LangChain 1.0重磅发布,完成1.25亿美元融资跻身独角兽。框架彻底重写,Agent开发告别拼凑,迈向精简、灵活、强大的工程化时代。
原文标题:LangChain 彻底重写:从开源副业到独角兽,一次“核心迁移”干到 12.5 亿估值
原文作者:AI前线
冷月清谈:
LangChain最初由Harrison Chase于2022年10月作为个人副业发起,旨在解决大模型开发中工具碎片化和抽象不足的问题。它通过连接模型与工具,将多个调用串联成链条,解决了早期大模型应用开发的痛点,如网页搜索、API调用和数据库交互。随着大模型热潮,LangChain迅速成长,成为下载量数千万、GitHub Star超11万的流行开源项目。
项目核心在于其“情境感知的推理型应用框架”定位,包含组件模块层和端到端链与应用层。团队长期坚持“模型与基础设施中立”路线,集成了主流大模型和80多种向量数据库,以及超过700个不同的集成,致力于成为连接各种技术触点的“粘合剂”。
然而,高速集成也导致了问题积累,包括大量Bug、PR积压,以及用户对更高控制权的需求。为解决这些痛点,团队开发了LangGraph,一个允许开发者以更底层方式编排智能体逻辑的工具。此次LangChain的重写正是以LangGraph为底座,并深受其开发经验影响,目标是实现生产环境下的可控性与内建运行时能力。
新版LangChain 1.0围绕“智能体=工具调用循环”概念构建,引入了统一的`create_agent`抽象,平衡了易用性与可控性。更关键的是,它添加了“中间件”概念,允许开发者在核心智能体循环的任意位置插入额外逻辑,以支持长上下文、人类在环审批等高级场景,并能基于上下文动态选择模型,实现真正的模型无关性。
产品层面,LangChain 1.0进行了四项系统升级:引入更规范的`content blocks`、精简代理选项、强化`middleware`以实现可控性和“上下文工程”,以及全面运行在LangGraph运行时之上,原生支持持久化、检查点恢复、人类在环和有状态交互等生产级需求。此次重写旨在延续“易上手”的同时,将LangGraph的生产级能力下沉到框架层,提供了更标准的内容结构、更克制的代理组合、更可编排的中间件体系,以及对生产级交互的原生支持。
怜星夜思:
2、文章提到LangChain的核心是“模型与基础设施中立”,并且集成了超过700个不同的集成。这种策略在LLM领域快速发展初期,无疑加速了普及。但过度集成是否也会带来维护成本高昂、项目显得臃肿等问题?这种“大而全”的策略在长期来看是否可持续,以及它如何与新版1.0中“精简代理选项”的决策统一起来?
3、LangChain公司有三条主要产品线:开源的LangChain、LangGraph和闭源的LangSmith(作为主要收入来源)。这种“开源+闭源”混合的商业模式在LLM时代非常普遍。大家怎么看待这种模式的利弊?对于一个长期依赖于社区贡献的开源项目来说,闭源产品的成功是否会影响社区的积极性,或者说如何才能更好地平衡这二者?
原文内容

本周,LangChain 宣布完成 1.25 亿美元融资,投后估值 12.5 亿美元。除了宣布其独角兽地位外,该公司还发布了里程碑式更新:经过 3 年迭代,LangChain 1.0 正式登场。而且,这并非一次常规的版本升级,而是一场从零开始的重写。
LangChain 是开源开发者社区中最受欢迎的项目之一,其每月下载量高达 8000 万次,数百万开发者正在使用,目前在 GitHub 上拥有 11.8 万颗 star 和 1.94 万个分支。要对这样一个普及度极高的框架进行全面“重写”,难度可想而知。

任职于 LangChain 的 Julia Schottenstein 发帖表示:
LangChain 从零开始重写 —— 现在更加精简、更灵活、更强大。各方面都大幅提升。要下决心重写这样一个已经如此普及的框架,绝非易事。 现在的 LangChain 围绕循环内的工具调用 Agent 架构构建,模型无关性是其核心优势之一。
