谷歌Dreamer 4世界模型纯靠“想象”训练,在《我的世界》中学会挖钻石,大幅超越离线智能体,实现高效交互与通用知识学习。
原文标题:梦里啥都有?谷歌新世界模型纯靠「想象」训练,学会了在《我的世界》里挖钻石
原文作者:机器之心
冷月清谈:
Dreamer 4 的技术基石在于其独特设计:它采用了一种新颖的 shortcut forcing 目标和高效的 Transformer 架构。这种设计使其能够准确学习复杂的物体交互,同时支持实时人机交互和高效的想象训练,甚至在单个GPU上即可运行。模型由 tokenizer(负责将视频帧压缩为连续表示)和动力学模型(根据动作预测这些表示)构成,两者均使用相同的Transformer架构。
实验结果表明,Dreamer 4不仅在《我的世界》离线钻石挑战中表现出色,还在人类交互测试中展现了对复杂交互的准确预测能力,优于以往的世界模型。更值得注意的是,Dreamer 4能够从大量无标签视频中吸收绝大部分世界知识,仅需少量带有动作标签的视频即可实现高质量的动作生成。这为未来智能体 从多样化的网络视频中学习通用世界知识,进而提升其决策能力开辟了广阔前景。文章强调,离线优化行为对于机器人等物理世界的应用具有重要价值,因为它避免了在线交互可能存在的安全风险。
