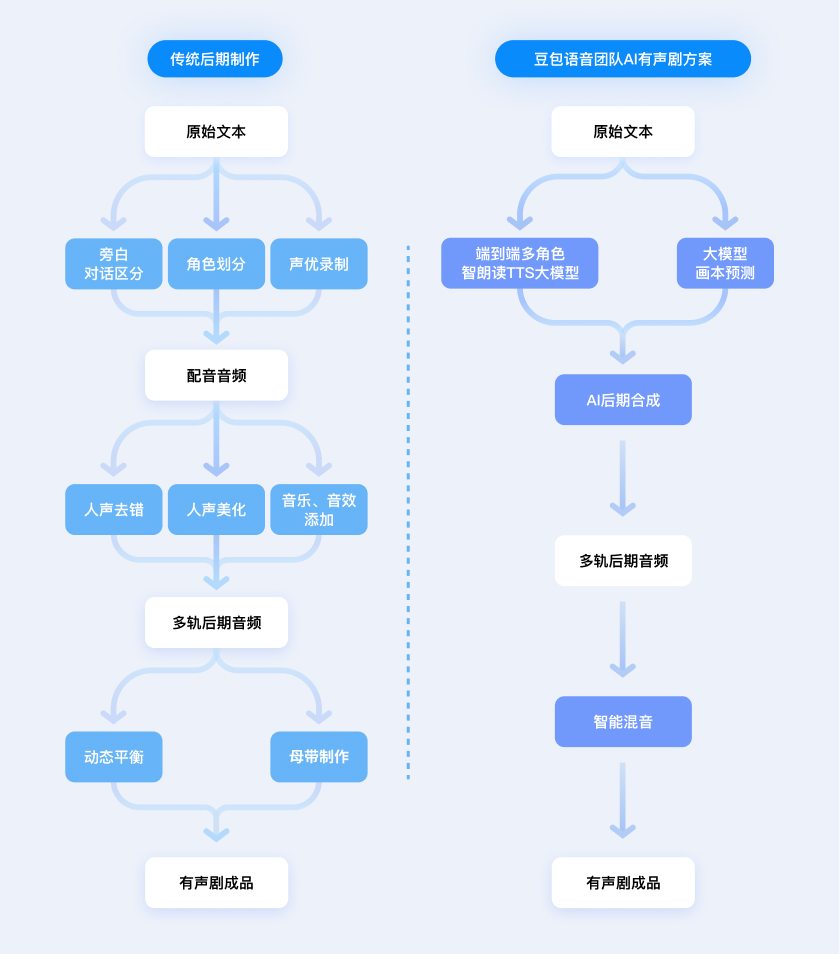
AI 一键生成多人有声剧,如何媲美「真人配音 + 后期」?
在「多角色演播」和「AI 后期」等流程中,豆包语音团队的「AI 多人有声剧」自动化方案做到了高水准生成。
首先是「多角色演播」的效果升级。这套方案支持从「小说文本」到「多角色智能朗读音频」的全自动生产,音色匹配和对话归属准确率超过 98%。
在多人演播效果上,多角色 Seed-TTS-2.0 模型通过对海量文本与语音的多模态预训练,原生地将文本和语音模态融合,凭借强大的文本理解能力和语音演绎能力,进一步提升了对小说的角色、情感、副语言等细腻的演绎效果。这种演绎效果的升级,源自于几个创新点:
-
篇章级长上下文感知,进一步增加模型对上下文的感知范围,对角色的理解更加到位;
-
历史长音频建模,模拟真实小说录制场景,可感知所有上文音频信息,各角色语音承接力、表现力进一步加强;
-
多轮思维链 (CoT) 推理,引入思维链信息,强化对当前角色、人设、情感、副语言的理解,打造更加细腻的演绎效果,带来沉浸式的听书体验。
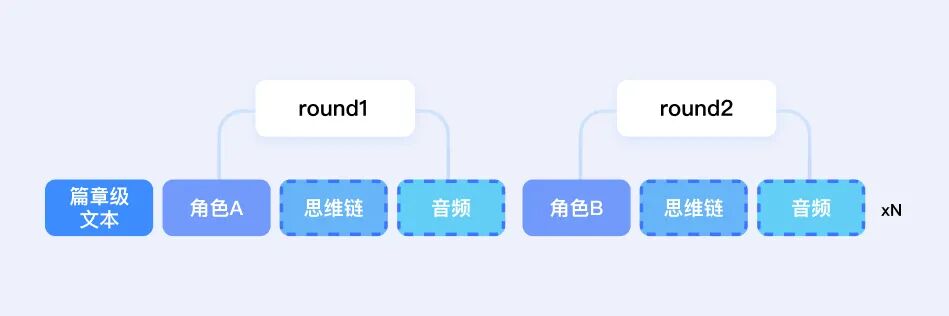
当模型的上下文感知能力更深刻,所呈现的「人物情感」也就更精准了:
满身是血的李子夜双臂强行撑起,说道:“趁他还不能动。”
再比如,小说文本中的「副语言」演绎效果有了显著的提升:
“咯咯咯!我现在告诉你一个好消息。”
此外,该方案创新地实现了「全自动 AI 后期」。