LangChain 于 2022 年 10 月左右由机器学习工程师 Harrison Chase 发起。最初是 Harrison 的一个副业,当时他大约写了 800 行代码,是一个体量不大的单文件 Python 包,于同年秋季发布到了他个人的 GitHub 账户(hwchase17)上。
Harrison 自述,项目的灵感来源于一次特殊的时期:大约在 Stable Diffusion 发布之后、ChatGPT 问世之前的一个月里。他频繁参加各种聚会和技术活动,结识了许多利用大模型进行前沿探索的人士。
面对工具碎片化和抽象不足的状况,通过交流,他大致梳理了大家构建项目的一些共性,并意识到:“将这些共同点抽象分解出来,会是一个很酷的副项目。” 后来,这个副项目就发展成了今天的 LangChain。
最开始的版本包含三个端到端的模块。一个是 NatBot,这是 Nat Friedman 开发的 Web 代理。另一个是 LLM Math Chain。第三个是 Self-Ask,是一种 RAG 搜索,类似于 React 风格的代理。该框架的作用主要是把模型与工具连接起来,将多个调用与业务逻辑串联成链条,解决了早期大模型开发应用时的一些痛点,例如网页搜索、API 调用以及数据库交互等。
发布后,他持续迭代,接入了各种 LLM 和向量数据库等更多集成,还提供了更多高级的“模板”,使用户仅用 5 行代码就能开始使用 RAG、SQL 问答、提取等功能。
随着大模型的火热发展,LangChain 很快成为增长最快的开源项目之一。Harrison 于 2023 年 4 月以 Benchmark 领投的 1000 万美元种子轮正式创立公司。一周后,他又完成了由红杉领投的 2500 万美元 A 轮融资,当时 LangChain 的估值据称已达 2 亿美元。
即使是创始人 Harrison 本人,现在也很难准确一句话概括 LangChain 到底是什么。在一次播客中,他曾这样定义:“LangChain 是一个构建 LLM 应用程序的框架,但这说法很模糊,也不够具体。我认为部分原因在于 LangChain 的功能实在太丰富了,所以很难用一句话具体说明。”
但就优先级与侧重点而言,LangChain 的核心是一个“情境感知的推理型应用框架”。它大体包含两层:其一是组件与模块层,覆盖提示模板、LLM 与聊天模型抽象、向量存储抽象、文本分割器与文档加载器等。LangChain 本身不提供自有的大模型或向量库,但整合了大量外部实现;文本分割器与文档加载器等则有自有逻辑,均可独立组合。其二是端到端的链与应用层,例如文档问答、聊天问答、SQL 问答与“即插即用”的代理等,把前述组件按既定流程装配,帮助开发者用少量代码快速完成从检索嵌入、合成提示,到生成、解析并后处理答案的全流程。
在整合生态这件事上,团队长期坚持“模型与基础设施中立”的路线。外界曾评价他们“就像开发者领域的瑞士”:比如说那时市面上有众多向量数据库,彼此都在竞争、争夺嵌入与数据归属,而 LangChain 的态度是“我们都支持”。
Harrison 认为,他们当初最坚定的信念是,这个领域还处于非常早期的阶段,而且发展非常迅速。因此,关于向量数据库将扮演什么角色、会有多少个向量数据库,未来发展如何,都存在很多不确定性。因此他认为“可选性和可切换性是必须的,LangChain 不能被任何技术路线束缚。”
除了主流大模型、80 种向量数据库,对于“文本分割器(Text splitters)”这类的组件,Harrison 曾表示:“我记得我们有大概 15 种,我还觉得它们的数量都被低估了。”
据 2024 年 10 月的数据显示,LangChain 里有总计超过 700 个不同的集成。这其中包括 10 大类组件,每一类里通常有 30 到 100 个集成。这个领域有非常多不同的技术触点,而 LangChain 的定位,就是连接这些触点的“粘合剂”。而且他们还提供了 Python 和 TypeScript 两种版本。
