Mamba-3带来SSM架构三大升级,挑战Transformer,擅长长序列和高效推理。
原文标题:老牌Transformer杀手在ICLR悄然更新:Mamba-3三大改进趋近设计完全体
原文作者:机器之心
冷月清谈:
实证结果表明,Mamba-3 在语言建模任务中性能达到或超越Mamba-2及Transformer,并展现了强大的关联记忆与问答能力。其MIMO变体在推理效率上也有显著提升,实现了更高硬件利用率和更低延迟。Mamba-3 的这些特性使其非常适合处理长序列、实时交互及本地边缘部署场景,有望在长文档理解、基因建模等领域发挥重要作用。
怜星夜思:
2、文章里提到 Mamba-1 曾被拒稿,Mamba-2 也没达到现象级关注。Mamba 家族明明技术上这么厉害,为什么一直没有像 Transformer 那样真正“出圈”呢?是不是生态、社区支持或者工程化的原因?
3、Mamba-3 预测能在长文档、实时交互和边缘设备上大显身手。但咱们在实际开发和使用中,除了这些技术进步,还会遇到哪些实际问题?比如工具链支持、部署复杂度,或者学习曲线啥的?
原文内容
编辑:冷猫
至今为止 Transformer 架构依然是 AI 模型的主流架构,自从其确立了统治地位后,号称 Transformer 杀手的各类改进工作就没有停止过。
在一众挑战者中最具影响力的自然是 2023 年社区爆火的基于结构化的状态空间序列模型(SSM)架构的 Mamba。
Mamba 的爆火可能和名字有关,但硬实力确实强大。
在当时,Mamba 在语言建模方面可以媲美甚至击败 Transformer。而且,它可以随上下文长度的增加实现线性扩展,其性能在实际数据中可提高到百万 token 长度序列,并实现 5 倍的推理吞吐量提升。
在 Mamba 问世后,涌现出了超多在不同任务上使用 Mamba 的工作以及一些改进工作,诞生了了 MoE-Mamba、Vision Mamba、VMamba、U-Mamba、MambaByte、MambaOut 等多项工作,被称为「Transformer 最有力的继任者」。
但 Mamba ,最终还是被拒稿。
在 2024 年,在 Mamba 发布的半年后,,拿下了顶会 ICML 2024。核心层是对 Mamba 的选择性 SSM 的改进,速度提高了 2-8 倍,同时在语言建模方面继续与 Transformers 竞争。
但 Mamba-2 除了让第一代 Mamba Out 之外,似乎没能获得现象级的关注。
就在最近,Mamba 的第三代迭代工作 Mamba-3 悄悄的出现在了 ICLR 2026,正在盲审环节。

