机器之心编辑部
RLHF 通过学习人类偏好,能够在难以手工设计奖励函数的复杂决策任务中学习到正确的奖励引导,得到了很高的关注,在不同环境中选择合适的人类反馈类型和不同的学习方法至关重要。
然而,当前研究社区缺乏能够支持这一需求的标准化标注平台和统一基准,量化和比较 RLHF 的最新进展是有挑战性的。
本文中,天津大学深度强化学习实验室的研究团队推出了面向现实决策场景的 Uni-RLHF 平台,这是一个专为 RLHF 量身定制的综合系统实施方案。它旨在根据真实的人类反馈提供完整的工作流程,一站式解决实际问题。

-
论文题目:Uni-RLHF: Universal Platform and Benchmark Suite for Reinforcement Learning with Diverse Human Feedback
-
项目主页:https://uni-rlhf.github.io/
-
平台链接:https://github.com/pickxiguapi/Uni-RLHF-Platform
-
算法代码库:https://github.com/pickxiguapi/Clean-Offline-RLHF
-
论文链接:https://arxiv.org/abs/2402.02423
-
作者主页:http://yifu-yuan.github.io/
Uni-RLHF 包含三个部分:1)通用多反馈标注平台,2)大规模众包反馈数据集,3)模块化离线 RLHF 基线代码库。
具体流程来看,Uni-RLHF 首先针对各种反馈类型开发了用户友好的标注界面,与各种主流 RL 环境兼容。然后建立了一个系统的众包标注流水线,产生了包含 32 个任务、超过 1500 万个时间步的大规模标注数据集。最后,基于大规模反馈数据集,实现了最先进的 RLHF 算法的基线结果和模块化组件以供其他研究者使用。
