scvi-hub平台利用预训练模型解决单细胞数据共享难题,实现高效复用。研究者可轻松访问与评估大规模单细胞图谱。#单细胞组学 #数据共享
原文标题:单细胞数据不再「海量难搬」,scvi-hub让实验室轻松调用模型与参考图谱
原文作者:数据派THU
冷月清谈:
scvi-hub的设计理念是“去除负担”,让模型和数据更轻巧、透明且易于分享。它基于强大的生成式概率建模工具包scvi-tools构建,并借助Hugging Face Hub托管,确保了模型的版本可追溯性和详尽的“模型卡片”式文档。平台支持贡献者选择上传原始数据或其精简后的压缩表示,这种压缩功能在显著降低内存需求的同时,仍能保留与原始数据大部分相同的功能,从而加速了表达值的生成。目前,scvi-hub上已“种子化”了90多个预训练模型,涵盖了多个大型项目和公共资源,并透明展示其训练细节、适用范围和性能指标,以保证后续使用的可追溯性与可复现性。
对于使用者而言,scvi-hub也提供了强大的评估机制。其专门开发的scvi.criticism模块允许用户在下载模型前,通过一系列通用指标(如基因和细胞水平的变异系数及差异表达相似性)来评估模型质量与相关性,就像查阅一份“体检报告”。这些指标独立于具体数据集,可实现跨研究场景的比较。该平台能广泛应用于多模态数据分析、迁移学习、查询数据分析、标签注入以及千万级细胞数据集的普查分析。例如,团队曾利用它识别出原研究中未识别的特定树突状细胞群体。总的来说,scvi-hub通过构建一个以模型为中心的高速通道,有效缓解了单细胞数据共享与复用的难题,让研究人员能够将更多精力集中在关键的科学问题上,促进良性社区循环。
怜星夜思:
2、scvi-hub这个平台能让科研人员更方便地用上这些模型和数据,确实能加速研究。但从商业角度看,你们觉得它有没有可能发展出一些独特的商业模式或者创造经济价值?毕竟现在搞这么大的平台,光靠捐赠或者科研基金长期运转下去也挺难的吧?
3、文章里提到scvi-hub甚至能识别出原研究中未发现的细胞群体,这太厉害了!大家觉得,未来随着像scvi-hub这样的平台越来越成熟,单细胞数据分析能达到什么程度?那些现在看起来有点科幻,但又有可能实现的应用,你们能想到哪些?
原文内容

