LatticeWorld框架将AI大模型与虚幻引擎5融合,实现描述即3D虚拟世界,效率提升90倍。为游戏、自动驾驶等领域带来革命性突破。
原文标题:工业级3D世界构建提速90倍!全新框架LatticeWorld让虚拟世界「一句话成真」
原文作者:机器之心
冷月清谈:
为解决这些难题,网易、香港城市大学等机构联合提出了LatticeWorld框架。该框架巧妙地将轻量级大语言模型(LLaMA-2-7B)与工业级渲染引擎虚幻引擎5(UE5)无缝融合,打通了程序化内容生成(PCG)管线。
LatticeWorld支持文本描述和视觉指令(如高度图、草图)的多模态输入,能够高效生成具备高动态环境、真实物理仿真和实时渲染的大规模交互式3D世界,并高效支持多智能体交互。相较于传统手工制作流程,它在保持高质量创作的同时,创作效率飙升90倍。
框架核心由三大组件构成:
1. **场景布局生成模块:** 采用大语言模型处理场景布局和环境配置,结合多模态视觉融合机制(通过CLIP视觉编码器和CNN投影网络),从多模态输入中生成创新的符号序列场景布局(例如,F代表森林,W代表水体等)。这种方法有效保持了空间关系的完整性,使纯文本基础模型能理解并生成复杂的二维空间布局。
2. **环境配置生成模块:** 基于已生成的场景布局和视觉输入,结合环境配置的文本描述,LatticeWorld进一步构建模型生成详细的环境配置参数,包括分层的场景属性(涵盖粗粒度地形、季节、天气等和细粒度资产材质、密度等)以及智能体参数(类别、数量、行为、位置),并以JSON格式输出。这确保了场景的语义一致性并减少了参数冲突。
3. **程序化渲染管线模块:** 将符号化场景布局和JSON格式的环境配置解码转译,将其转换为UE5等渲染引擎可理解的输入形式,最终生成可交互、可定制化的3D虚拟世界。
实验证明,LatticeWorld在场景布局和环境配置生成方面表现优异,能有效依据文本描述调整环境属性,并支持生成动态交互式智能体环境。在应用领域上,该框架对具身智能、自动驾驶、游戏开发和影视制作等具有重大意义。未来,该框架有望在智能体行为策略、多玩家控制、精细化智能体控制及扩充资产库等方面持续发展。
怜星夜思:
2、文章提到了文本描述和视觉指令(如高度图、草图)作为多模态输入,这无疑大大增加了灵活性。但除了这些,未来LatticeWorld还能引入哪些类型的“模态”来进一步提升其生成能力和用户体验?比如,声音输入、手势识别,甚至情绪感知?这些新模态会如何影响3D世界的构建流程和最终效果?
3、LatticeWorld在工业级3D世界构建上取得了显著进展。但它在未来商业化应用中可能遇到哪些挑战?例如,资产库的版权问题、生成内容的细致度是否能满足顶级项目的需求、以及如何确保生成内容的“独特性”和“创意性”而非千篇一律?对于独立开发者或小型团队来说,LatticeWorld的普及门槛高吗?
原文内容

本文的作者来自网易、香港城市大学、北京航空航天大学和清华大学等机构。本文的共同第一作者为网易互娱段颖琳、北京航空航天大学邹征夏、网易互娱谷统伟。本文的通讯作者为香港城市大学邱爽、网易互娱陈康。

-
论文题目:LatticeWorld: A Multimodal Large Language Model-Empowered Framework for Interactive Complex World Generation
-
文章链接:https://arxiv.org/pdf/2509.05263
构建一个工业级高仿真 3D 虚拟世界,需要投入多少时间与人力?如果仅需一段描述、一张草图,AI 便可快速自动生成 —— 你相信吗?