Uni-RLHF 希望通过评估各种设计选择,深入了解它们的优势和潜在的改进领域,构建有价值的开源平台、数据集和基线,以促进基于真实人类反馈开发更强大、更可靠的 RLHF 解决方案。目前平台、数据集和基线代码库均已开源。
多反馈类型通用标注平台
Uni-RLHF 标注平台提供了众包标准标注工作流程:
-
接口支持多种在线环境 (Online Mode) 和离线数据集 (Offline Mode),并且可以通过简单的接口扩展方式接入定制化的环境;
-
查询采样器 (Query Sampler) 可决定哪些数据需要被标注,支持多种类型的采样策略;
-
交互式用户界面 (User Interface) 可让众包查看可用轨迹片段并提供反馈响应,提供包含选择、拖动、框选和关键帧捕捉等一系列视频片段和图像标注方式;
-
反馈翻译器 (Feedback Translator) 可将不同的反馈标签转换为标准化格式。
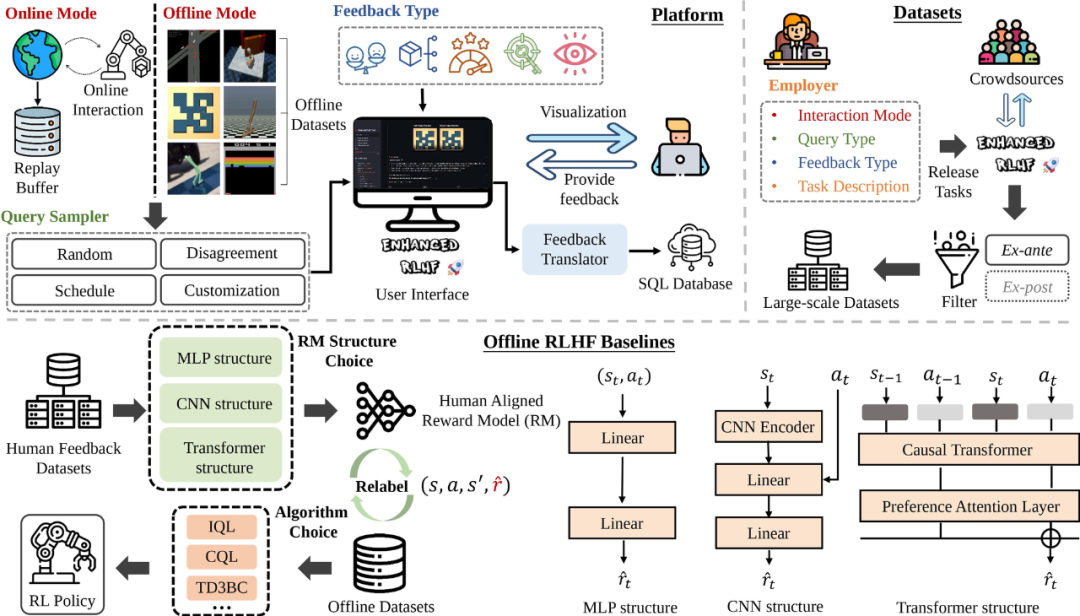
Uni-RLHF 包括平台、数据集和离线 RLHF 基线代码库三个部分
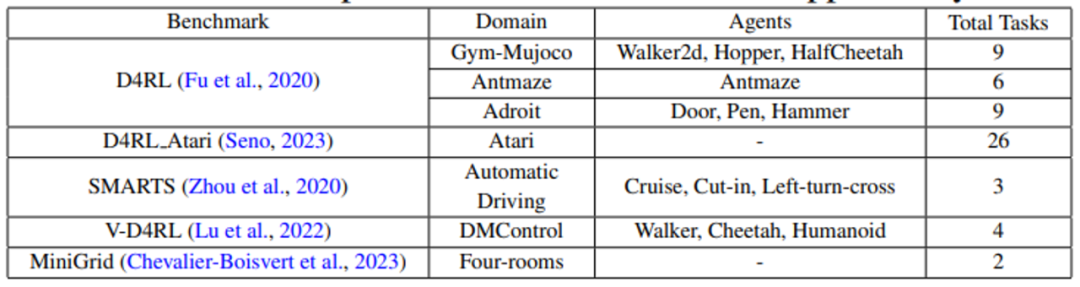
Uni-RLHF 能够支持大量主流的强化学习环境
适用于强化学习的标准反馈编码格式
为了更好地捕捉和利用来自标注者的各种不同类型的反馈标签,Uni-RLHF 对一系列相关研究进行了总结,提出一种标准化的反馈编码格式和对应的训练方法。使用者可以根据任务和标注成本需求,选择不同类型的标注方法。一般来说,信息密度越高,标注成本相应也会更大,但是反馈效率也会随之提升。
Uni-RLHF 支持以下五种反馈类型:
-
比较反馈 (Comparative Feedback):对两段轨迹给出相对性的二元反馈比较
-
属性反馈 (Attribute Feedback):对两段轨迹给出基于多属性的相对反馈比较
-
评估反馈 (Evaluative Feedback):对一段轨迹给出多个级别的评估选项
-
视觉反馈 (Visual Feedback):对一段轨迹中的视觉重点进行选择和标记
