《自然》发布新型AI工具Delphi-2M,可根据个体健康数据,提前预测长达20年内超过1000种疾病的风险,为精准医疗和早期预防提供强大助力。
原文标题:Nature | 20年后你会患上哪些疾病?AI准确预测超1000种疾病患病风险,助力预防
原文作者:数据派THU
冷月清谈:
当前,针对特定疾病的预测算法已相对成熟,但同时对多重疾病进行建模仍是一大挑战。这不仅涉及庞大的诊断类别(国际疾病分类第十版包含逾1000种顶层诊断),还需处理既往事件的时间依赖性,并整合多元预后相关数据。
为应对这些挑战,研究团队对生成式预训练 Transformer (GPT) 架构进行了改进,构建了Delphi-2M模型。该模型基于约40万英国生物银行参与者的健康数据进行训练,并通过超大规模外部数据进行验证,展现出强大的模拟人类疾病进展的能力。
Delphi-2M能够根据个体的既往病史,准确预测包括癌症、皮肤病及免疫系统疾病在内的1000多种疾病的发病率,其准确度与现有的单病种模型相当。此工具可为个体提供长达20年的潜在疾病风险评估,综合考量健康记录和生活方式因素。值得注意的是,其基于Transformer的架构使其能够轻松整合更多数据层,如生活方式信息、自报健康状况、处方记录和检测指标等,展现出卓越的适应性。研究团队也从可解释AI的角度分析了模型预测的内在逻辑。