这并非科幻!最新论文提出的 LatticeWorld 框架让「指令直达场景」。该方法将大语言模型与工业级 3D 渲染引擎虚幻引擎 5(Unreal Engine 5,UE5)无缝融合,打通工业级程序化内容生成(PCG)管线,实现让虚拟世界「一句话成真」。创作效率提升 90 倍,为 3D 世界构建带来了革命性的突破。
在具身智能、自动驾驶、游戏开发和影视制作等领域,高质量的 3D 世界构建具有重大意义。
在具身智能和自动驾驶中,高质量的 3D 虚拟世界可作为仿真与算法训练的关键基础设施;在游戏与影视领域,高质量 3D 世界可支撑逼真与沉浸体验。然而,传统的 3D 场景制作主要依赖艺术家手工建模,不仅成本高昂、耗时巨大,还难以快速响应多样化的创作需求。
随着生成式 AI 的快速发展,自动化的 3D 世界生成逐渐成为可能,为行业提供了新的解决思路。然而,现有方法存在显著局限:基于神经渲染的方法缺乏交互能力,限制了实际应用;基于扩散模型的视觉生成方案虽能创建内容,但依赖大量视频训练数据,在复杂物理仿真与多智能体交互场景中仍有待进一步发展。
对此,另一类研究尝试将生成式模型与 3D 建模平台相集成,其中以 Blender 平台尤为常见。不过,Blender 在实时交互的支持和高保真的物理仿真方面原生能力依然有限,不能很好的满足工业级 3D 世界建模的现实需求。
为解决上述难题,研究团队提出了一个高效的多模态 3D 世界生成框架 LatticeWorld。该框架巧妙地将轻量级大语言模型(LLaMA-2-7B)与工业级渲染引擎(如 UE5)相结合,支持文本描述和视觉指令的多模态输入,能够生成具备高动态环境、真实物理仿真和实时渲染的大规模交互式 3D 世界,并高效支持多智能体交互。相比传统手工化的工业流程,LatticeWorld 在保持高创作质量的同时,创作效率提升超过 90 倍,为 3D 世界构建带来了革命性的突破。

LatticeWorld 框架介绍
LatticeWorld 框架的核心思想是采用大语言模型处理场景布局和环境配置的生成,并构建多模态输入融合机制,可同时接收文本描述和视觉条件(如高度图或对应的草图)作为模型输入生成结构化的中间结果 (包括场景布局和 JSON 格式的场景与智能体参数),进一步通过定制的解码和转译流程中间结果映射为渲染引擎可理解的输入形式,最终由渲染引擎生成为可交互、可定制化的 3D 虚拟世界。
具体而言,本研究提出的 LatticeWorld 框架通过三个核心组件模块实现从自然语言描述与草图到完整 3D 场景的端到端生成:场景布局生成模块、环境配置生成模块、程序化渲染管线模块。

1. 场景布局生成
LatticeWorld 将场景布局生成问题建模为
![]()
其中![]() 为布局生成大语言模型,
为布局生成大语言模型,![]() 代表布局描述文本输入,
