浙大团队综述:机器学习加持的“增强采样”方法,突破分子模拟时间尺度限制。进展包括CV构建、偏置势能表征,但全自动化、可解释性仍是挑战。未来有望实现“计算显微镜”愿景。
原文标题:浙大侯廷军团队联合IIT等发布系统综述:全景解析机器学习加持下的「增强采样」方法
原文作者:数据派THU
冷月清谈:
综述全面阐述了ML与增强采样融合的方法论进展,并提供了实践应用视角,涵盖蛋白质折叠、配体结合、化学催化及结构相变等多个重要领域。其中,机器学习在集合变量(CV)的构建方面取得了最具实质性和广泛性的进展,不仅显著加速了模拟过程,也催生了多样化的策略和学习目标。
除CV构建外,ML还在表征偏置势能、优化自由能微扰方案以及指导副本交换协议等方面推动着增强采样技术的发展。虽然目前一些用ML算法完全取代偏置方案或生成模型替代传统采样的新方法仍处于萌芽阶段,但其前景可观。然而,将这些先进方法扩展到更大更复杂的异质体系,如固有无序蛋白或生物分子组装体,面临巨大挑战,主要在于现有部署尚未实现全自动化,仍需大量化学直觉。
为实现全自动增强采样的目标,未来的突破口在于:一是提升表征学习能力,克服复杂体系描述符构建的瓶颈;二是将集合变量学习与偏置势能学习统一于端到端框架,实现探索与收敛的自动化;三是增强方法的可解释性,密切融合可解释人工智能。最终目标是通过加强ML与增强采样及机器学习势函数的融合,并开发统一的软件生态系统,将MD模拟转化为能够在扩展时空尺度上揭示复杂体系微观机理的“计算显微镜”。
怜星夜思:
2、综述指出,要实现全自动增强采样,克服“化学直觉”的依赖是关键。对于从事相关研究的同学来说,你们觉得哪些“化学直觉”是最难被模型学习或替代的?我们应该如何平衡人的经验和机器的智能?