怜星夜思:
2、文章提到Dreamer 4利用高效的Transformer架构大幅提升了预测性能。我们都知道Transformer在处理长序列和因果关系方面表现出色,但它在处理时间序列的“真实物理规律”预测时,是否有其固有的局限性?比如在《我的世界》这种物理引擎相对简单的环境中表现好,换到更复杂的物理仿真环境(如Unity、Unreal Engine),是否还需要额外的机制或架构改进才能准确预测物体交互?
3、Dreamer 4 能从大量无标签视频中学习到《我的世界》的大部分知识,这确实很酷。如果把这个思路推广到现实世界,比如让AI观看海量的YouTube视频,它能不能从中学习到像人类一样“通用的世界知识”?这种学习和我们人类通过观察世界学习有什么本质区别?要达到“通用世界知识”,我们还需要迈过哪些技术门槛?
原文内容
机器之心编辑部
只让机器人或虚拟智能体「想象」,不让它们和物理世界交互,它们也能学到和世界交互的技能?谷歌的世界模型 Dreamer 4 为这一想法提供了新的支撑。
为了在具身环境中解决复杂任务,智能体需要深入理解世界并选择成功的行动。世界模型通过学习从智能体(如机器人或电子游戏玩家)的视角预测潜在行动的未来结果,为实现这一目标提供了一种有前景的方法。