代表布局描述文本输入,![]() 表示视觉输入信息,如本文中的地形高度图等,
表示视觉输入信息,如本文中的地形高度图等,![]() 为视觉到语言的映射,而
为视觉到语言的映射,而![]() 为本论文中创新性提出的符号序列场景布局表示。其中,
为本论文中创新性提出的符号序列场景布局表示。其中,![]() 中还包含了特定的系统提示词,描述符号化布局中不同符号的含义。此外,值得注意的是,借助已有方法,地形高度图
中还包含了特定的系统提示词,描述符号化布局中不同符号的含义。此外,值得注意的是,借助已有方法,地形高度图![]() 可通过简单的手绘草图直接生成,显著降低视觉输入的复杂度并提升框架的可用性。
可通过简单的手绘草图直接生成,显著降低视觉输入的复杂度并提升框架的可用性。
符号序列场景布局表示:本文创新性地设计了一种场景布局中间表示方案。首先将复杂的空间场景布局转换为![]() (文中
(文中![]() 设为 32) 的符号矩阵:每个符号精确代表特定的资产类型,例如 F 表示森林区域,W 表示水体,B 表示建筑物,R 表示道路网络等。随后,这种符号化矩阵被序列化为大语言模型可直接处理的字符串格式:
设为 32) 的符号矩阵:每个符号精确代表特定的资产类型,例如 F 表示森林区域,W 表示水体,B 表示建筑物,R 表示道路网络等。随后,这种符号化矩阵被序列化为大语言模型可直接处理的字符串格式:
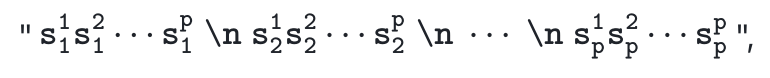
其中![]() 代表符号矩阵的第 i 行第 j 列个元素,而 \n 代表换行符。这种方式有效保持了空间关系的完整性,同时又可使纯文本基础模型能够理解和生成复杂的二维空间布局。
代表符号矩阵的第 i 行第 j 列个元素,而 \n 代表换行符。这种方式有效保持了空间关系的完整性,同时又可使纯文本基础模型能够理解和生成复杂的二维空间布局。
多模态视觉融合机制:针对具有高度变化的复杂地形场景,本文训练了视觉指令集成模块。该框架利用预训练的 CLIP 视觉编码器![]() 提取高维视觉特征表示,随后通过专门设计的多层 CNN 投影网络 Proj 将这些特征映射到
提取高维视觉特征表示,随后通过专门设计的多层 CNN 投影网络 Proj 将这些特征映射到 ![]() 的词嵌入空间:
的词嵌入空间:

论文采用精心设计的三阶段训练范式:(1) CLIP 微调阶段。专门针对地形理解任务对![]() 进行微调;(2) 持续预训练阶段。在保持
进行微调;(2) 持续预训练阶段。在保持![]() 和 CLIP 权重冻结的条件下进行 Proj 的训练;(3) 端到端微调阶段。构建相应的多模态数据集,每个样本包含视觉信息(高度图)、布局文本描述与符号化场景布局。在此基础上,采用交叉熵损失,联合优化 Proj 模块和
