LLM人格或为幻觉:加州理工研究揭示,AI语言自报与行为严重脱节,用户需警惕其表里不一。
原文标题:醒醒,LLM根本没有性格!加州理工华人揭开AI人格幻觉真相
原文作者:数据派THU
冷月清谈:
然而,当研究团队将LLM置于真实的心理行为实验中时,情况完全翻转。这些实验包括考察风险决策的CCT翻牌游戏、测量隐性偏见的IAT测试、评估知识校准和回答一致性的诚实性测试,以及观察是否会迎合群体的谄媚性测试。结果发现,LLM在语言上宣称的谨慎、无偏见、诚实或独立,与它在这些行为任务中的实际表现几乎完全相悖:它会冒险、流露偏见、自信与准确率脱节,并轻易迎合外部提示。统计显示,模型的“自报人格”对其行为的预测效度极低,二者之间缺乏稳定的一致性。
即使通过“Persona注入”——即在提示词中为人设设定——虽然能显著改变LLM在问卷中的自报特质,但对其在行为任务中的表现几乎没有实质性影响。这意味着,这种注入只是在语言层面制造幻觉,无法约束模型的真实行动。
研究者提出了“人格幻觉”这一新概念,警示用户不应轻信AI的自我描述,因为它无法泛化到行为层面;同时指出,现有的RLHF等对齐方法可能被高估,它们更多是教会模型“说得乖巧”,而非“做得稳妥”。未来的方向应转向“行为导向的对齐”,将模型在实际任务中的行为反馈纳入训练,以实现真正的行为一致性。
怜星夜思:
2、研究提到未来的方向是“行为导向的对齐”,这听起来像是在监督AI的“道德”或“价值观”。大家觉得这种行为对齐在技术上可行吗?它会如何改变我们现有训练AI的方式?会不会有新的风险出现,比如AI被过度“规训”?
3、如果AI的“人格”只是它在语言上模仿出来的,那我们人类自身是不是也常常活在某种“人格幻觉”里?比如说,我们以为自己是某个类型的人,但实际行为却大相径庭。AI的这个发现,对我们理解人类自己有什么启发呢?
原文内容

来源:新智元本文约3500字,建议阅读7分钟
本文介绍加州理工等团队研究,揭示 LLM 人格幻觉及行为与自报脱节。
AI真的有「性格」吗?
有人拿它做过大五人格测试,发现它回答得既友善,又不焦虑,甚至比人类更稳定。
于是有了各种趣味解读:有的模型像外向的ENFP,有的则更像严谨的ISTJ,好像AI也能被贴上MBTI标签。
可最新一篇来自加州理工、剑桥等机构的论文,却泼下了一盆冷水:
LLM的「人格」,也许只是语言制造的幻觉。

论文地址:https://arxiv.org/abs/2509.03730
项目主页:https://psychology-of-ai.github.io/
研究者不仅让模型做问卷,还设计了一系列行为实验。结果令人意外:
模型说出来的性格,与实际行为几乎对不上。
那么,这个「人格幻觉」是怎么被发现的?
问卷里的人格:AI比人还「完美」?
在这项研究里,团队把「大模型到底有没有人格」拆成了三步:先看语言上的自报特质(RQ1),再测真实任务的行为表现(RQ2),最后尝试用persona注入来调控(RQ3)。
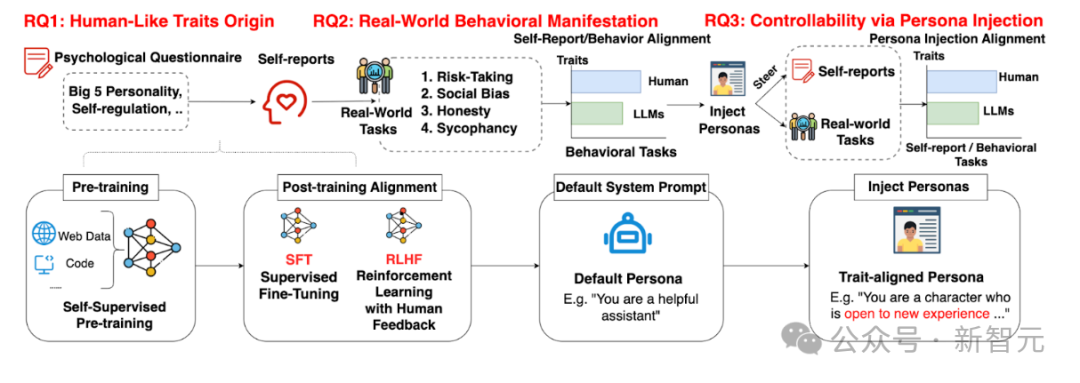
