北大DKP++框架提出分布驱动的终身学习范式,通过分布原型建模与跨域对齐,有效解决行人重识别中的灾难性遗忘问题,无需保留历史样本,提升了持续学习与知识巩固能力。
原文标题:IEEE TPAMI 2025 | 北京大学提出分布驱动的终身学习范式,用结构建模解决灾难性遗忘
原文作者:机器之心
冷月清谈:
行人重识别(ReID)技术在智能监控、交通等领域应用广泛,但面对环境变化导致的行人图像分布迁移,传统模型适应性不足。为应对此挑战,LReID任务要求模型在持续学习新域数据的同时,保持对旧知识的辨识能力。然而,现有LReID方法多通过保留历史样本(存在数据隐私和存储成本问题)或知识蒸馏(限制新知识学习能力)来缓解遗忘,且原型学习技术因仅保留单一特征中心而忽略类内差异,难以满足细粒度匹配需求。
DKP++框架的核心创新在于:
1. 它通过**分布原型学习**机制,利用实例级分布建模捕捉细粒度信息,构建鲁棒的类别级分布原型,从而在不存储历史样本的情况下有效保留旧知识,克服了单一特征中心无法有效表征类内差异的局限。
2. 同时,引入**跨域分布对齐**机制,通过输入端分布建模和样本对齐,弥合新旧域数据之间的分布鸿沟,增强历史原型对新数据学习的引导作用,在显著提升模型对历史知识巩固能力的同时,保障了新知识的学习能力。
具体方法实现包括:实例级细粒度建模网络、分布感知的原型生成算法、输入端分布对齐机制以及基于原型的知识迁移模块。实验结果显示,DKP++在已知域性能和未知域泛化性能上均显著优于现有方法,并展现出更高的历史知识巩固能力及对多种基础模型的良好适配性。
这项工作为无样本保留的终身学习技术提供了新范式,未来展望包括与大模型结合进行分布对齐、探索知识主动遗忘机制以及多模态终身学习能力的拓展。
怜星夜思:
2、DKP++不存储历史样本,在隐私保护上听起来很棒。但实际场景中,行人重识别处理的都是非常敏感的个人身份信息。除了不存样本,大家觉得在部署这类“终身行人重识别”系统时,还有哪些伦理和隐私问题需要特别重视,做到万无一失呢?
