IndexTTS-2.0实现精准时长与情感控制,开启AI语音合成新纪元,助力B站内容出海!
原文标题:B站出海的强有力支柱:最新开源文本转语音模型IndexTTS-2.0标志零样本TTS进入双维度时代
原文作者:机器之心
冷月清谈:
怜星夜思:
2、这个模型能把音色和情感都做得很真,还支持独立控制,听起来很强大也很酷。但话说回来,会不会被一些不怀好意的人拿去搞“声音诈骗”或者制造假新闻啊?我们普通人咋辨别真伪?
3、B站有了 IndexTTS-2.0 这把“秘密武器”,内容出海肯定更方便了。对于咱们普通内容创作者来说,这个技术能给咱们带来哪些实际的好处,或者说,你最希望用它来做点什么新东西?
原文内容

最近在 B 站上,你是否也刷到过一些 “魔性” 又神奇的 AI 视频?比如英文版《甄嬛传》、坦克飞天、曹操大战孙悟空…… 这些作品不仅完美复现了原角色的音色,连情感和韵律都做到了高度还原!更让人惊讶的是,它们居然全都是靠 AI 生成的!
英文版甄嬛传他来了
让坦克飞
B 站开源 index-tts-2.0 长视频测试,效果真的强,曹操大战孙悟空
如果让 AI 开中文苹果发布会,indextts2 效果展示
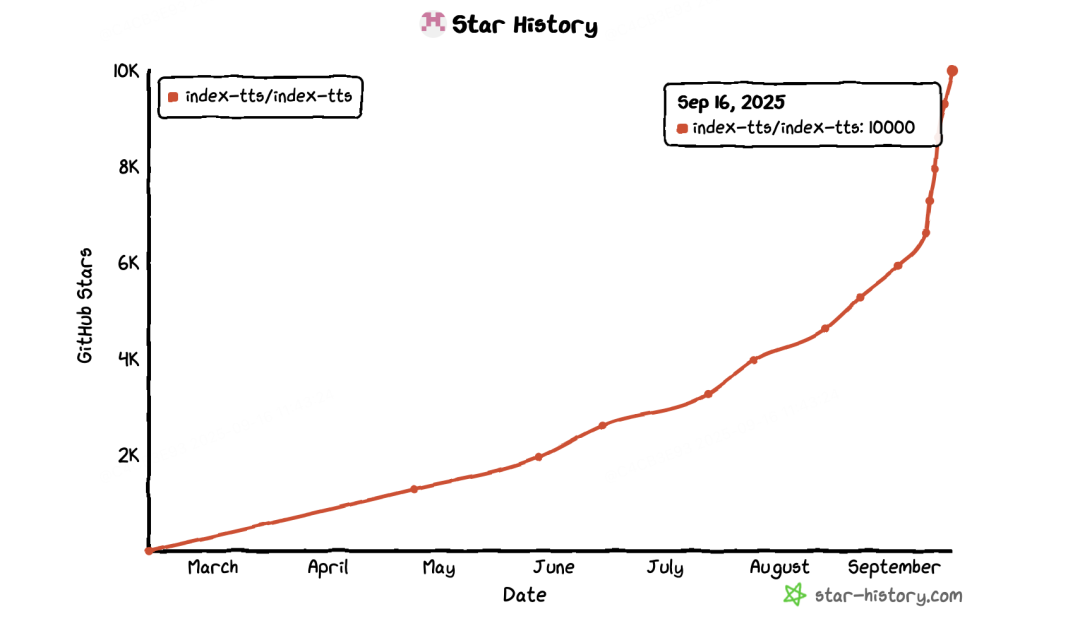
据悉,这些视频都是运用了哔哩哔哩 Index 团队最新开源的文本转语音模型 IndexTTS-2.0, 这一模型从 demo 发布起,就在海内外社区引发了不少的关注。目前该工作在 Github 已超过 10k stars 。

-
论文标题:IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech
-
论文链接:https://arxiv.org/abs/2506.21619
-
github 链接:https://github.com/index-tts/index-tts
-
魔搭体验页:https://modelscope.cn/studios/IndexTeam/IndexTTS-2-Demo
-
HuggingFace 体验页:https://huggingface.co/spaces/IndexTeam/IndexTTS-2-Demo
-
官宣视频:https://www.bilibili.com/video/BV136a9zqEk5/
