此文详述了如何在有限算力下构建Mini-DeepSeek-V3,重点解析其Transformer Block、多Token预测 (MTP) 机制及其在整体框架中的实现与损失计算。
原文标题:原创 | 一文读懂DeepSeek-V3(下)
原文作者:数据派THU
冷月清谈:
核心内容首先围绕Transformer Block的实现展开,指出其封装相对简单。随后,文章深入探讨了MTP(多Token预测)机制的实现细节。作者纠正了DeepSeek-V3原文中可能存在的图示和公式上的迷惑性,通过详细的输入输出序列分析和损失计算方式,清晰阐释了MTP在不同预测深度下的工作原理。特别是对k=0、k=1、k=2时主模型与MTP模块的输入序列、目标序列和损失计算进行了图示化解释,强调了MTP模块辅助输入的角色。为简化代码逻辑,文中实例将MTP的预测深度固定为1。
在MTP的具体实现中,文章提醒了几点注意事项,如MTP的Transformer Block在输出头前加入了norm层,前馈网络使用了普通MLP(而非MoE),以及MTP仅在训练时使用需添加mask逻辑等。
最后,文章展示了Mini-DeepSeek-V3的整体模型框架,详细说明了主模型部分、MTP部分和总损失部分的构成。总损失由主模型损失、所有层的序列级辅助损失和MTP损失共同构成,并指明了这些输出数据用于后续的训练监控和可视化。文章还提供了GitHub项目链接,供读者查阅完整的训练代码。
怜星夜思:
2、文章提到为了简化代码逻辑,Mini-DeepSeek-V3把MTP的预测深度固定为1。如果未来想扩展到更大的预测深度,比如真像DeepSeek-V3那样实现可变或更深的深度,你觉得会遇到哪些工程上的挑战?除了代码复杂度的增加,还有没有其他的坑?
3、Mini-DeepSeek-V3虽然是“迷你”版,但它还原了DeepSeek-V3的核心架构。大家觉得这种将大模型复杂机制“微缩”复现的意义何在?对于我们学习和理解大模型有什么特别的帮助?(不限于技术层面)
原文内容

作者:王坤擎本文约2500字,建议阅读5分钟本文主要介绍如何利用较小的算力资源,实现一个Mini-DeepSeek-V3模型架构,需要对DeepSeek-V3相关理论具有一定了解。
完整的DeepSeek-V3涉及到庞大的工程优化和算力资源,本文旨在基于较小的算力,从MLA、DeepSeekMoE、MTP、无辅助损失的负载均衡策略、序列级辅助损失等核心架构来实现一个Mini-DeepSeek-V3的训练和推理Demo。由于模型规模较小,采用单卡或DDP的方式训练,且不考虑使用YaRN来扩展上下文长度,仅使用原始RoPE。
在介绍了Mini-DeepSeek-V3的MLA、MoE实现,在本篇中将重点介绍Transformer Block 实现,MTP 以及Mini-DeepSeek-V3的整体框架。