这背后是大量艰苦的适配与集成工作——尤其是在团队仅约 10 人的阶段(2023 年 7 月的时候团队只有 6 个人,随后两个月增加到 10 人上下),仍投入了可观的时间去打通各种不同的组件,以保证开发者随取随用、自由组合。
然而,在这种高速集成的情况下,项目也积攒了不少问题,Harrison 透露:“(那时我们)有大约 2,500 个未解决的问题或类似的(Bug),还有 300 或 400 个待处理的 PR。”
到了 2023 年夏天,LangChain 团队开始接收到大量负面反馈。其中有些问题尚能修复,比如防止破坏性更改、显式化隐藏的提示词、解决安装包臃肿、依赖冲突以及文档过时等。
然而,有一项反馈更难处理——用户希望获得更高的控制权。虽然 LangChain 一直是开发者快速入门的最佳选择,但团队为此牺牲了部分定制化能力以换取易用性。最初,LangChain 中那些让用户快速上手的高层级接口,现在反而成了开发者试图进行定制化并推向生产环境时的阻碍。
为了解决这一痛点,LangChain 团队于同年夏天开始开发 LangGraph,并在 2024 年初正式推出。LangGraph 允许开发者以更底层的方式编排每一步智能体逻辑,包括记忆管理、人类在环(human-in-the-loop)以及持久化执行的长任务管理。
例如,Replit 在几个月前发布的智能体就是基于 LangGraph 和 LangSmith 构建的。值得一提的是,LangSmith 是 LangChain 生态中的一款闭源工具,专注于 LLM 运维领域,主要提供可观察性和监控功能,同时也是该公司的主要收入来源。
目前,LangChain 公司有三条主要产品线,工作侧重点各有不同。在 LangChain 开源方面,核心工作是生态系统的规模化管理,需要与大量的合作伙伴进行协作。在 LangGraph 方面,当前许多工作聚焦于可扩展性,以及智能体的集成开发环境(IDE)与调试能力的提升。而在 LangSmith 方面,随着承载的生产工作负载持续增加,团队会继续致力于推进其可扩展性。

截图来源:https://js.langchain.com/docs/introduction/
LangChain 在三年前发布时,其功能主要围绕着各种集成和高层接口展开。当时集成范围还比较有限,模型端主要集中在 OpenAI、Cohere 和 Hugging Face 这几家,而围绕模型、向量库、文档加载器等核心积木,LangChain 都提供了相应的组件与集成。另一块是高层接口,它让用户可以非常容易地上手,比如实现 RAG 或 SQL 问答只需短短五行代码。
团队当时判断,行业所处阶段决定了 LangChain 的首要目标:让开发者“尽快用起来”。随着生态成熟、原型走向生产,关注点随之转移。
以发布一年半后的 LangGraph 为例,它瞄准了两个核心:可控性与内建的运行时。
其一,在生产环境中,开发者需要更强的自定义与边界控制,“五行代码做 RAG”背后隐含了大量默认前提(如隐藏提示与所谓“上下文工程”),有利于入门,却不利于深度定制与规模化稳定。
其二,运行时层面,团队沉淀出三项关键设计:可持久的执行环境(局部出错不致整次作废)、检查点恢复(运行中缓存应用状态以便回溯与重启)、以及将流式交互作为一等公民(支持长任务的实时进度与互动)。
当年团队在构建 LangChain 时,像流式输出、人类在环这类能力并非一开始就具备,而是后来“回填”进去的。
几个月前,他们开始重新审视 LangChain,并决定全面重写。
这一重大决策也深受 LangGraph 开发过程的影响:在 LangGraph 的开发过程中,团队曾反思为何某些在原型期易于实现的功能,在生产环境中却难以落地。基于此,他们从架构层面提出核心要求,即运行时必须原生支持“人类在环”等关键能力——这也正是 LangGraph 的核心目标之一。
这些经验与要求,直接奠定了重写的技术方向:团队最终决定以 LangGraph 为底座,对 LangChain 进行彻底的架构重构。