3、文章说“分布原型”比单一特征中心能更好地捕捉类内差异。但如果面对实际场景中高度不平衡的数据(比如某个身份只有一两张照片)或者极端复杂环境(光线巨差、遮挡严重),大家觉得这种“分布原型”还能保持其理论优势吗?会不会反而因为过度建模噪声而失效?
原文内容

近日,北京大学王选计算机研究所周嘉欢助理教授与彭宇新教授合作在人工智能重要国际期刊 IEEE TPAMI 发布一项最新的研究成果:DKP++(Distribution-aware Knowledge Aligning and Prototyping for Non-exemplar Lifelong Person Re-Identification)。该工作针对终身学习中的灾难性遗忘问题,提出分布建模引导的知识对齐与原型建模框架,不仅有效增强了对历史知识的记忆能力,也提升了模型的跨域学习能力。
本文的第一作者为北京大学北京大学王选计算机研究所助理教授周嘉欢,通讯作者为北京大学王选计算机研究所教授彭宇新。目前该研究已被 IEEE TPAMI 接收,相关代码已开源。

-
论文标题:Distribution-aware Knowledge Aligning and Prototyping for Non-exemplar Lifelong Person Re-Identification
-
论文链接:https://ieeexplore.ieee.org/abstract/document/11120364
-
代码链接:https://github.com/zhoujiahuan1991/TPAMI-DKP_Plus_Plus
行人重识别(Person Re-Identification, ReID)旨在针对跨相机视角、跨地点、跨时间等场景中,基于视觉特征实现对同一行人图像的匹配与关联。该技术在多摄像头监控、智能交通系统、城市安全管理以及大规模图像视频检索等实际场景中具有广泛应用价值。然而,在现实环境中,由于采集地点、拍摄设备和时间条件的不断变化,行人图像的分布会随之发生迁移,导致测试数据与模型训练时所依赖的源数据之间存在显著的域偏移。这一分布漂移问题使得传统 “静态训练 - 固定推理” 的 ReID 范式在长期动态环境中的适应性不足。
