国产AI算力芯片市场蓬勃发展,多元厂商通过技术创新、生态建设和差异化竞争,正加速追赶国际先进水平。
原文标题:主流国产AI算力芯片全景图
原文作者:牧羊人的方向
冷月清谈:
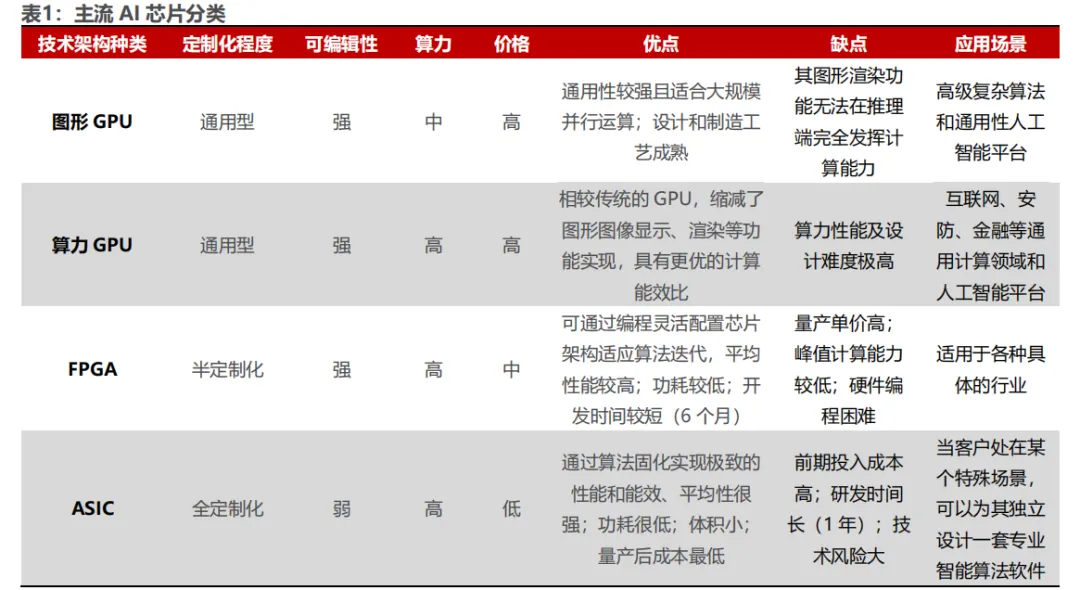
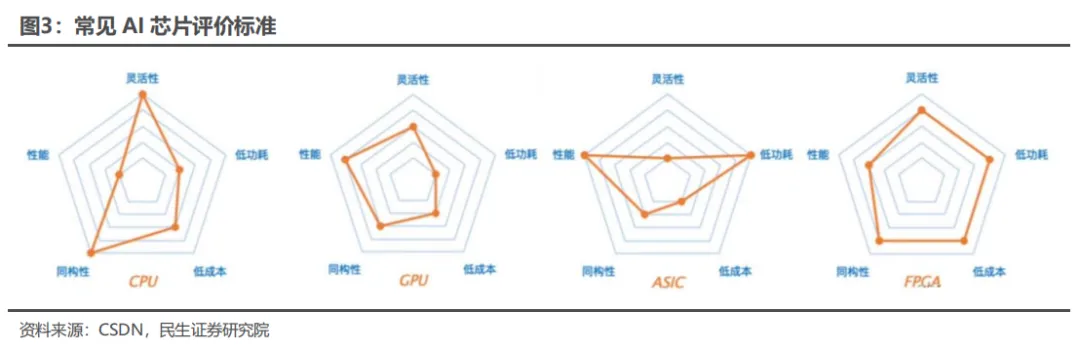
AI算力芯片主要包括GPU、FPGA和ASIC,其中GPGPU因其通用性在AI训练和推理领域应用最广。评估AI芯片的关键指标包括算力、功耗和面积(PPA)。算力衡量运算速度,功耗关注能效比,而面积则影响成本和良率。文章详细介绍了英伟达GPGPU的关键硬件参数及其架构演变。
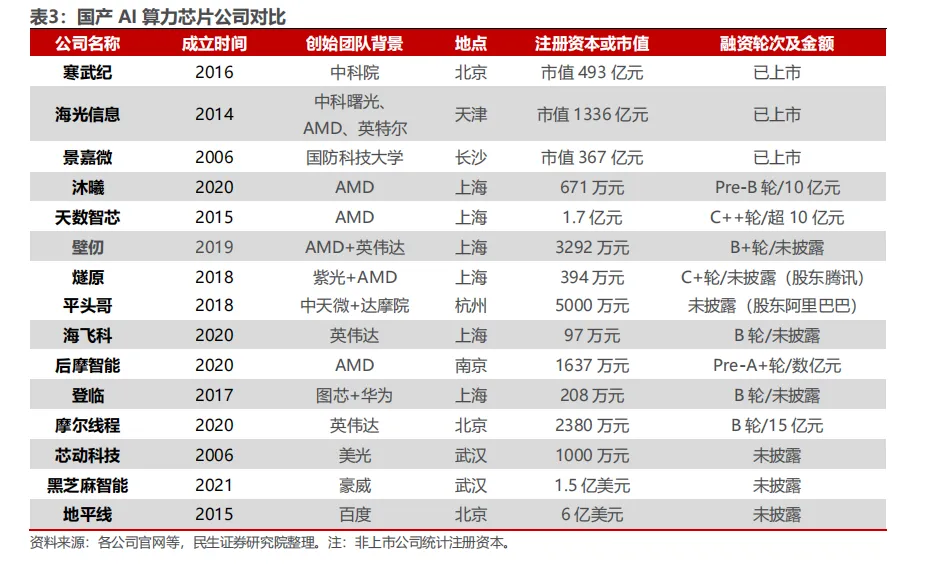
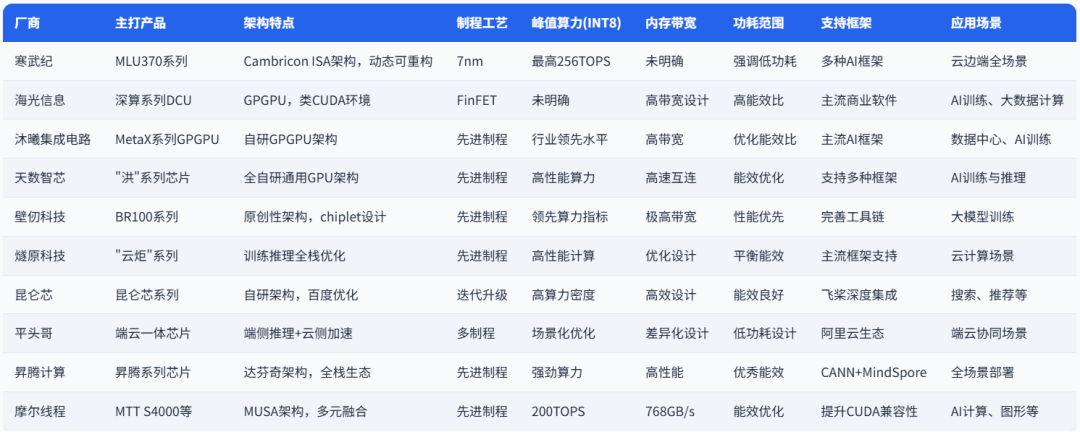
针对国内市场,文章深入剖析了多家代表性国产AI算力芯片企业,包括寒武纪、海光信息、沐曦集成电路、天数智芯、壁仞科技、燧原科技、昆仑芯、平头哥、昇腾计算产业链和摩尔线程。每家企业都有其独特的技术路线、产品定位、性能特点和生态建设策略。例如,寒武纪以自主指令集架构和云边端产品矩阵为特点;海光信息则以兼容“类CUDA”环境的GPGPU架构降低用户迁移成本;昇腾计算产业链则致力于构建从芯片到应用的完整全栈生态。
目前,国产AI芯片厂商在算力性能上正加速追赶,旗舰产品普遍在INT8精度下达到100-200TOPS水平,领先企业已采用7nm工艺,5nm产品正在研发中,并尝试通过Chiplet等先进封装技术提升性能。同时,各厂商积极寻求差异化竞争,重视软件栈与开发生态建设,许多厂商 致力于构建类CUDA的软件平台或兼容主流深度学习框架(如Pytorch, TensorFlow)。此外,与大模型的深度合作、构建集群级解决方案以及强调供应链自主和国产化,也成为国产AI芯片产业发展的重要趋势。
怜星夜思:
2、文章中提到国产芯片正在寻求性能追赶与差异化竞争。在你看来,国产AI芯片目前最应该优先在哪一领域或场景进行差异化布局,才能最大化地发挥优势并取得突破?是边缘计算、特定行业AI、还是超大规模模型训练等?
