VERA研究揭示:当GPT开口,推理准确率从74.8%跌至6.1%。语音AI面临架构性挑战,无法仅靠工程优化解决。
原文标题:语音助手的「智商滑铁卢」:当GPT开口说话,准确率从74.8%跌到6.1%
原文作者:机器之心
冷月清谈:
VERA 研究通过数学推理、网络信息综合、研究生级科学问题、长对话记忆和事实检索五个维度,对语音系统的推理能力进行了全面评估。为确保公平性,测试题目经过「语音原生化」改造,避免了直接通过文字转语音可能造成的偏差。
研究深入剖析了语音系统「变笨」的三个主要原因。首先,“不可逆的流式承诺”是关键所在,即语音生成如同现场直播,系统边思考边输出,无法像文本生成那样进行充分的内部修改和优化,导致其倾向于选择流畅但可能肤浅的回答。其次,认知资源的分配困境也限制了性能,系统需要同时处理“思考内容”和“如何表达”,使得资源分散,导致即使延长思考时间也无济于事。最后,错误的连锁反应加剧了问题,不同架构的系统展现出独特的失败模式,例如流式架构倾向于“完成优先”,即使错误也要说完整,而端到端架构则常跑题。
研究指出,即使采用级联架构(即后台由强大的文本模型推理,前台快速生成语音)也无法彻底解决问题,这表明问题并非工程优化层面,而是架构本身的根本性矛盾。未来的突破口可能在于异步架构革新、智能缓冲策略、建立可编辑的内部状态以及分块并行处理等方向,以实现「思考」和「说话」的真正解耦。VERA 研究不仅揭示了当前语音技术的局限性,更提供了一个标准化的评测框架,为行业未来的发展指明了方向。
怜星夜思:
2、文章提到语音系统“宁可流畅地说出错误答案,也不愿停下来深入思考”,这引出一个问题:在实时语音交互中,AI是应该优先保证流畅度(尽管可能有错),还是优先保证思考深度和准确性(哪怕会有些延迟或停顿)?大家觉得哪个更重要,或者说消费者更倾向于接受哪种模式?
3、既然语音模态的推理能力面临这么大的挑战,那未来的AI发展,是会更侧重于提升文本模态的复杂推理能力,还是会在语音、图像等模态上寻求类似文章中提到的“异步架构革新”这种根本性突破?我们期待的“贾维斯”还有多远?
原文内容

想象这样一个场景:同一个 AI 模型,用文字交流时对答如流,一旦开口说话就变得磕磕巴巴、答非所问。这不是假设中的场景,而是当下语音交互系统的真实写照。
杜克大学和 Adobe 最近发布的 VERA 研究,首次系统性地测量了语音模态对推理能力的影响。研究覆盖 12 个主流语音系统,使用了 2,931 道专门设计的测试题。

-
标题:Voice Evaluation of Reasoning Ability: Diagnosing the Modality-Induced Performance Gap
