YOLO-Count来袭!清华等提出可微分对象计数模型,通过“基数图”精准指导文生图AI生成指定数量物体。
原文标题:ICCV 2025 | 清华等提出YOLO-Count:让AI“心中有数”,可微分“对象计数”精准控制图像生成
原文作者:数据派THU
冷月清谈:
YOLO-Count的核心创新要素包括:
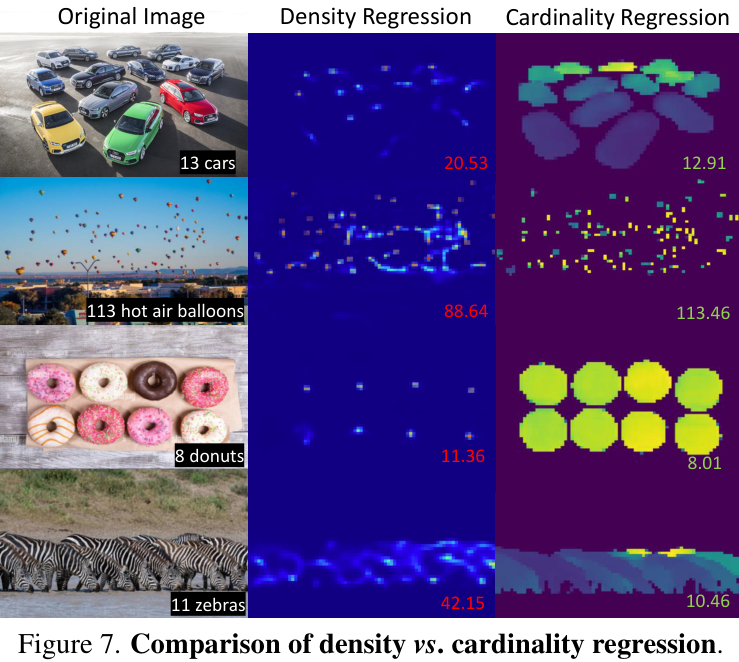
首先,研究者们引入了“基数图”(Cardinality Map)这一新颖的回归目标。与传统密度图不同,基数图的每个网格单元直接回归一个[0, 1]之间的值,代表该单元包含一个对象的“分数”。将整个图的数值求和,即可得到总的对象数量。这种设计巧妙地解决了对象大小和空间分布变化带来的计数偏差问题,确保无论物体大小,每个物体都贡献大约为1的总和。
其次,YOLO-Count继承了YOLO-World架构的开放词汇能力,并实现了完全可微分。这意味着它不仅能对任意类别的对象进行计数,更关键的是,YOLO-Count计算出的计数误差能够通过梯度下降的方式,反向传播给文生图模型,从而在生成过程中实时“纠正”其行为,使其更精确地按指令生成指定数量的物体。
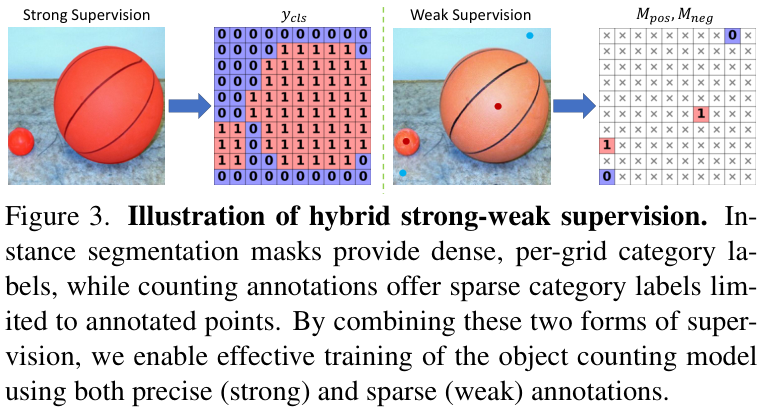
最后,为了高效训练模型,YOLO-Count采用了混合强弱监督方案,能够同时利用带有精确分割掩码的“强”标注数据和只有点标注或数量标注的“弱”标注数据,大大拓宽了可用训练数据的范围,提升了模型的泛化能力。
实验结果表明,YOLO-Count在T2I数量控制任务中表现卓越,显著降低了生成数量与提示数量之间的误差,并在通用对象计数任务中达到了SOTA(State-of-the-Art)精度。YOLO-Count的问世,弥合了对象计数与生成式AI之间的鸿沟,为可控内容生成领域带来了新的突破,让“所说即所得”的AI创作更进一步。
怜星夜思:
2、YOLO-Count的核心“基数图”概念听起来很巧妙。如果未来有一个通用的“基数图”可以适用于所有可控生成任务,你觉得它除了计数还能解决哪些问题?比如形状控制、纹理细节控制,甚至更抽象的属性?大家脑洞大开地聊聊吧!
