斯坦福AgentFlow创新「流中学习」,多智能体协作,小模型性能逆袭GPT-4o!
原文标题:智能体系统如何「边做边学」?斯坦福团队探索在线优化的新范式
原文作者:机器之心
冷月清谈:
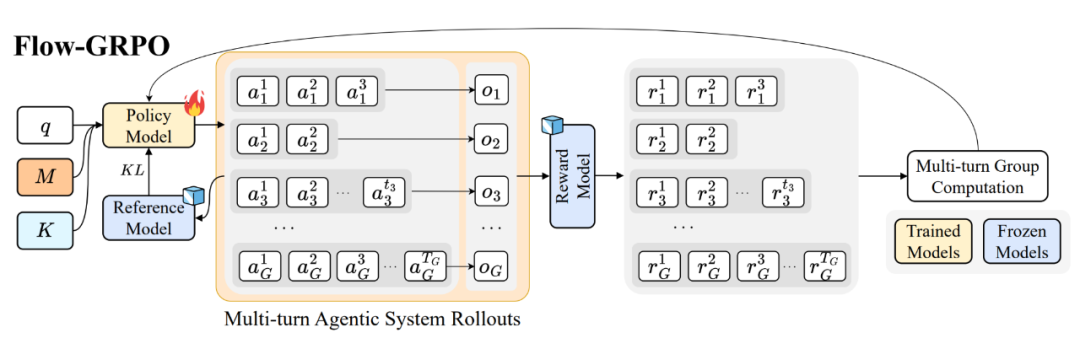
AgentFlow 的核心创新在于,规划器能够在智能体交互的“流”(flow)中进行实时的在线策略优化,即 “流中强化学习”机制,使整个系统能够在动态环境中自适应进化。为实现这一目标,团队开发了 Flow-GRPO 算法,通过将最终结果的成功或失败信号广播到每一步,有效地解决了多轮信用分配和稀疏奖励问题。
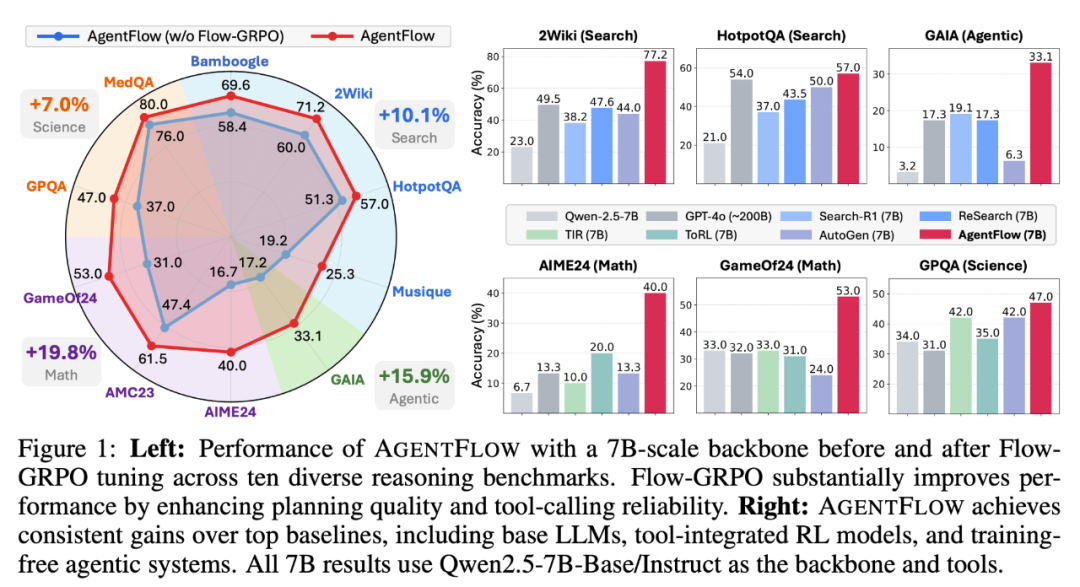
实验结果表明,AgentFlow 在知识检索、智能体任务、数学推理和科学推理等多个基准测试上取得了显著提升。特别是,使用 7B 参数的小模型 AgentFlow,在多项任务中甚至超越了约 200B 参数的 GPT-4o 和 405B 的 Llama-3.1,验证了合理系统设计和“流中学习”的重要性,而非单纯依赖模型规模。
怜星夜思:
2、AgentFlow用小模型就实现了超越大模型(如GPT-4o)的性能。这对于AI的普惠性、计算资源消耗以及未来AI模型发展的方向有什么启发?是不是意味着大家可以少“卷”模型参数量了?
