UniVid:融合视频理解与生成,实现通用视频AI,性能超越SOTA。
原文标题:告别「偏科」,UniVid实现视频理解与生成一体化
原文作者:机器之心
冷月清谈:
怜星夜思:
2、UniVid采用Adapter-based架构降低了训练开销,但对于我们普通开发者或小型团队来说,想尝试复现或基于UniVid做二次开发,会面临哪些主要的技术挑战?比如,除了算力,还有数据、算法理解等方面的问题吗?
3、视频生成技术越来越强大,像UniVid这种能“理解”还能“生成”的模型,在带来便利的同时,也肯定会有一些潜在的伦理和安全风险。大家觉得有哪些方面需要特别警惕,或者作为普通用户我们能做些什么来保护自己?
原文内容

在视频生成与理解的赛道上,常常见到分头发力的模型:有的专注做视频生成,有的专注做视频理解(如问答、分类、检索等)。而最近,一个开源项目 UniVid,提出了一个「融合」方向:把理解 + 生成融为一体 —— 他们希望用一个统一的模型,兼顾「看懂视频」+「生成视频」的能力。

这就像把「看图识物」和「画图创作」两件事,交给同一个大脑去做:理解一段文字 + 理解已有视频内容 → 再「画」出新的、连贯的视频 —— 这在技术上挑战极大。

-
论文标题:UniVid: The Open-Source Unified Video Model
-
论文地址:https://arxiv.org/abs/2509.24200
UniVid 想解决什么问题?
UniVid 尝试把视频「理解」与「生成」融合为一体,构建出一个真正通用的统一视频模型(Unified Video Model),一个既能「理解」又能「生成」的视频多模态模型。
核心创新
1.统一结构:Adapter-based Unified Architecture
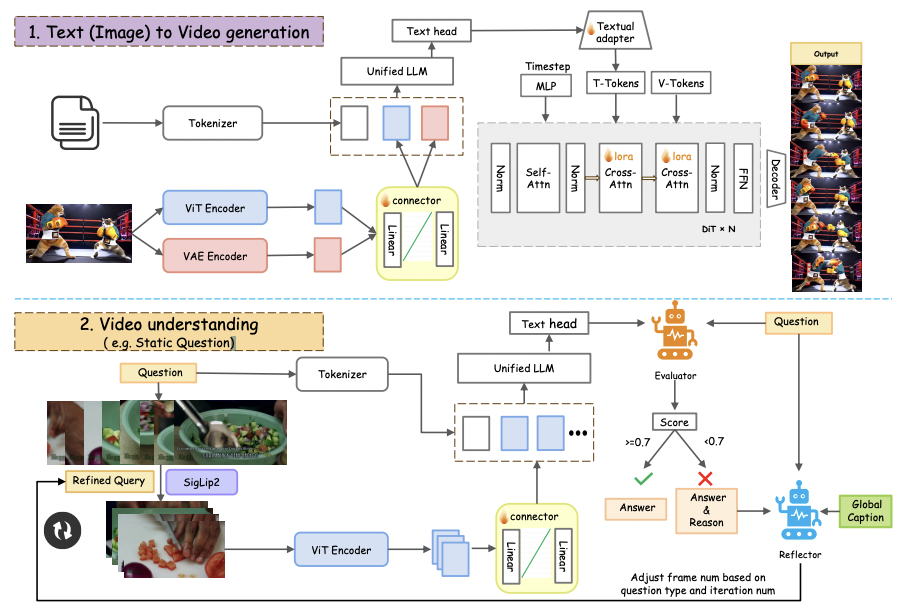
在传统方案中,理解模型和生成模型是完全分开的系统,训练开销大、互通困难。要把它们融合,需要重新训练一个庞大的联合模型,成本极高。
本文采用适配器(Adapter)插入机制,在已有多模态大语言模型中插入轻量模块,使其具备视频生成能力。这样,理解模块 + 生成模块可以共享大部分参数,只需训练少量新增参数。
优势:
-
显著降低训练开销与算力成本;
-
提高模型扩展性:已有理解能力的模型能「平滑地」插入生成能力;
-
兼顾理解与生成,不牺牲已有强大的视觉 / 语言理解基础。
2. 温控对齐:Temperature Modality Alignment
在跨模态(文本 → 视频)生成中,文本与视觉之间表示尺度、语义强度往往不匹配。若直接融合注意力或特征,很容易出现「提示偏移」(Prompt Drift):生成的视频越偏离最初的文字意图。
