阿里云通义大模型家族全面升级,六款新模型及企业级语音基座发布,覆盖文本、视觉、语音、视频、代码、图像全场景智能应用,能力突破显著。
原文标题:你们催更的模型,云栖大会一口气全发了!
原文作者:阿里云开发者
冷月清谈:
具体来看,此次发布涵盖了多个关键领域:
**Qwen MAX**是一款参数规模超万亿的旗舰大模型,在编码与工具调用能力上表现卓越,于SWE-Bench Verified评测中得分69.6,并在国际权威数学评测AIME25中斩获满分,展现了强大的理科推理能力,支持即时交互与并行推理。
**Qwen3-Omni**是新一代原生全模态大模型,原生支持19种语言及方言输入、10种语言输出,能够处理长达30分钟的会议录音,并承诺“全模态不降智”。它采用Thinker-Talker MoE架构,在音频识别、语音生成、图像理解等多项任务上超越了Qwen2.5-Omni和GPT-4o。该模型还支持无缝嵌入车机、智能音箱等系统,实现复杂指令的精准执行。
**Qwen3-VL**作为视觉理解模型,真正实现了“看懂世界、理解事件、做出行动”,支持2小时视频精确定位,OCR语言能力扩展至32种,原生支持256K上下文并可扩展至100万token。其强化了视觉智能体、可视化编程、空间感知以及超长视频与行为分析等能力,在安全感知与风险预警方面也有显著提升。
**Qwen-Image-Edit-2509**(Qwen-Image)是图像编辑专家,本次升级支持多图参考编辑,显著强化了人脸、商品和文字的ID一致性。它原生集成ControlNet,实现了“改字不崩脸、换装不走样”的工业级稳定性,满足电商、设计等高要求场景。
**Qwen3-Coder**作为上下文代码专家,通过Agentic Coding联合训练,TerminalBench分数大幅提升,支持256K上下文,可一次性理解并修复项目级代码库,推理更快、消耗更少、安全性更高,被誉为“可一键修复复杂项目的负责任AI”,并支持多模态输入生成代码。
**Wan2.5-Preview**(通义万相2.5预览版)作为音画同步创意引擎,首次原生支持音画同步视频生成,时长提升至10秒,并全面提升了视频生成、图像生成(包括科学图表与艺术字)、图像编辑三大核心能力,满足商业级内容生产需求。
最后,阿里云还发布了全新品牌**通义百聆**,一款企业级语音基座大模型。它整合了Fun-ASR语音识别大模型和Fun-CosyVoice语音合成大模型,通过Context增强架构,将语音识别幻觉率从78.5%大幅降至10.7%,并彻底解决了串语种问题,支持热词动态注入和跨语种语音克隆,覆盖10+行业场景,致力于攻克复杂环境下的语音落地应用难题。
这些模型现在已同步上线魔搭、GitHub、Hugging Face平台,并可通过阿里云百炼平台API调用体验。
怜星夜思:
2、Qwen3-Omni和Qwen3-VL都提到很强的多模态能力,一个强调音视频+多语言,一个强调看懂世界+超长视频。大家觉得这两者如果结合起来,能在未来现实生活中解决哪些目前看起来很科幻的问题?比如给机器人做“眼睛和耳朵”,或者实现AR眼镜的“超能力”?
3、文本里提到Qwen3-Coder能“一键修复复杂项目”还强调“负责任AI”,Qwen-Image也说“改字不崩脸”。这种越来越强的AI生成和修改能力,未来会对程序员、设计师这类创意职业产生什么影响?大家是期待它成为辅助神器,还是有点担心饭碗问题?