我们知道,画本对有声书的制作非常重要,传统人工方案需要根据剧本中的人物特点,在文本上标记强调词、停顿点、角色转换提示等,帮助配音者在演播过程中准确无误地传达信息。而「AI 多人有声剧」方案能高效地实现从小说文本到带有音效、人声特效、环境音、配乐的画本预测。
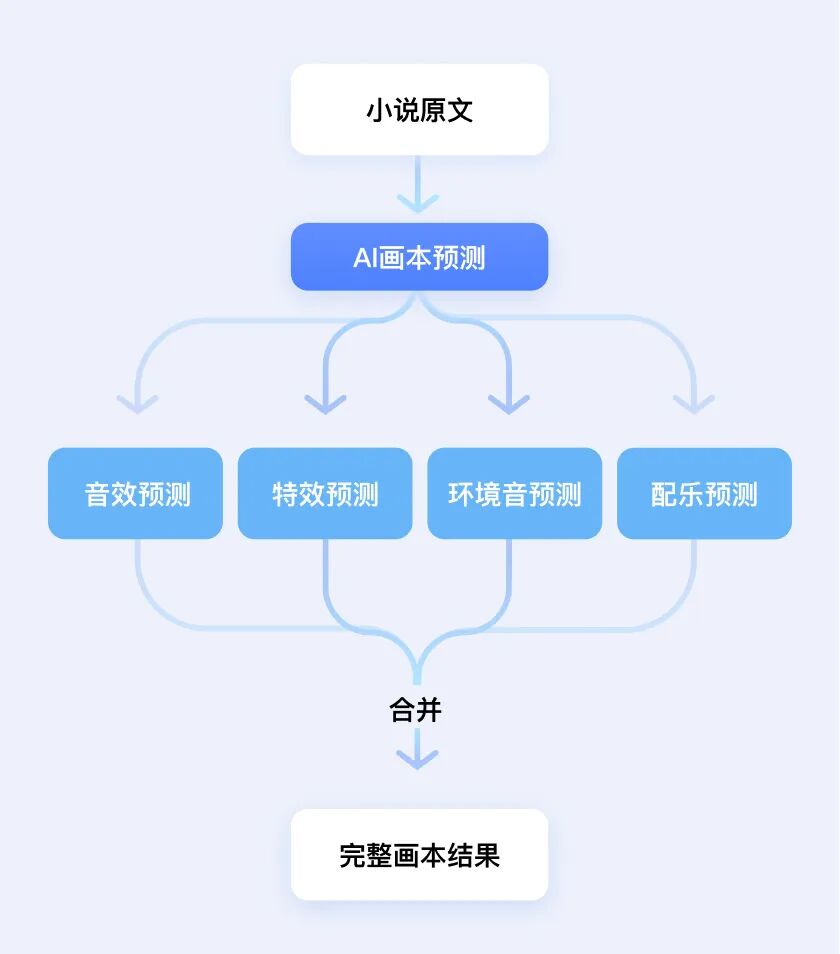
其中,「人声特效预测」能够结合说话人信息,预测是否添加特效以及特效内容,准确度接近 100%;动作音效预测基于 AED(音频事件检测)技术构建动作音效体系,在篇章级别的预测中避免剧情撞车的问题,实现时间轴精准对齐;环境识别预测能够在环境渲染可实现智能的淡入淡出,丰富后期效果的同时,保持情节和情绪的稳定性,完美适配 TTS 时长;在配乐设计层面,方案包含的小说智能配乐系统,能够为不同题材匹配最佳 BGM, 配乐与剧情情绪同步、章节收尾自然,可以很好地烘托剧情氛围。
方案包含智能动态混音策略,做到了整体听感的自然统一与音质清晰度的最优平衡。在智能动态平衡与响度控制上,方案能够实时分析人声轨的能量与响度,使用侧链压缩技术通过人声自适应压低 BGM 与环境音,让对白始终清晰突出,并通过内容感知的动态范围与响度标准化处理,确保成品在不同设备上始终保持一致、自然、专业的听感。
据了解,「AI 多人有声剧」自动化方案未来将持续升级,覆盖更多精品内容,为更多用户带来优质的听书体验。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com