3、文章提到了YOLO-Count的“可微分”特性是关键。在AI模型开发中,可微分性究竟意味着什么?为什么它对于“指导”T2I模型如此重要?如果一个模型不可微分,会有哪些局限性呢?
原文内容

来源:人工智能前沿讲习本文约1800字,建议阅读5分钟
本文介绍了高质量合成图表数据集,提升开源MLLM图表理解能力。
本文介绍了高质量合成图表数据集,提升开源MLLM图表理解能力。

你是否曾让AI画“三只猫”,结果它却给你画了五只,或者干脆糊成一团?当前强大的文生图(T2I)模型虽然在艺术风格和真实感上表现惊人,但在精确控制生成对象的“数量”上却常常“数不清”。
为了解决这个业界难题,来自清华大学、加利福尼亚大学圣迭戈分校(UC San Diego)和加利福尼亚大学伯克利分校(UC Berkeley)的研究者们提出YOLO-Count,一个创新的、可微分的、开放词汇的对象计数模型。它不仅在通用计数任务上达到了SOTA水平,更重要的是,它能作为“指导老师”,教会T2I模型如何精确地按指令生成指定数量的物体。

-
作者: Guanning Zeng, Xiang Zhang, Zirui Wang, Haiyang Xu, Zeyuan Chen, Bingnan Li, Zhuowen Tu
-
机构: 清华大学; 加州大学圣地亚哥分校; 加州大学伯克利分校
-
论文标题: YOLO-Count: Differentiable Object Counting for Text-to-Image Generation
-
论文地址: https://arxiv.org/pdf/2508.00728v1
-
录用会议: ICCV 2025
研究背景
精确的数量控制是实现可控内容生成的关键一环。然而,现有的T2I模型,如Stable Diffusion XL (SDXL),在遵循包含数字的文本提示时表现不佳。
传统的对象计数方法,无论是基于检测还是基于密度图回归,都难以直接有效地集成到T2I模型的生成过程中。基于检测的方法通常是不可微分的,无法通过梯度指导生成;而基于密度图的方法在处理稀疏对象或尺寸变化大的对象时存在偏差。
如何设计一个既能准确计数,又能与生成模型无缝协作的模块,是当前面临的核心挑战。
YOLO-Count:核心方法与创新
为了解决上述挑战,研究者们提出了YOLO-Count。它是一个完全可微分的架构,能够以端到端的方式进行优化,并指导生成模型。
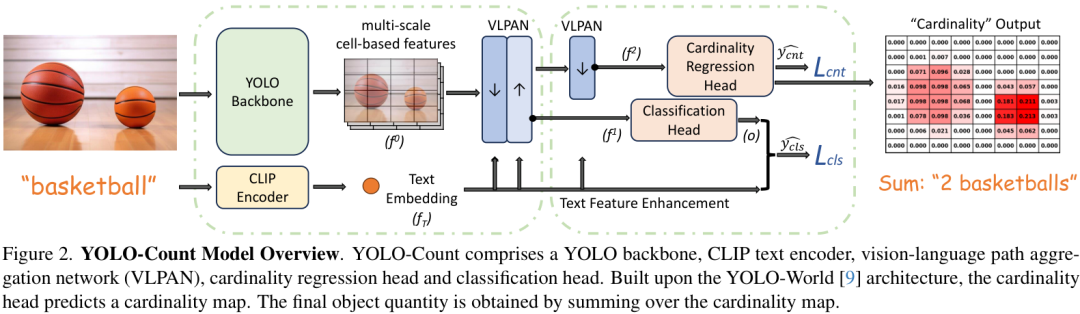
其核心创新主要有以下几点:
1. 基数图 (Cardinality Map):