原文内容
-
Qwen MAX:万亿参数大模型,Coding 与工具调用能力登顶国际榜单;
-
Qwen3-Omni:新一代原生全模态大模型,真正实现“全模态不降智”;
-
Qwen3-VL:Agent 和 Coding能力全面提升,真正“看懂、理解并响应世界”;
-
Qwen-Image:再升级!真正实现“改字不崩脸、换装不走样”;
-
Qwen3-Coder:256K上下文修复项目,TerminalBench分数大幅提升;
-
Wan2.5-Preview:音画同步视频生成,图像支持科学图表与艺术字;
-
通义百聆:企业级语音基座大模型,攻克企业落地语音模型的“最后一公里”;
接下来,我们将对这些模型逐项拆解,带你了解各模型核心能力与关键升级。
Qwen MAX
万亿参数旗舰模型
Qwen3-Max 是一款参数规模超万亿的大模型,智能水平相比开源 235B 版本有显著提升。Coding 能力在 SWE-Bench Verified 评测中得分69.6 ,工具调用能力在 BFCL 和 TAU2 评测中达到国际前沿水平。理科推理能力方面,在 AIME25 评测中斩获满分100分。
快速了解
-
Instruct:适用于代码生成、工具调用等即时交互任务;
-
Thinking:支持结合工具的并行推理与工具调用,Qwen3-Max推理能力创下新高,在 AIME25 和HMMT等国际权威数学评测中均斩获满分100 分。
在 AIME25(数学推理)评测中得分 81.6,显著高于 Qwen3-235B-A22B 的 70.3 分;在 SWE-Bench Verified(代码生成)中得分为 69.6。
在 SuperGPQA、LiveCodeBench、τ²-Bench 等任务上均优于 Qwen3-235B-A22B,展现更强的通用智能与编程能力。
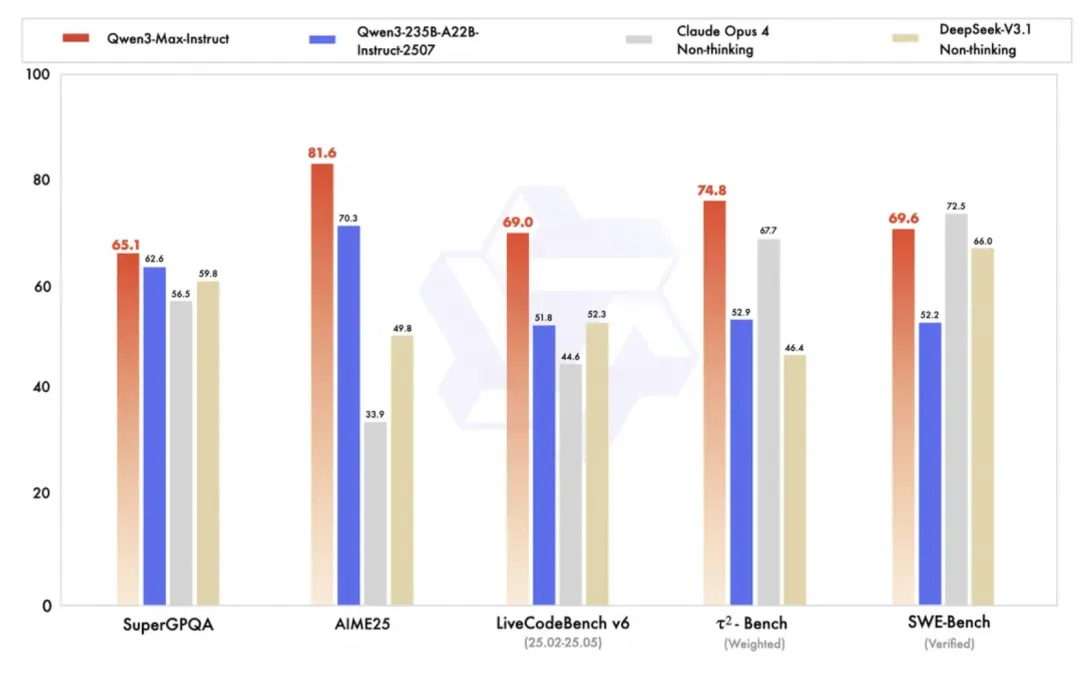
