ReCA框架通过软硬协同加速多机器人协作,显著提升具身智能实时性与效率,助推其落地。
原文标题:协同加速,多机器人协作不再「慢半拍」!软硬一体化框架ReCA破解具身智能落地效率瓶颈
原文作者:机器之心
冷月清谈:
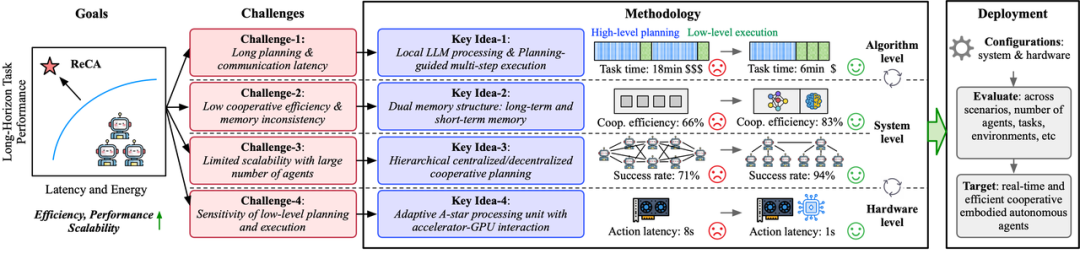
研究团队首先系统性分析了现有系统的三大瓶颈:基于LLM的高昂规划与通信延迟、在智能体数目增加时表现出的有限可扩展性,以及底层执行的精确性与效率敏感性。 针对这些挑战,ReCA框架从算法、系统和硬件三个层面进行了跨层次优化。在**算法层面**,ReCA引入了本地化微调LLM以消除网络延迟,并采用规划指导下的多步执行策略,显著减少LLM调用频率。在**系统层面**,它设计了双重记忆结构(长短期记忆分离)来提升规划连贯性,并采用分层协作规划模式(簇内中心化,簇间去中心化)以增强可扩展性。在**硬件层面**,ReCA采用异构硬件系统,GPU负责高阶规划,并为精准路径规划等低阶任务设计了如专用A-Star处理单元(APU)等硬件加速器。
这些优化使得ReCA在多个基准测试中展现出卓越性能,包括平均5-10倍的端到端任务加速,同时任务成功率平均提升4.3%,并在12个智能体的大规模协作场景下仍能保持80-90%的高成功率。 此外,APU相较于GPU实现了4.6倍的速度提升和281倍的能效改进。ReCA的工作标志着具身智能研究从单一追求“成功”到“成功且高效”的范式转变,也为未来的软硬协同设计和异构计算架构提供了重要的参考范本,为具身智能从实验室走向真实世界奠定了坚实基础。
怜星夜思:
2、ReCA强调了软硬件协同设计的重要性,通过算法、系统、硬件的跨层优化实现了显著性能提升。但在实际落地过程中,这种深度融合的开发模式,可能会带来哪些意想不到的工程挑战或成本压力呢?
3、ReCA让多机器人协作效率大幅提升,文章也畅想了未来在家庭、救援、科研等领域的应用。如果让你自由发挥,你最期待未来看到具身智能机器人团队在哪个特定场景中大放异彩?为什么?