3、AgentFlow通过四个专门化智能体协作实现复杂任务。在实际应用场景中,设计并协调如此复杂的智能体系统可能面临哪些挑战?比如,如何确保各模块间的无缝协作、避免内部冲突,或者更有效地处理模块故障?
原文内容

如何让智能体进行复杂推理与工具调用?传统方法主要有两类:训练单一的大语言模型,使其同时承担思考与工具调用的任务;要么依赖静态提示词驱动的 training-free 智能体系统。
然而,前者在长链推理、工具多样化与动态环境反馈下训练常变得不稳定,缺乏可扩展性(scalability);后者则缺少学习与适应能力,难以应对复杂场景。
为此,斯坦福大学联合德州农工大学(Texas A&M)、加州大学圣地亚哥分校(UC San Diego)和 Lambda 的研究团队提出了 AgentFlow 框架,通过多个独立 Agent 模块协作,并且提出 Flow-GRPO 算法用于训练。在评测中,AgentFlow 在搜索、代理、数学与科学任务上均取得显著提升,即便是 3B 模型,也能超越 405B 的 Llama-3.1 和 200B 的 GPT-4o。

该方法创新性地将智能体协作推理与强化学习融为一体,提出流中强化学习机制,让智能体系统在推理流中协同演化,形成「动态共振」效应。使其在长期规划能力、工具调用效率和动态推理深度上实现大幅提升,并在搜索、数学、科学及智能体任务等多个领域展现优秀的泛化能力。

-
项目主页: https://agentflow.stanford.edu/
-
论文链接: https://huggingface.co/papers/2510.05592
-
开源代码: https://github.com/lupantech/AgentFlow
-
开源模型: https://huggingface.co/AgentFlow
-
在线 Demo: https://huggingface.co/spaces/AgentFlow/agentflow
-
YouTube 视频: https://www.youtube.com/watch?v=kIQbCQIH1SI
该工作目前不仅在 X 上收获了超高的关注度,同时荣登 Huggingface Paper 日榜第二名!
https://x.com/lupantech/status/1976016000345919803

https://huggingface.co/papers/date/2025-10-08
研究动机:
从「单兵作战」到「团队协作」
目前,让语言模型学会使用工具进行复杂任务推理主要有两种思路:一种是训练一个「全能型」模型,让它既要思考又要调用工具,所有操作都在一个完整的上下文中交织进行;另一种是采用「智能体系统」,将任务分解给多个专门化的智能体模块协同完成。
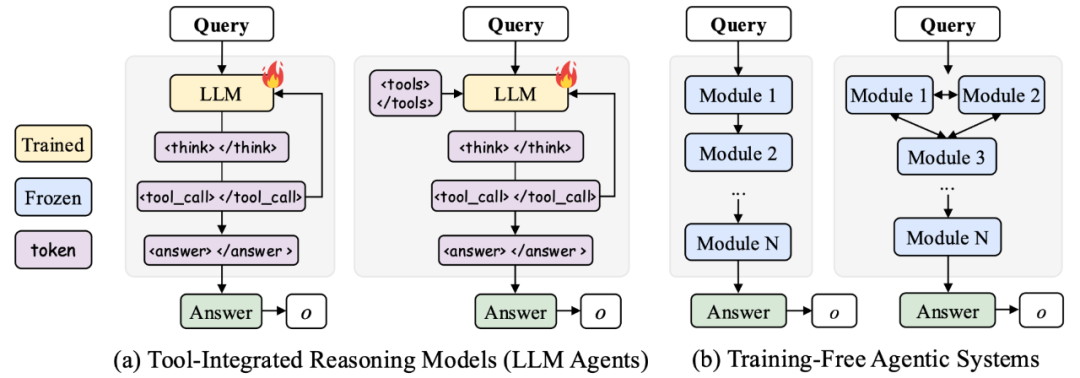
第一种方法在简单场景中表现良好,但在面对长链推理、多样化工具调用以及动态环境反馈时,训练过程往往不稳定,难以实现良好的可扩展性。第二种方法虽然具备更高的灵活性,但多数系统依赖人工设计的提示词与逻辑,缺乏从经验中自我学习与优化的能力。
这使得研究团队思考:能否让智能体系统也具备「边做边学」的能力,使其能够在交互中不断进化?