图1:Qwen3-Max 多个权威评测基准性能对比图
Qwen3-Omni
新一代全模态大模型
Qwen3-Omni 是通义全新发布的全模态大模型,支持 19 种语言及方言输入、10 种语言输出,可处理长达 30 分钟的会议录音或播客,精准输出纪要。
模型采用 Thinker-Talker MoE 架构,在支持音视频、图像等多模态能力的同时,文本智力不打折。原生支持 Function Call 与 MCP 协议,可无缝嵌入车机、智能音箱等语音助手系统,实现“打开座椅加热并导航到公司”这类复合指令的精准执行。闭源版提供 17 种拟人音色,每种音色支持 10 语种自然表达,满足全球化企业交互需求。
该版本在音频识别、语音生成、图像理解等任务上全面超越 Qwen2.5-Omni 与 GPT-4o。在 VoiceBench-CommonEval 上得分达 90.8,展现极强的语音理解与对话能力。
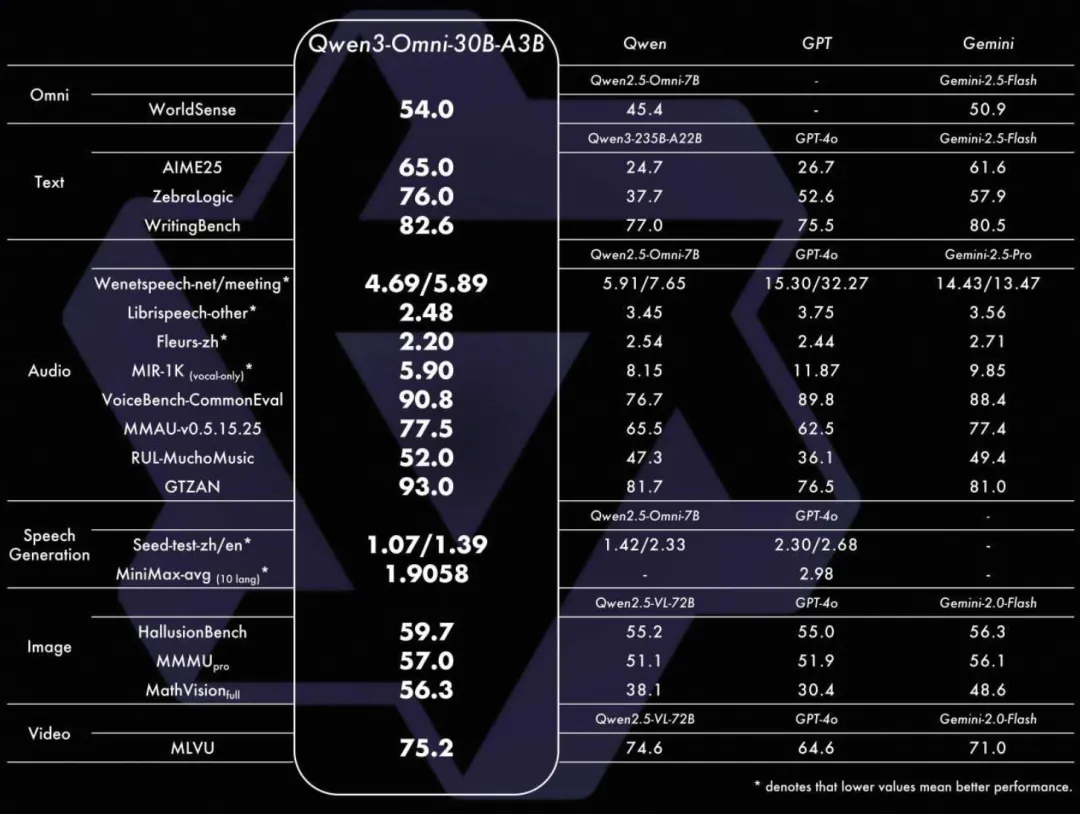
图2:在开闭源评测中 22 项达 SOTA 水平
该版本在 AIME25、ZebraLogic 等文本推理任务上得分更高,语音生成(MiniMax-avg)达到 2.5803,优于 Qwen2.5-Omni 与 GPT-4o。同时,在 VoiceBench-CommonEval 上得分为 91.0,语音理解能力进一步提升,为车机、智能助手等高要求场景提供更强支持。
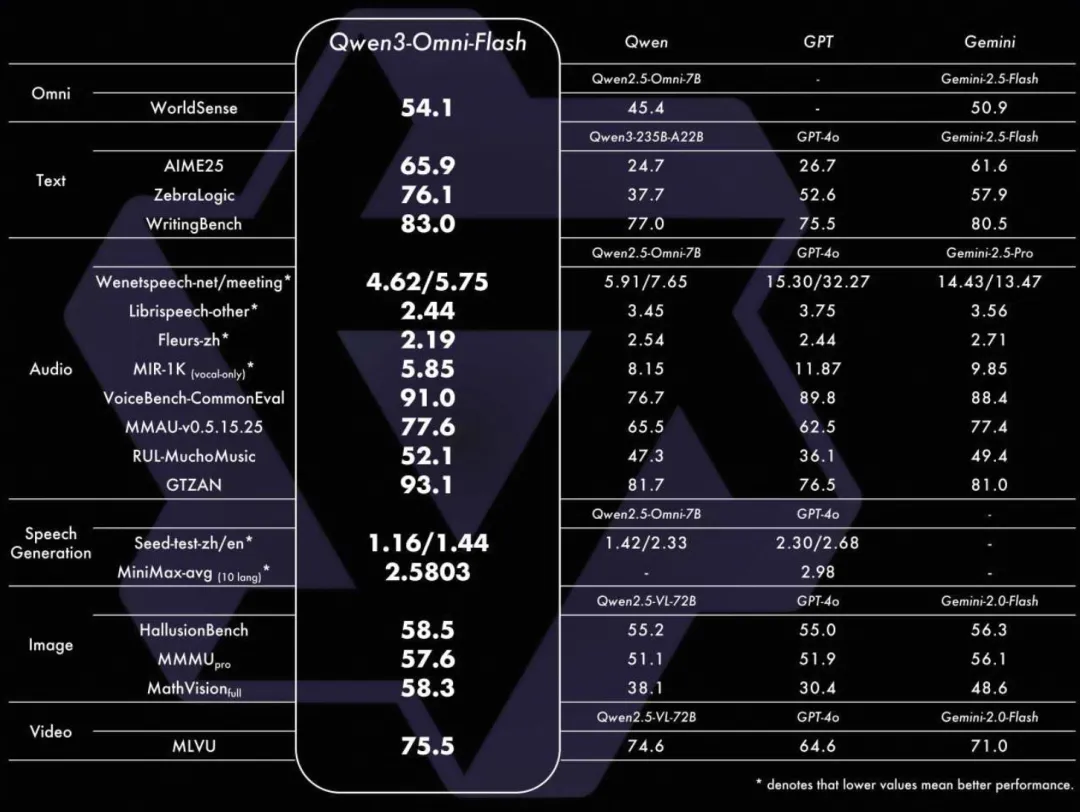
图3:多项指标领先开源模型
语种和方言(19种)
-
阿拉伯语、粤语、中文、荷兰语、英语、法语、德语、印尼语、意大利语、日语、韩语、马来语、葡萄牙语、俄语、西班牙语、泰语、土耳其语、乌尔都语、越南语。
语音生成(10种)
-
支持的语种:中文、英语、法语、德语、俄语、意大利语、西班牙语、葡萄牙语、日语、韩语
-
支持的方言:闽南语、吴语、粤语、四川话、北京话、南京话、天津话、陕西话