原文内容

从仓库里的物流机器人到科幻电影中的「贾维斯」,我们对智能机器人的想象从未停止。学术界在模拟器里实现了越来越复杂的协作任务,工业界也让机器人学会了韦伯斯特空翻。
然而,一个残酷的现实是:当下的机器「人」更像是提线木偶,而非真正自主的智能体。
想象一下,机器人每做一个动作都要延迟十几秒,完成同样的任务比人类慢上十倍,这样的效率如何走入我们的生活?这个从虚拟到现实的「最后一公里」,其瓶颈常常被忽视:高昂的时间延迟和低下的协作效率。它像一道无形的墙,将真正的具身智能困在了实验室里。

-
论文标题: ReCA: Integrated Acceleration for Real-Time and Efficient Cooperative Embodied Autonomous Agents
-
论文地址: https://dl.acm.org/doi/10.1145/3676641.3716016
为了打破这一僵局,来自佐治亚理工学院、明尼苏达大学和哈佛大学的研究团队将目光从单纯的「成功」转向了「成功且高效」。他们推出了名为 ReCA 的集成加速框架,针对多机协作具身系统,通过软硬件协同设计跨层次优化,旨在保证不影响任务成功率的前提下,提升实时性能和系统效率,为具身智能落地奠定基础。
简单来说:ReCA 不再满足于让智能体「完成」任务,而是要让它们「实时、高效地完成」任务。
这份工作发表于计算机体系结构领域的顶级会议 ASPLOS'25,是体系结构领域接收的首批具身智能计算论文,同时入选 Industry-Academia Partnership (IAP) Highlight。