通过这种方式,世界模型使智能体能够深入理解世界,并具备通过在想象中进行规划或强化学习来选择行动的能力。此外,原则上世界模型可以从固定数据集中学习,这使得智能体能够纯粹在想象中进行训练,而无需在线交互。对于许多实际应用而言,离线优化行为很有价值,例如物理世界中的机器人,在这种情况下,与未充分训练的智能体进行在线交互往往不安全。
世界模型智能体 —— 如 Dreamer 3—— 是迄今为止在游戏和机器人领域表现最佳且最为稳健的强化学习算法之一。虽然这些模型在其特定的狭窄环境中速度快且准确,但其架构缺乏拟合复杂现实世界分布的能力。可控视频模型,如 Genie 3,已在多样的真实视频和游戏上进行训练,并实现了多样的场景生成和简单交互。这些模型基于可扩展架构,如 diffusion transformer。然而,它们在学习物体交互和游戏机制的精确物理规律方面仍存在困难,这限制了它们在训练成功智能体方面的实用性。此外,它们通常需要多个 GPU 才能实时模拟单个场景,这进一步降低了它们在想象训练方面的实用性。
在最近的一篇论文中,来自谷歌 DeepMind 的研究者提出了 Dreamer 4。这是一种可扩展的智能体,它通过在快速且准确的世界模型中进行想象训练来解决控制任务。

-