语音翻译(54种)
-
xx2En (任意语言 → 英文)
-
xx2Zh (任意语言 → 中文)
-
En2xx (英文 → 任意语言)
-
Zh2xx (中文 → 任意语言)
其中,xx(任意语言)包含的语言有:中文、英语、韩语、日语、德语、法语、意大利语、西班牙语、葡萄牙语、印尼语、泰语、阿拉伯语、粤语、越南语等。
Qwen3-VL
“看懂、理解并响应世界”的视觉理解模型
Qwen3-VL 是一款真正实现“看懂世界、理解事件、做出行动”的视觉理解模型,支持 2 小时视频精确定位(如“第15分钟穿红衣者做了什么”),OCR 语言从 19 种扩展至 32 种,生僻字、古籍、倾斜文本识别率显著提升。原生支持 256K 上下文,可扩展至 100 万 token,适配超长视频与文档分析。
256K 内定位准确率100%,1M仍达99.5%。
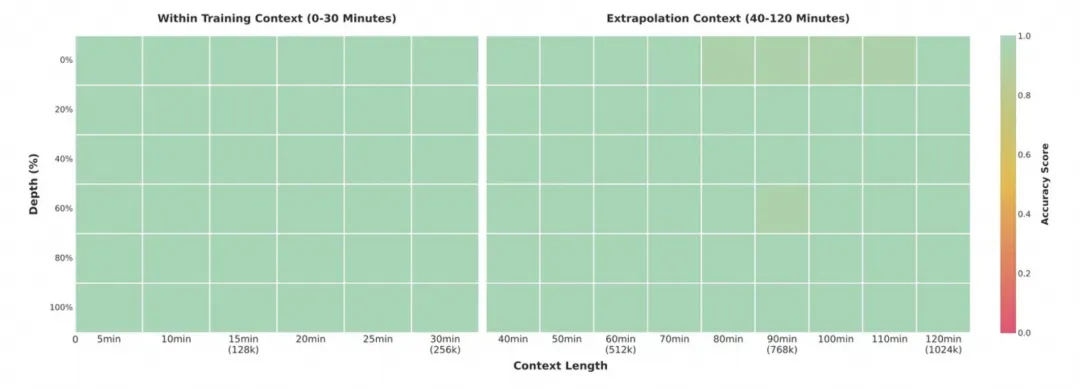
图4:2小时“视频大海捞针”测试
本次发布重点强化以下能力:
-
视觉智能体:可操作电脑和手机界面,识别 GUI 元素、理解按钮功能、调用工具并执行任务,在 OS World 等评测中达到世界顶尖水平;
-
可视化编程:看到 UI 设计图或流程图,可直接生成 HTML/CSS/JS 代码或 Draw.io 图表,大幅提升产品与开发协作效率;
-
空间感知与 3D Grounding:支持判断物体方位、视角变化与遮挡关系,为具身智能、机器人导航、AR/VR 等场景提供底层支持;
-
超长视频理解与行为分析:不仅能理解 2 小时视频内容,还能精准回答“第15分钟穿红衣者做了什么”“球从哪个方向飞入画面”等时序与行为问题;
-
Thinking 版本强化 STEM 推理:在 MathVista、MathVision、CharXiv 等评测中达 SOTA 水平,可精准解析科学图表、公式与文献图像;
-