3、文章最后提到了可解释性对大型复杂模型的重要性。在科学研究,特别是分子动力学这种需要精确定位原子级机理的领域,如果一个AI模型给出了看似正确的结果,但我们无法理解其内部逻辑,这会不会让它的应用打上问号?你们认为在这些高精度科学领域,AI的“黑箱”问题有多严重?
原文内容

来源:ScienceAI本文约1400字,建议阅读5分钟全景解析了在机器学习技术的加持下,增强采样方法的发展。
分子动力学(MD)模拟已成为理解分子尺度物理、化学与生物过程不可或缺的工具,在揭示复杂分子体系的微观行为机制方面具有巨大潜力。
然而,传统的 MD 方法因为模拟的时间尺度有限,其有效性常受限于稀有事件相关的长时间尺度问题。为应对该挑战,增强采样方法应运而生,近年来更是与机器学习技术日益深度融合。
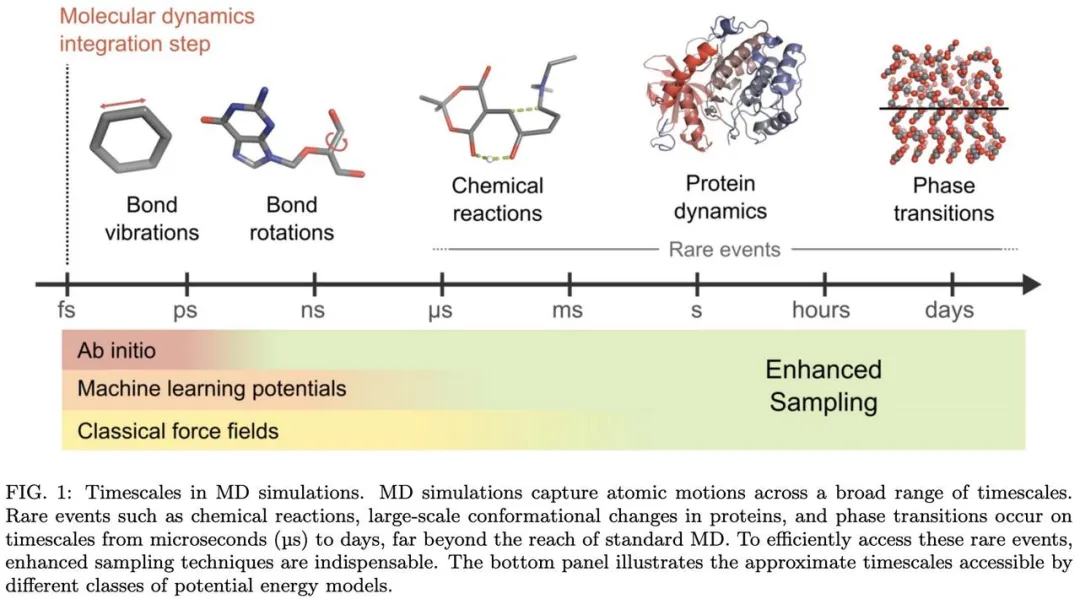
近期,浙江大学药学院侯廷军团队联合意大利技术研究院(IIT)等发布了一篇综述 ——《Enhanced Sampling in the Age of Machine Learning: Algorithms and Applications》,全景解析了在机器学习技术的加持下,增强采样方法的发展。浙江大学药学院博士生祝凯是综述共同一作。

综述地址:https://arxiv.org/pdf/2509.04291
综述概览
该综述旨在全面阐述 ML 与增强采样技术融合的方法论进展,并为关注实际应用的研究者提供实践视角。综述展示了跨领域应用案例,重点分析了实际部署此类模型的需求与挑战,涵盖蛋白质折叠等生物构象变化、配体结合热力学与动力学、化学催化反应及结构相变等重要领域。

在众多机器学习与增强采样的融合方向中,最具实质性和广泛性的进展体现在集合变量(collective variable,CV)的构建方面,但由于即使采用近似变量也能实现显著的加速效果,因此带来了两方面影响:一方面,它催生了多样化策略与学习目标的开发应用;另一方面,由于缺乏单一明确的目标,方法学变体激增。