论文标题:Training Agents Inside of Scalable World Models
-
论文链接:https://www.arxiv.org/pdf/2509.24527v1
-
项目地址:https://danijar.com/project/dreamer4/
Dreamer 4 是第一个仅从标准离线数据集(无需与环境交互)就在具有挑战性的电子游戏《我的世界》(Minecraft)中获得钻石的智能体。

Dreamer 4 利用一种新颖的 shortcut forcing 目标和高效的 Transformer 架构,准确学习复杂的物体交互,同时实现实时人机交互(在单个 GPU 上)和高效的想象训练。作者表示,该世界模型能够准确预测《我的世界》中广泛的语义交互,性能大幅优于以往的世界模型。

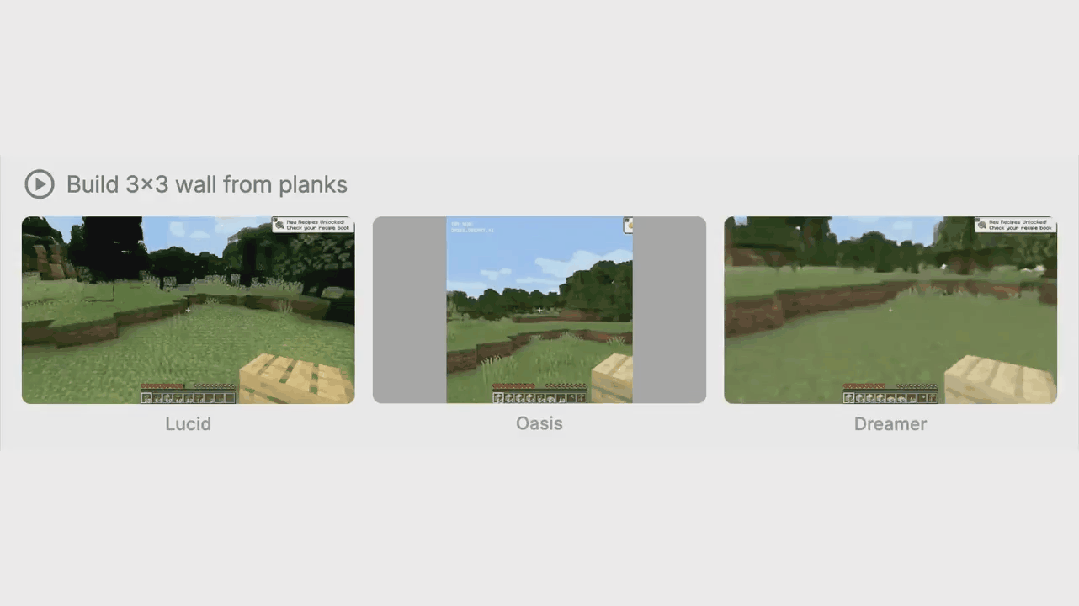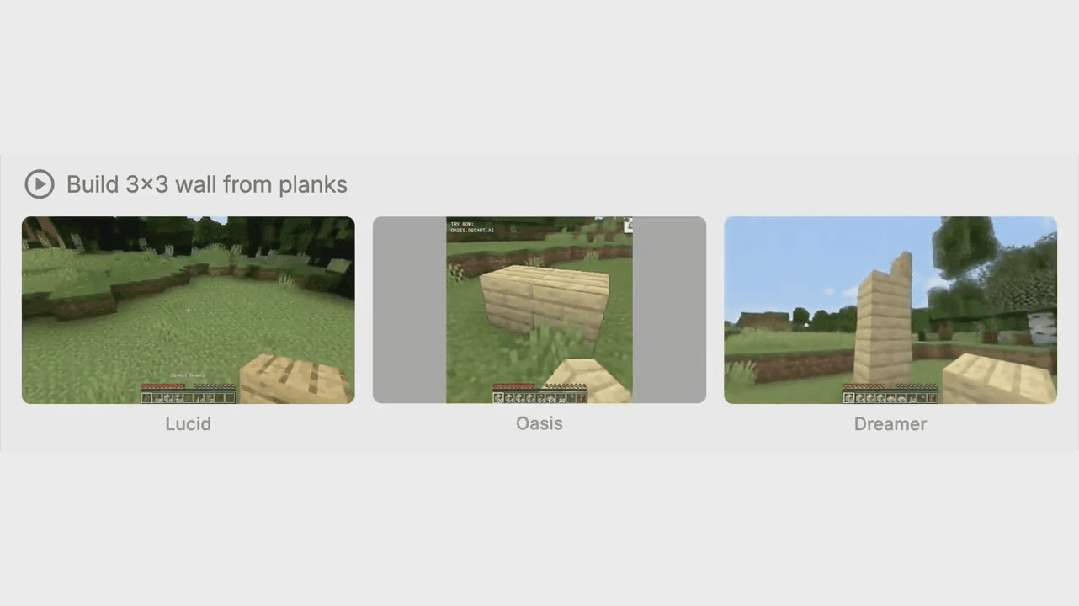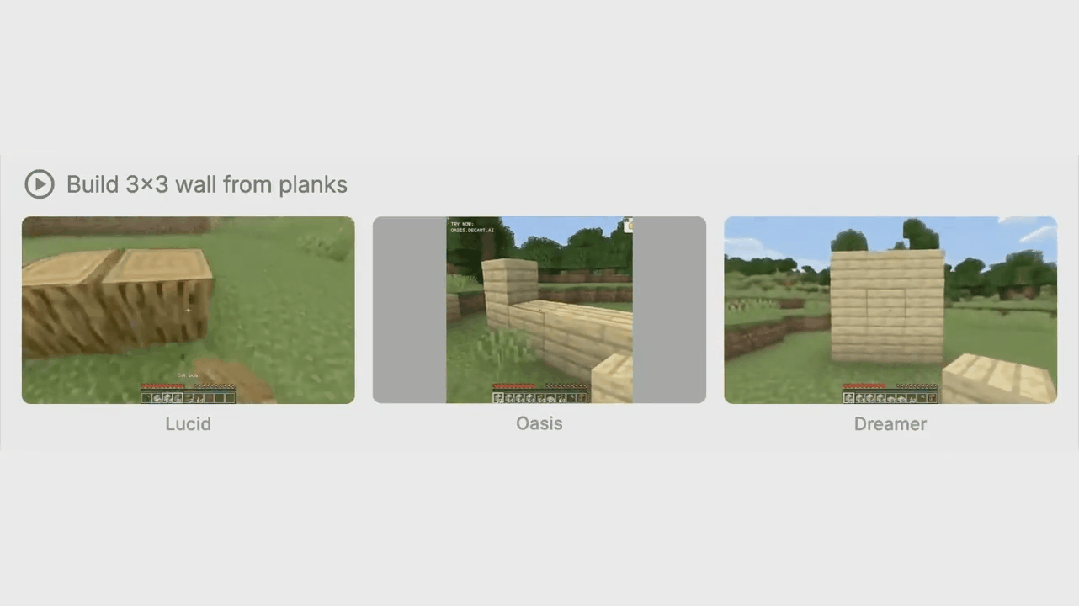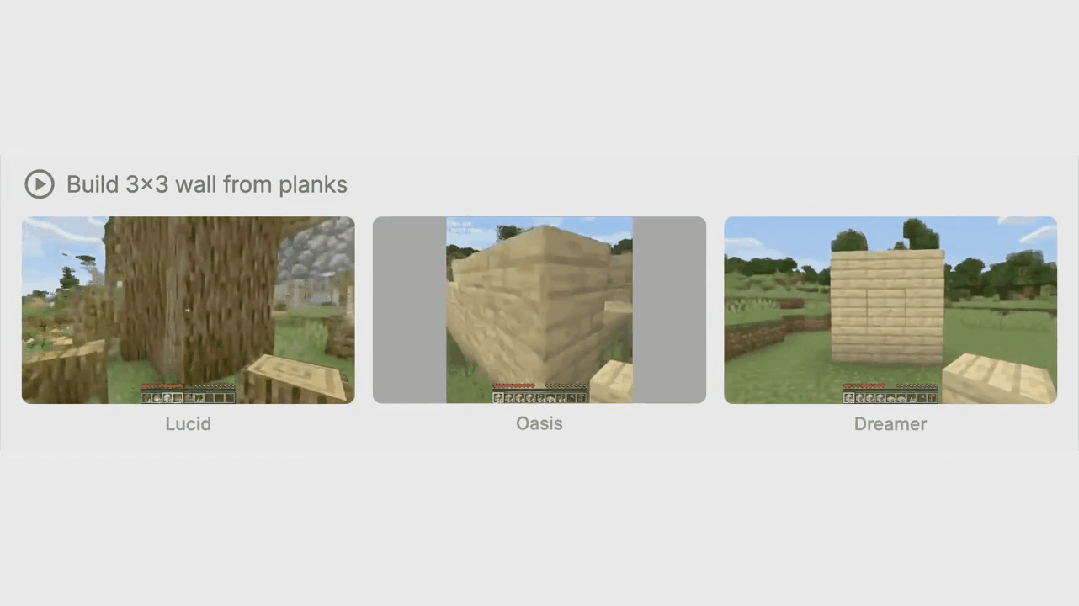
此外,Dreamer 4 可以在大量无标签视频上进行训练,并且只需要少量与动作配对的视频。这为未来从多样的网络视频中学习通用世界知识开辟了可能性,因为这些网络视频没有动作标签。