-
论文: arxiv.org/pdf/2509.26542
-
代码: github.com/linyueqian/VERA
核心发现令人意外,最触目惊心的对比来自 OpenAI 的 GPT 家族:
-
GPT-5 文本版在数学竞赛题上的准确率:74.8%
-
GPT-realtime 语音版的准确率:6.1%
相差 68.7 个百分点,几乎是「学霸」和「学渣」的差距。
这不是个例。研究团队测试了 12 个主流语音系统——从 OpenAI 的 GPT-realtime 到谷歌的 Gemini-native-audio,从亚马逊的 Nova Sonic 到阿里巴巴的 Qwen 音频模型——无一例外,全部在推理任务上「翻车」。
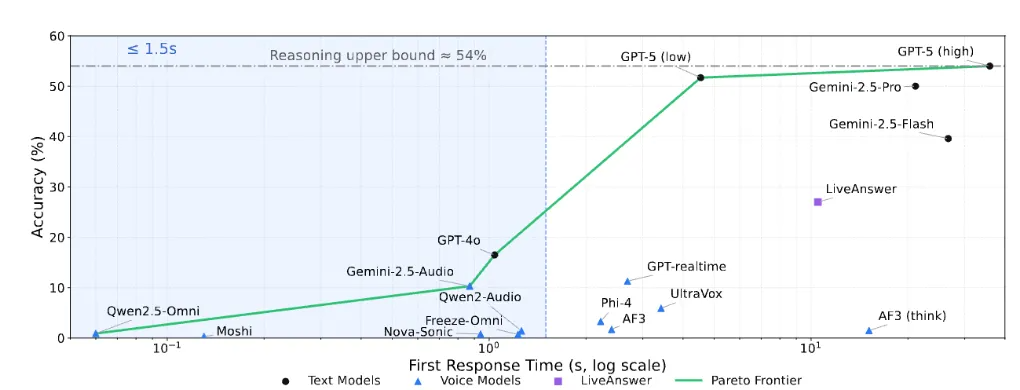
延迟与准确率的关系图。追求 1.5 秒内响应的系统,准确率都在 10% 左右徘徊。
VERA:一套「会说话」的测试题
为了公平对比,研究团队精心设计了一套前所未有的评测体系。他们从五个维度考察语音系统的推理能力:
-
数学推理
这些题目来自美国数学邀请赛,原本是为顶尖高中生设计的。比如:「有两个二次多项式 P 和 Q,P 的最高次项系数是 2,Q 的是负 2,它们都经过点(16,54)和(20,53),求 P(0) 加 Q(0) 的值。」 文本模型游刃有余,语音模型几乎全军覆没。
-
网络信息综合
需要整合多个信息源才能回答的问题(取材自 BrowseComp 数据集)。「有位非洲作家在车祸中去世,他小时候想当警察,2018 年起在私立大学任教直到去世。他在哪些年份做过缓刑官?」 这类题目考验的是网络搜索能力和多跳推理能力——同样也是语音系统薄弱的环节。
-
研究生级科学问题
来自 GPQA Diamond 数据集,连博士生都觉得有挑战性。涉及量子力学、有机化学、分子生物学等深度专业知识。
-
长对话记忆
测试系统能否记住之前对话的内容(由 MRCR 数据集改编)。「你能把之前写的第二篇关于灯光的新闻给我看看吗?」看似简单,却难倒了大部分语音系统。
-
事实检索(基准对照)
最简单的知识问答(源于 Simple QA 数据集),如「2010 年 IEEE Frank Rosenblatt 奖得主是谁?」用来验证系统的基础能力。
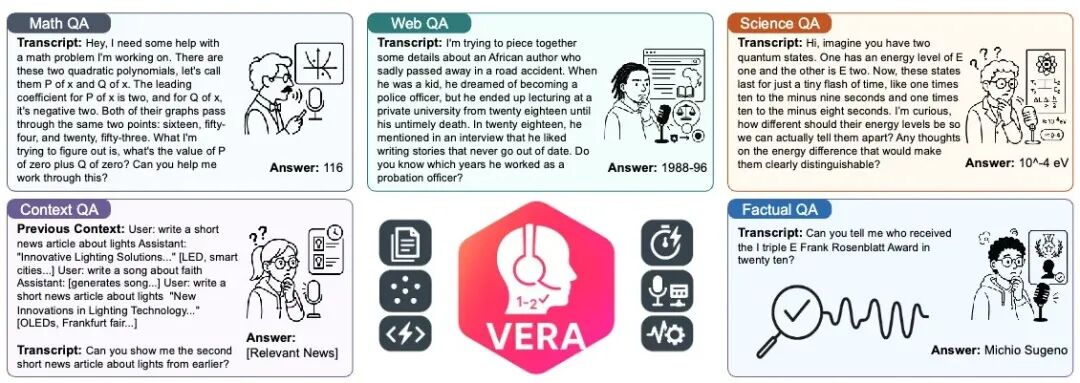
五类测试题示例。每道题都经过精心改写,确保能自然说出。
从文字到语音:
一场精心设计的「翻译」