视觉感知全面升级:优化预训练数据,支持“万物识别”——从名人、动漫角色、商品、地标到动植物,覆盖生活与专业场景;
-
多语言 OCR 与复杂场景支持:语言扩展至 32 种,复杂光线、模糊、倾斜文本识别更稳定,生僻字、古籍字、专业术语召回率显著提升;
-
安防感知与风险预警:在家庭、商场、街区、道路等真实场景中,对风险人物与事件的检测准确率达到行业领先水平;
-
长上下文原生支持:256K 起步,可扩展至 100 万 token,支持整本教材、数小时会议录像的全程记忆与精准检索。
Qwen-Image-Edit-2509
开源图片编辑专家
本次升级核心亮点:
-
多图编辑支持:对于多图输入,Qwen-Image-Edit-2509 基于Qwen-Image基模,不仅能够处理各种单图编辑场景,而且全新支持了多种多图编辑场景,提供“人物+人物”,“人物+商品”,“人物+场景” 等多种新玩法。
-
单图编辑一致性增强:对于单图编辑场景,Qwen-Image-Edit-2509 相比之前,显著提高了各个维度的一致性,主要体现在以下方面:
-
人物编辑一致性增强:增强人物ID保持,支持各种风格肖像、姿势变换;
-
商品编辑一致性增强:增强商品ID保持,支持各种商品海报编辑;
-
文字编辑一致性增强:除了支持文字内容修改外,还支持多种文字字体、色彩以及材质编辑;
-
原生支持ControlNet:支持包括深度图、边缘图、关键点图等引导信息。
本次更新单图输入编辑的一致性获得了显著增强,并且支持了多图输入编辑。

图5:Qwen-Image-Edit-2509图像编辑的样例
Qwen3-Coder
上下文代码专家
Qwen3-Coder 本次迎来能力升级,通过 Agentic Coding 联合训练优化,TerminalBench 分数大幅上涨,在 OpenRouter 平台一度成为全球第二流行的 Coder 模型(仅次于 Claude Sonnet 4)。支持 256K 上下文,可一次性理解并修复整个项目级代码库,推理速度更快、Token 消耗更少、安全性更高,被开发者誉为“可一键修复复杂项目的负责任 AI”。