AgentFlow:
在流中学习的智能体系统
为了解决以上挑战,研究团队提出了 AgentFlow —— 一个可训练的、工具集成的智能体系统,旨在突破现有方法在可扩展性与泛化能力上的限制。AgentFlow 采用了模块化的智能体结构,由四个具备记忆能力的专门化智能体协同配合,共同完成复杂推理,从而实现「即时学习」:
-
规划器(Action Planner):分析任务、制定策略并选择最合适的工具
-
执行器(Tool Executor):调用工具集并整合工具执行结果
-
验证器(Verifier):基于系统维护的累积记忆评估中间结果是否满足目标与约束
-
生成器(Generator):整合所有信息与验证反馈,生成最终答案或行动建议
AgentFlow 的关键创新在于:规划器(Planner)并非固定不变,而是能够在智能体交互的「流」(flow)中实时进行 on-policy 优化,使决策过程随着环境变化及其他智能体的反馈不断自适应进化。通过这一机制,各模块在推理流中协同演化,使整个智能体系统在复杂环境下实现自适应推理(adaptive reasoning)与鲁棒工具调用(robust tool-calling)。

Flow-GRPO:
流中强化学习优化算法
实现智能体流中强化学习训练的核心挑战在于多轮信用分配(multi-turn credit assignment):即如何在长时跨度(long-horizon)且奖励稀疏(sparse reward)的条件下,稳定且高效地训练。为此团队提出动作级别的(Action Level)的多轮推理优化目标:
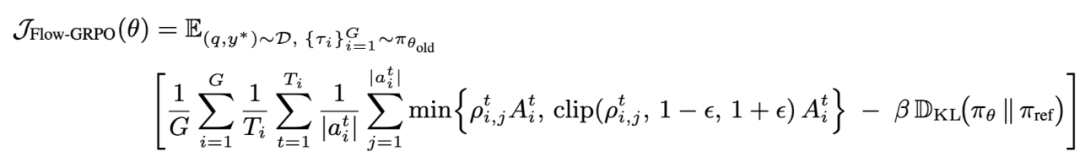
通过将轨迹最终结果的成功或失败信号(outcome reward)广播至每一步,将原本复杂的多轮强化学习问题转化为一系列可处理的单轮策略更新。该方法不仅缓解了奖励稀疏问题,还显著提升了训练效率,为智能体在复杂多轮推理中的稳定学习提供了基础。