三大瓶颈:
当前模块化具身智能的「效率之殇」
研究团队首先对当前的协同具身智能系统(如 COELA, COMBO, MindAgent)进行了系统性分析,定位了三大性能瓶颈:
高昂的规划与通信延迟: 系统严重依赖基于 LLM 的模块进行高阶规划和智能体间通信。每一步行动都可能涉及多次 LLM 的顺序调用,其中网络延迟和 API 调用成本更是雪上加霜,使得实时交互成为奢望。

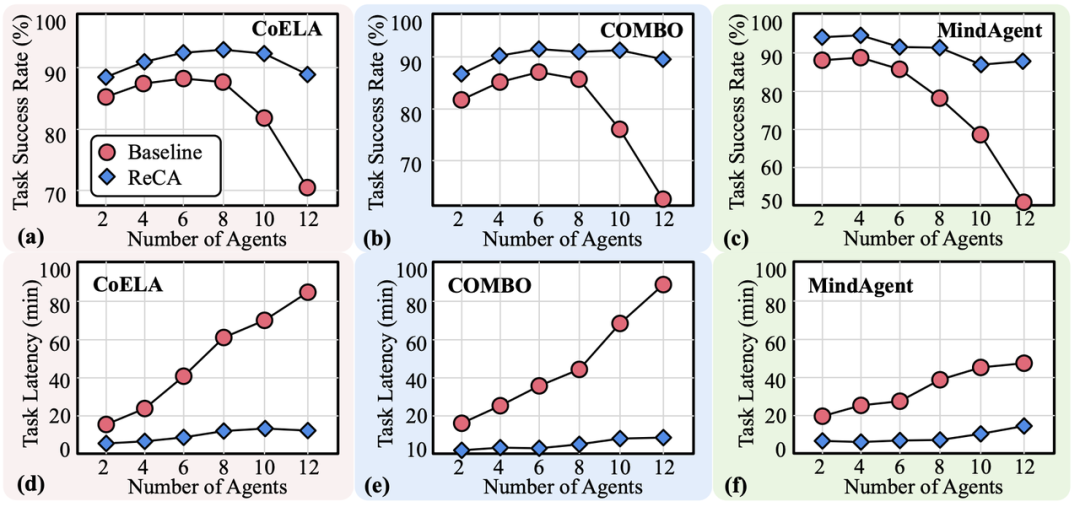
有限的可扩展性: 随着智能体数量的增加,去中心化系统会面临通信轮次爆炸性增长和效率下降的问题;而中心化系统则由于单一规划者难以处理复杂的多智能体协同,导致任务成功率急剧下滑。
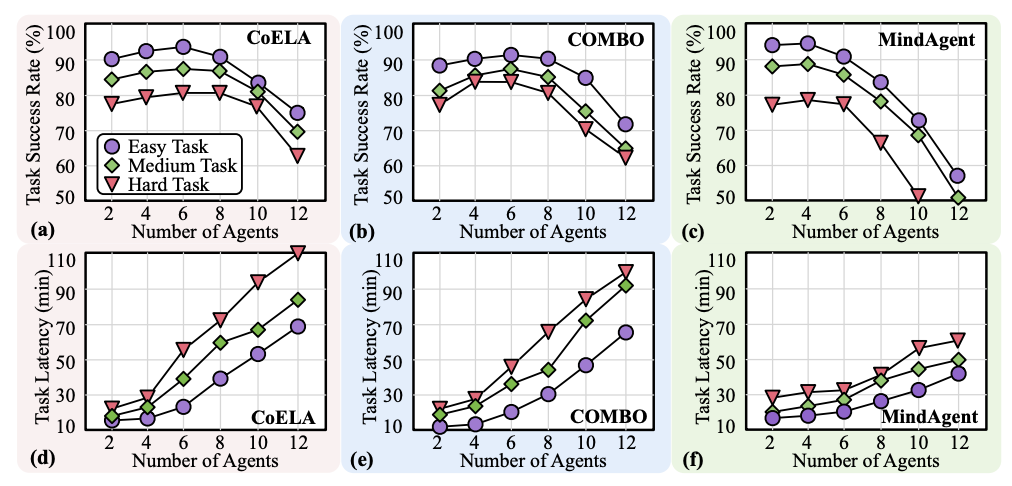
底层执行的敏感性: LLM 生成的高阶计划需要被精确翻译成底层的控制指令,底层执行的效率和鲁棒性直接关系到任务的成败。
ReCA 的「三板斧」:
从算法到系统再到硬件的跨层协同优化
针对上述挑战,ReCA 提出了一个贯穿算法、系统和硬件三个层面的跨层次协同设计框架,旨在提升协同具身智能系统的效率和可扩展性。
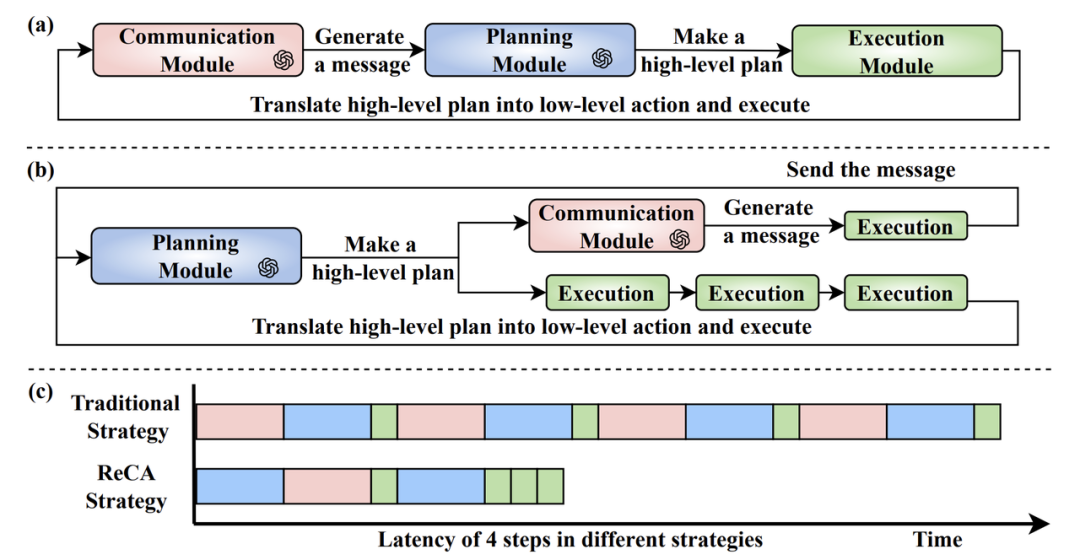
算法层面:更聪明的规划与执行
-
本地化模型处理: 通过部署更小的、本地化的经过微调的开源 LLM,ReCA 摆脱了对外部 API 的依赖,消除了网络延迟瓶颈,同时保障了数据隐私。
-
规划指导下的多步执行: 颠覆了传统「规划一步、执行一步」的模式。ReCA 让 LLM 一次性生成可指导连续多步底层动作的高阶计划,大幅减少了 LLM 的调用频率,显著降低了端到端延迟。