3、文章末尾提到“集群级解决方案与先进互联”是国产AI芯片的竞争焦点。构建一个稳定高效、支持万卡级甚至更高规模的国产AI算力集群,除了芯片本身的性能,你认为还需要在哪些方面投入更多研发和突破?
原文内容
2.1.1 主打产品与技术路线
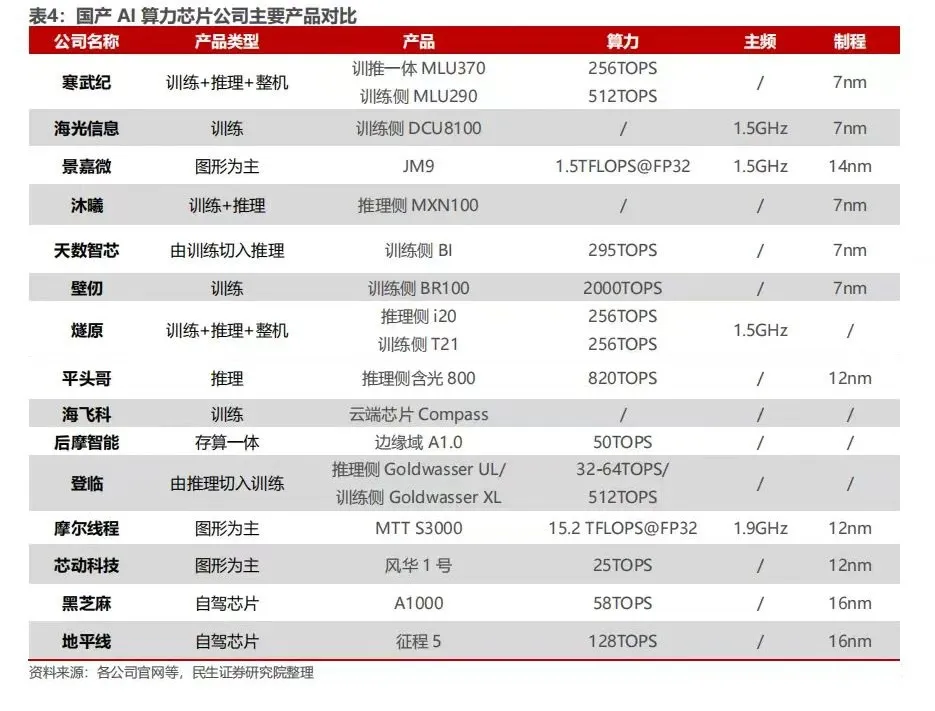
寒武纪作为中国最早专注于AI芯片的企业之一,形成了完整的云边端产品矩阵。其云端主打产品包括MLU370-X8、MLU370-S4和MLU370-X4训练加速器,以及MLU100智能云芯片;边缘端则覆盖Cambricon-1A、1H、1M系列终端智能处理器。
2.1.2 技术特点与性能分析
寒武纪的核心竞争力在于自主指令集架构(Cambricon ISA),该架构专门针对深度学习任务优化,支持动态可重构架构,可根据不同算法需求调整计算单元配置。在计算精度方面,其芯片支持稀疏计算加速和低精度量化(FP16/INT8/INT4),显著降低功耗的同时保持计算效率。
性能表现上,寒武纪产品持续迭代升级:早期Cambricon-1A(2016年)的非稀疏理论峰值性能为0.5TOPS(FP16);第三代Cambricon-1M在1GHz主频下,8位定点AI运算峰值速度达8TOPS,16位为4TOPS,32位为1TOPS 。最新产品算力显著提升,有信息显示其芯片算力可达256TOPS,并支持高达16TOPS的性能表现但具体对应型号未明确说明。
工艺方面,寒武纪已采用7nm制程技术,并正在研发第四代智能处理器IP Cambricon 1V和5nm先进工艺物理设计技术,体现了持续的技术演进能力。
2.1.3 生态建设与应用场景
寒武纪芯片可应用于视觉、语音、自然语言处理、推荐系统、搜索、传统机器学习等多种应用领域。其产品强调高性能、低功耗、高能效比、可扩展性、自适应精度训练和小体积部署在多个行业已有实际部署案例。
2.2.1 产品体系与市场定位
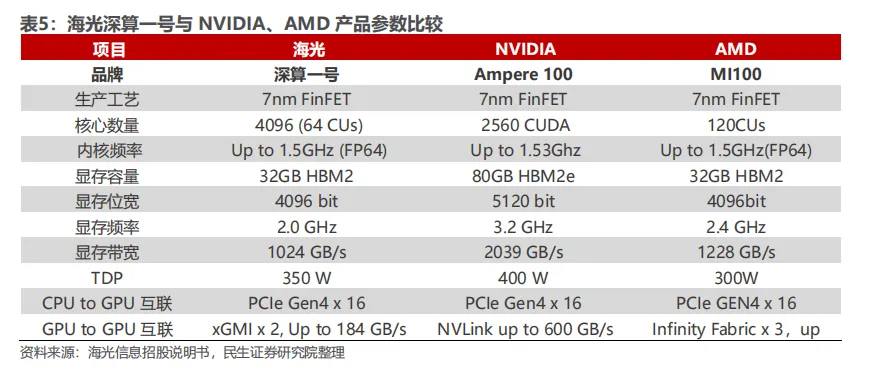
海光信息专注于高端处理器研发,产品线分为海光通用处理器(CPU)和海光协处理器(DCU)两条主线。在AI加速领域,其DCU系列(深算一号、深算二号、深算三号)是主打产品,其中"深算二号"于2023年第三季度发布,深算三号应是近期推出的新品。