实验结果:
AgentFlow 全面基准测试
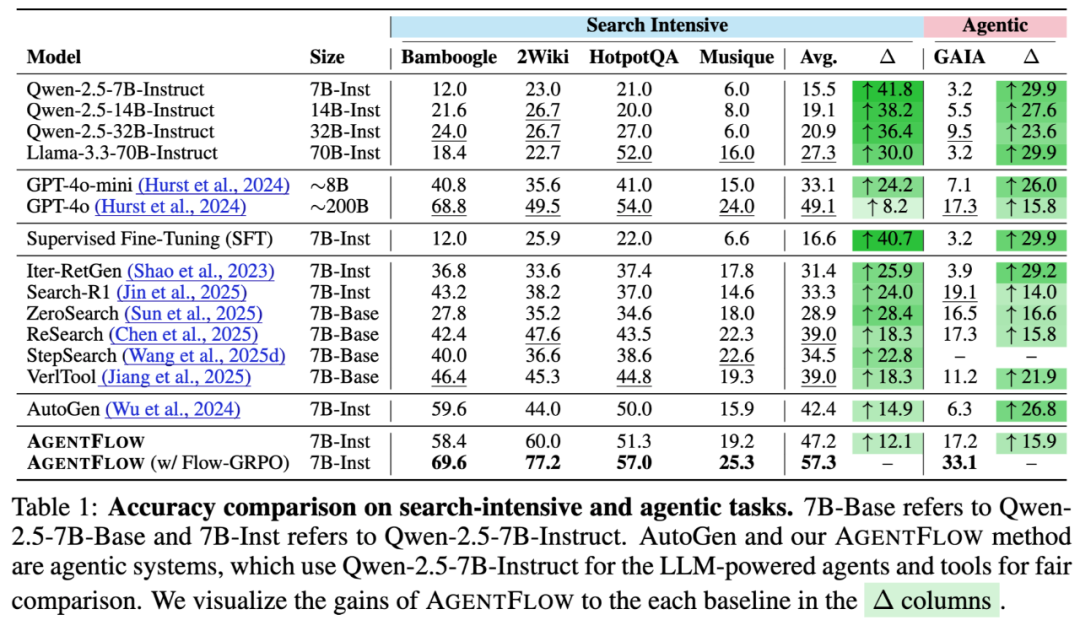
为了充分评估 AgentFlow 的泛化能力与高效性,研究团队在 10 个跨各个领域的基准测试上进行了系统评测,涵盖知识检索、智能体任务、数学推理和科学推理四大类。 以 Qwen-2.5-7B-Instruct 为基座模型的 AgentFlow 在各项基准上均超越现有领先方法:
-
知识检索(Search):提升 +14.9%
-
智能体推理(Agentic Reasoning):提升 +14.0%
-
数学推理(Math):提升 +14.5%
-
科学推理(Science):提升 +4.1%
值得注意的是,AgentFlow 的表现甚至超过了大规模的专有模型,如 GPT-4o(~200B)。

实验发现:
小模型的「大智慧」
研究团队在 10 个基准测试上进行了评估,涵盖知识检索、智能体任务、数学推理和科学推理四大类。 一些有趣的发现:
-
模型规模不是唯一答案
使用 7B 参数的 AgentFlow 在多个任务上超过了约 200B 参数的 GPT-4o,Llama3.1-405B,在搜索任务上领先 8.2%,在智能体任务上领先 15.8%。这再一次展现了,合理的系统设计和训练方法可能比单纯堆砌参数训练 All in one 的大模型更有效。
-
「在流中学习」至关重要
对比实验显示,若采用离线监督学习(SFT)方式训练规划器,性能反而显著下降,平均降低 19%。这表明,智能体在真实交互环境「流」中进行在线学习是实现高效推理的必要条件。此外,尽管 AgentFlow 的推理流本身能够利用其强大的任务分解能力带来显著性能提升,但仍可能出现循环错误或卡顿问题。通过在真实环境中的训练,智能体系统展现出快速修正错误的工具调用、更精细的子任务规划,以及全局任务解决性能的提升。