本文提出模态温度对齐机制(Temperature Modality Alignment)。在跨模态注意力层中对不同模态(文本 / 视觉特征)引入温度系数(类似 softmax 温度调节),动态调节它们的注意力权重与融合强度。在生成过程的早期阶段,更高权重给文本提示以加强语义引导;在后期阶段,则逐渐让视觉特征主导细节优化。
这能够有效减少提示偏移,提高语义一致性;让模型在「理解 → 生成」过程中过渡更自然;保证最终视频既符合提示,又具备高质量视觉细节。
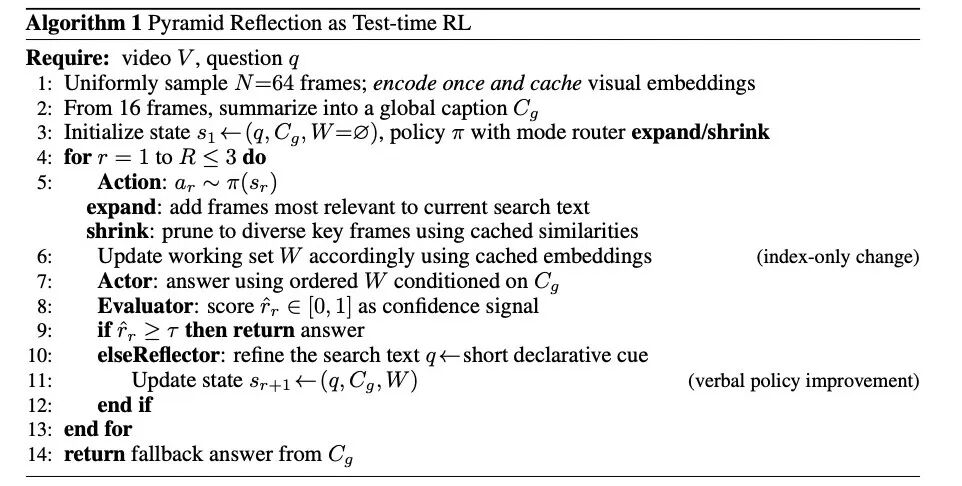
3. 金字塔反射:Pyramid Reflection
视频是时序数据,理解和建模长时域依赖(远帧之间的关联)成本极高。传统 Transformer 全帧注意力的计算量呈平方级增长,难以扩展。
本文提出金字塔反射机制(Pyramid Reflection):
-
在理解任务中采用 Reflector 模块,通过动态选择关键帧,并在金字塔层次上进行「反射 / 聚合」操作;
-
将帧序列映射到不同时间尺度,自底向上或自顶向下反射信息,使模型能在多个尺度上捕捉时序关系。
在视频 QA / 时序理解任务中,PR 模块结合 Actor – Evaluator – Reflector 循环结构,让模型能用最少的帧达到准确推理结果。
实验结果:打败 SOTA?
UniVid 在视频生成与理解两大方向上,都达到了同级模型最优表现。
1. 视频生成:VBench 全维度刷新记录
测试基准:VBench-Long,是目前最严格的视频生成综合评测集,涵盖多个维度:
-
技术质量(Technical Quality)
-
美学质量(Aesthetic Quality)
-
语义一致性(Semantic Fidelity)
-
对象 / 动作 / 场景 / 时序等细粒度指标
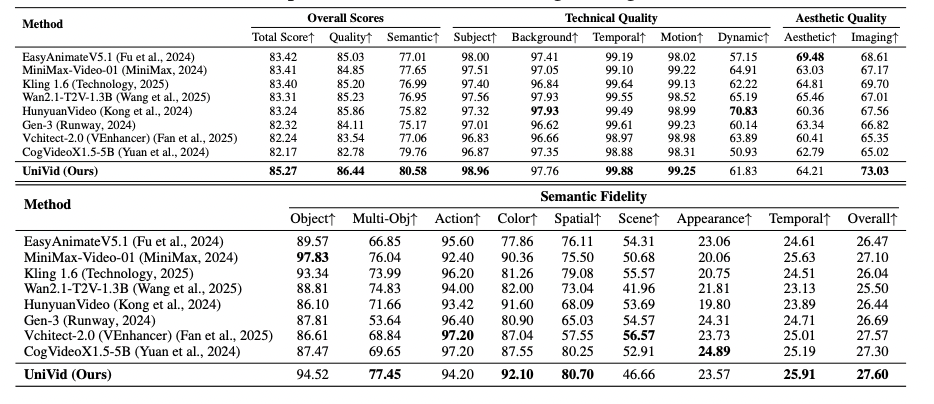
UniVid 的成绩不仅在总分上超越所有主流视频生成模型,更在关键维度上超越同级:
-
Temporal Consistency(时序一致性):99.88(几乎满分);
-
Motion Smoothness(运动平滑度):99.25;
-
Semantic Alignment(语义一致性):80.58(领先 EasyAnimate 的 77.01);
-
Imaging Quality(影像质量):73.03(显著高于其他模型)。
UniVid 在生成的同时,极大提升了语义契合度与画面连贯性。