-
关键帧反馈 (Keypoint Feedback):对一段轨迹中的关键帧进行捕捉和标记
大规模众包标注流水线
在 RLHF 训练过程中,数据标注是一项复杂的工程问题。研究人员围绕 Uni-RLHF 构建众包数据注释流水线,通过并行的众包数据注释和过滤,促进大规模注释数据集的创建。
为了验证 Uni-RLHF 平台各方面的易用性和对 RLHF 前沿算法性能进行验证,研究人员使用广受认可的离线 RL 数据集实现了大规模众包标注任务,以收集反馈标签。
在完成数据收集后,研究人员进行了两轮数据过滤,以尽量减少有噪声的众包数据量,最终建立了一个系统化的众包注释流水线,形成了大规模标注数据集,包括 32 个主流任务中的 1,500 多万个时间步。
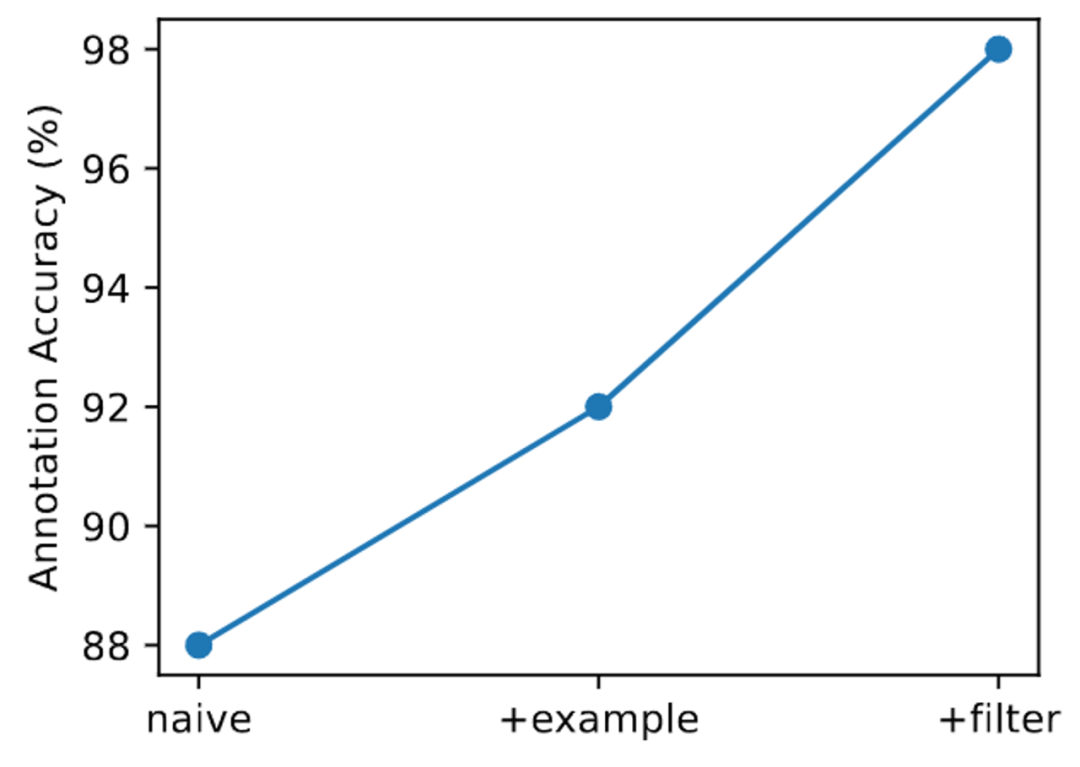
标注流水线中每个组件的验证
为了证明数据过滤的有效性。研究人员首先在 SMARTS 中抽取了 300 个轨迹片段进行专家注释,称为「Oracle」。接下来,研究人员请了五位众包在三种不同的设置下分别标注 100 条轨迹。「Naive」意味着只能看到任务描述,「Example」允许查看专家提供的五个注释样本和详细分析,而「Filter」则添加了过滤器。
以上实验结果表明,每个组件都显著提高了标注的可靠性,最终实现了与专家注释 98% 的一致率。
离线 RLHF 基准实验
研究人员利用收集到的众包反馈数据集对下游决策任务进行了大量实验,以评估各种不同的设计选择及其对应的优势。
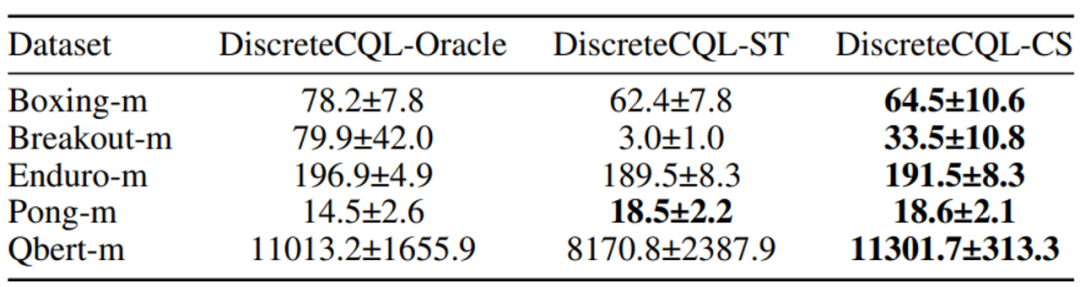
首先,Uni-RLHF 使用了三种不同的奖励模型设计结构,分别是 MLP、TFM (Transformer) 和 CNN,其中 MLP 结构便于处理向量输入,而 CNN 结构便于处理图像输入。TFM 奖励结构则能够更好地拟合 non-Markovian 奖励。同时Uni-RLHF 使用了三种广泛使用的离线强化学习算法作为底座,包括 IQL、CQL 和 TD3BC。