2.2.2 技术架构与性能表现
海光DCU采用GPGPU架构,兼容"类CUDA"环境,能够适配国际主流商业计算软件和人工智能软件,拥有开源软件栈。这一设计极大降低了用户迁移成本,是其市场竞争的关键优势。
在计算性能方面,海光DCU支持多种精度(双精度、单精度、半精度和整型)计算,在AI训练和推理方面有专门优化。芯片内置高带宽内存芯片,提升大规模数据处理效率,具备强大的并行计算能力。虽然搜索结果未提供具体的TOPS或FLOPS数值,但多次强调其"计算性能出色"和"高能效比"的特点。
工艺方面,海光8100采用FinFET工艺,但具体制程节点(如7nm、5nm等)和详细的内存接口规格未明确披露。
2.2.3 应用生态与市场前景
海光DCU适用于AI推理、大数据处理、边缘计算、物联网等场景在商业计算领域已有广泛应用。其兼容CUDA生态的策略降低了用户学习成本,有利于市场推广和生态建设。
2.3.1 技术路线与产品定位
沐曦集成电路专注于提供高性能GPGPU芯片及解决方案,产品瞄准数据中心、AI训练和推理等高端市场。虽然搜索结果中未详细提及沐曦的具体产品参数,但根据行业公开信息,沐曦已推出系列GPGPU产品,采用自主研发的架构。
2.3.2 性能特点与技术创新
沐曦芯片支持全线精度计算(FP32、FP16、BF16、INT8等),具备高计算密度和能效比。其架构设计注重兼容主流AI软件生态,支持多种深度学习框架,降低用户迁移门槛。
2.3.3 生态建设与发展战略
沐曦注重构建完整的软件栈和开发生态,提供基础驱动、运行时库、编译器、开发工具等全套软件支持。公司与多家服务器厂商、云计算企业和高校科研机构建立合作,推动产品落地和生态成熟。

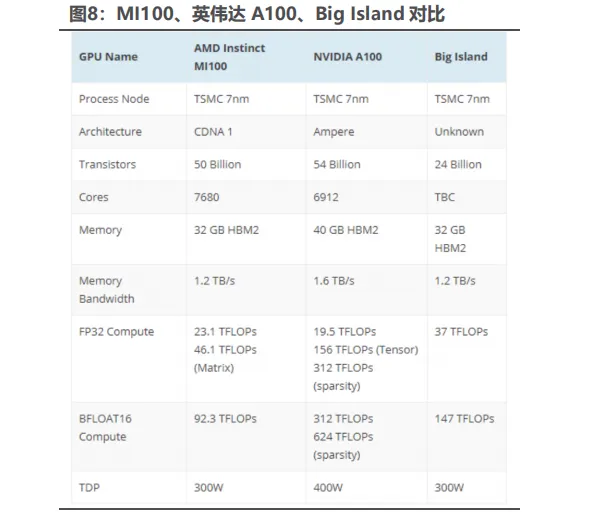
天数智芯主打通用GPU芯片,其产品包括训练和推理加速卡。公司推出全自研的"洪"系列芯片,支持FP32、FP16、BF16等多种计算精度,针对AI训练和推理场景进行优化。天数智芯的 Big Island 云端 GPGPU 是一款具有自主知识产权、自研 IP 架构的 7nm 通用云端训练芯片,这款芯片达到 295TOPSINT8 算力。