与顶尖视频生成模型的比较
2. 视频理解:多项问答任务登顶
在视频问答(Video Question Answering, Video-QA)任务中,UniVid 同样登顶多个主流基准。
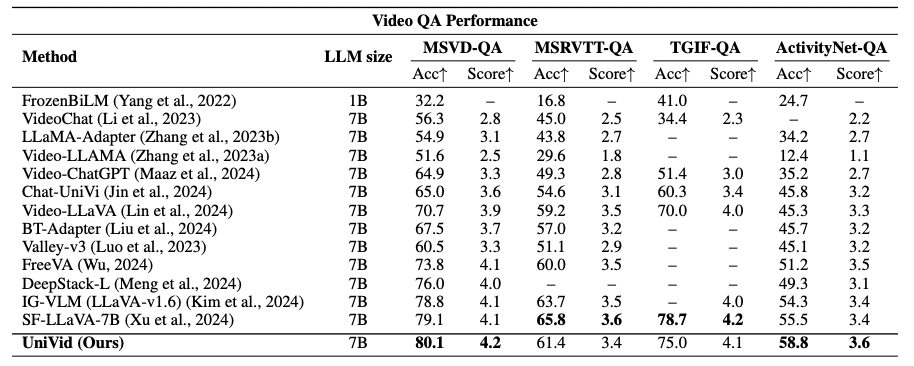
UniVid 在 MSVD-QA 和 ActivityNet-QA 上均创造新纪录,并在更复杂的长时序视频上展现出卓越的时序推理与语义理解能力。

与顶尖视频生成模型的比较
Demo 展示
为了让大家更直观地理解 UniVid 的能力,研究团队还准备了视频 Demo,涵盖视频生成和视频理解两类任务。
视频生成:
从左到右的 prompt 分别是:
-
Mouse with large teeth aggressively eating cheese.
-
A white cat in sunglasses relaxes on a surfboard at the beach under a sunny sky.
-
Ten fluffy kittens eat breakfast together in warm sunlight.
视频理解:
应用价值与意义
1. 视频创作与生成
在影视、广告、短视频等场景中,创作者只需输入文字脚本或图像提示,UniVid 就能自动生成连贯、符合语义逻辑的视频。它能「理解」剧情后再去「创作镜头」,让内容生产更自然、更高效。
2. 视频理解与分析
UniVid 还能看懂视频。无论是体育赛事、监控画面还是教学视频,它都能识别动作、人物、事件逻辑,生成精准摘要或问答结果。让机器不仅看到画面,更「理解故事」。
3. 机器人与具身智能
在机器人导航、自动驾驶或智能体系统中,UniVid 可以理解摄像头输入并生成未来场景预测,帮助智能体进行规划与决策。它让机器人不仅「看得到」,还能「想得出下一步」。
4. 开源生态与科研价值
与闭源视频模型不同,UniVid 的代码开源,任何研究者或开发者都可自由使用、复现、二次开发。它为视频智能研究提供了一个通用底座,也让产业界能以更低成本构建自己的视频生成系统。
作者介绍
罗嘉滨是北京大学软微与微电子学院在读博士生,研究兴趣为多智能体系统、多模态生成、RAG、AI 安全。曾参与多项科研项目,长期致力于构建安全可信的 AGI。
林峻辉是北京师范大学在读本科生,AI Geek 成员,研究兴趣为图像,视频生成与处理。曾参与多项科研项目,积极探索有趣且有用的计算机视觉模型。
张泽宇是 Richard Hartley 教授和 Ian Reid 教授指导的本科研究员。他的研究兴趣扎根于计算机视觉领域,专注于探索几何生成建模与前沿基础模型之间的潜在联系。张泽宇在多个研究领域拥有丰富的经验,积极探索人工智能基础和应用领域的前沿进展。
唐浩现任北京大学计算机学院助理教授 / 研究员、博士生导师、博雅和未名青年学者,入选国家级海外高水平人才计划。曾获国家优秀自费留学生奖学金,连续三年入选斯坦福大学全球前 2% 顶尖科学家榜单。他曾在美国卡耐基梅隆大学、苏黎世联邦理工学院、英国牛津大学和意大利特伦托大学工作和学习。长期致力于人工智能领域的研究,在国际顶级期刊与会议发表论文 100 余篇,相关成果被引用超过 10000 次。曾获 ACM Multimedia 最佳论文提名奖,现任 ICLR 2026、ACL 2025、EMNLP 2025、ACM MM 2025 领域主席及多个人工智能会议和期刊审稿人。
-
更多信息参见个人主页: https://ha0tang.github.io/

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com