为应对这一挑战,研究者提出了更具现实意义的任务设定,终身行人重识别(Lifelong Person Re-ID, LReID)。该任务要求模型在持续接收新域数据的过程中,能够高效地增量学习新知识,同时保持对先前已学习域中身份信息的辨识能力,从而实现跨时间与跨域的长期学习与知识保留。
研究现状
终身行人重识别任务的核心挑战是灾难性遗忘问题,即模型在学习新域知识后,对旧域中行人数据的检索性能大幅降低。为解决该问题,现有方法主要通过保留历史样本或采用知识蒸馏策略来缓解遗忘。然而,保留历史样本的方法存在数据隐私风险和存储开销持续增长的问题;知识蒸馏方法因强制新旧模型输出一致性,制约了模型的可塑性,限制了新知识学习能力。尽管原型学习技术在类增量学习任务中取得了较高性能,但现有方法仅为每个类别保留单一特征中心,忽略了类内分布差异,导致行人的细粒度知识丢失,难以适用于依赖细粒度匹配的终身行人重识别任务。
研究动机
动机 1:分布原型学习。为实现无历史样本存储条件下有效保留历史知识,我们提出通过实例级分布建模挖掘数据中的细粒度信息,进而构建分布原型,提升对不同域数据信息的表征和保存能力。
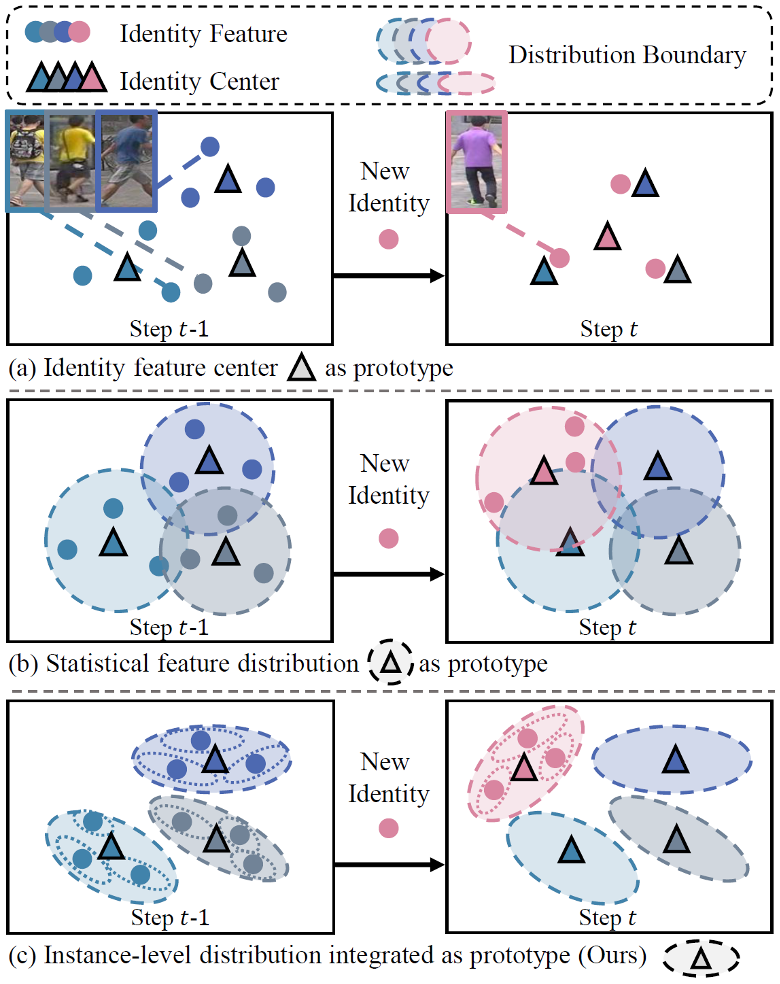
图 1 分布原型学习动机
动机 2:跨域分布对齐。虽然分布原型可有效缓解遗忘问题,由于新旧域数据存在分布鸿沟,造成历史原型对新数据学习的引导和约束作用较弱,导致模型的新知识学习能力和抗遗忘能力仍然受限。为克服该挑战,我们提出引入输入端分布建模并构建跨域样本对齐机制,提升历史分布信息对新域特征学习的引导作用,从而在大幅提升模型对历史知识巩固能力的同时,保障了对新数据知识的学习能力。
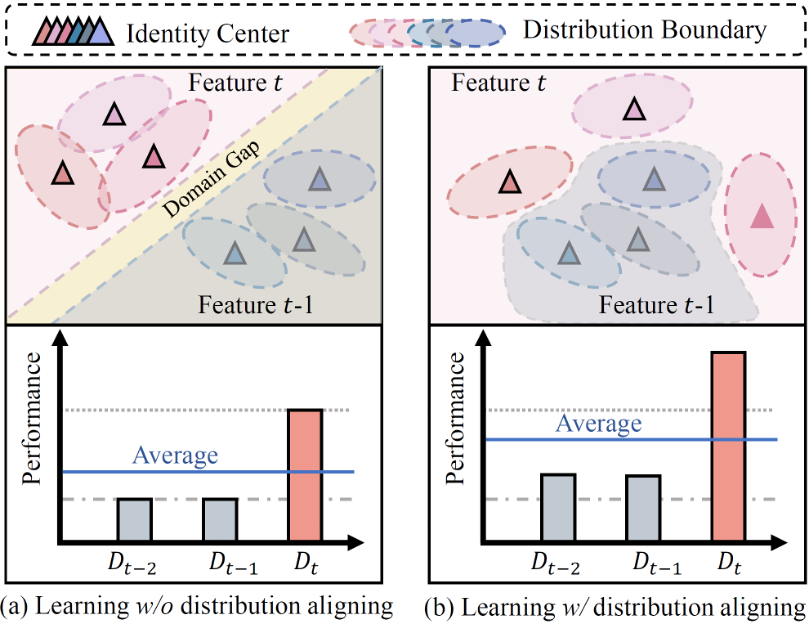
图 2 跨域分布对齐动机
方法设计:分布建模引导的知识对齐与原型建模框架