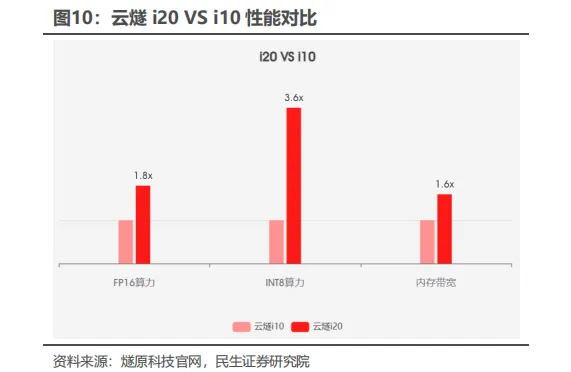


2.9 昇腾计算产业链
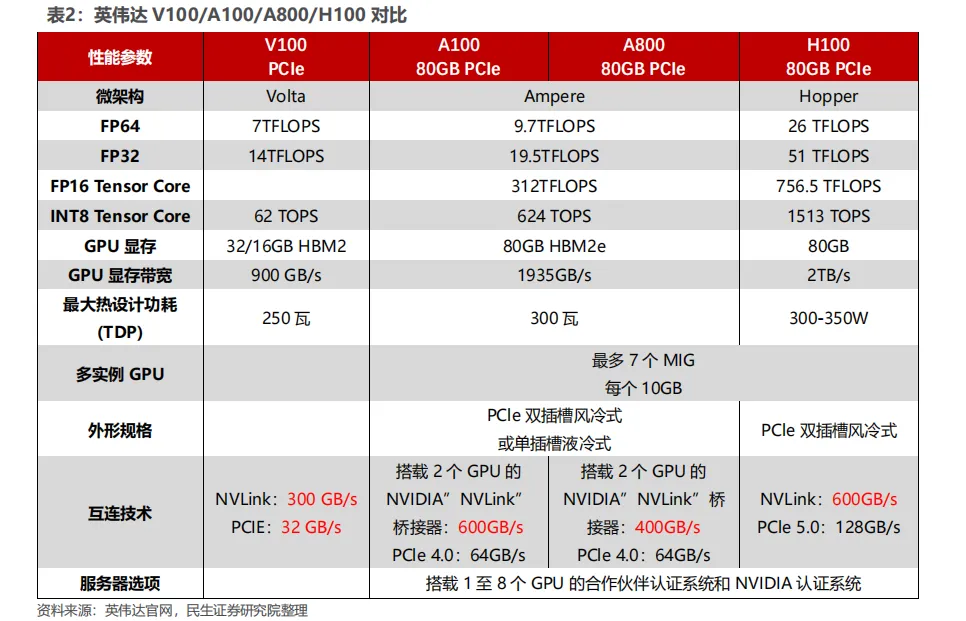
华为昇腾打造了芯片+硬件+软件+应用的全栈生态系统。昇腾系列芯片包括训练和推理产品,基于达芬奇架构,支持从边缘到数据中心的全面部署。华为主打 AI 芯片产品有昇腾310 和910B。310 偏推理,当前主打产品为 910B,拥有FP32 和 FP16 两种精度算力,可以满足大模型训练需求。910B 单卡和单台服务器性能对标 A800/A100。
昇腾计算产业是基于昇腾 AI 芯片和基础软件构建的全栈 AI 计算基础设施、行业应用及服务,能为客户提供 AI 全家桶服务。主要包括昇腾 AI 芯片、系列硬件、CANN、AI 计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链。
2.10 摩尔线程(Moore Threads)
2.10.1 技术架构与产品矩阵
摩尔线程采用多元融合的技术路线,基于自研MUSA架构,产品覆盖AI计算加速、图形渲染、物理模拟和视频处理等多种工作负载。公司形成了从云端到终端的"云-边-端"产品布局。主要产品包括:服务器级的MCCX D800 X2(大型模型训练)、MTT S4000(智能计算加速卡)、MTT S3000(云渲染卡)、MTT S80(桌面级图形卡)以及边缘AI计算模块。公司还推出KUAE智能计算集群解决方案,目标是构建支持大规模GPU集群和达到拍瓦级浮点计算能力的平台。
2.10.2 性能指标与技术特点
MTT S4000采用第三代MUSA架构,配备48GB GDDR6内存,提供768GB/s带宽,支持PCIe 5.0 x16总线。其算力表现为:FP32算力25 TFLOPs,TF32算力50 TFLOPs,FP16/BF16算力100 TFLOPs,INT8算力200 TOPS 。作为参考,其FP32性能约为RTX 4090的30% 。
MTT S2000则拥有4096个MUSA核心,32GB显存,12TFlops单精度计算能力。整个产品线强调异构多核架构和自适应调度器设计,旨在降低功耗和提高能效。