-
论文标题:Mamba-3: Improved Sequence Modeling Using State Space Principles
-
论文链接:https://openreview.net/pdf?id=HwCvaJOiCj
Mamba-1 使用的是连续时间动态模型,并通过「选择性记忆更新」机制来保留信息,在不依赖注意力机制的情况下实现了高效记忆。
Mamba-2 更进一步,提出状态空间更新(SSM)与注意力机制在数学上是等价的两种形式,从而在保持接近 Transformer 性能的同时,大幅提升了在 GPU 上的运行速度。
关于 Mamba-1 和 Mamba-2 的技术解析,。
现在的 Mamba-3 给人的感觉是,这个架构终于成熟了。它不仅是注意力机制的替代方案,而是在状态演化方式、记忆机制以及硬件并行利用方式上,完成了一次更全面、更统一的设计。
三大重要改进
Mamba-3 在三个关键领域相对于 Mamba-2 引入了重大改进:
梯形离散化(Trapezoidal Discretization)
研究团队使用梯形法对底层的连续时间动力系统进行离散化。最终得到的递推形式是 Mamba-2 递推结构的一个更具表达力的超集,并且可以被视为一种卷积。
之前的状态更新只考虑区间起点的信息,而现在会同时结合起点和终点。
研究团队将这种新的离散化方式与作用于 B、C 的偏置项结合使用,发现这种组合在经验上可以替代语言建模中的短因果卷积。
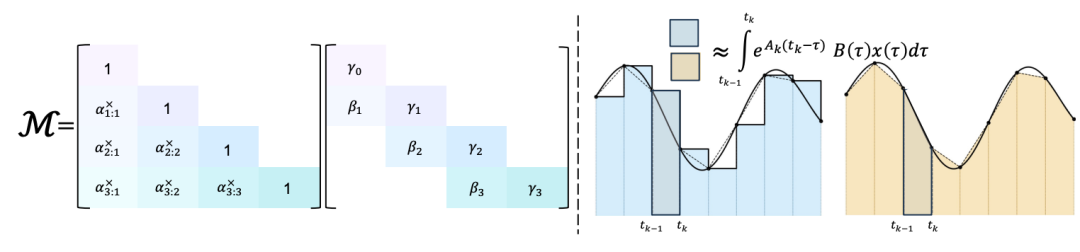
左图: 广义梯形积分法引出的结构化掩码,是由衰减掩码与卷积掩码的乘积构成的;右图: 欧拉方法(使用端点值保持不变)对比梯形积分法(取区间两端点的平均值)
复数化状态空间模型(Complexified State-Space Model)
通过将 Mamba-3 底层的状态空间模型视为复值结构,研究团队实现了相比 Mamba-2 更具表达力的状态更新机制。
这种更新规则在设计上仍保持训练和推理的轻量级特性,同时克服了当前许多线性模型在状态追踪能力上的不足。研究团队指出,这种复数更新机制等价于一种数据依赖的旋转位置编码,因此可以高效计算。
多输入多输出状态空间模型(MIMO SSM)
为了提升解码阶段的 FLOP 利用效率,研究团队将状态更新方式从基于外积(outer-product)的形式转换为基于矩阵乘法的形式。从 SSM 的信号处理基础来看,这一转变正对应于从单输入单输出(SISO)动态系统向多输入多输出(MIMO)动态系统的泛化。
Mamba-3 可以多通道同时更新状态,极大提升 GPU 并行吞吐效率。
MIMO 形式尤其适合推理阶段,因为其额外的表达能力允许在状态更新中投入更多计算量,而无需增加状态大小,从而不影响速度。
同时,研究团队也对整体架构进行调整,使其更贴近基线 Transformer 架构。Mamba-3 用更常见的 QK-normalization 替换了输出前投影归一化机制,并将短卷积设为可选项。
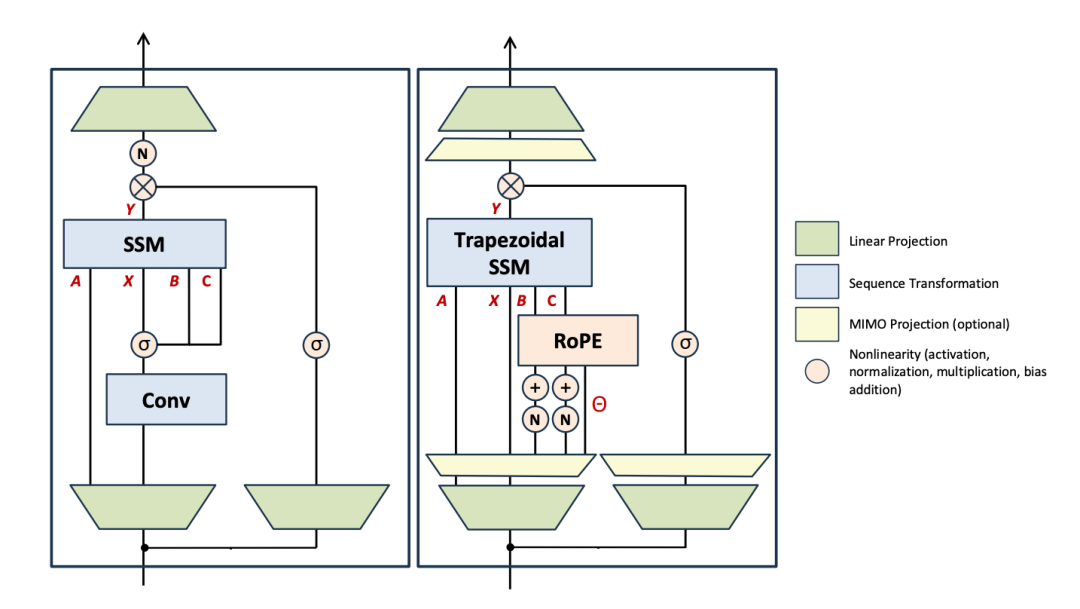
对比 Mamba-2 与 Mamba-3 的架构升级
实证验证
研究团队在一系列合成任务和语言建模任务上对新模型进行实证验证:
更好的质量(Better Quality)
在标准下游语言建模评测中,Mamba-3 的表现达到或超过 Mamba-2 及其他开源架构。例如,Mamba-3-1.5B 在所有下游任务上的平均准确率优于其 Transformer、Mamba-2 和 Gated DeltaNet 对应模型。