在外部验证中,Delphi-2M在未进行任何重训练或参数调整的情况下,平均AUC评分为0.67,略低于其在内部测试中的表现(0.69),但仍能有效反映多重病症的真实演变规律,证明了其泛化能力。然而,研究团队也承认,不同健康数据源的多样性可能会影响模型的预测准确性。
总的来说,Delphi-2M有望显著增强人们对个性化健康风险的认知,为精准医疗策略提供重要依据。但研究人员强调,此类AI模型应被视为现有诊断流程的补充工具,而非替代品。它开启了“上医治未病”的可能性,通过早期预警和干预,助力疾病预防和管理。
怜星夜思:
2、这种AI模型为了训练和预测,肯定要用到很多个人健康数据。你们会担心自己的隐私泄露吗?或者数据会不会被商业机构滥用?有什么好的解决方案吗?
3、AI预测疾病听起来很酷,但文章也说了它只是“补充工具”。从实验室到真正走进医院或普通家庭,Delphi-2M可能面临哪些实际的挑战?比如医生和患者的接受度、成本、数据互通等等。
原文内容

来源:ScienceAI本文约1200字,建议阅读5分钟现在,人工智能(AI)可以为人类预测疾病风险了!

古籍云:「上医治未病」,意思是医术最高明的医生擅长预防疾病。在综合评估个人健康风险状态的基础上,一些疾病可以通过一定的防治干预手段来阻断发展。
现在,人工智能(AI)可以为人类预测疾病风险了!
来自德国癌症研究中心(DKFZ)、欧洲分子生物学实验室(EMBL)、哥本哈根大学等机构的研究团队开发了一款新型 AI 工具 ——Delphi-2M,可以预测一个人罹患 1000 多种疾病的风险,在某些情况下甚至可以提前几十年预测。
研究论文以《Learning the natural history of human disease with generative transformers》为题发表在《Nature》上。

论文地址:https://www.nature.com/articles/s41586-025-09529-3
Delphi-2M
关于疾病预测,现有算法大多针对特定疾病,而对多重疾病建模仍是一个难题。根据国际疾病分类第十版(ICD-10)编码系统,人类疾病谱包含超过 1000 种顶层诊断分类。
除诊断数量庞大外,多重疾病建模挑战还包括:对既往事件间时间依赖性的建模、整合预后相关多元数据等。