2.10.3 生态建设与兼容策略
摩尔线程定位为全栈AI基础设施提供商其MUSA架构注重计算通用性、技术演进能力和生态兼容性。产品兼容X86、ARM和主流Linux操作系统,并通过提升CUDA兼容性来改善软件可移植性,助力中国GPU行业的自主可控进程。
2.11 厂商对比
国产AI芯片主要分为三条技术路线:专用ASIC路线(寒武纪、天数智芯、昆仑芯)、GPGPU路线(海光、壁仞、沐曦)和全栈解决方案路线(昇腾、平头哥、摩尔线程、燧原科技)。ASIC路线在能效和特定场景优化上有优势;GPGPU路线在通用性和生态兼容性上更胜一筹;全栈解决方案则强在端到端优化和系统级性能。从算力性能看,各厂商旗舰产品在INT8精度下普遍达到100-200TOPS算力水平,部分产品可达更高算力。内存带宽多在500-800GB/s范围,支持PCIe 5.0成为新代产品的标准配置。在工艺制程方面,领先企业已采用7nm工艺,5nm产品正在研发中。
-
性能追赶与差异化竞争:国产芯片在绝对算力上与国际顶尖水平尚有差距,但正通过支持FP8、FP64多精度、优化HBM高带宽内存、采用** Chiplet** 先进封装等方式提升性能。在能效(如平头哥PPU)、特定场景优化(如昇腾超节点)等方面寻求差异化优势。
-
软件栈与开发生态:许多厂商致力构建类CUDA的软件平台(如海光DTK、沐曦MXMACA),或通过兼容主流框架(如Pytorch, TensorFlow)降低开发者迁移成本。
-
适配与大模型合作:积极适配国内外主流大模型(如DeepSeek、LLaMA、ChatGLM等)成为普遍策略,甚至出现芯片公司与模型公司“深度软硬协同优化”(如阶跃星辰与沐曦)。
-
集群级解决方案与先进互联:不止于单卡性能,万卡级集群的建设和互联技术成为竞争焦点。华为昇腾超节点、壁仞科技参与的光互连光交换GPU超节点等都体现了这一点。
-
应用导向与行业渗透:芯片设计更贴近实际应用场景,面向互联网、金融、政务、能源、科研等不同领域提供解决方案。
-
供应链自主与国产化:强调自主研发核心IP、构建国产供应链已成为众多厂商的重要目标和发展战略。
参考资料:
1、智能计算芯世界