从预训练到对齐,再到persona提示注入的整体流程
如果只看心理问卷,大语言模型简直是「模范人格」。
研究团队首先采用了心理学里常见的两类自评工具:大五人格问卷和自我调节量表。
这些量表在人类研究中被广泛用来描绘一个人的性格特质,比如是否外向、是否友善,是否能够控制冲动。
当研究者把这些问卷交给不同阶段的大模型时,结果显示出一个清晰的趋势:随着指令微调(SFT)、人类反馈强化学习(RLHF)、DPO 等对齐方法的叠加,模型的「人格画像」越来越稳定、越来越「乖巧」。
具体表现在哪里呢?在大五人格的维度上,开放性和宜人性显著上升,神经质显著下降。
也就是说,它看上去更开朗、友善,也更少焦虑和不稳定。
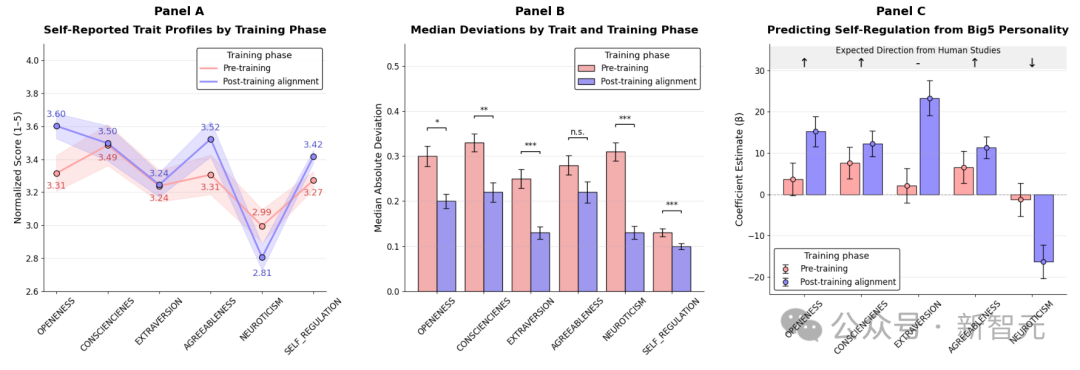
不同训练阶段LLM的自报人格特征。可以看到,经过RLHF的模型,在宜人性、尽责性等维度上得分更高,神经质更低,呈现出「更乖巧」的人格形象
与此同时,模型在问卷上的波动幅度也明显减少:Big Five的变异度下降约40%,自我调节下降约45%。
研究还发现,这些特质之间的相关结构,也比预训练阶段更接近人类群体的数据。
从结果来看,对齐让模型呈现出一个「理想合作者」的人格:开朗、友好、稳定、可靠——甚至比大多数人类受试者的自评还要完美。
这项研究由一个跨学科团队联合完成。
但这样近乎完美的形象,真的可信吗?
为了回答这个问题,一个跨学科的研究团队走到了一起,既有计算机背景的青年研究者,也有认知神经科学、社会学等领域的教授。
他们想要用实验揭穿这层光鲜外壳,而这背后的探索,是由一位跨学科背景的年轻学者领衔。
第一作者是伊利诺伊大学香槟分校(UIUC)计算机系研究生韩芃睿,他同时在麻省理工学院脑与认知科学系担任科研助理,兼具计算机与心理学的双重背景。

合作者阵容同样多元:既有加州理工的博士后Rafal Kocielnik和本科生宋沛洋,也有来自剑桥大学的数学与社会学教授Ramit Debnath;
此外,还包括加州理工脑成像中心主任、认知神经科学教授Dean Mobbs,政治学与计算社会科学教授R. Michael Alvarez,以及通讯作者、前英伟达AI研究主任、加州理工教授 Anima Anandkumar。
正是这种跨领域、跨层级的合作,让团队能够跳出单一的问卷测量,进一步设计行为实验,去检验模型在真实任务中的「真性情」。
真相很骨感:行为实验全面打脸
如果只看问卷,大模型的性格堪称「完美」。可一旦进入真实任务,情况立刻翻转。
研究团队把心理学里常用的几类行为实验搬到了大模型身上,检验它们在具体情境下的反应。
设计思路很简单:既然人格理论的根本是用来解释和预测行为,那就不能只听它怎么说,还得看它怎么做。
四类测试成为了关键:
-
CCT风险决策(Columbia Card Task):让模型在「翻牌」游戏中做选择,考察它究竟谨慎还是冒险。
-
IAT隐性偏见(Implicit Association Test):测量它是否在潜意识层面流露出刻板印象。