Oracle 代表使用手工设计的任务奖励训练的模型;CS (CrowdSource) 代表一种是通过 Uni-RLHF 系统众包获得的众包标签;而 ST (Script Teacher) 代表根据实际任务奖励生成的合成标签,可视为专家标签供比较。
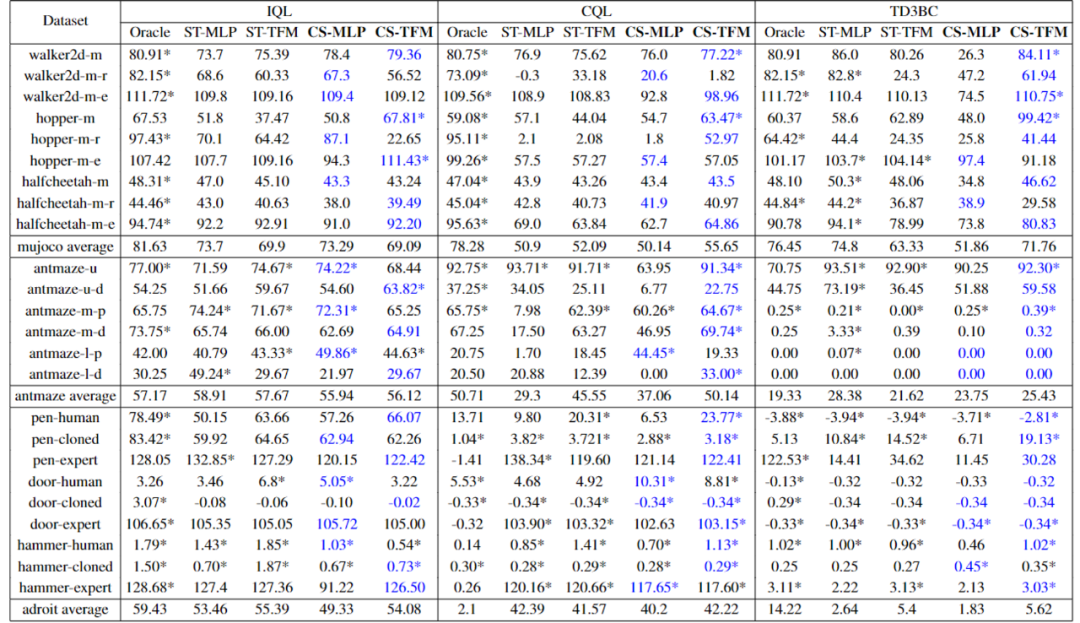
实验结论表明:
-
基于 IQL 基线效果最稳定,并且比较 IQL-CS 能够表现出和 IQL-Oracle 相当的优异性能,而 CQL 基线偶尔会出现策略崩溃的结果;
-
总体看来,TFM 结构在稳定性和性能两方面均领先于 MLP 结构,尤其是在稀疏奖励设置的环境中;
-
和合成标签 (ST) 相比,众包标签 (CS) 在大多数环境中能够达到相当甚至超越的效果,这也证明了 Uni-RLHF 具有高质量的数据标注。
在图像输入的环境中,众包标签 (CS) 则全面领先于合成标签 (ST),研究人员认为这种优异表现来源于人类能够更敏感的捕捉到游戏过程中的细节过程,这些细节则很难用简单的积分奖励来概括。
RLHF 方法是否能在真实的复杂任务上成功替代手工设计的奖励函数?研究人员使用了 NeurIPS 2022 中 SMARTS 自动驾驶竞赛的环境,该环境提供了相对真实和多样化的自动驾驶场景,并使用成功率,速度和舒适度等多个指标评估模型的性能。其中,冠军方案针对该任务设计奖励函数会经过多次试错,并在多次训练过程中不断调整完善各项奖励时间及系数,最终形成了以下极为复杂的奖励函数构成,设计成本极高:
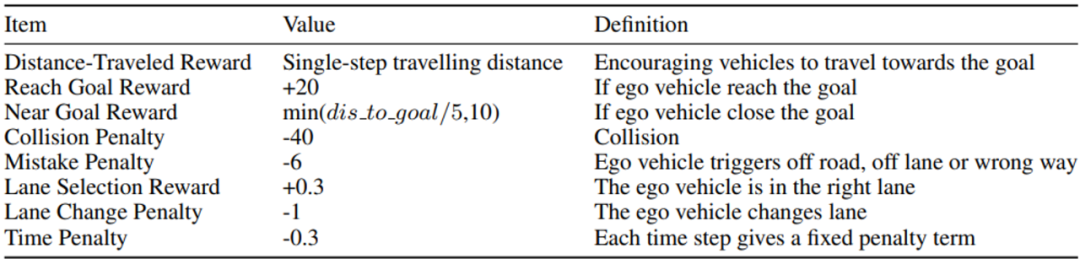
自动驾驶场景奖励函数设计
而通过众包标注的简单反馈标签进行奖励函数训练,Uni-RLHF 就能够达到超越专家奖励的任务成功率,并且在舒适度指标上也有所领先。
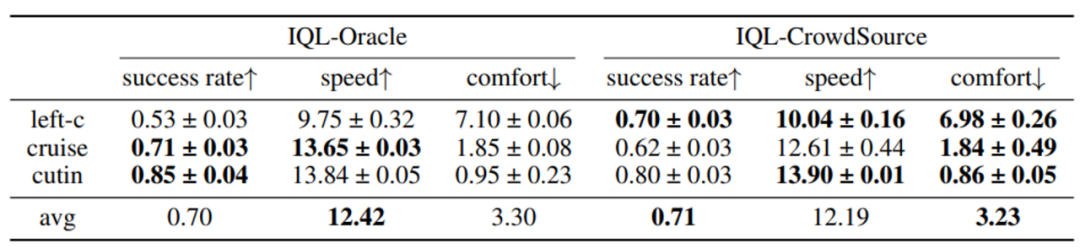