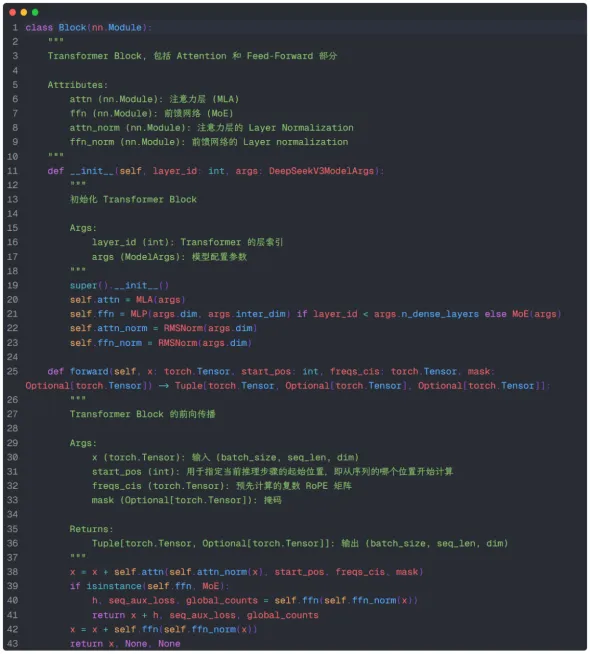
Transformer Block实现
Transformer Block的实现相对简单,只需将前面的各模块封装起来,代码如下,这里不再赘述:
![]()
MTP实现
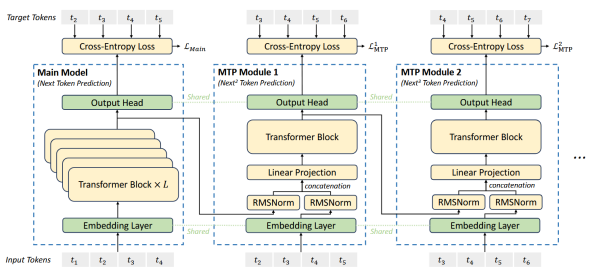
由于DeepSeek-V3未开源训练代码,因此MTP的代码实现仅基于个人理解,未必准确。在DeepSeek-V3原文中,介绍了MTP的基本原理,然而,个人认为原文中的配图和公式具有一定的迷惑性,在此我们进一步深入剖析。论文原图如下:
![]()
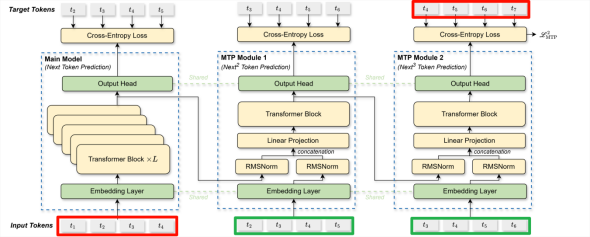
首先结合原文图片看MTP的公式表达。对于输入的第i个token![]() ,在预测深度为k时,首先通过投影矩阵融合第k-1个预测深度的输出表征
,在预测深度为k时,首先通过投影矩阵融合第k-1个预测深度的输出表征![]() 和第i+k个token的Embedding
和第i+k个token的Embedding ![]() :
:
![]()
其中,![]()
![]() 表示拼接操作。特别的,当k=1时,
表示拼接操作。特别的,当k=1时,![]()
![]() 就是主模型的表征。另外,注意每个MTP模块的Embedding层和输出头,都是与主模型共享的。融合后的
就是主模型的表征。另外,注意每个MTP模块的Embedding层和输出头,都是与主模型共享的。融合后的![]()
![]() 作为输入,输入到第k个深度的Transformer模块中,产生输出表征
作为输入,输入到第k个深度的Transformer模块中,产生输出表征![]()
![]() :
:
![]()
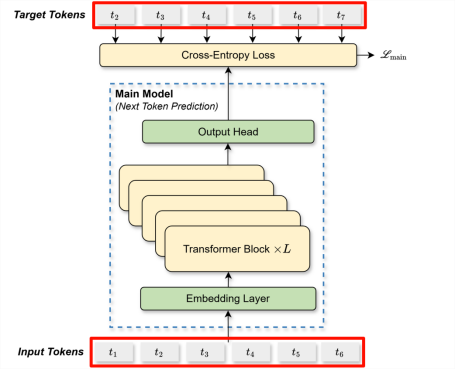
k=0时的输入输出:(图一)
![]()
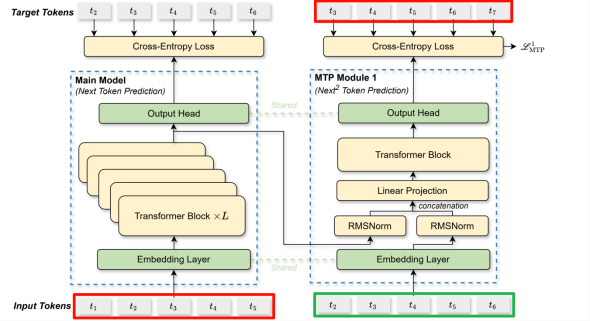
k=1时的输入输出:(图二)
![]()
k=2时的输入输出:(图三)
![]()
因此,不论k是几,![]()
![]() 的输入的下标均是1:T-k,这实际上是主模型的输入序列,即左下角的红框,而
的输入的下标均是1:T-k,这实际上是主模型的输入序列,即左下角的红框,而![]()
![]() 的输出则是右上角的红框,这也符合预测下k+1个token的逻辑。实际上我们可以将绿框中的部分理解为是一个辅助输入,对于这些辅助输入,
的输出则是右上角的红框,这也符合预测下k+1个token的逻辑。实际上我们可以将绿框中的部分理解为是一个辅助输入,对于这些辅助输入,![]()
![]() 做的是next token预测,但对于主模型输入,做的则是多token预测。
做的是next token预测,但对于主模型输入,做的则是多token预测。