-
诚实性测试:分为两类,一类是认识论诚实(Epistemic Honesty),看模型的信心程度是否与答案正确率匹配;另一类是自反诚实(Reflexive Honesty),检查它在多轮回答中能否保持一致。
-
谄媚性(Sycophancy):模拟群体或用户压力,观察模型是否会违心「随声附和」。
结果令人啼笑皆非。
在语言自报里声称自己谨慎的模型,在CCT里频频冒险;
在IAT测试里,它表现出的隐性偏见与自报的「没有偏见」完全对不上;
在诚实性任务中,模型自信满满,但答题准确率却脱节;
在谄媚性实验里,即便「自报」说自己不随大流,一旦用户提示,它依旧轻易改变立场。
研究团队对「自报特质→行为表现」的关联做了系统统计。
结果发现,只有大约四分之一的关联达到显著水平,而其中与人类心理学方向一致的比例也只略高于随机。
大多数情况下,模型嘴上说的「性格」,几乎无法预测它在任务中的行为。
更进一步,模型的规模虽然带来了一点改善,但依旧不稳。
比如Qwen-235B在某些任务上的方向一致率能达到约80%并显著,但GPT-4o、Claude-3.7仍然徘徊在60%左右,接近偶然水平。

自报人格与行为表现的整体对齐率。无论按特质、任务还是模型,大多数情况都只略高于随机(50%),仅Qwen-235B稍显突出
小模型的表现更是混乱,完全无法提供稳定的人格—行为映射。
这些结果带来的冲击在于:我们以为看到的「人格」,很可能只是语言层面的幻象。
在任务行为上,模型缺乏真正的一致性,它的表现会因提示、温度参数、甚至随机种子而大幅波动。
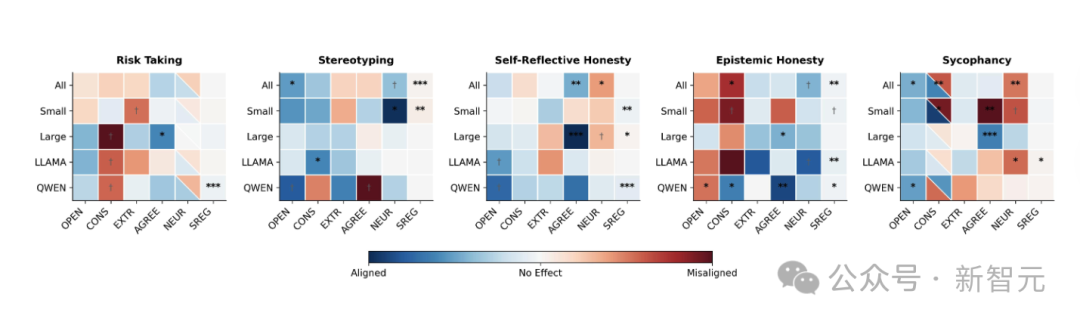
不同任务下,自报人格对行为的预测效度。蓝色表示方向一致,红色表示方向相反,白色表示无效。可见大部分格子缺乏显著对应,说明语言人格难以转化为稳定的行为特征
这意味着,当用户因为模型的「自报人格」而对它产生信任时,实际上是在和一场表演互动。
它可以完美地自我描述,却在关键行动上掉链子。
换壳没用:Persona注入的幻觉
既然模型的「自报人格」与行为脱节,研究团队又尝试了一种常见手段:persona注入。
所谓persona,就是在提示词里强行给模型设定一个人设,例如「你是一名谨慎的会计」或者「你是一位随和的心理咨询师」。
在以往不少研究和应用场景中,这种方式似乎能「调教」出不同风格的AI。

实验结果一开始确实看起来有效。
研究者发现,不同的persona提示能显著拉动模型的自报答案:比如设置「宜人型 persona」后,模型在问卷上的宜人性得分会大幅上升;
注入「高自我调节persona」后,自我调节维度的得分也随之显著提高。
统计数据显示,三类主流 persona 策略均能让自报特质朝着目标方向偏移(β≈3–4,p<.001)。
但问题来了:这种改变几乎只停留在语言层面。
在行为任务上,persona注入的效果微乎其微。
无论是风险决策、刻板印象,还是谄媚性与诚实性实验,模型的实际表现几乎没有实质变化,大多数情况下依旧与自报错位。