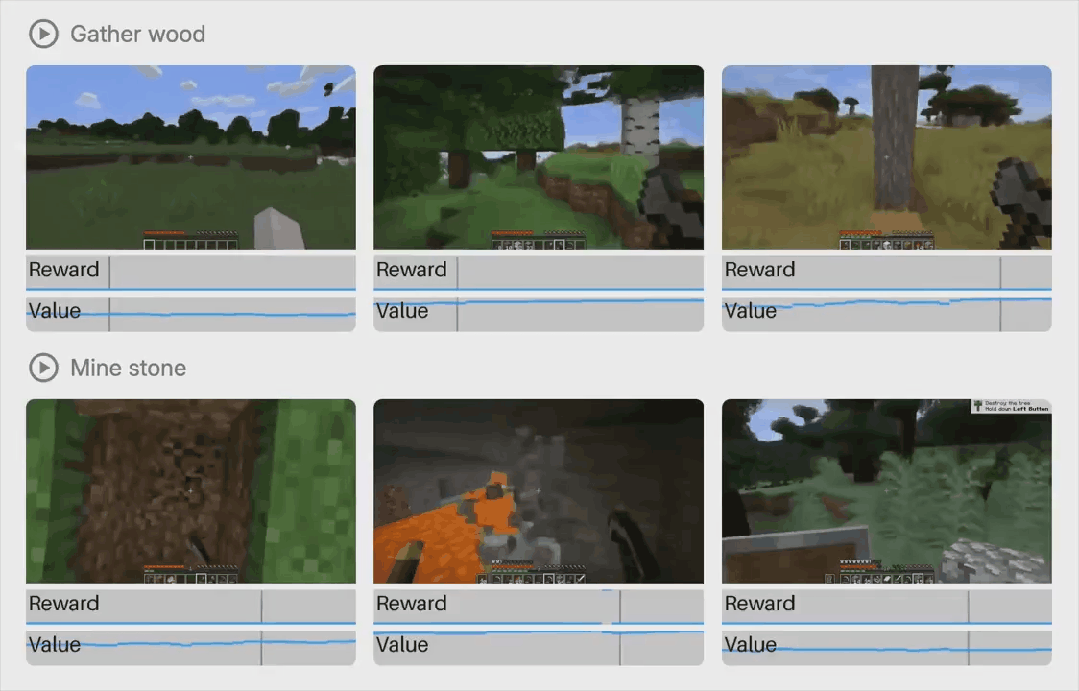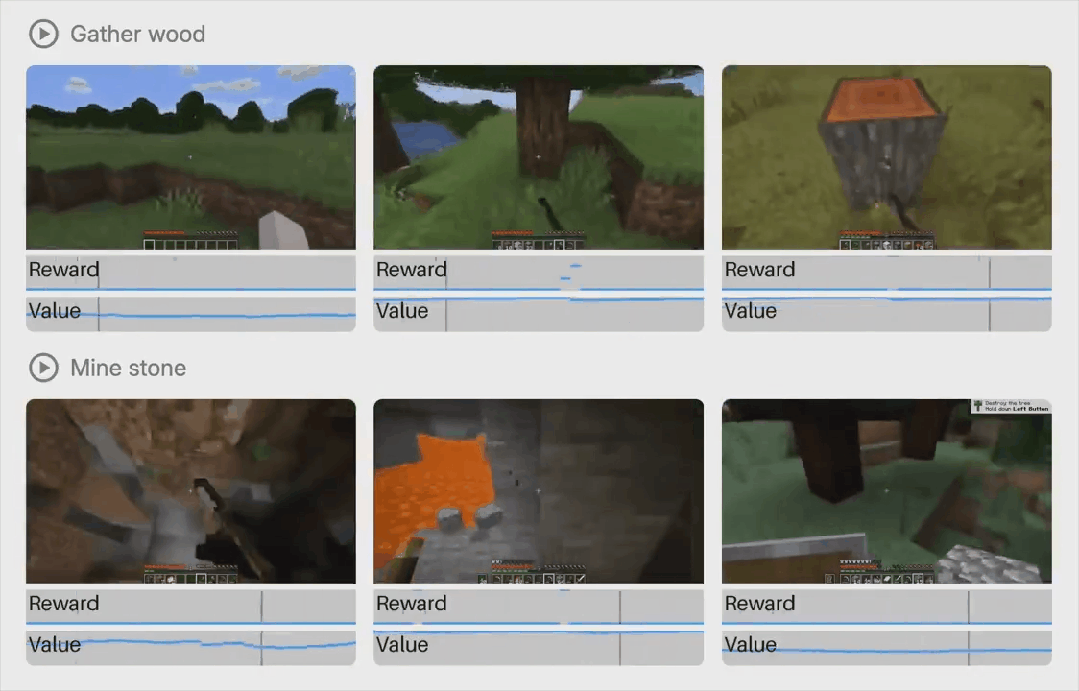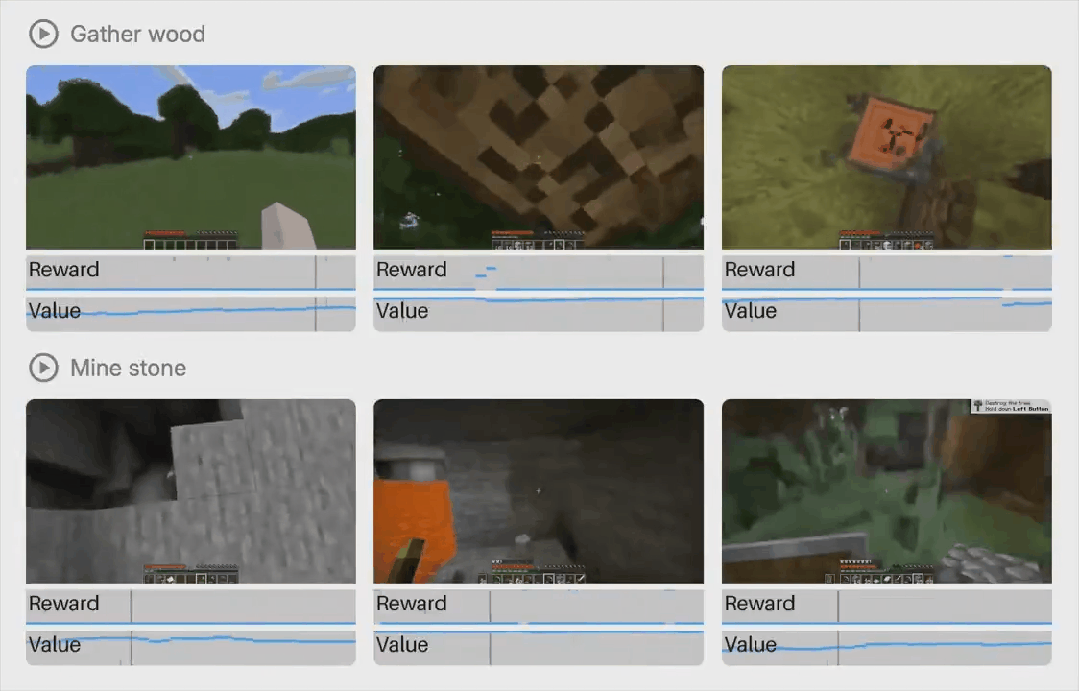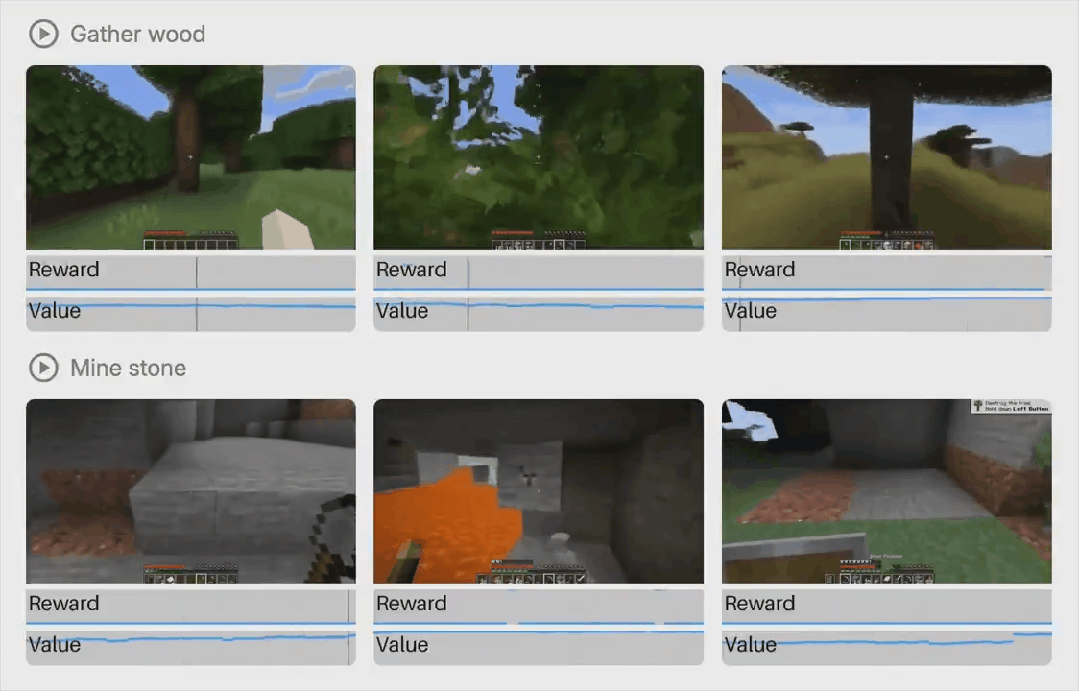
模型设计概览
Dreamer 4 是一种可扩展的智能体,它通过在快速且准确的世界模型中进行强化学习来学习解决复杂的控制任务。
如图 2 所示,该智能体由一个 tokenizer 和一个动力学模型组成。tokenizer 将视频帧压缩为连续表示,动力学模型根据交错的动作预测这些表示,两者均使用相同的高效 Transformer 架构。tokenizer 通过掩码自动编码进行训练,动力学模型则通过 shortcut forcing 目标进行训练,以实现少量前向传递的交互式生成,并防止随时间累积误差。
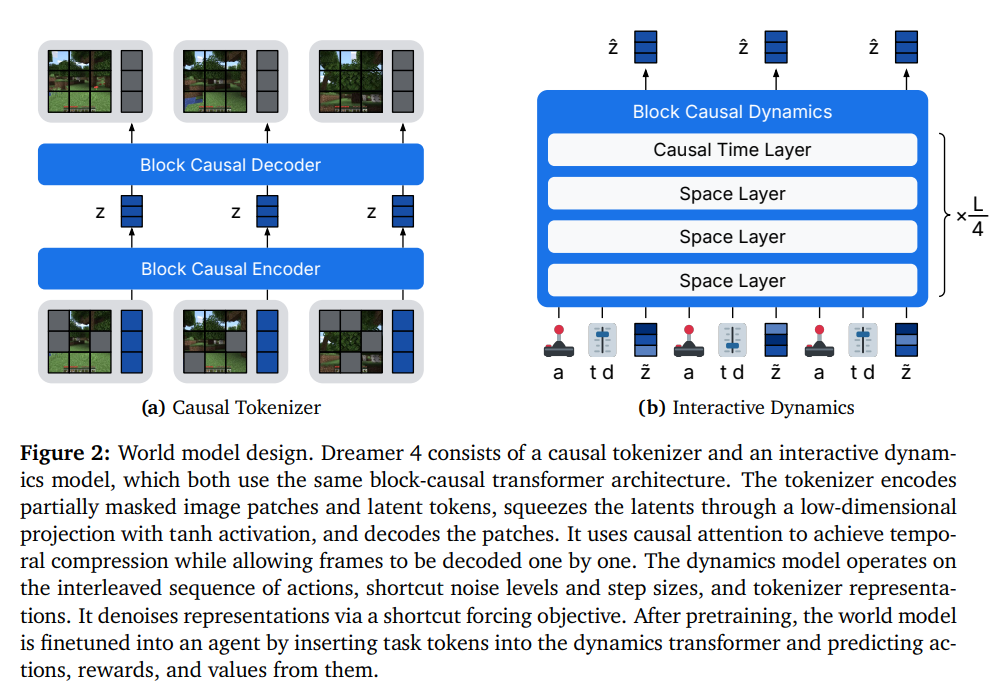