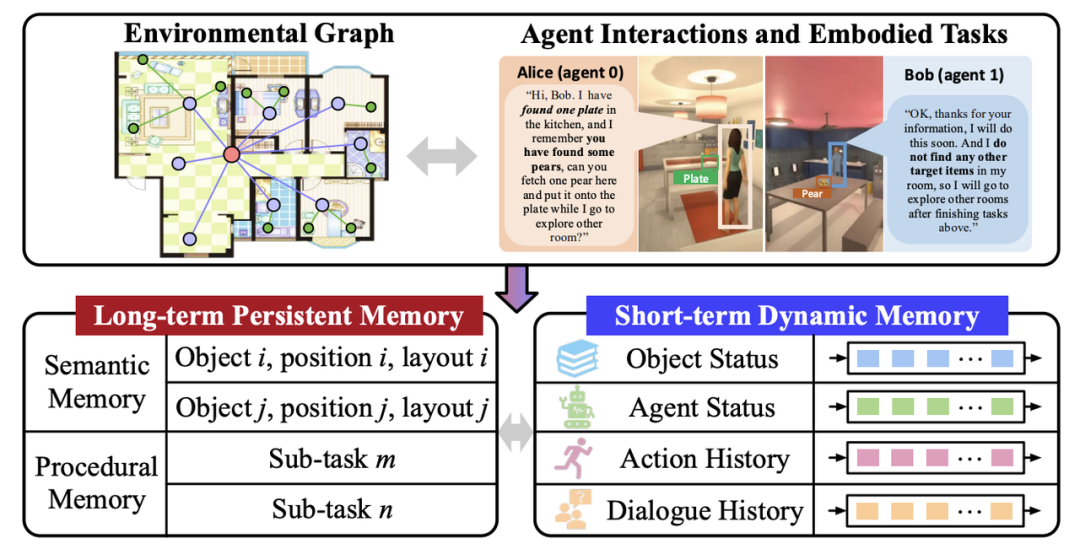
系统层面:更高效的记忆与协作
-
双重记忆结构: 借鉴了人类认知的「双系统理论」,ReCA 设计了长短时记忆分离的结构。
-
长期记忆以图结构存储环境布局等静态信息。
-
短期记忆则动态刷新智能体状态、任务进度等实时信息。
有效解决了 LLM 在长任务中 prompt 过长导致「遗忘」关键信息的痛点,提升了规划的连贯性和准确性。
-
分层协作规划: 为了解决扩展性难题,ReCA 引入了一种新颖的分层协作模式。在小范围的「簇」内,采用「父-子」智能体的中心化模式高效规划;在「簇」之间,则采用去中心化模式进行通信,更新彼此进度。这种混合模式兼顾了规划效率和系统规模。
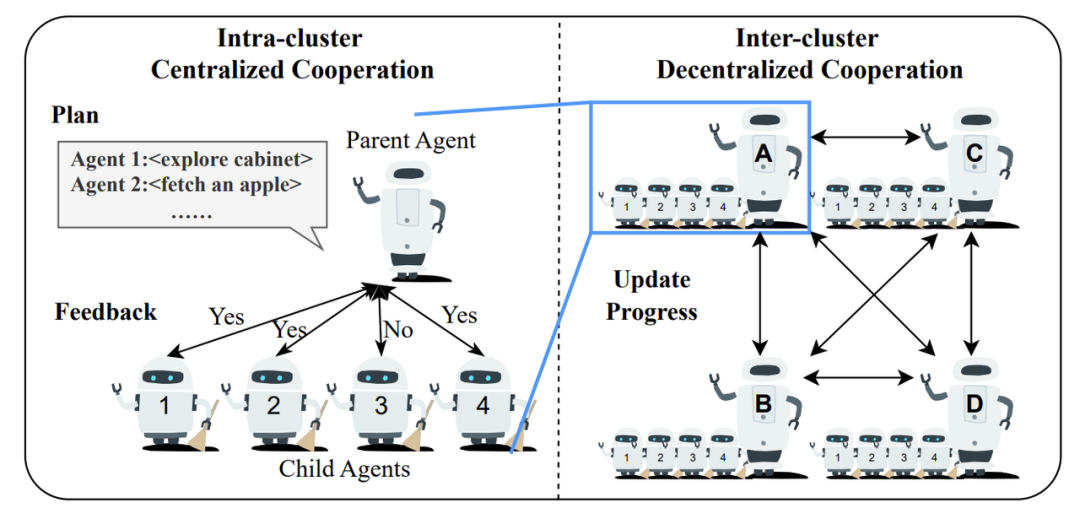
硬件层面:更专业的加速单元
-
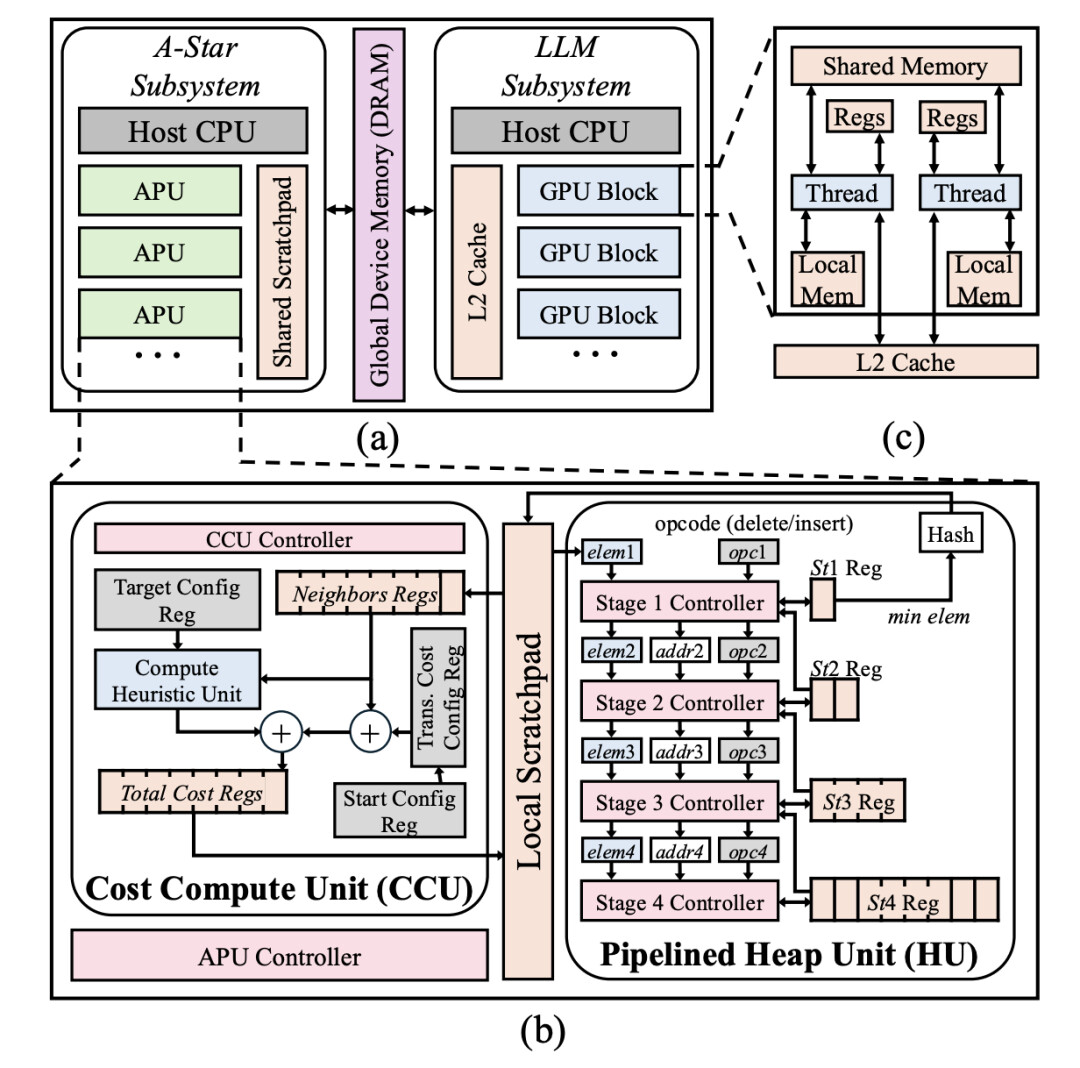
异构硬件系统: ReCA 为高阶和低阶规划匹配了最合适的计算单元。它采用 GPU 子系统处理 LLM 的高阶规划,同时为精准路径规划等低阶任务设计了专门的硬件加速器。
-
专用路径规划处理器: 研究表明,在系统优化后,原本占比不高的 A-star 路径规划延迟会成为新的瓶颈。ReCA 的专用 A-Star Processing Unit(APU)通过定制化的计算单元和访存设计,大幅提升了低阶规划的效率和能效。
效率提升:
5-10 倍速度提升,成功率不降反升