和 CLIP 权重冻结的条件下进行 Proj 的训练;(3) 端到端微调阶段。构建相应的多模态数据集,每个样本包含视觉信息(高度图)、布局文本描述与符号化场景布局。在此基础上,采用交叉熵损失,联合优化 Proj 模块和![]() ,其中
,其中![]() 使用轻量级大语言模型 LLaMA-2-7B。
使用轻量级大语言模型 LLaMA-2-7B。
2. 环境配置生成
基于已生成的场景布局![]() ,视觉输入信息
,视觉输入信息![]() ,以及环境配置的文本描述
,以及环境配置的文本描述![]() ,该方法进一步构建了环境配置生成模型
,该方法进一步构建了环境配置生成模型![]() ,并生成环境配置参数
,并生成环境配置参数![]() :
:
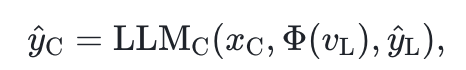
该模型能够生成关于场景内容的两方面配置:(1)场景属性,(2)智能体参数,该两方面配置则以 JSON 数据格式的来表达。针对![]() 的训练,该方法构建相应数据集,每个数据样本包含视觉信息(高度图)、环境配置文本描述、场景布局以及对应的环境配置,并在此基础上使用交叉熵损失函数对轻量级大语言模型 LLaMA-2-7B 进行微调,最终得到
的训练,该方法构建相应数据集,每个数据样本包含视觉信息(高度图)、环境配置文本描述、场景布局以及对应的环境配置,并在此基础上使用交叉熵损失函数对轻量级大语言模型 LLaMA-2-7B 进行微调,最终得到![]() 。
。
层次化场景属性框架:该方法建立了双层场景属性的层次化结构来精确建模场景特征。其中,粗粒度属性层控制全局环境特征,包括地形类型、季节变化、天气状况、时间设定和艺术风格等宏观参数。细粒度属性层则涵盖多种细节参数,如资产的材质、密度、位置、朝向等。这些细粒度参数的具体表现又会受到粗粒度属性的约束和影响,确保场景的语义一致性并有效减少复杂环境中的参数冲突。
智能体参数生成:该框架能够生成动态智能体配置信息,包括智能体类别分类 (人形机器人、机器狗、动物等)、数量、行为状态 (静止、移动等) 和空间位置等。这些参数生成受到场景属性约束和视觉条件限制,确保智能体的正确布置,例如水生动物仅出现在水体区域。
3. 程序化渲染管线
在生成得到符号化场景布局和环境配置后,该方法通过特定的渲染过程
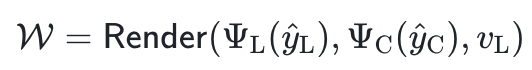
来最终得到虚拟的 3D 世界![]() 。其中,Render 为特定的 3D 渲染引擎,本文采用工业级渲染引擎 UE5。
。其中,Render 为特定的 3D 渲染引擎,本文采用工业级渲染引擎 UE5。![]() 和
和 ![]() 分别作为场景布局的解码器和环境配置的转译系统,将符号化场景布局和 JSON 格式的环境配置转换为 3D 渲染引擎的输入。
分别作为场景布局的解码器和环境配置的转译系统,将符号化场景布局和 JSON 格式的环境配置转换为 3D 渲染引擎的输入。