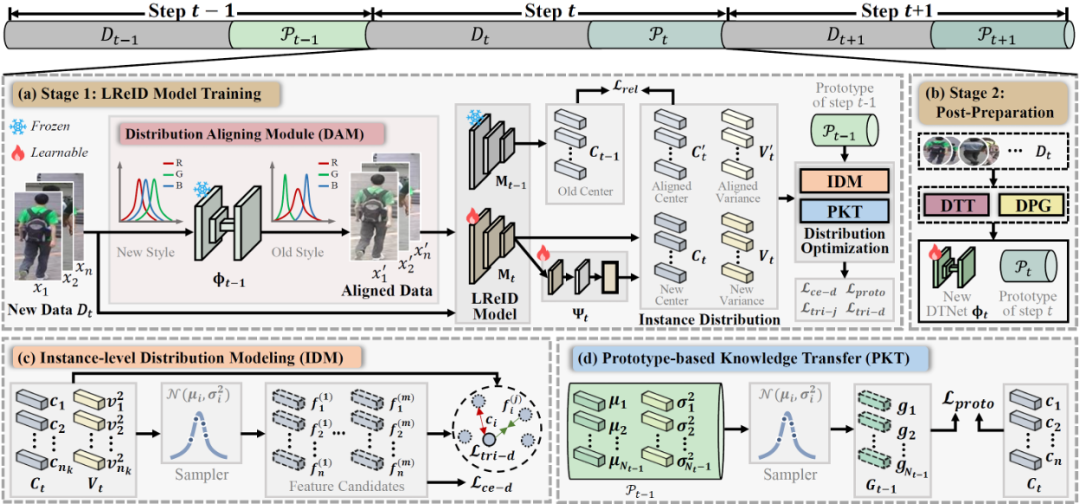
图 3 DKP++ 模型
(1)实例级细粒度建模:提出实例分布建模网络,动态捕捉行人实例的局部细节信息,为细粒度匹配奠定基础;
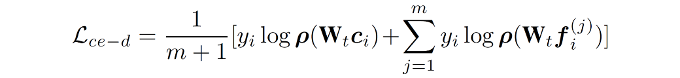
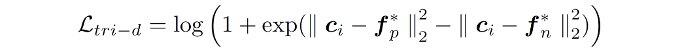
(2)分布感知的原型生成:设计分布原型生成算法,将学习到的实例级分布信息聚合为更鲁棒的类别级分布原型,克服了单一特征中心的局限性,保留类内差异知识。
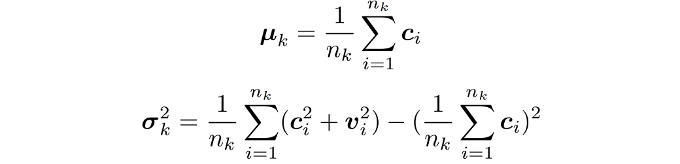
(3)分布对齐:引入输入端分布建模机制,弥合新旧数据特征分布鸿沟,提升模型对历史知识的利用能力。
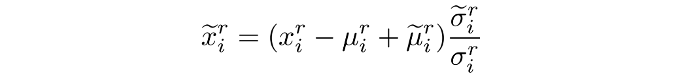
(4)基于原型的知识迁移:提出基于原型的知识迁移模块,利用生成的分布原型和有标注的新数据协同指导模型学习,在促进新知识吸收的同时,实现了对旧知识的记忆。
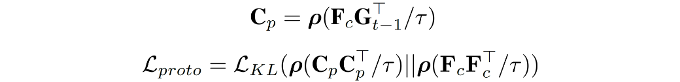
实验分析
1. 数据集与实验设置
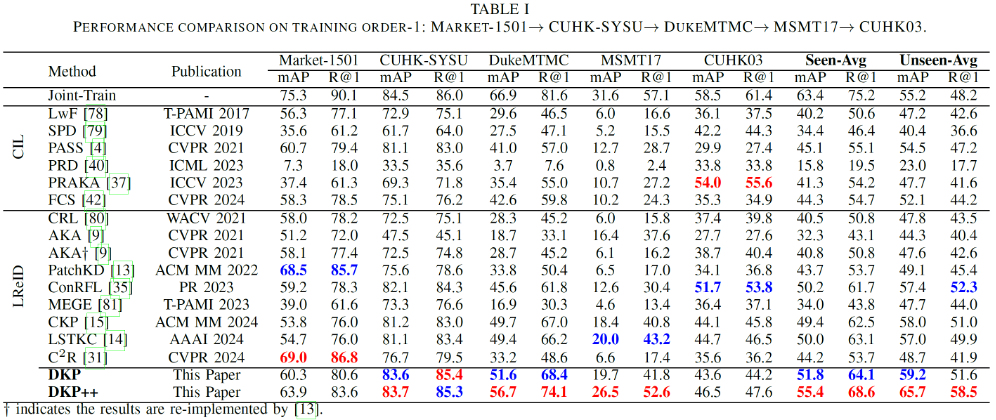
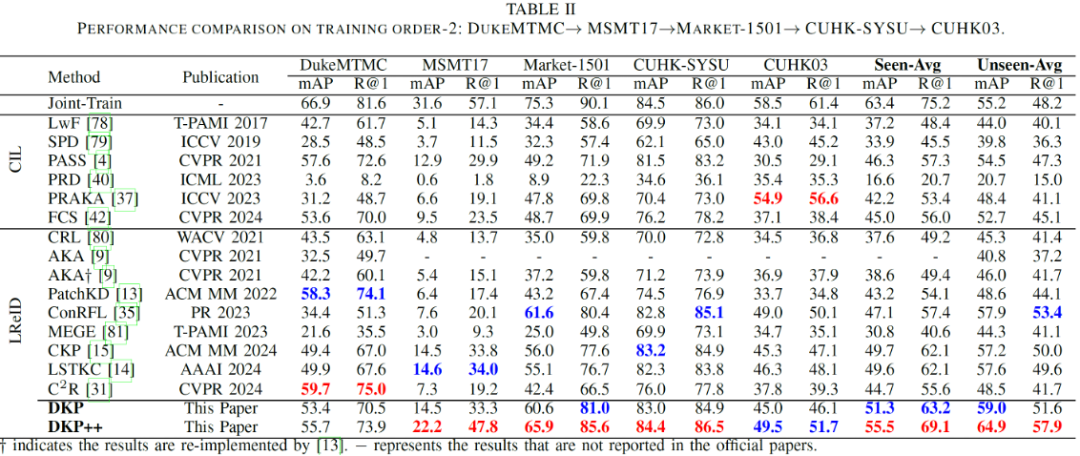
论文的实验采用两个典型的训练域顺序(Order-1 与 Order-2),包含五个广泛使用的行人重识别数据集(Market1501、DukeMTMC-ReID、CUHK03、MSMT17、CUHK-SYSU)作为训练域。分别评估模型在已学习域(Seen Domains)上的知识巩固能力和在未知域(Unseen Domains)上的泛化能力。评测指标采用行人 ReID 任务的标准指标:平均精度均值(mAP)和 Rank-1 准确率(R@1)。
2. 实验结果:
综合性能分析:在两种不同的域顺序设定下,DKP++ 的已知域平均性能(Seen-Avg mAP 和 Seen-Avg R@1)相比于现有方法提升 5.2%-7%。同时,DKP++ 在未知域的整体泛化性能(UnSeen-Avg mAP 和 UnSeen-Avg R@1)上相比于现有方法提升 4.5%-7.7%。
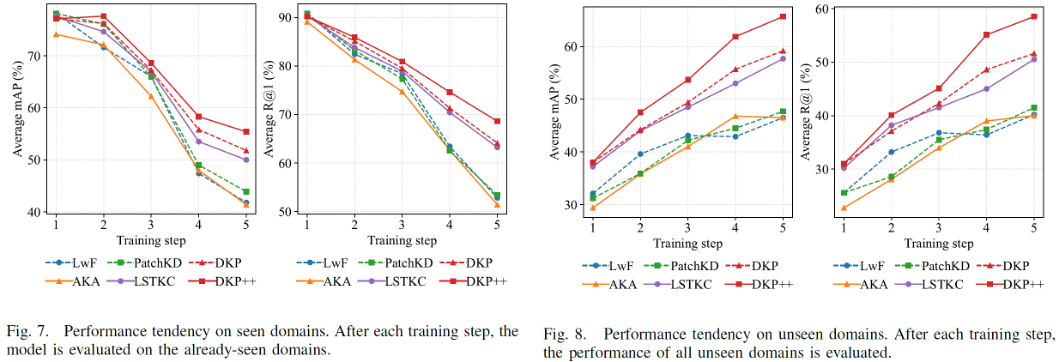
学习趋势分析:与现有方法相比,随着已学习域的数量增加,DKP++ 呈现了更高的历史知识巩固能力。同时,DKP++ 也呈现了更高的未知域泛化性能增长速度,验证了其所积累知识的鲁棒性。
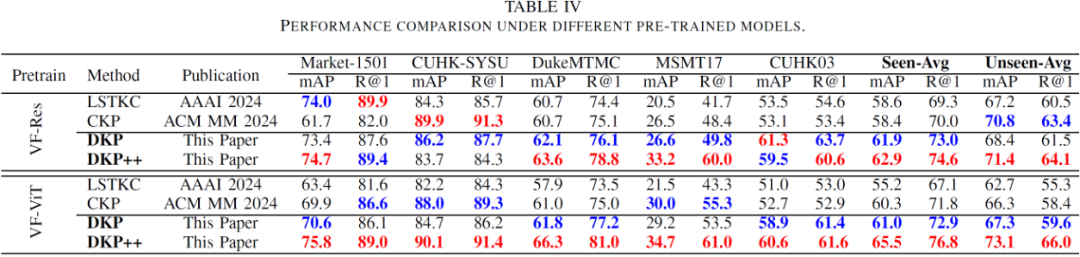
基础模型适配能力分析:在以不同的重识别基础模型(VF-Res,VF-ViT)作为预训练模型时,DKP++ 均保持了对现有方法的优势,说明其对不同的预训练模型均具备良好的适配能力。
总结与展望
1. 技术创新
本项被 IEEE TPAMI 2025 接收的工作聚焦于终身行人重识别(LReID)任务,提出了以下创新性设计:
分布原型建模与表征:提出基于实例级分布建模构建分布原型,增强了模型对历史信息的表达能力;
样本对齐引导的原型知识迁移:通过域分布建模与样本分布对齐克服新旧域数据的分布鸿沟,增强历史原型的利用能力。・
2. 未来展望
DKP++ 为无样本保留的终身学习技术提供了新范式,未来在多个方面仍有改进空间:
1. 基于大模型的分布对齐。本方法的分布对齐通过简单的卷积网络实现,未来可基于 Diffusion 等架构促进分布对齐以进一步提升模型的抗遗忘能力。
2. 知识主动遗忘机制。由于缺乏显式的引导,模型中往往包含冗余知识,在引入抗遗忘机制时容易干扰新知识的学习,因此构建模型的主动遗忘机制对进一步增强模型的知识巩固和学习能力具有重要研究价值。
3. 多模态终身学习机制。实际场景中存在红外、点云、音频、文本等多模态信息,增强模型的多模态数据持续学习能力,可促进模型充分利用多元化信息以增强复杂环境的感知能力。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com