通过跨越六个基准测试和三大主流协同系统的评估,ReCA 展现了其强大的实力:
-
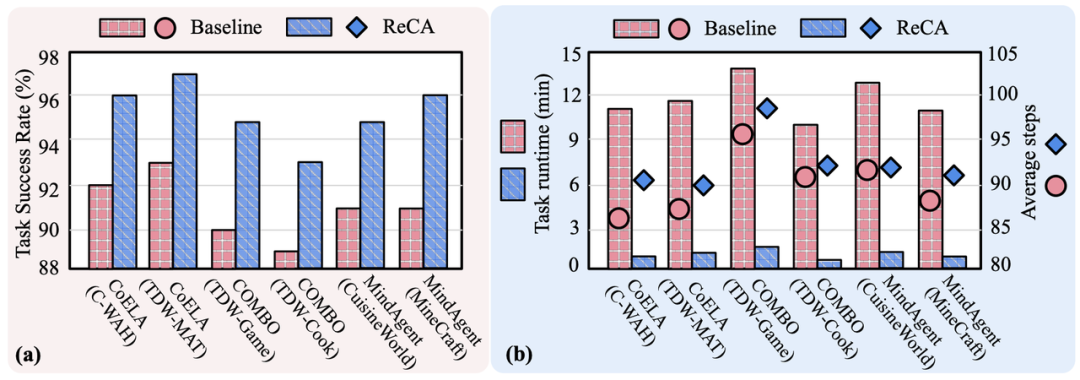
效率: 在任务步骤仅增加 3.2% 的情况下,实现了平均 5-10 倍的端到端任务加速。原本需要近一小时的复杂任务,ReCA 能在 20 分钟内完成。
-
成功率: 在大幅提升速度的同时,任务成功率平均还提升了 4.3%。这得益于其优化的记忆和协作机制,证明了效率与性能可以兼得。
-
可扩展性: 即使在 12 个智能体的大规模协作场景下,ReCA 依然能保持 80-90% 的高成功率,而基线系统的成功率已跌至 70% 以下。
-
能效: 其定制的 A-star 硬件加速器(APU)相较于 GPU 实现,取得了 4.6 倍的速度提升和 281 倍能效改进。
影响与未来
ReCA 的意义,远不止于一组性能提升的数据。它更像一块基石,为具身智能的未来发展铺设了三条关键路径:
从「能用」到「好用」的跨越: 此前,研究的焦点大多是如何让机器人「成功」完成任务。ReCA 则明确地提出,「成功且高效」是更关键的目标。这项工作有助于推动领域的研究范式转变,让延迟、效率和可扩展性也成为衡量具身智能系统的核心指标,加速其在家庭服务、智能制造等场景的落地。
「软硬协同」释放效能提升: ReCA 通过算法、系统、硬件的跨层次协同优化,突破了过往「单点优化」的局限。未来的具身智能系统,有望像 ReCA 一样,在不同层面协同设计的产物。它为 GPU 处理高阶规划、硬件加速器处理底层精确任务的异构计算模式提供了范本,为下一代机器人「大脑」+「小脑」的设计提供了一种可行方案。