场景布局解码器:![]() 实现对生成的符号化场景布局进行精确处理:(1) 将
实现对生成的符号化场景布局进行精确处理:(1) 将![]() 符号化场景布局转换为各场景类型的降采样二值掩码图片;(2) 调整掩码图像以达到特定的场景大小并通过边缘平滑技术形成不同类型场景内容的自然过渡区域;(3) 输出渲染引擎直接可读的对应多场景类型的多通道灰度图像。
符号化场景布局转换为各场景类型的降采样二值掩码图片;(2) 调整掩码图像以达到特定的场景大小并通过边缘平滑技术形成不同类型场景内容的自然过渡区域;(3) 输出渲染引擎直接可读的对应多场景类型的多通道灰度图像。
环境配置转译系统:![]() 负责将 JSON 格式的环境配置参数转译为特定渲染引擎的原生属性格式,精确控制物体和智能体的类型、状态、空间分布等详细参数。
负责将 JSON 格式的环境配置参数转译为特定渲染引擎的原生属性格式,精确控制物体和智能体的类型、状态、空间分布等详细参数。![]() 通过编写转换脚本或借助以 Houdini 等软件为基础开发的专业插件来实现转译流程的自动化。
通过编写转换脚本或借助以 Houdini 等软件为基础开发的专业插件来实现转译流程的自动化。
4. 数据集构建
论文中构建了两个高质量的数据集来进行模型训练:(1)LoveDA,包含 8,236 个精心标注的郊区场景实例,通过对开源数据集 LoveDA 进行处理和增强后得到。该数据集的场景设定为固定高度。(2)Wild,包含 24,380 个多样化的荒野地形实例,通过采集卫星地图数据进行处理并增强后得到。该数据集的场景设定为可变高度,因此包含高度图和对应的草图。
在以上两个数据集中,首先分别构建每个卫星图片样本的场景布局和对应的符号化场景布局,同时生成相应的高度图和草图。随后进行数据增强,包括对每个样本中的图片和对应的符号化场景布局进行多次旋转等,以提升训练所得模型的鲁棒性。进一步,通过 GPT-4o 对布局图片进行文字标注,结合精心设计提示词工程,GPT‑4o 能够提供场景和资产的有效的空间关系与分布描述。对于高度图,同样利用 GPT‑4o 生成关于地形起伏变化及其方向的描述。最终得到了对应的场景布局数据集用以训练![]() 和
和![]() 。
。
进一步,构造环境配置数据集以训练![]() 。本文对应的提出一种分层框架,构造 LoveDA 和 Wild 环境配置样本。首先用 GPT‑4o 为布局图与高度图生成文字描述。然后采用部分随机采样(针对某些场景无关的配置)与结构化提示词工程相结合的方式生成 JSON 格式的环境配置(含场景属性与智能体参数)。最后,采用基于特定规则的提示词,将环境配置与场景布局以及高度图的描述融合,指导 GPT‑4o 生成完整的环境配置文本描述。