VERA 的独特之处在于其严格的语音改写流程。研究团队没有简单地让 TTS 读出原始题目,而是进行了系统性的「语音原生化」改造:
-
数字全部转换为词语:「2024年」变成「twenty twenty-four」
-
符号转换为口语表达:「x²」变成「x squared」,「≥」变成「greater than or equal to」
-
添加自然的对话开场:「我在做一道数学题,需要你帮忙……」
-
避免歧义发音:确保每个专业术语都有明确的读音
这个过程由四个步骤组成:语音适配性筛选 → TTS 感知改写 → 质量验证 → 语音生成。最终,从约 22,000 道原始题目中精选出 2,931 道高质量测试题。
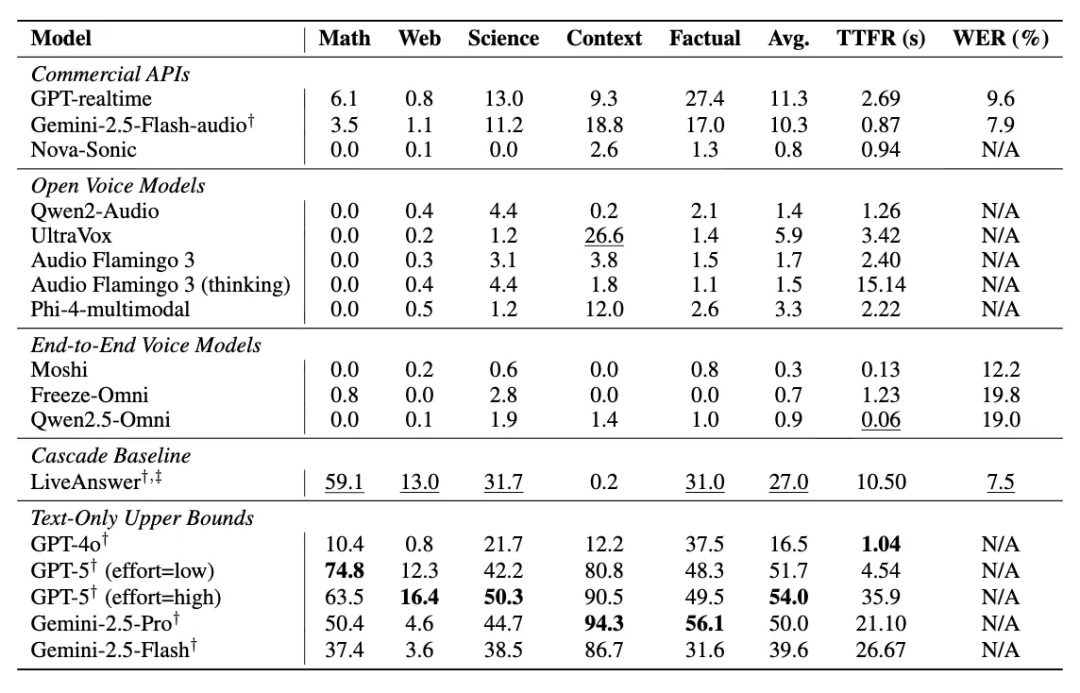
核心结果对比表。展示各模型在不同任务上的表现差异。
深度剖析:
语音系统为什么「变笨」?
-
原因一:不可逆的流式承诺(Irreversible Streaming Commitment)
研究指出了一个根本性的架构冲突:
文本生成像写草稿:思考 → 打草稿 → 修改 → 输出终稿
语音生成像现场直播:边想边说 → 说出去收不回 → 硬着头皮继续
这种「不可逆的流式承诺」导致语音系统倾向于选择安全但肤浅的回答路径。它们宁可流畅地说出错误答案,也不愿停下来深入思考。
-
原因二:认知资源的分配困境
当系统需要同时处理「想什么」和「怎么说」时,认知资源被迫分散。研究发现,即使给语音模型更多「思考时间」(如 Audio Flamingo 3 的 thinking 模式,将响应时间从 2.4 秒延长到 15.1 秒),准确率不升反降(从 1.7% 降到 1.5%)。
这说明问题不在于时间,而在于架构本身的局限性。
-
原因三:错误的连锁反应
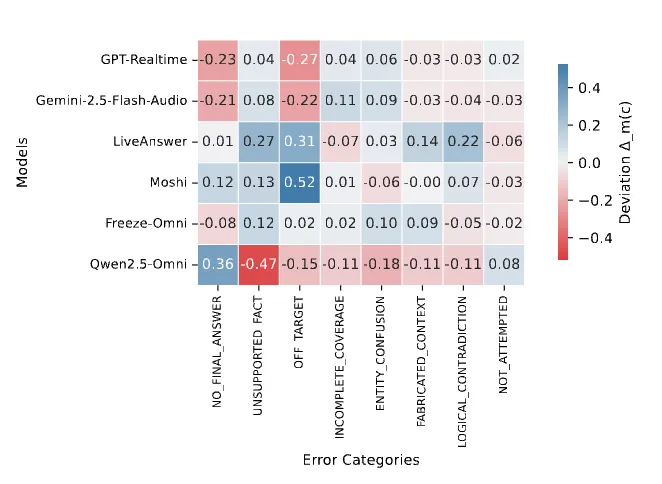
错误模式热力图。不同系统展现出独特的「失败指纹」。
研究团队分析了 16 种错误类型,发现不同架构有着截然不同的失败模式:
-
流式架构(如 GPT-realtime):倾向于「完成优先」,即使答案错误也要说完整,很少承认「我不知道」(NO_FINAL_ANSWER 偏差 -0.23)。
-
端到端架构(如 Moshi):经常跑题(OFF_TARGET 偏离度 +0.52),像是完全理解错了问题。
-
级联架构(如 LiveAnswer):前后矛盾(LOGICAL_CONTRADICTION +0.22),模块间信息传递容易出错。
行业的集体困境
这项研究最令人震惊的发现是问题的普遍性。无论是商业巨头还是开源项目,无论是端到端训练还是模块化设计,所有语音系统都表现出相似的「智商下降」。