本次升级核心亮点:
-
Agentic Coding 联合训练:与 Qwen Code 或 Claude Code 联合优化,在 CLI 应用场景效果显著提升;
-
项目级代码理解:256K 上下文支持,可处理跨文件、多语言的复杂项目;
-
推理效率优化:相比上代模型,推理速度更快,用更少 Token 达成更优效果;
-
代码安全性提升:强化漏洞检测与恶意代码过滤,迈向“负责任的 AI”;
-
多模态输入支持:搭配 Qwen Code 系统,支持上传截图+自然语言指令生成代码,全球领先。
在 SWE-Bench Verified 上得分达70.3;TerminalBench 与 SecCodeBench 也显著上涨,展现更强的 CLI 应用生成与安全修复能力。
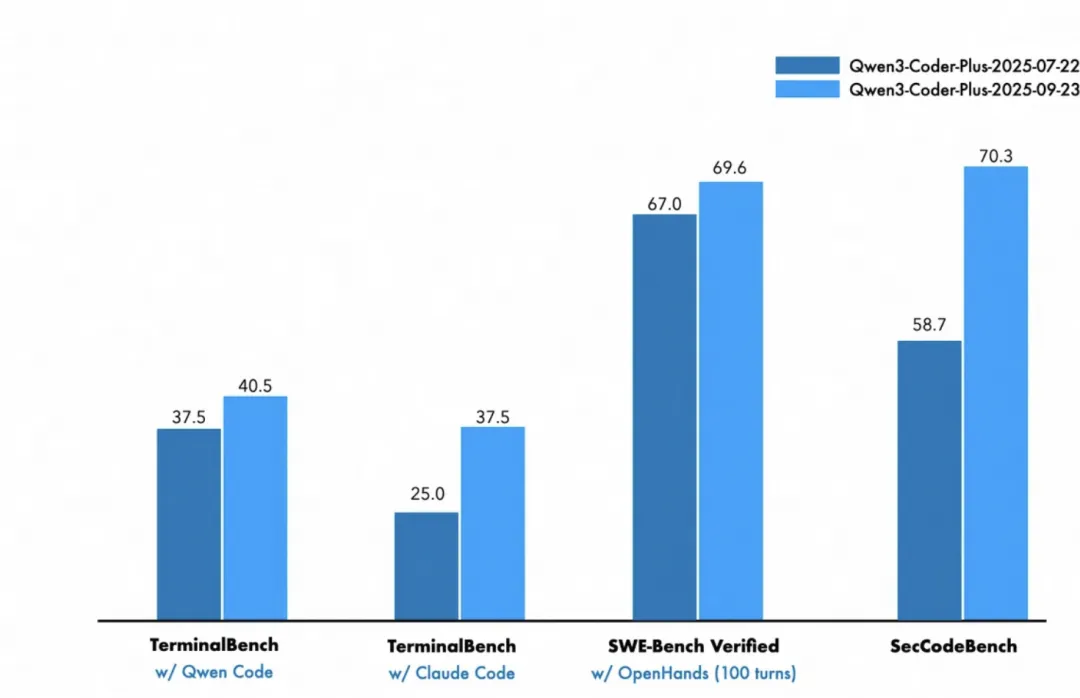
图6:Qwen3-Coder Plus 代码能力对比图
Wan2.5-Preview
音画同步创意引擎
通义万相 2.5 preview 版上线,首次原生支持音画同步,全面提升视频生成、图像生成、图像编辑三大核心能力,满足广告、电商、影视等商业级内容生产需求。
🎬 视频生成 —— 会“配音”的10秒电影
-
原生音画同步:视频自带人声(多人)、ASMR、音效、音乐,支持中文、英文、小语种及方言,画面与声音严丝合缝;
-
10秒长视频生成:时长提升1倍,最高支持1080P 24fps,动态表现力与结构稳定性大幅提升,叙事能力跃升;
-
指令遵循提升:支持复杂连续变化指令、运镜控制、结构化提示词,精准还原用户意图;
-
图生视频保 ID 优化:人物、商品等视觉元素一致性显著提升,商业广告与虚拟偶像场景可用;
-
通用音频驱动:支持上传自定义音频作为参考,搭配提示词或首帧图生成视频,实现“用我的声音讲你的故事”。