再来看MTP的损失计算方式,对每个预测深度,计算交叉熵损失:
![]()
其中:
-
T:输入序列长度,在本文的例子中为6;
-
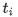 :第 i 个位置的ground truth token;
:第 i 个位置的ground truth token; -
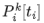
 :由第 k 个MTP模块给出的对应的预测概率。
:由第 k 个MTP模块给出的对应的预测概率。
从公式角度来看,第k个MTP模块计算的应当是![]()
![]() 的交叉熵损失,例如在原图中,k=2时,计算的是
的交叉熵损失,例如在原图中,k=2时,计算的是![]()
![]() 的损失,这没问题。问题在于,原文的图直接将
的损失,这没问题。问题在于,原文的图直接将![]()
![]() 标记在了MTP模块1旁边,这是具有迷惑性的,如果根据图中的标识,可能很容易理解为
标记在了MTP模块1旁边,这是具有迷惑性的,如果根据图中的标识,可能很容易理解为![]()
![]() 是在为
是在为![]()
![]() 做损失,如果真是这样的话,对于token
做损失,如果真是这样的话,对于token ![]() 就丢失了预测下2个token的过程。实际上,根据公式,k=1时,应当计算的是
就丢失了预测下2个token的过程。实际上,根据公式,k=1时,应当计算的是![]() 的损失,即也需要做到T+1的token,如图二所示。
的损失,即也需要做到T+1的token,如图二所示。
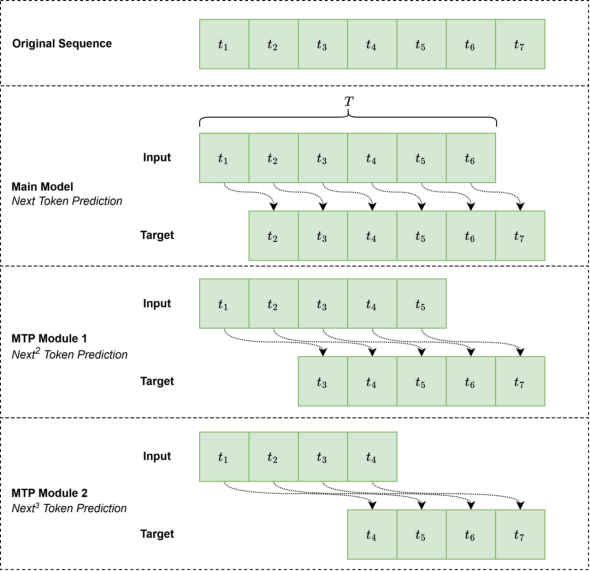
从图一至图三来看,![]()
![]() 全部作为输入,均在主模型做了next token预测,计算
全部作为输入,均在主模型做了next token预测,计算![]()
![]() 的损失。然后截取主模型
的损失。然后截取主模型![]()
![]() 的输出表征,结合
的输出表征,结合![]()
![]() 辅助(辅助使用的是输入序列的ground truth),在MTP 1中做了下2个token预测,计算
辅助(辅助使用的是输入序列的ground truth),在MTP 1中做了下2个token预测,计算![]()
![]() 的损失。然后截取MTP 1
的损失。然后截取MTP 1 ![]()
![]() 的输出表征,结合
的输出表征,结合![]()
![]() 辅助,在MTP 2中做了下3个token的预测,计算
辅助,在MTP 2中做了下3个token的预测,计算![]()
![]() 的损失。下图能很好的展示这一点这一过程:
的损失。下图能很好的展示这一点这一过程:
![]()
在DeepSeek-V3中,设置的预测深度为1,即只额外预测1个token,这种情况下,就不存在上述歧义了。为了简化代码逻辑,本文也将预测深度固定为1,代码如下:
![]()
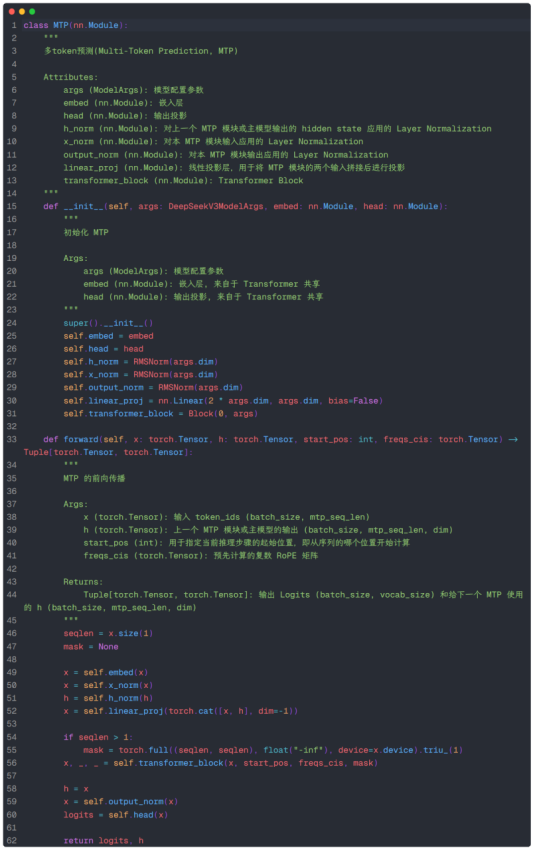
其实现也比较简单,需要注意以下几点:
-
原文的图中,每个MTP的 Transformer Block在输出head前没有体现出norm,但主模型的源代码有,因此这里也加上self.output_norm。
-
原文中未说明MTP使用的是否是MoE架构,这里我使用普通MLP作为前馈。
-
MTP只在训练时使用,因此这里需添加mask的逻辑。
-
输入序列长度标记为mtp_seq_len,这是因为当预测深度k=1时,MTP的输入长度比原序列长度少1。
-
最终返回MTP的logits,和用于下一个MTP模块使用的输出表征(由于这里固定预测深度为1,所以实际上没有用到它)
整体模型
最终,我们将上述所有模块构造成整体模型,代码如下:
![]()
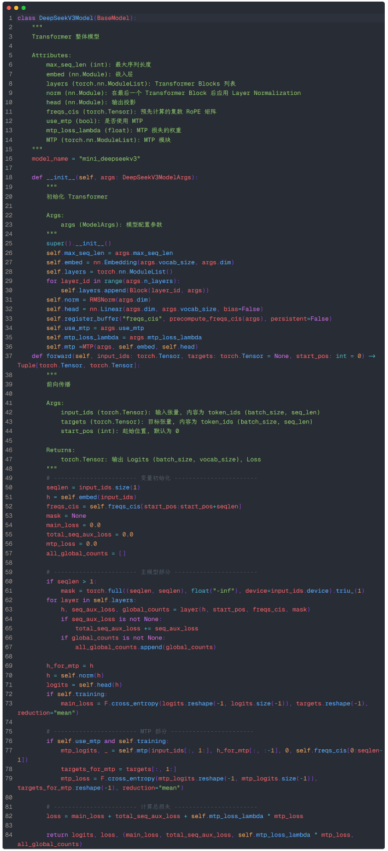
主模型大致也可分为四个部分,这里主要说明一下主模型部分、MTP部分和总损失部分:
1. 主模型部分
![]()

seqlen为1通常是使用KV Cache推理时,此时无需mask,若大于1,则需要使用因果mask。

前向传播每个Transformer Block,收集各层的序列级辅助损失和专家负载情况。

一方面将主模型输出表征赋值给h_for_mtp,用于输入到MTP模块,另一方面继续进入到RMSNorm和输出头,计算主模型损失。
2. MTP部分
![]()

由于预测深度固定为1,这里截取input_ids为input_ids[:, 1:],充当MTP的辅助输入,截取的h_for_mtp[:, :-1],代表MTP上一个模块的输出表征。target则截取为targets[:, 1:]。最后计算出MTP的损失,该部分只在训练时执行。
3. 总损失部分
![]()

最终,总损失由主模型损失、所有层的序列级辅助损失和MTP损失构成。前向传播返回模型输出的logits、loss和其他需要外部代码收集以进行可视化的数据。这里我将三种损失和专家负载情况传出,用于后续监控训练过程和可视化。
结语
项目具体的训练代码等在此不做介绍了,可在https://github.com/WKQ9411/Mini-LLM查看所有代码。最终效果如下:
参考链接
1. [DeepSeek-V3 technical report]( http://arxiv.org/abs/2412.19437)
2. [DeepSeek-V2: A strong, economical, and efficient mixture-of-experts language model]( http://arxiv.org/abs/2405.04434)