突破瓶颈,解锁想象力: 当延迟不再是瓶颈,我们可以大胆想象:一个机器人管家团队能在你下班前,实时协作,烹饪好一顿丰盛的晚餐,并打扫干净房间;又或者在灾难救援现场,多个机器人能实时共享信息,高效协同,在黄金救援时间内完成搜索与拯救任务。在自动化科学实验室里,机器人集群能够 7x24 小时不间断地进行复杂的协同实验,以前所未有的速度推动科学发现。
总而言之,ReCA 的工作不仅解决了一个关键的技术瓶颈,更是为具身智能从实验室走向真实世界,架起了一座坚实的桥梁。我们距离那个能实时响应、高效协作的「贾维斯」式智能助手,确实又近了一大步。
作者介绍
万梓燊 是佐治亚理工学院博士生,研究方向为计算机体系架构和集成电路,聚焦通过系统-架构-芯片的跨层软硬件协同设计,为具身智能机器人和神经符号 AI 构建高效、可靠的计算平台。个人主页 https://zishenwan.github.io/
杜宇航 是 Yang Zhao 教授和 Vijay Janapa Reddi 教授指导的本科研究员,研究方向为计算机体系架构和集成电路,致力于通过系统级的性能分析与协同设计,为智能体在真实世界的计算打造基础设施。
Mohamed Ibrahim 是佐治亚理工学院博士后研究员,研究方向为软硬件协同设计,融合类脑计算与 VLSI 系统,构建具备高适应性与高可靠性的创新硬件架构。
钱家熠 是佐治亚理工学院博士生,研究方向为高效机器学习算法与系统、计算机体系结构与硬件设计,聚焦面向具身智能与神经-符号系统的协同优化与加速。
Jason Jabbour 是哈佛大学计算机科学系博士生,研究方向为机器学习、机器人和自动驾驶。