🖼️ 文生图 —— 能“写字”的设计大师
-
美学质感提升:真实光影、细节质感表现力增强,擅长不同艺术风格与设计质感还原;
-
稳定文字生成:支持中英文、小语种、艺术字、长文本、复杂构图精准渲染,海报/LOGO一次成型;
-
图表直接生成:可输出科学图表、流程图、数据图、架构图、文字内容表格等结构化图文;
-
指令遵循提升:复杂指令精细化理解,具备逻辑推理能力,可精准还原现实IP形象与场景细节。
✂️ 图像编辑 —— “改字不崩脸”的工业级修图
-
指令编辑:支持丰富编辑任务(换背景/改颜色/加元素/调风格),指令理解精准,无需专业PS技能;
-
一致性保持:支持单图/多图参考垫图,人脸、商品、风格等视觉元素ID强保持,编辑后“人还是那个人,包还是那个包”。
通义百聆
企业级语音基座大模型
支持热词动态注入与跨语种语音克隆,行业术语 100% 准确召回。Fun-CosyVoice 语音合成大模型采用创新性的语音解耦训练方法,大幅提升音频合成效果,并支持跨语种语音克隆。
核心能力速览:
-
幻觉率大幅下降:通过 Context 增强架构,将 CTC 初筛结果作为 LLM 上下文,幻觉率从 78.5% 降至 10.7%,输出更稳定可靠;
-
彻底解决串语种问题:CTC 解码文本输入 LLM Prompt,极大缓解英文录音输出中文等“自动翻译”现象;
-
强定制化能力:引入 RAG 机制动态注入术语库,支持人名、品牌、行业黑话(如“ROI”“私域拉新”)精准识别,5分钟完成配置;
-
跨语种语音克隆:采用多阶段训练方法,一个音色可说遍全球,声音相似度行业领先;
-
行业场景全覆盖:基于数千万小时真实音频训练,覆盖金融、教育、制造、互联网、畜牧等 10+ 行业,深入产业一线。
现阶段所有的模型已经同步上线,你可以进入魔搭、GitHub、Hugging Face 搜索模型名,一键部署,还可以登陆阿里云百炼平台调用 API,快去体验吧~