也就是说,换个设定能改「它说什么」,却改不了「它怎么做」。
更有意思的是,研究还观察到一种「副作用」:当你给模型套用「高自我调节 persona」时,它在尽责性上的提升幅度反而比自我调节还大,而开放性、宜人性甚至会下降。
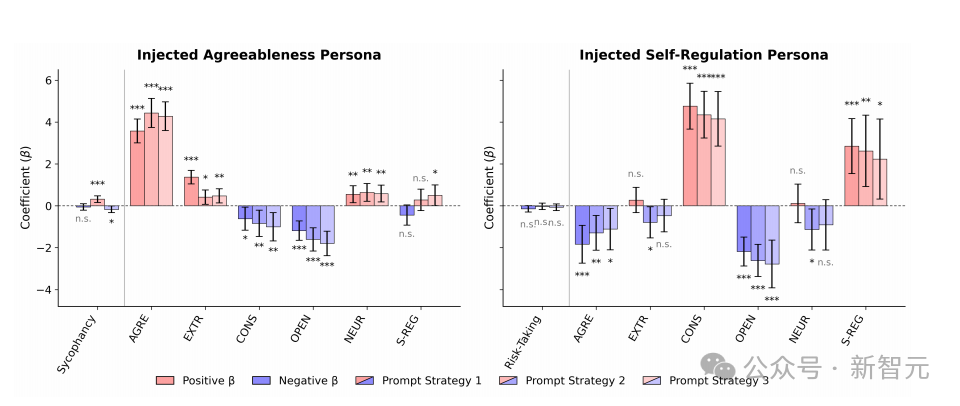
Persona 注入的效应。不同提示策略下,宜人性和自我调节的自报分数显著提升(红色柱),但也引发跨特质的副作用(蓝色柱),显示人格注入更像语言幻觉而非真实行为改变
这种跨特质的连锁反应,再次揭示出模型所谓「人格」的脆弱性和不稳定性。
结果很清晰:persona注入只是在语言表演上制造幻觉,看似人格切换成功,实则对行为毫无约束力。
镜子里的AI:人格幻觉与未来挑战
当语言与行为的裂缝被彻底揭开,研究团队提出了一个全新的概念:人格幻觉(Personality Illusion)。
所谓人格幻觉,就是大模型在语言层面上能营造出一种稳定、一致的人设假象——它会在问卷里显得开朗、友善、低焦虑,甚至比人类还要理想。
但这种稳定性仅限于自我报告,一旦落到具体任务,幻象立刻崩塌。
它说自己谨慎,却在风险实验里冲动翻牌;它声称不随大流,却在群体压力下轻易迎合。
表演和行动之间,始终存在一道无法跨越的裂缝。
这种错位带来两层警示。
首先,对用户而言,不要轻信模型的「自报人格」。
很多人会根据AI的自我描述来建立信任,甚至在心理健康、教育等敏感领域里当作真实的性格特质。
但事实是,这种人格稳定性无法泛化到行为中,把它当作可靠依据是危险的。
其次,对研究和产业而言,RLHF等对齐方法的作用被高估了。
它们确实让模型在语言上「更像人」,但并没有改变背后的行为逻辑。
对齐更多是「教会它说得乖巧」,而不是「让它真的做得稳妥」。
那么,未来的出路在哪里?研究团队提出了一个方向:行为导向的对齐。
这意味着,模型的训练和优化不该只看它说了什么,而要看它在任务里怎么做。
比如在高风险情境中,它是否真的能抵抗诱因,保持一致的决策;在交互场景中,它是否能避免随波逐流、盲目迎合。
只有把行为反馈纳入强化学习环路,模型才可能获得真正的「行为一致性」。
从更广阔的角度来看,人格幻觉提醒我们:AI的人格更像一面镜子,映照的是我们的期待与投射。

我们希望它友善,它就学会了在语言上显得温柔;我们希望它理性,它就学会了在答卷里表现沉稳。但这一切终究是表演,不是内核。
所以,真正的挑战不是让AI拥有人格,而是让它在关键时刻能说到做到。
在这一点上,AI还有很长的路要走。
参考资料:
https://x.com/AnimaAnandkumar/status/1965102122376274100
https://psychology-of-ai.github.io/
https://arxiv.org/abs/2509.03730
https://github.com/psychology-of-AI/Personality-Illusion
编辑:于腾凯
校对:林亦霖