在使用 100B 规模的 FineWeb-Edu 语料训练后,对各模型进行下游语言建模评测的结果。

在参数规模匹配的预训练模型上进行下游语言建模评测结果,其中包含 Mamba-3 的 MIMO 版本。
更强的能力(Better Capability)
Mamba-3 对 SSM 状态的复数化使模型能够解决 Mamba-2 无法处理的合成状态追踪任务。

通过真实任务与合成任务混合评测检索能力。真实检索任务使用数据集的完形填空(cloze)变体,并截断至 2K 长度。
Mamba-3 在关联记忆与问答能力上表现出色,但在半结构化与非结构化数据的信息抽取方面存在不足。此外,Mamba-3 在「大海捞针」(NIAH)任务上具有很高的准确率,并能够泛化到其训练上下文之外的场景。
此外,研究团队表示,基于 RoPE 的高效计算几乎可以完美解决算术任务,而不带 RoPE 的 Mamba-3 与 Mamba-2 的表现则接近随机猜测。
更高的推理效率(Better Inference Efficiency)
Mamba-3 的 MIMO 变体在保持相同状态规模的同时,提升了相较于标准 Mamba-3 及其他模型的硬件利用效率。在不增加内存需求的前提下实现性能提升,从而推动了推理效率的 Pareto 前沿。

延迟(单位:毫秒)在不同模型、精度设置以及 d_state 数值下的对比。在常用的 bf16、d_state = 128 配置下,Mamba-3 的 SISO 和 MIMO 版本都比 Mamba-2 和 Gated DeltaNet 更快。
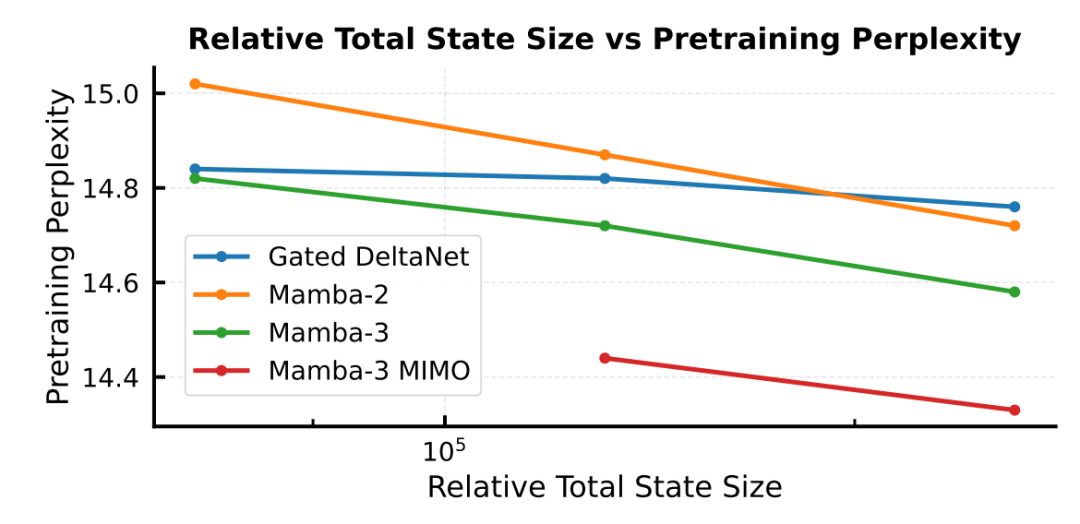
探索 状态大小(推理速度的代理指标) 与 预训练困惑度(性能的代理指标) 之间的关系。Mamba-3 MIMO 在不增加状态大小的前提下推动了 Pareto 前沿。
总结
Mamba-3 的高效长序列处理能力,使它非常适合应用于长文档理解、科学时间序列、基因建模等场景 —— 这些领域正是 Transformer 因上下文受限而表现不佳的地方。
由于其线性时间推理且延迟稳定,它同样非常适合用于实时交互场景,例如聊天助手、机器翻译和语音接口,这些任务更看重响应速度而非模型规模。
此外,得益于其友好的硬件特性,Mamba-3 有潜力未来运行在本地设备或边缘侧,在无需依赖云端的情况下执行大模型推理。
更多信息,请参阅原论文。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com