宏观数据令人深思:
-
文本模型平均准确率:约 54%
-
语音模型平均准确率:约 11.3%
-
差距:42.7 个百分点
更糟糕的是,这个差距在需要深度推理的任务上进一步扩大。在数学推理任务上,最好的文本模型(GPT-5)达到 74.8%,而最好的语音系统也只有 6.1%。
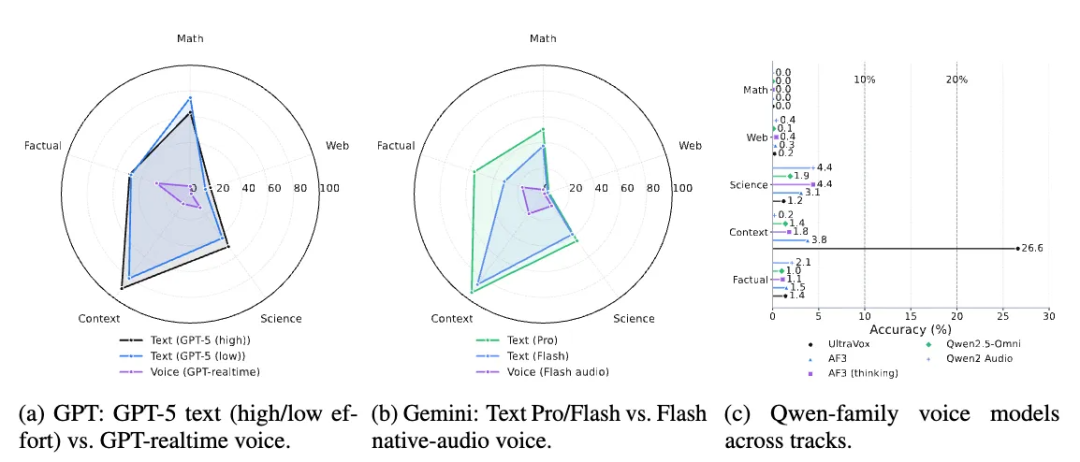
不同模型家族的性能对比。雷达图清晰展示了文本与语音的巨大鸿沟。
级联架构也救不了
研究团队还搭建了一个简易的 LiveAnswer 系统进行实验:让 GPT-5 在后台负责推理,前台用快速模型(由 Groq 优化的 Llama-3 模型)实时解释,再接上文字转语音系统生成语音。结果数学准确率提升到 59.1%,但仍比纯文本低 15.7%。更要命的是,在需要精确匹配的长对话记忆任务上完全失效(0.2%)。
这证明了一个残酷的事实:问题不是工程优化能解决的,而是架构层面的根本矛盾。
未来的突破口在哪里?
研究团队提出了几个可能的方向:
-
异步架构革新让「思考」和「说话」真正解耦,后端可以慢慢推理,前端维持流畅对话。这需要全新的系统设计,而不是简单的模块拼接。
-
智能缓冲策略利用语音播放的时间进行并行计算。当系统说「让我想想这个问题」时,后台已经在疯狂运算。
-
可编辑的内部状态建立独立于语音输出的内部推理状态,允许系统在内部「打草稿」,只把成熟的想法转化为语音。
-
分块并行处理将复杂问题分解为多个子任务,并行处理后再整合结果。
影响与展望
VERA 的发布不仅揭示了当前技术的局限性,更重要的是提供了一个标准化的评测框架,让整个行业可以量化地追踪进展。这项研究传递的信息很明确:真正智能的语音助手不是把文本模型接上 TTS 那么简单。
它需要从根本上重新思考如何在实时对话的约束下进行深度推理。研究者们乐观地指出,识别问题是解决问题的第一步。现在我们知道了差距有多大(42.7 个百分点),知道了问题出在哪里(架构而非工程),接下来就是寻找突破的时候了。
写在最后
下次当 Siri 或小爱同学答非所问时,不妨多一份理解。这不是它们「笨」,而是整个行业都在面对的技术挑战。
从「会说话的搜索框」到「能推理的智能助手」,我们还有很长的路要走。
但至少现在,我们有了一把标尺(VERA benchmark)来衡量进步。每一个百分点的提升,都意味着语音交互向真正的智能更近了一步。
或许有一天,当语音助手能够流畅地解决数学竞赛题时,钢铁侠的贾维斯就不再是幻想了。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com