具体来说,tokenizer 对部分被掩码的图像块和 latent token 进行编码,通过带有 tanh 激活的低维投影压缩潜变量,并对图像块进行解码。它使用因果注意力实现时间压缩,同时允许逐帧解码。动力学模型在由动作、shortcut 噪声水平、步长和 tokenizer 表示交错组成的序列上运行。它通过 shortcut forcing 目标对表示进行去噪。在预训练之后,通过在动力学 Transformer 中插入任务 token 并从中预测动作、奖励和值,将世界模型微调为一个智能体。
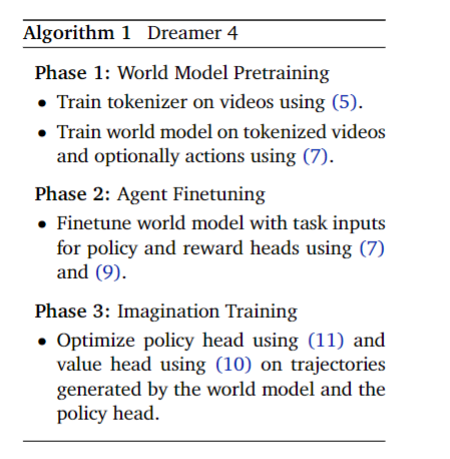
如算法 1 所述,作者首先在视频和动作上预训练 tokenizer 和世界模型,然后通过交错任务嵌入将策略和奖励模型微调至世界模型中,最后通过想象训练对策略进行后训练。为了训练具有多种模态和输出头的单个动力学 Transformer,作者通过对均方根(RMS)的运行估计对所有损失项进行归一化。
实验结果
离线钻石挑战
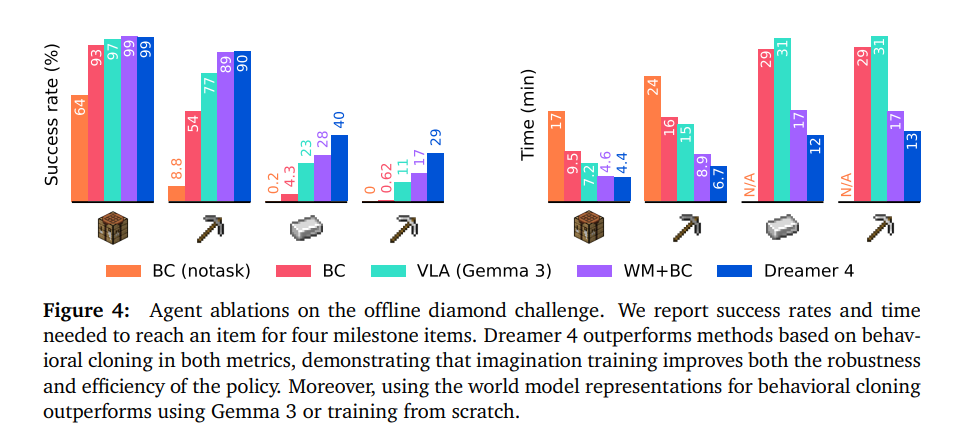
图 3 比较了智能体在钻石任务中的表现。该图记录了在随机世界中从空物品栏开始的 60 分钟游戏情节中获得重要物品的成功率,该成功率是在 1000 个 episode 上计算得出的。通过利用想象力训练,Dreamer 4 是首个纯粹从离线经验中在《我的世界》中获取钻石的智能体。