除构建 CV 外,机器学习还在多个层面推动增强采样技术发展:包括表征偏置势能、优化自由能微扰方案、指导副本交换协议等。
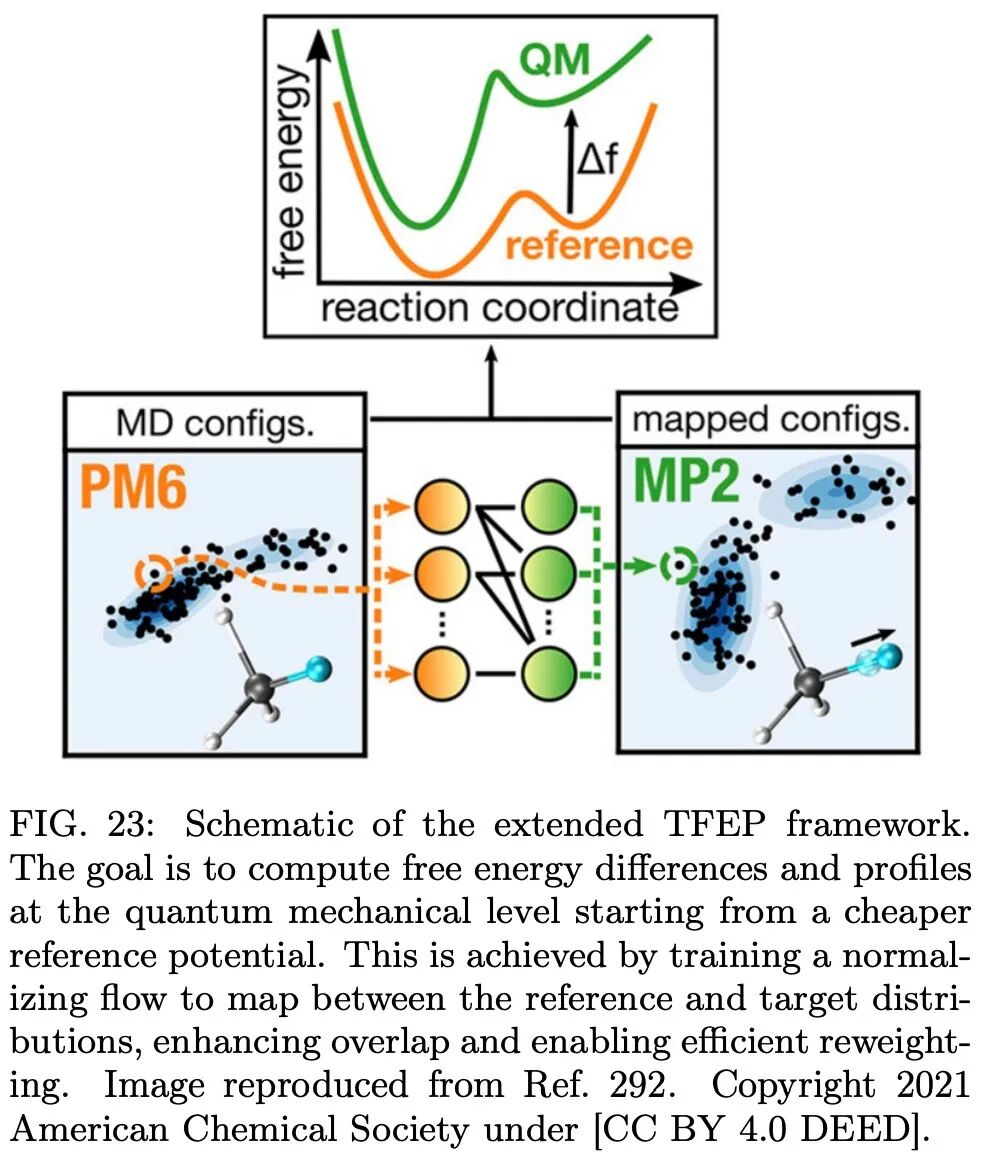
一些颇具前景的新方法正崭露头角,例如完全用机器学习算法取代偏置方案,甚至用生成模型替代传统采样。但这些研究仍处于萌芽阶段,尽管前景可观,新方法在成为通用解决方案之前仍面临重大障碍,尤其对于具有大量自由度(如溶剂分子)的大型真实体系。
综述指出:将机器学习技术加持的增强采样方法扩展到更大更复杂的异质体系(如固有无序蛋白、生物分子组装体或真实催化环境)仍存在巨大挑战。关键原因在于这些方法的部署尚未实现全自动化:仍需大量化学直觉来选择初始条件、定义合适表征方式及识别目标过程。
要实现全自动增强采样的目标,需要在多个层面取得突破:
首先,表征学习的进步至关重要。对复杂大型体系而言,构建合适描述符仍是主要瓶颈,往往需要深厚的领域专业知识。
第二,将集合变量学习与偏置势能学习统一于端到端框架尤其值得关注。传统上这两个环节相互分离,若将低维表征识别与偏置势的自适应构建耦合,可以形成全集成工作流,实现探索与收敛的双重自动化。
第三,随着方法学复杂度和表现力的提升,可解释性成为紧迫议题。领域需与可解释人工智能更紧密融合,以确保工具保持透明性、可解释性和实践可用性。
要实现这些突破,还需进一步加强增强采样与机器学习势函数的融合,并开发统一的软件生态系统,无缝集成工作流的所有环节:从表征学习与集合变量构建,到偏置方案设计、机器学习势函数应用,再到后处理分析工具与结果解读。
这些进展共同作用,终将把分子动力学转化为真正的「计算显微镜」,在扩展时空尺度上揭示复杂物理、化学、生物体系的结构、动力学与反应活性,提供原子级的机理洞察。
感兴趣的读者可以阅读综述原文,了解更多研究内容。
编辑:文婧