。本文对应的提出一种分层框架,构造 LoveDA 和 Wild 环境配置样本。首先用 GPT‑4o 为布局图与高度图生成文字描述。然后采用部分随机采样(针对某些场景无关的配置)与结构化提示词工程相结合的方式生成 JSON 格式的环境配置(含场景属性与智能体参数)。最后,采用基于特定规则的提示词,将环境配置与场景布局以及高度图的描述融合,指导 GPT‑4o 生成完整的环境配置文本描述。
实验对比
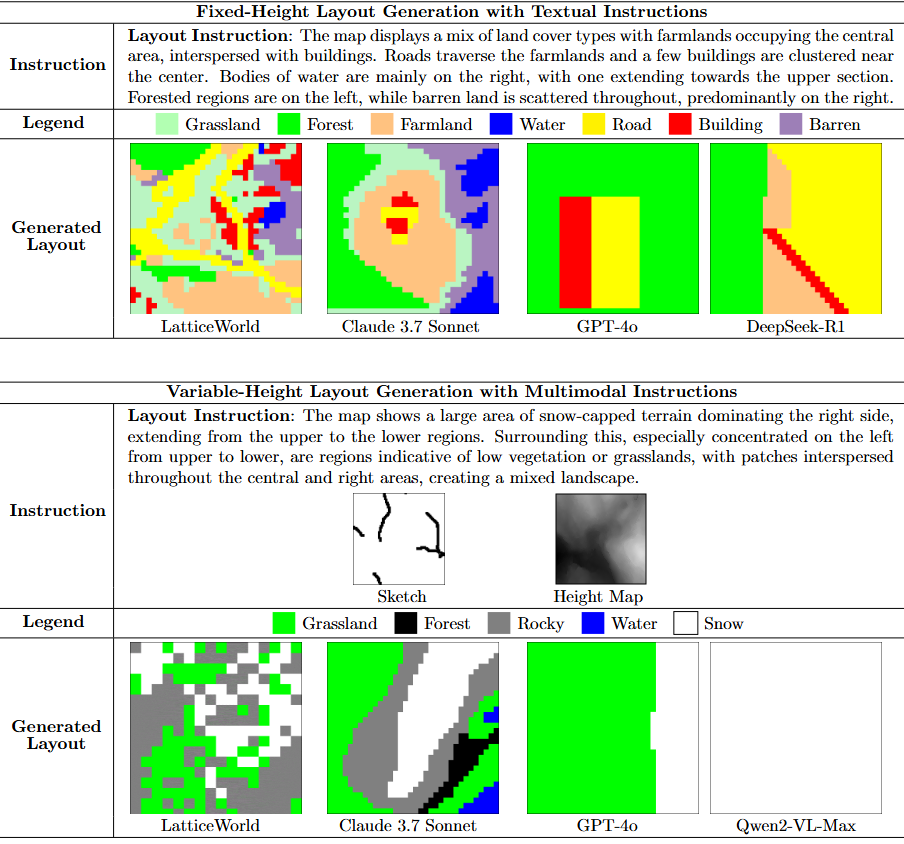
1. 基于多模态指令的场景布局生成
文中将 LatticeWorld 与 GPT-4o、Claude 3.7 Sonnet、DeepSeek-R1 和 Qwen2-VL-Max 等模型进行对比,在固定高度条件(仅文本描述)和可变高度条件(草图所对应转化成的高度图的视觉信号)下测试文本到布局的生成能力。结果显示 LatticeWorld 在生成准确布局方面表现更优。
2. 环境生成能力评估
下面的表格展示了 LatticeWorld 在不同多模态布局指令下的场景生成能力,通过 $$32\times 32$$ 的符号矩阵编码空间关系,结合文本和视觉输入进行场景生成,所有布局均在 UE5 中渲染。
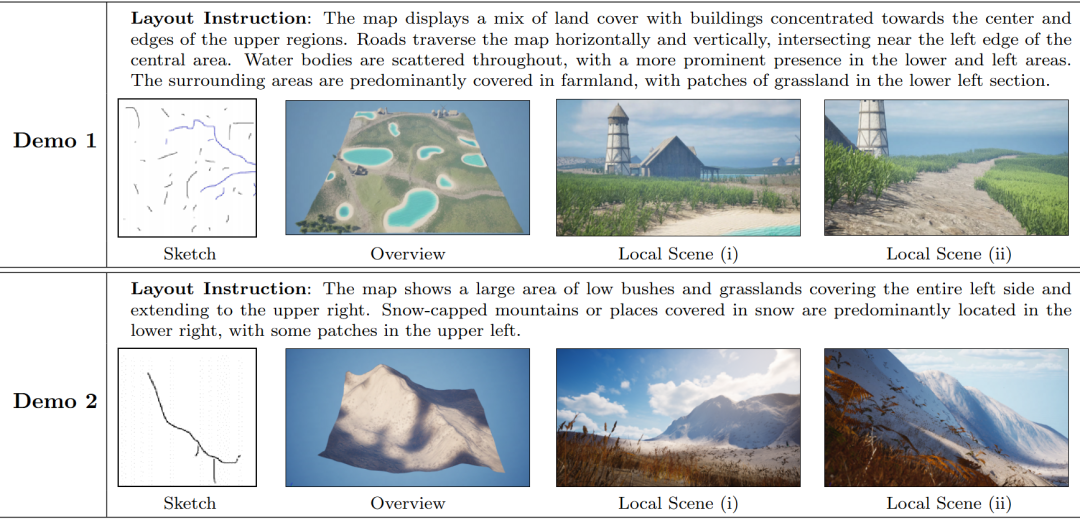
3. 场景属性生成验证
在该实验中,固定场景布局并输入不同的环境描述,验证了 LatticeWorld 支持多样化的自然环境生成,并能够有效地依据文本描述调整整个场景的环境属性。

4. 生成动态交互式智能体环境
表格展示了基于 LatticeWorld 构建多智能体交互环境的能力。LatticeWorld 支持通过文本描述生成智能体参数配置(类型、数量、分布、行为等)。生成的 3D 世界中可预置了基于预定义规则的自主对抗行为,如在接近时进行追逐和攻击。

5. LatticeWorld 与专业艺术家对比
使用相同的布局和参数指令,对比专业艺术家手工创作和 LatticeWorld 生成的环境。工作量对比显示,LatticeWorld 将总制作时间从 55 天(手工)降低到不到 0.6 天,效率提升超过 90 倍,在生成多个环境时优势更加明显。
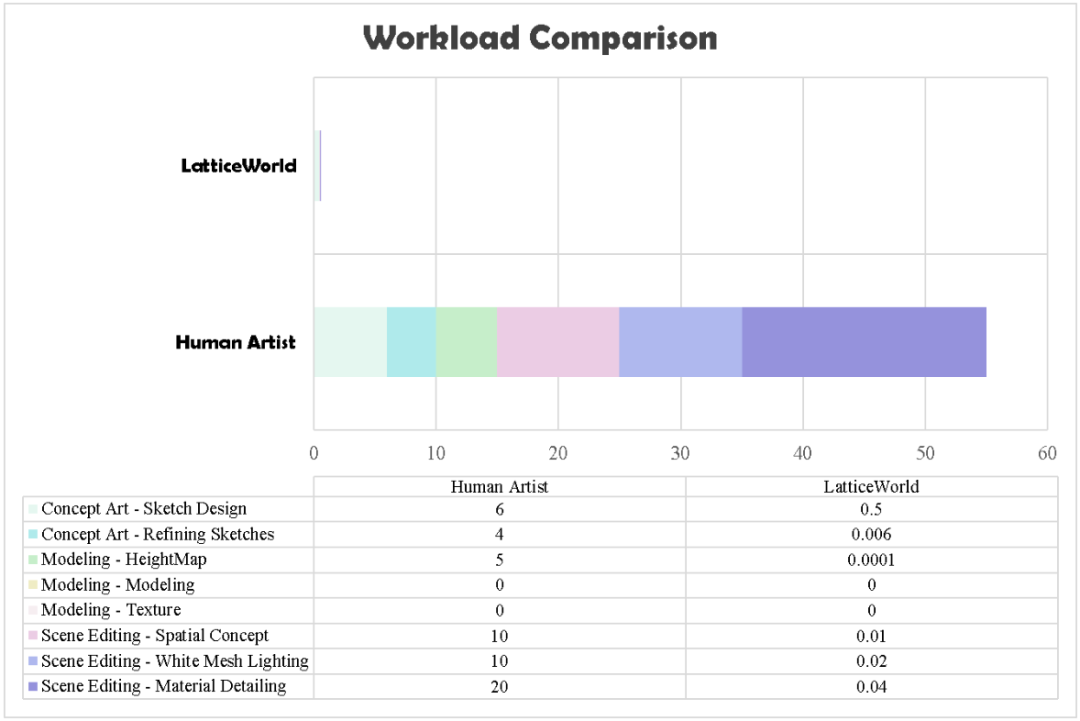
下方表格展示了两者在构建场景的效果上的对比,可见 LatticeWorld 保证了极高的生成质量。

未来展望
未来该框架可继续扩展研究的方向包括:(1) 设计更多样化的对抗智能体行为策略,提升交互的丰富性;(2) 支持多玩家控制和 AI 算法策略;(3) 实现主智能体身体部位的精细化独立控制;(4) 扩充资产库,增加更多对象和交互元素以生成更加多样的虚拟世界。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com