来源:ScienceAI本文约1600字,建议阅读5分钟美国加州大学伯克利分校(University of California, Berkeley)等的团队提出了 scvi-hub —— 一个利用预训练概率模型高效共享和访问单细胞组学数据集的平台。

单细胞组学的「洪水时代」已经来临。成百上千万的细胞转录组测序结果不断涌现,研究者们期待把这些数据串联起来,绘制出全面的人体和动物细胞图谱。然而现实中,一个难题屡屡挡道:数据量太大、训练太慢、下载太耗资源,导致大规模参考集很难被真正广泛复用。
在这种背景之下,美国加州大学伯克利分校(University of California, Berkeley)等的团队提出了 scvi-hub —— 一个利用预训练概率模型高效共享和访问单细胞组学数据集的平台。研究者希望通过它,让任何实验室都能像调用工具包一样,轻松利用社区已经训练好的模型与参考图谱。
该成果以「Scvi-hub: an actionable repository for model-driven single-cell analysis」为题,于 2025 年 9 月 8 日发布在《Nature Methods》。

相关链接:https://www.nature.com/articles/s41592-025-02799-9
单细胞组学生态平台
单细胞技术过去十年间快速扩张,Tabula Sapiens、HLCA(Human Lung Cell Atlas)等大型项目产生了数量庞大的参考数据集。随着单细胞数据集的增长,迁移学习将成为一种关键技术,这类技术在单细胞组学中大致分为参数与非参数两类,尽管前者已经得到了广泛运用,但实现训练模型重用能力的挑战依然存在。
如何实现高效复用?如何解决数据库与框架之间的版本问题?诸如此类,都是急需解决的问题。
Scvi-hub 的设计初衷就是要「去除负担」,让模型和数据变得轻巧、透明而且易于分享。它基于 scvi-tools(一种生成式概率建模工具包)构建,并通过 Hugging Face Hub 托管,确保版本可追溯、卡片式(model card)文档清晰。
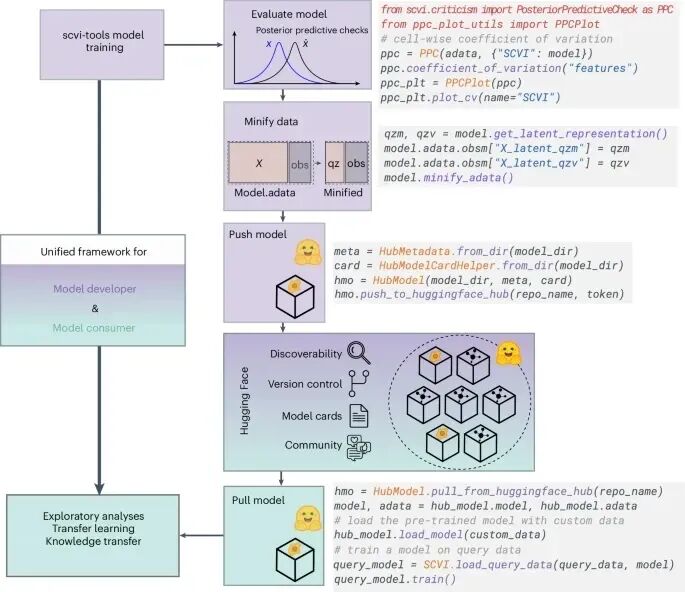
图 1:Scvi-hub 概述。
模型的贡献者可以自行选择分享模型背后的数据,以原始数据或者以精简后的形式进行上传。精简功能提供了参考数据集的压缩表示,同时仍然保留了与原始数据大部分相同的功能。