3. [DeepSeekMoE: Towards ultimate expert specialization in mixture-of-experts language models]( http://arxiv.org/abs/2401.06066)
4. [Auxiliary-loss-free load balancing strategy for mixture-of-experts]( http://arxiv.org/abs/2408.15664)
5. [优雅地实现多头自注意力——使用einsum(爱因斯坦求和)进行矩阵运算](https://www.cnblogs.com/qftie/p/16245124.html)
6. [DeepSeek-V3 MLA 优化全攻略:从低秩压缩到权重吸收,揭秘高性能推理的优化之道](https://zhuanlan.zhihu.com/p/25449691772)
7. [全网最细!DeepSeekMTP 多Token预测:从算法原理到代码实现](https://www.bilibili.com/video/BV1QEwReKEHg/?spm_id_from=333.1391.0.0&vd_source=8d0e80baab699baab100ac9fdf2c4028)
8. [deepseek技术解读(2)-MTP(Multi-Token Prediction)的前世今生](https://zhuanlan.zhihu.com/p/18056041194)

欢迎在评论区留言与本文作者互动交流!
作者简介
王坤擎,国防科技大学智能科学学院 | 控制科学与工程(认知科学创新实验室) 硕士。对大模型和智能交互技术抱有浓厚兴趣和持续学习的热情,致力于实现更高效、自然的智能交互喜欢深入研究探索新鲜技术,记录并分享收获与心得。
数据派研究部介绍
数据派研究部成立于2017年初,以兴趣为核心划分多个组别,各组既遵循研究部整体的知识分享和实践项目规划,又各具特色:
算法模型组:积极组队参加kaggle等比赛,原创手把手教系列文章;
调研分析组:通过专访等方式调研大数据的应用,探索数据产品之美;
系统平台组:追踪大数据&人工智能系统平台技术前沿,对话专家;
自然语言处理组:重于实践,积极参加比赛及策划各类文本分析项目;
制造业大数据组:秉工业强国之梦,产学研政结合,挖掘数据价值;
数据可视化组:将信息与艺术融合,探索数据之美,学用可视化讲故事;
网络爬虫组:爬取网络信息,配合其他各组开发创意项目。
点击文末“阅读原文”,报名数据派研究部志愿者,总有一组适合你~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THUID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
未经许可的转载以及改编者,我们将依法追究其法律责任。