Yang (Katie) Zhao 是明尼苏达大学电子与计算机工程系助理教授,研究方向聚焦于计算机体系架构、硬件设计与机器学习的交叉领域,致力于通过从算法、芯片到系统的全栈式协同设计,为大语言模型等新兴应用提供高效、可靠的硬件加速方案。
Tushar Krishna 是佐治亚理工学院电子与计算机工程学院副教授,入选 ISCA、HPCA 和 MICRO 名人堂。长期致力于计算机体系架构、NOC 与 AI/ML 加速器等领域的研究,相关成果被引用超过 20000 次。曾有多篇论文入选 IEEE Micro 最佳论文推荐(Top Picks)或荣获最佳论文奖,现任 ML Commons Chakra 工作组联合主席。
Arijit Raychowdhury 是佐治亚理工学院电子与计算机工程学院院长,IEEE Fellow。长期致力于低功耗数字与混合信号电路、专用加速器设计等领域的研究,在国际顶级期刊与会议发表论文 250 余篇,拥有超过 27 项美国及国际专利。担任 ISSCC、VLSI、DAC 等多个顶级会议的技术委员会委员。
Vijay Janapa Reddi 是哈佛大学工程与应用科学学院教授,入选 MICRO 与 HPCA 名人堂。长期致力于计算机体系架构、机器学习系统与自主智能体的交叉领域研究,是 TinyML 领域的开拓者之一,并联合领导创建了 MLPerf。曾获 MICRO、HPCA 最佳论文奖及多次入选 IEEE Micro 最佳论文,现任 MLCommons 董事会成员和联合主席。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com