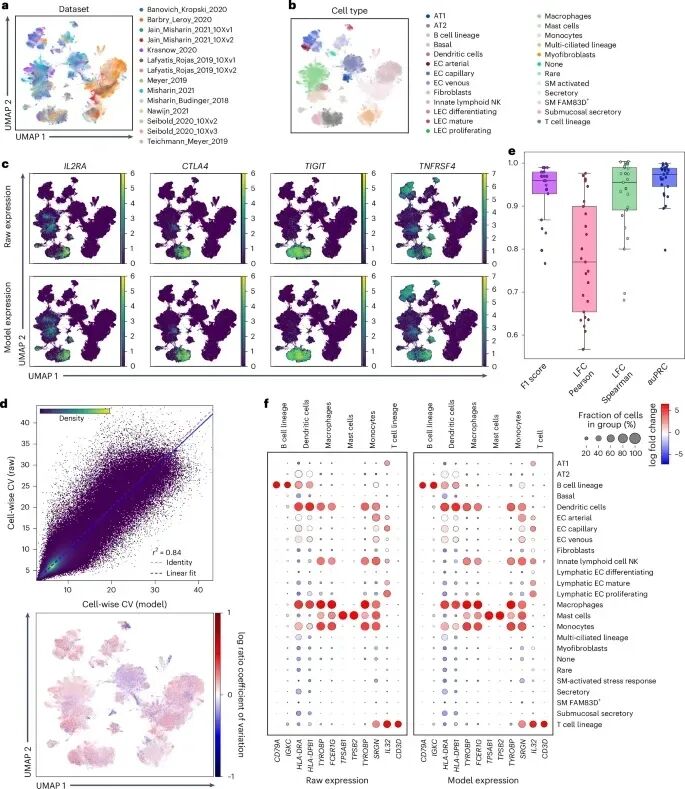
图 2:scvi-hub 实现的仅参考任务。
数据压缩显著降低了内存需求并加快了表达值的生成。借助这项功能,团队已经在平台上「种子化」了 90 多个预训练模型,覆盖了多个大型计划以及 CELLxGENE Census 等公共资源。每个模型的训练细节、适用范围与性能指标都被透明化展示,保证后续使用的可追溯性与可复现性。
轻装上阵
接下来,除开贡献者角度,该平台针对使用者也做出了相当程度的评估优化。
模型评估是 scvi-hub 的关键功能,使贡献者能够在上传前评估模型,用户可以判断其相关性和质量。为此,团队专门开发了 scvi.criticism 模块,用于评估使用 scvi-tools 训练的模型。
这个模块引入了一系列通用指标来评价模型质量,比如说计算基因水平和细胞水平的变异系数和差异表达,并评估它们的相似性。相似性越高,说明模型训练得越好。
这些指标不依赖具体数据集,因此可跨研究场景比较。研究者在下载模型前,可以先查看其「体检报告」,对模型的可靠性心里有数。
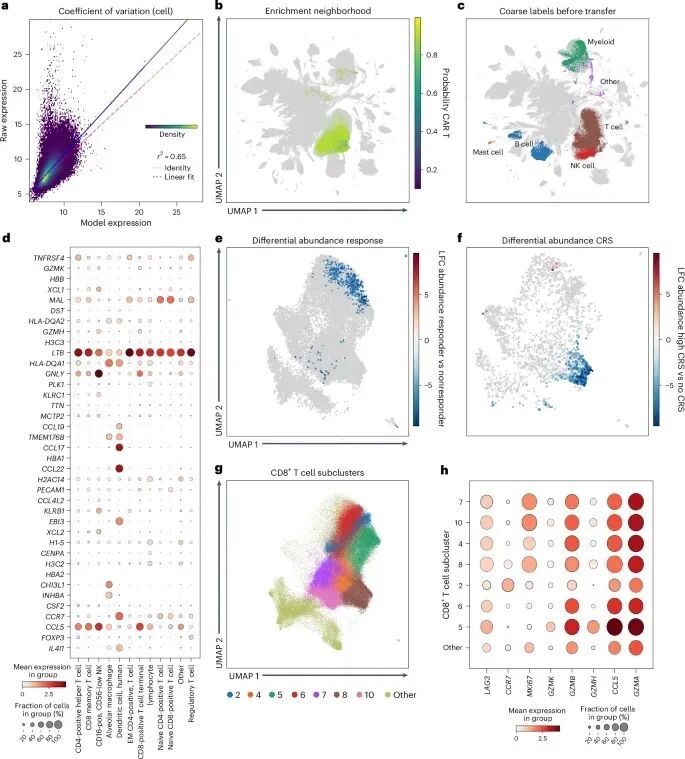
图 3:使用普查级预训练模型进行查询分析。
Scvi-hub 也可以扩展到多模态数据。从迁移学习的查询数据分析,再到标签注入后的查询参考,以及超过 3000 万细胞的数据集普查分析,scvi-hub 的使用范围非常广泛, 除开本职工作意外,团队甚至利用它识别出一种在原研究中未识别的对 CCR7、CCL17 和 CCL22 呈阳性的树突状细胞群体。
潜力与谨慎并行
研发团队共计设想了三种适用群体:共享数据并提供可重复分析的个人研究员、大规模图集工作的高级分析项目以及使用预训练模型执行注视或反卷积任务的研究者。结合外部参考文献,数据集分析逐渐丰富,细胞类型组成等相关见解也日益增多。
这是良性的社区循环,且它所采用的以模型为中心的方法能够以缩小的格式表示大型参考数据集,加速对资源的访问。在单细胞数据洪流里,研究者终于不必再为数据而焦头烂额,而是能够把精力集中在真正重要的科学问题上。可以说,scvi-hub 并不是又一个工具,而是一条让数据、模型与社区之间形成正循环的高速通道。
编辑:文婧