Dreamer 4 在使用的数据量少 100 倍的情况下,大幅超越了 OpenAI 的离线智能体 VPT15。它还超越了 VLA 智能体,后者利用了 Gemma 3 视觉语言模型的通用知识,在制作铁镐的成功率上几乎是 VLA 智能体的三倍。
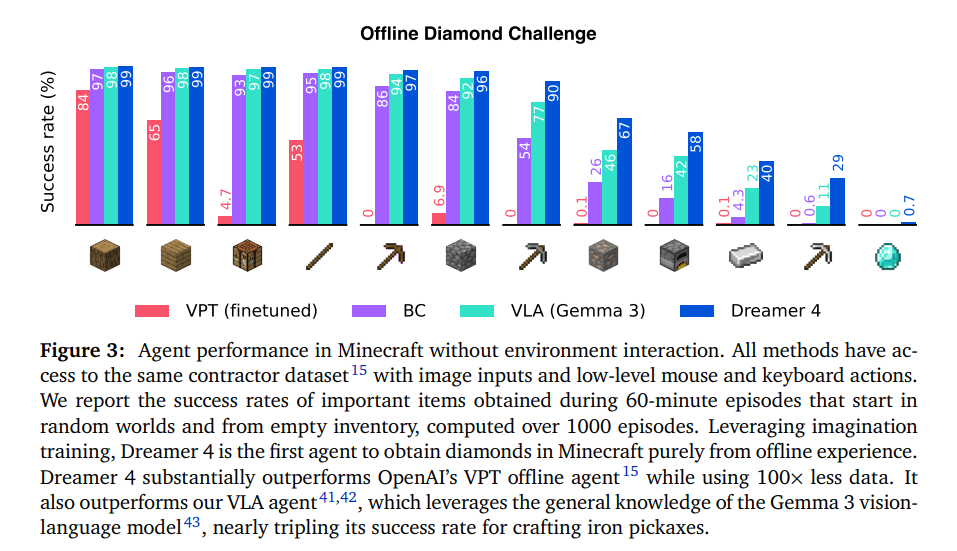
图 4 展示了离线钻石挑战中的智能体消融实验。作者报告了四个关键物品的成功率以及获取物品所需的时间。在这两个指标上,Dreamer 4 的表现均优于基于行为克隆的方法,表明世界模型表示在行为克隆方面优于 Gemma 3 的通用表示。这表明视频预测隐式地学习到了对世界的理解,这对决策也很有用。最后,想象训练不仅持续提高成功率,还使策略更高效,从而能更快达到里程碑。
人类交互
为了评估 Dreamer 4 预测复杂交互的能力,作者在 Minecraft VPT 数据集上训练 Dreamer 4,并将其生成结果与该数据集上的先前的世界模型进行比较。在这项评估中,一名人类玩家尝试在世界模型中游玩以完成任务,如图 5 所示。人类玩家会收到任务描述,世界模型会初始化为任务的起始帧。

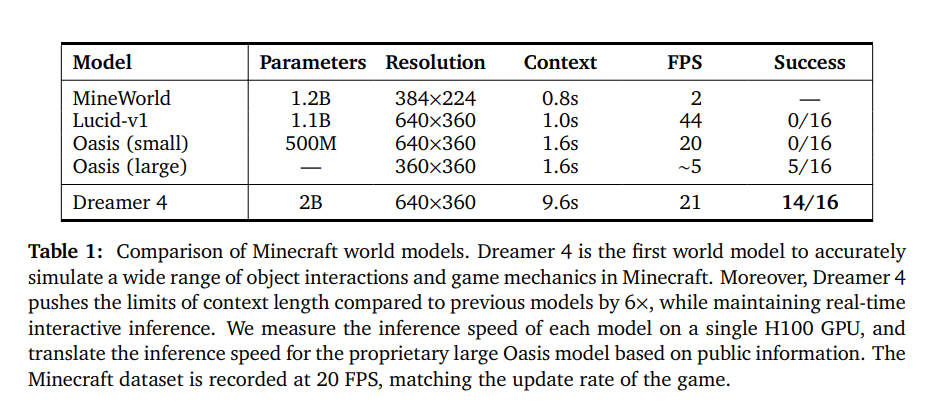