这些结果进一步证明了模块协作机制以及流中强化学习在提升多轮智能体系统稳定性与效率方面的显著作用。


-
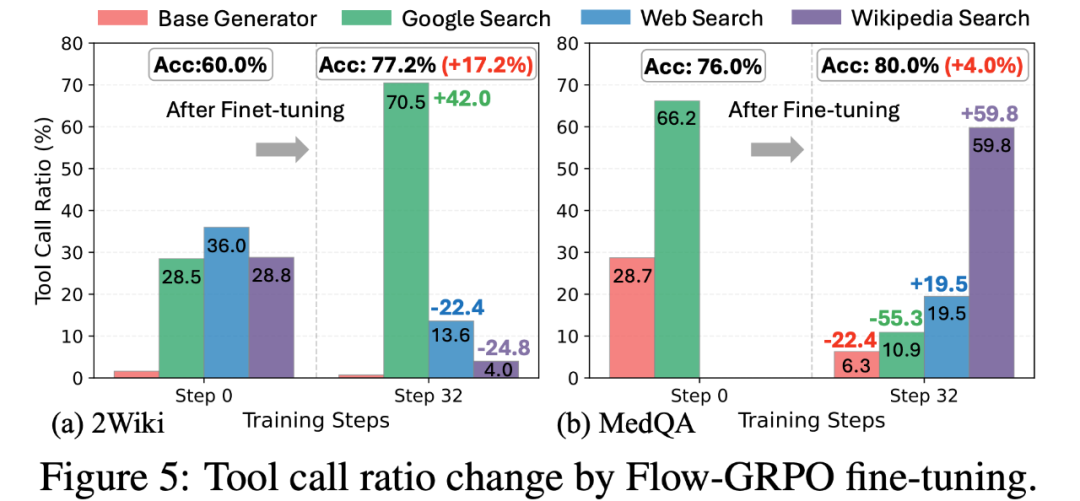
自主发现新的解决路径
有意思的是,经过 Flow-GRPO 的强化训练规划器,系统学会了根据任务特点选择合适的工具组合;同时,经过训练的系统会自发探索出新的工具使用模式,比如组合使用维基百科搜索(Wikipedia Search)和特定网页增强搜索(Web Search)的连招,通过工具链获得更加深入地信息挖掘,而这些模式几乎没有在未训练的推理流中出现。
-
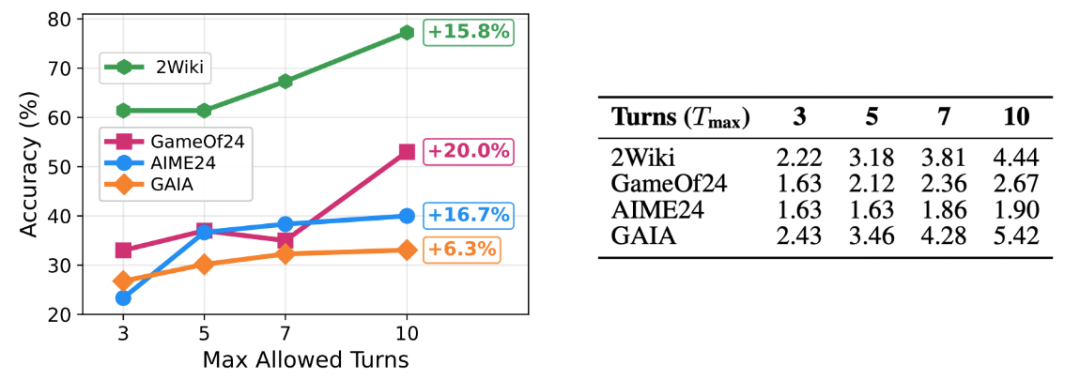
动态推理深度与性能提升
对于相同的数据集下的不同难度任务:譬如说多跳搜索(Multihop Search),智能体任务中的密集长链推理任务,AgentFlow 在经过 Flow-GRPO 训练后能够随着最大限制推理步数的上升稳步提升性能,同时又不会大幅提升平均推理步数——这表示对于长难任务会增加有效的推理步数来提升正确率,而不会一味地所有任务都随着最大轮数限制而延长推理步数。
结语
AgentFlow 为智能体训练提供了一种全新的思路:与其追求一个功能完备的单一大语言模型或「一次性完美」的智能体系统,不如让智能体在系统中自我适应与持续学习。通过将群体智能与「边做边学」的范式相结合,AgentFlow 使智能体系统能够在协同演化中不断优化,从而高效应对复杂任务。
尽管从研究探索到实际应用仍有较长的距离,但这样的工作让我们看到:Agentic AI 依然蕴藏着巨大的潜力与想象空间。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com