研究团队通过改进 GPT(生成式预训练 transformer)架构,构建了能够模拟人类疾病进展的模型 ——Delphi-2M。该模型基于 40 万英国生物银行参与者的数据训练,并使用超大规模外部数据(参数未调整)进行验证。
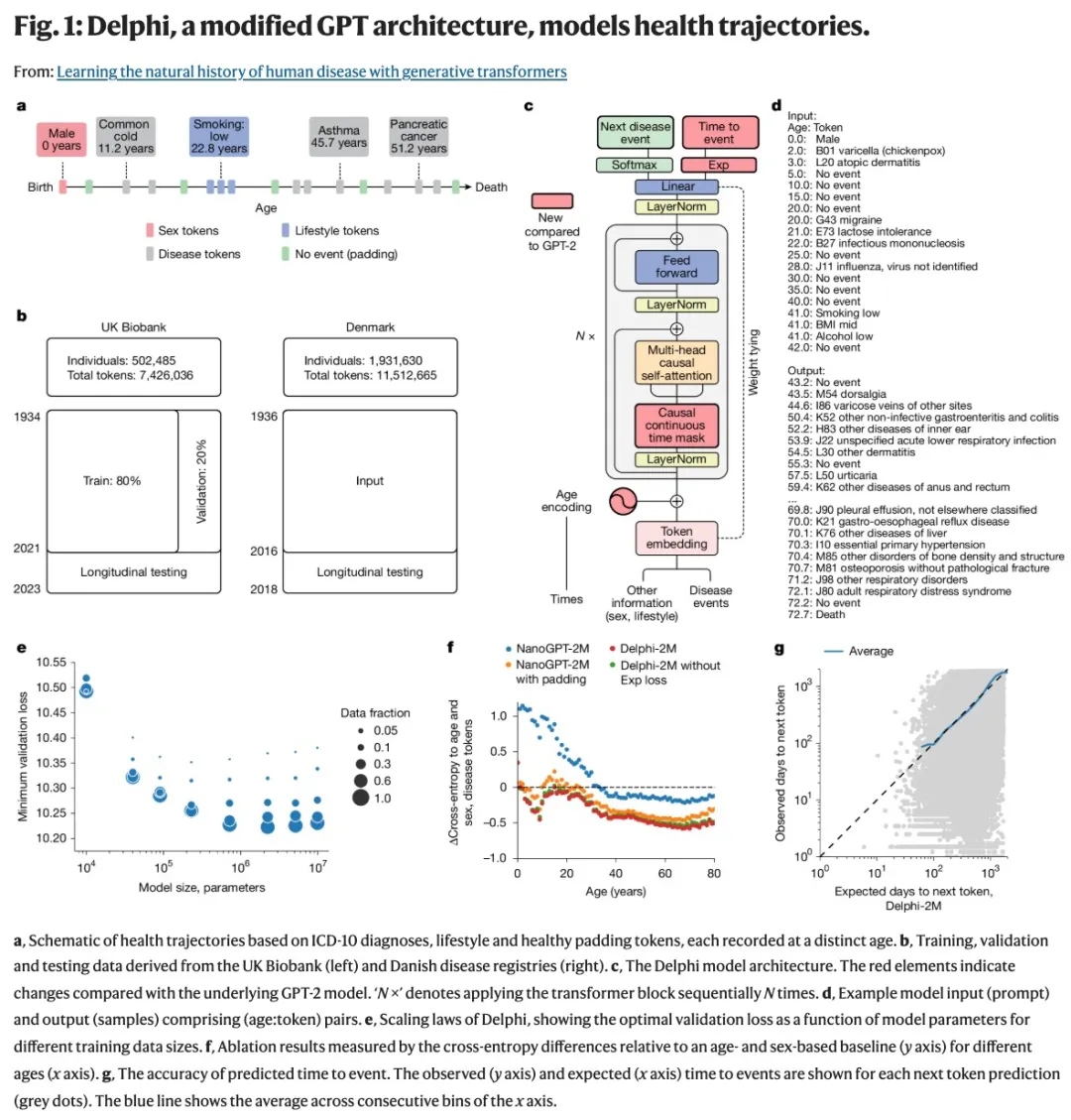
根据个体既往病史,Delphi-2M 能够预测 1000 多种疾病的发病率,并且准确度与现有单病种模型相当。
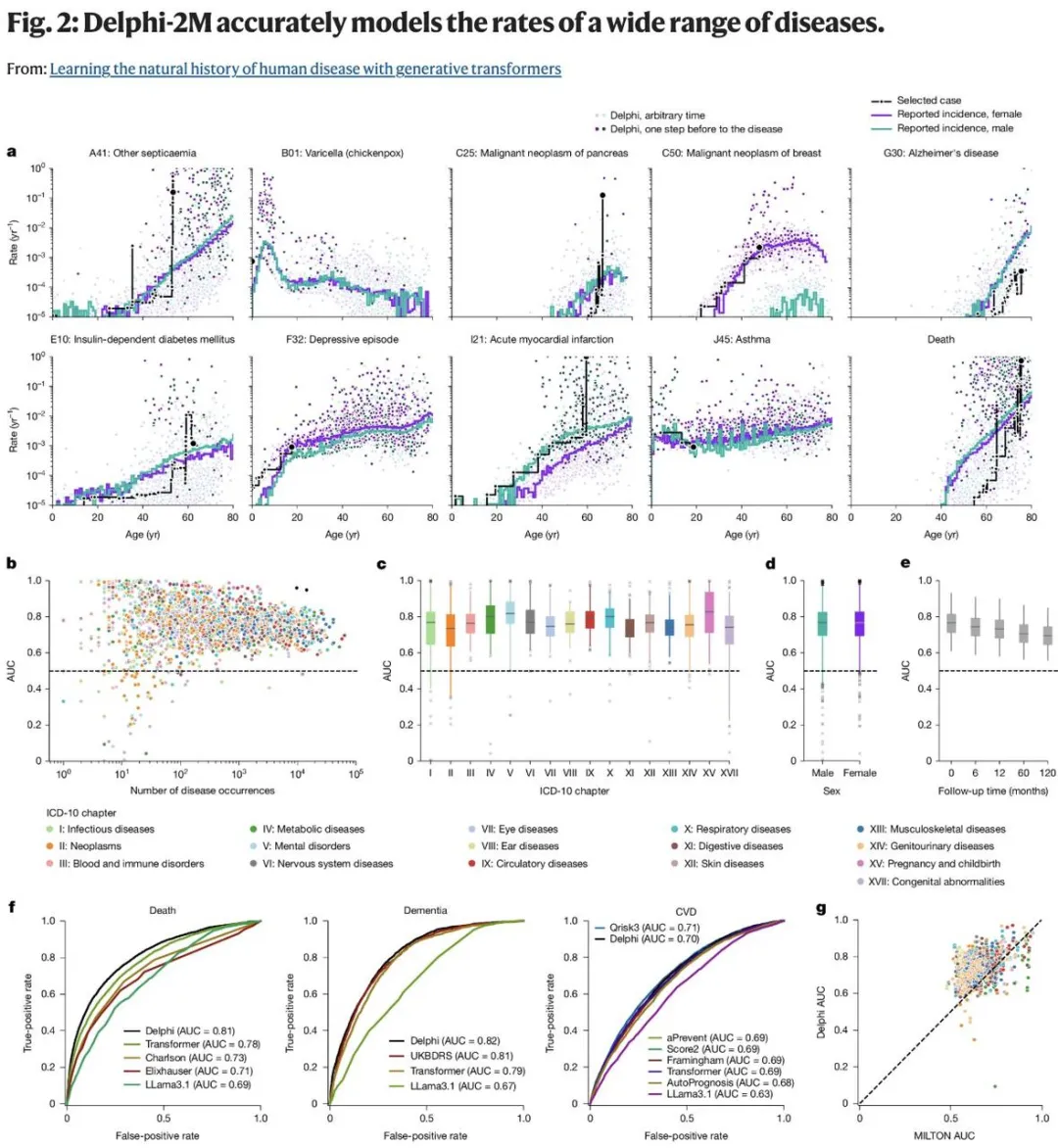
Delphi-2M 还可为个体提供长达 20 年的潜在疾病风险估计,利用健康记录和生活方式因素来估算其未来 20 年内罹患癌症、皮肤病和免疫系统疾病等疾病的可能性。
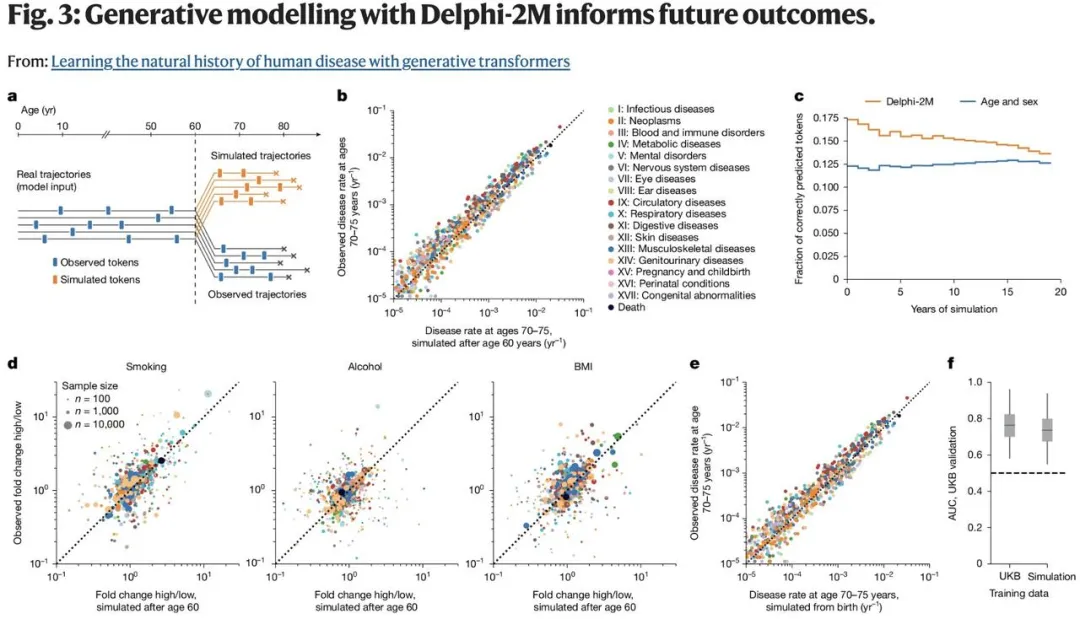
研究团队还从可解释 AI 的角度对 Delphi-2M 预测的内在逻辑进行了分析:
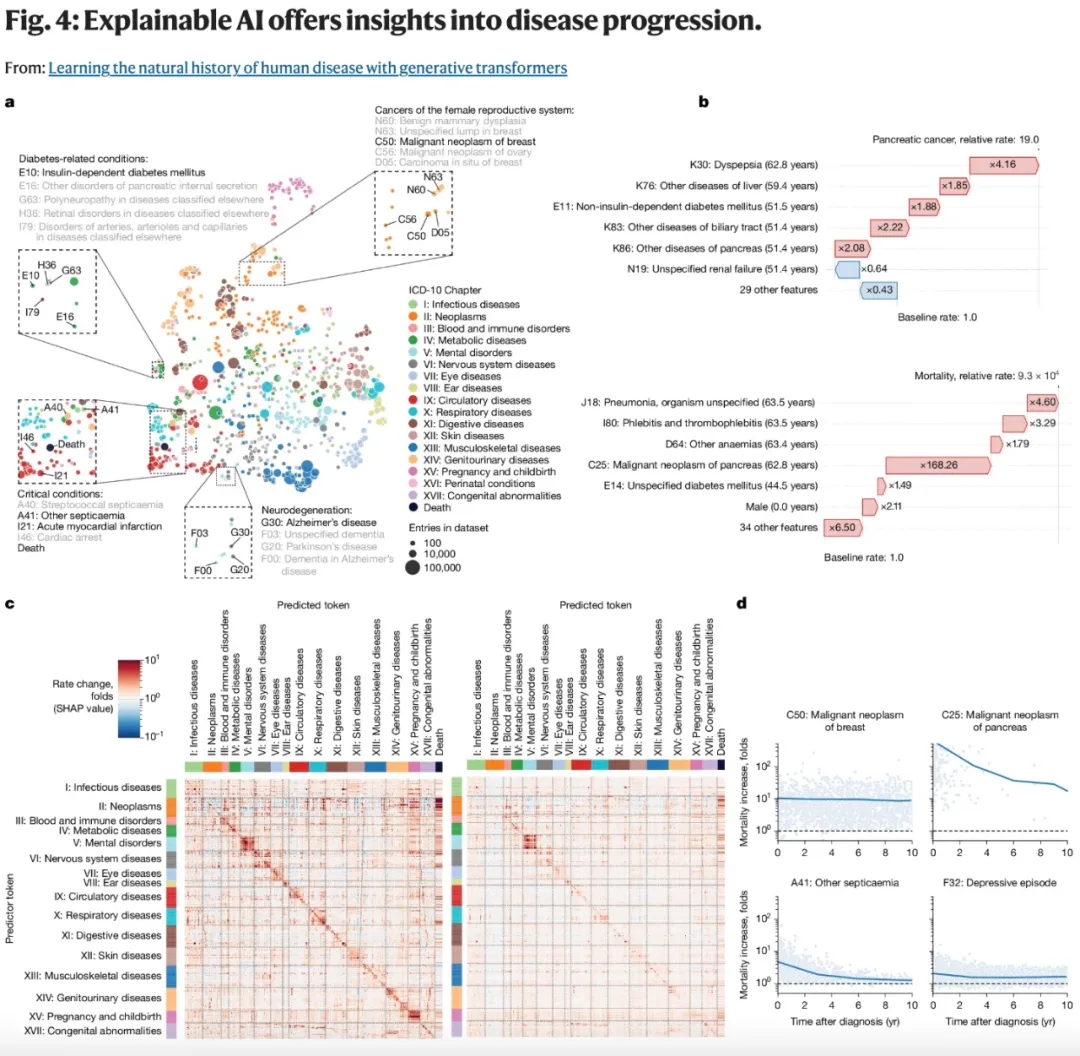
值得一提的是,基于 Transformer 的架构让 Delphi-2M 能够相对简便地整合附加数据层,即时纳入更多生活方式数据、自报健康状况、处方记录、检测指标等等。