作者选择了一系列多样化的任务,涵盖了广泛的物体交互和游戏机制。这些任务包括挖坑、建造墙壁、砍伐树木、放置和乘坐船只、看向别处然后再看向物体、与工作台和熔炉交互等等。他们将 Dreamer 4 与世界模型 Oasis46、Lucid-v147 和 MineWorld48 进行比较。请注意,作者无法直接与 Genie 3 进行比较,因为它仅支持相机操作和一个通用的 “交互” 按钮,而 Minecraft 需要更通用的鼠标和键盘操作空间。表 1 总结了所比较的模型。完整结果见图 12 至图 14。



动作生成
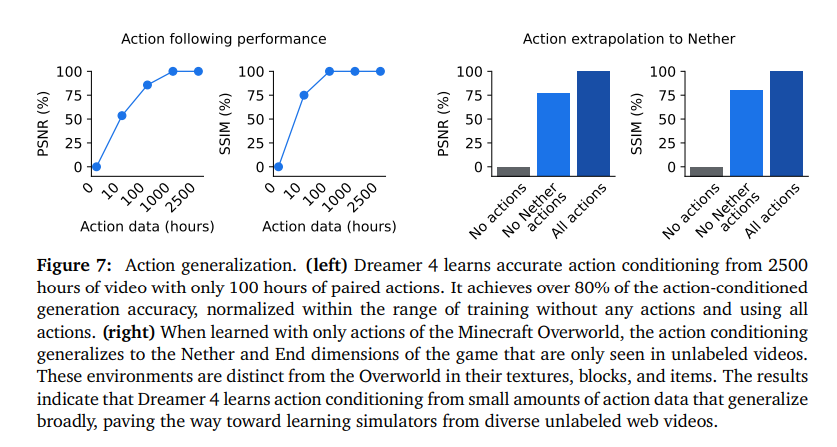
图 7 展示了与完全不使用动作训练以及使用所有动作训练相比,动作条件的质量情况。仅使用 10 小时的动作时,与使用所有动作训练的模型相比,Dreamer 4 的 PSNR 达到 53%,SSIM 达到 75%。使用 100 小时的动作时,性能进一步提升,PSNR 达到 85%,SSIM 达到 100%。这一结果表明,世界模型从无标签视频中吸收了大部分知识,仅需要少量的动作。
更多细节请参见原论文。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com