这是YOLO-Count最核心的贡献。研究者提出了一种新颖的回归目标——基数图。与传统密度图不同,基数图的每个网格单元(grid cell)直接回归一个[0, 1]之间的值,表示该单元“包含”一个对象的“分数”。将整个图的数值求和,便能得到总的对象数量。这种设计巧妙地解决了对象大小和空间分布变化带来的计数偏差问题,无论物体大小如何,每个物体都贡献大约为1的总和。
2. 可微分与开放词汇:
YOLO-Count建立在YOLO-World架构之上,继承了其开放词汇的能力,可以对任意类别的对象进行计数。更重要的是,整个模型是完全可微分的。这意味着YOLO-Count计算出的计数值与期望值之间的误差,可以通过梯度下降的方式,反向传播给T2I模型,从而在生成过程中实时“纠正”其行为,使其生成正确数量的对象。
3. 混合强弱监督 (Hybrid Strong-Weak Supervision):
为了有效地训练模型,YOLO-Count采用了一种混合监督方案。它既可以利用带有精确分割掩码的“强”标注数据,也可以利用只有点标注或数量标注的“弱”标注数据。这大大扩展了可用训练数据的范围,提升了模型的泛化能力。
实验与结果分析
论文进行了广泛的实验,验证了YOLO-Count在通用计数和T2I数量控制两方面的卓越性能。
在T2I数量控制任务中,如下图所示,与基线模型(SDXL)和其他控制方法相比,YOLO-Count显著降低了生成数量与提示数量之间的误差,无论是在训练过的类别还是未见过的类别上,都表现出强大的控制力。
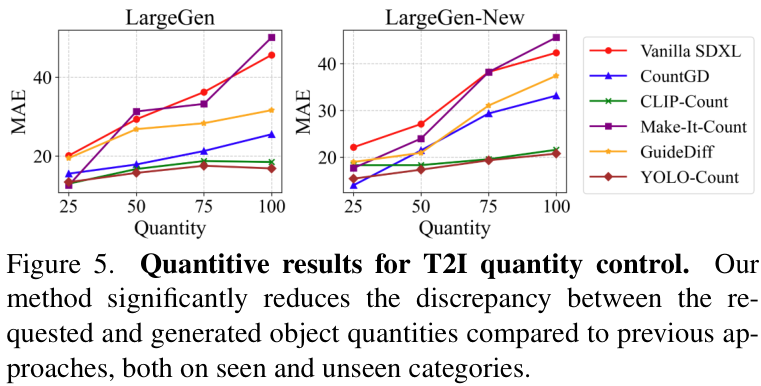
从定性结果来看,效果一目了然。当提示词要求“5个苹果”时,基线模型可能生成任意数量的苹果,而经过YOLO-Count指导后,模型能够稳定地生成5个苹果,且保持了高质量的图像效果。
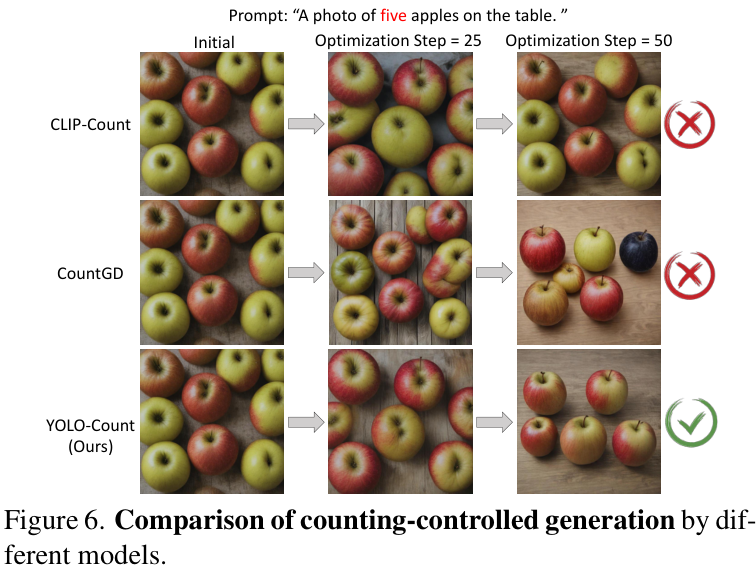
在通用对象计数任务中,YOLO-Count同样取得了SOTA的精度。

论文贡献与价值
YOLO-Count的提出,为可控内容生成领域带来了重要突破:
-
弥合差距:成功地将在计算机视觉中发展成熟的对象计数能力与生成式AI的需求相结合,为T2I模型的细粒度控制开辟了新途径。
-
核心创新:提出的“基数图”是一种新颖且有效的回归目标,为解决通用计数问题提供了新的SOTA方案。
-
增强可控性:其可微分的特性使其能作为即插即用的指导模块,显著提升了现有T2I模型在数量控制上的精确性和鲁棒性。
-
实用性强:混合监督的学习方式降低了对数据标注的要求,使其更具现实应用价值。
总而言之,YOLO-Count不仅是一个更精确的计数器,更是一个有效的“生成指导器”,它让我们离“所说即所得”的AI内容创作更近了一步。