总体而言,Delphi-2M 展现出卓越的适应性,既能胜任预测性和生成性健康任务,又可应用于人群级数据集,揭示疾病事件间的时间依赖性。
外部验证
为了评估 Delphi-2M 模型在未知人群中的泛化能力,研究团队直接迁移了基于英国生物银行数据训练得到的 Delphi-2M 模型权重,在超大规模外部数据上进行了验证评估,未进行任何重训练或参数调整。
结果显示:模型平均 AUC 值为 0.67(标准差 0.09),略低于在英国生物银行数据纵向测试中的表现(0.69,标准差 0.09)。虽然准确度略有下降,但 Delphi-2M 能准确反映多重病症的真实演变规律。
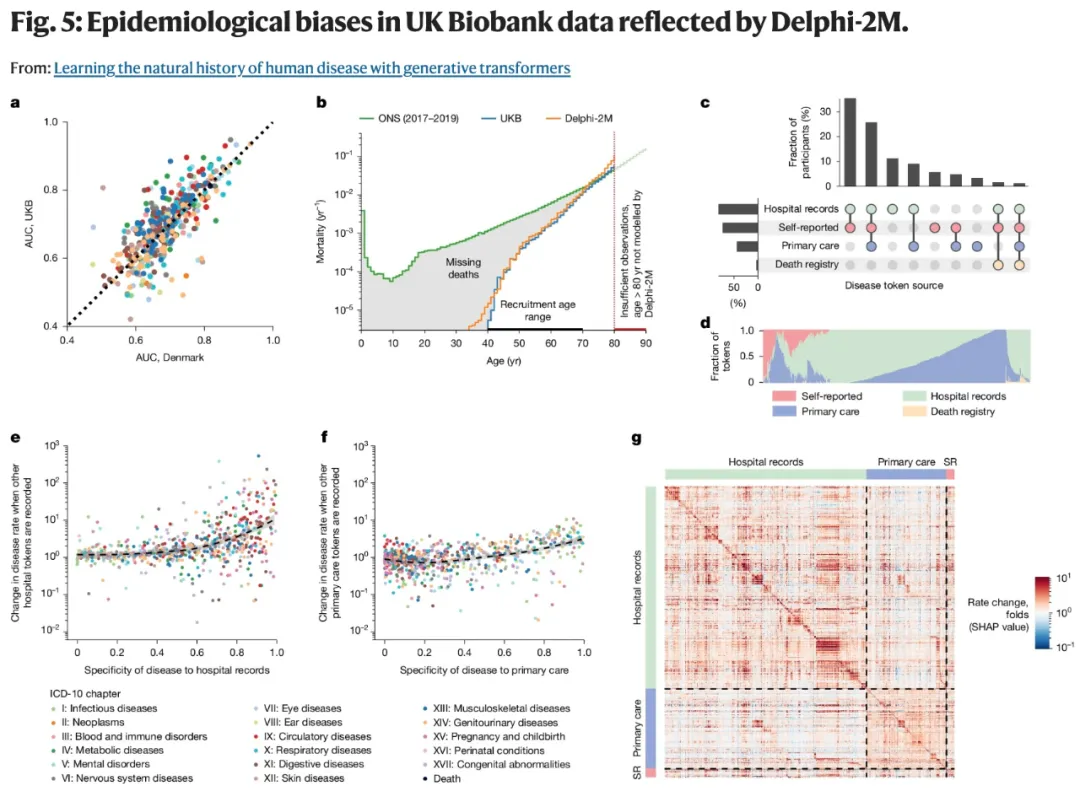
但研究团队坦言:Delphi-2M 还存在一些局限性,例如,健康数据源的多样性影响了模型预测。
总的来说,Delphi-2M 有望增强个性化健康风险认知,为精准医疗方法提供依据。不过,使用 AI 模型进行推断预测时需保持审慎,此类模型更适合作为现有诊断流程的补充工具而非替代方案。
感兴趣的读者可以阅读论文原文,了解更多研究内容。
参考内容:https://www.nature.com/articles/d41586-025-02993-x
编辑:文婧