两年来,整个行业里已经冒出了一堆围绕“智能体构建”的框架,但基本收敛在“智能体 = 工具调用循环(tool-calling loop)”这个概念上。因此新版 LangChain 1.0 为平衡“强可控性”与“低门槛”,提供了统一的 create_agent 抽象,让开发者用少量代码即可起步,快速搭建经典的“模型—工具调用”循环。
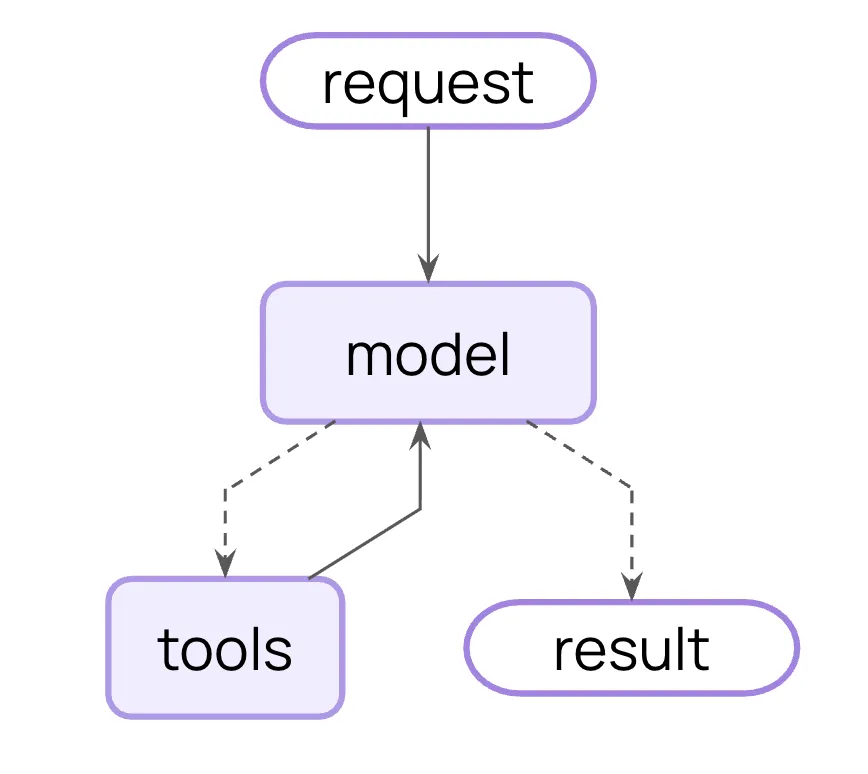
该抽象既延续了早期 LangChain 0.0.8 的 “chat agent executor” 范式,也吸收了 LangGraph 社区广泛使用的 “create_react_agent” 经验,在一致性与易用性上进一步收敛。
此外,LangChain 1.0 还添加了一个新的 中间件 概念,这也是此次重写的关键抓手。
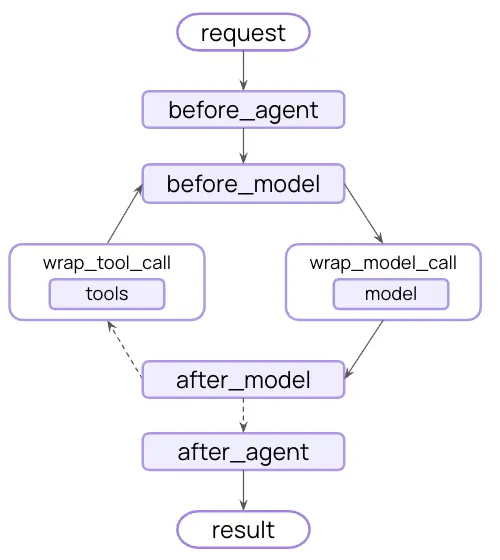
这种中间件模式允许开发者在“核心智能体循环”的任意位置插入额外逻辑,使主循环更易扩展到各类场景:例如,它可以在模型调用前自动总结历史对话,以支持长时运行带来的超长上下文;或者在高风险或高成本的工具调用处,通过添加 Hook(钩子)的方式,启用人类在环(Human-in-the-loop)审批。
LangChain 团队表示:“我们非常认可在整个智能体循环周围添加钩子的这种范式。因此,我们也让大家非常容易去构建自定义的中间件。” 团队进一步指出,如果想要定制动态提示词(dynamic prompt)或动态工具(dynamic tools),同样可以通过中间件来实现。“我们认为,这正是将 LangChain 作为一个智能体框架区别开来的地方:中间件中内建的可定制化能力。”
而且,借助 动态模型中间件(dynamic model middleware),系统还可以基于上下文动态选择要使用的模型,从而将“模型无关性”落到工程实处。
如今已非“单一模型通吃”的时代:写代码去找 Anthropic,推理(reasoning)去找 OpenAI,多模态去找 Google。某种意义上,每家模型都显现出了自己的专长领域。
团队强调,“在我们与开发者交流时,模型之间的可选性本来就是 LangChain 的初心之一。能够启用这种可选性,才是你在智能体构建上保持最前沿的方式。”中间件让系统可在对话生成或下一步循环中按需切换模型,于能力与成本之间取得更优解。
“create_agent + middleware API 是把‘上下文工程’真正落地为可操作抽象的首次清晰尝试。”
在产品层面,LangChain 1.0 做了四项系统升级:
-
引入更规范的 content blocks,在不同模型间统一输入 / 输出结构;
-
精简代理选项,仅保留经过官方打磨与背书的实现,降低选择与调参成本;
-
提出 middleware 以强化可控性与“上下文工程”;
-
全面运行在 LangGraph runtime 之上,原生支持持久化、检查点恢复、人类在环与有状态交互等生产级需求。
整体而言,LangChain 1.0 在延续“易上手”的同时,将 LangGraph 的生产级能力下沉到框架层:更标准的内容结构、更克制的代理组合、更可编排的中间件体系,以及对人类在环与有状态交互的原生支持,构成了这次重写的核心价值。
参考链接:
https://blog.langchain.com/three-years-langchain/
https://blog.langchain.com/langchain-langgraph-1dot0/
https://www.youtube.com/watch?v=NxrMgMBuxao
https://www.latent.space/p/langchain
https://www.infoq.cn/news/WHkGx30RJzlCVXWNXBNo
https://www.youtube.com/watch?v=r5Z_gYZb4Ns
声明:本文为 InfoQ 整理,不代表平台观点,未经许可禁止转载。