针对 SMARTS 自动驾驶场景的多指标评测

Uni-RLHF 方法和 Oracle 奖励函数对比。(左:Oracle,右:Uni-RLHF)
Uni-RLHF 还针对其他多种类型的反馈形式进行了更多验证,这里以多属性反馈 (Attribute Feedback) 举一个简单的例子:用户希望训练一个 Walker 机器人,使其速度和躯干高度在运动的过程中进行自由的变化,而不是简单的最大化速度。此时简单的比较反馈就很难准确的表述用户的偏好,Uni-RLHF 则提供了针对多属性反馈的标注模式。在本实验中,Walker 会运行 1000 步,并每 200 步调整姿态,速度的属性值设定为 [慢,快,中,慢,快],高度的属性值设定为 [高,中,高,低,高]。从曲线和相应的视频中可以清楚地观察到经过 Uni-RLHF 标注后训练的模型能够灵活的进行姿态转换。

Walker 遵循用户偏好进行灵活姿态转换
总结和未来展望
Uni-RLHF 展示了在决策任务中基于 RLHF 方法取代手工设计奖励函数的重要前景,研究人员希望通过建设平台、大规模数据集和代码库以促进更加可靠,基于真实人类反馈标注的 RLHF 解决方案。该领域仍存在一些挑战和可能的未来方向:
-
评估人类的非理性和偏向性:众包提供反馈标签势必会带来反馈标签的噪音,即对任务认知不统一、标注错误、有偏向性等问题,如何在嘈杂的标签数据中进行学习是值得研究的方向。
-
不完美奖励函数修正:反馈标签的噪音和数据分布狭窄等问题会导致学习到次优的奖励函数、如何基于奖励塑形、先验知识等进一步的基于该奖励函数进行修正也是重要的研究问题。
-
多反馈类型的组合作用:尽管目前的研究已经证实,使用更细粒度的反馈方式会给学习效率带来巨大提升,但在同一个任务中聚合图像、评估、关键帧等各类型反馈方式依然值得进一步研究。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com