近年来,大规模文本转语音(Text-to-Speech, TTS)模型在自然度和表现力上取得了显著进展,但如何让语音「在韵律自然的同时,又能严格对齐时长」仍是悬而未决的难题。传统自回归(Autoregressive, AR)模型虽然在韵律自然性和风格迁移上占优,却难以做到精准时长控制;而非自回归(Non-Autoregressive, NAR)方法虽能轻松操纵时长,却往往牺牲了语音的自然感和情绪表现力。如何在保留 AR 模型优势的同时,突破其核心限制,成为了前沿挑战。
来自哔哩哔哩的 IndexTTS 团队创新性地提出了一种通用于 AR 系统的 “时间编码” 机制,首次解决了传统 AR 模型难以精确控制语音时长的问题。这一新颖的架构设计不仅解决了时长控制问题,更引入了音色与情感的解耦建模,实现了前所未有的情感表现力和灵活控制,在多个指标上全面超越现有 SOTA 系统。
研究方法
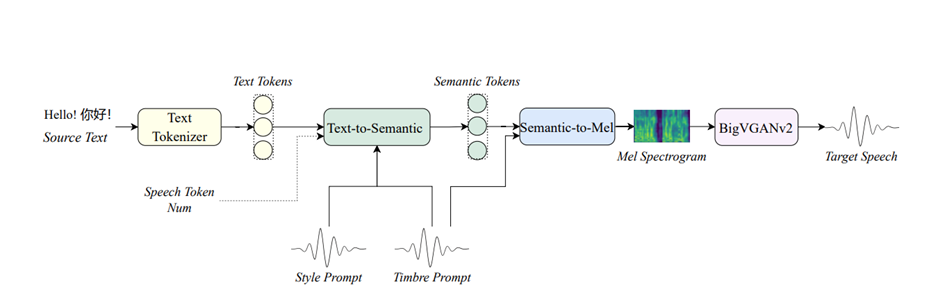
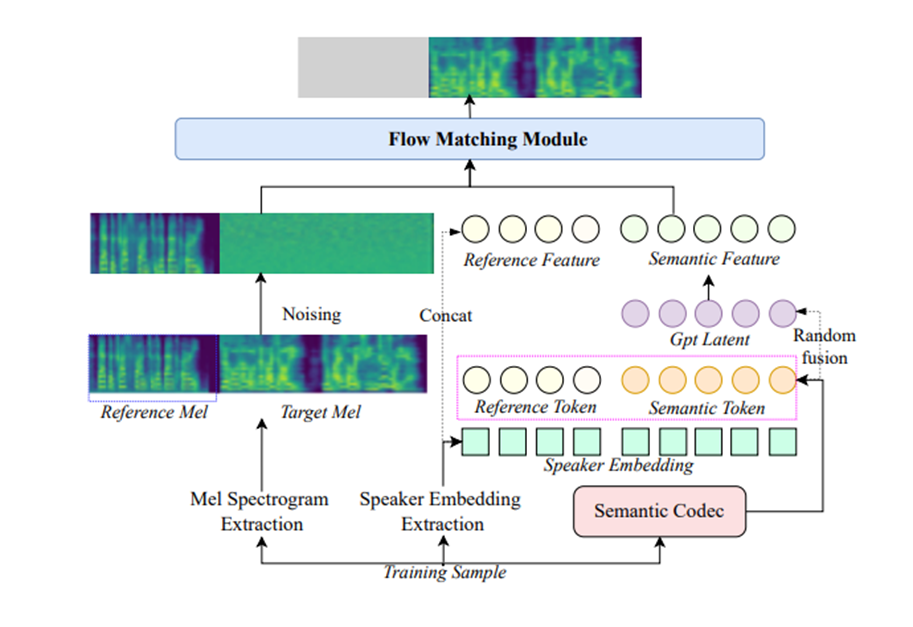
IndexTTS2 由三个核心模块组成:Text-to-Semantic(T2S) 、Semantic-to-Mel(S2M) 以及 BigVGANv2 声码器 。首先,T2S 模块基于输入的源文本、风格提示、音色提示以及一个可选的目标语音 token 数,生成对应的语义 token 序列。然后,S2M 模块以语义 token 和音色提示作为输入,进一步预测出梅尔频谱图。最后,BigVGANv2 声码器将梅尔频谱图转换为高质量的语音波形,完成端到端的语音合成过程。
IndexTTS2 可以在零样本条件下生成自然流畅的多情感、跨语言语音。它还支持在自回归框架下精确控制语音时长,让合成既可控又不失自然。同时具备工业级性能,既适合研究探索,也能直接应用到实际场景中。
1、基于 AR 架构的时长控制
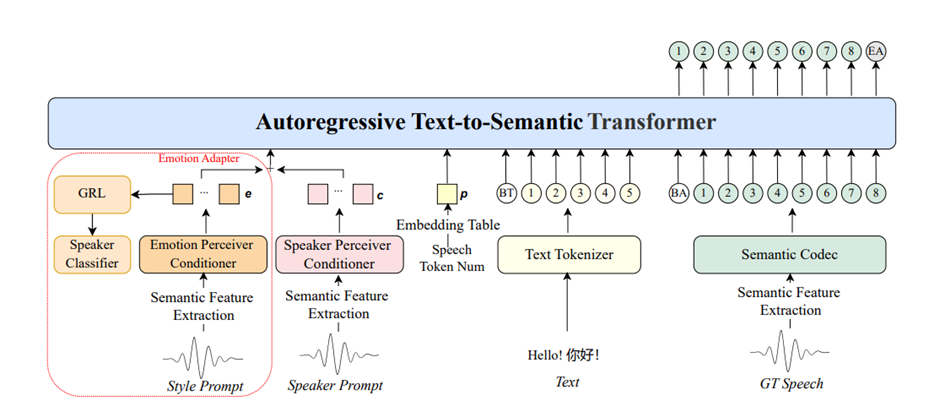
在 IndexTTS2 中,针对自回归 (AR) TTS 难以精确控制语音时长的问题,提出了基于 token 数量约束 的解决方案。核心思路是:在生成时可以指定所需的语义 token 数,模型通过一个专门的时长 embedding 将这个信息注入到 Text-to-Semantic 模块,通过对合成 token 的数量强约束来实现生成语音时长控制。训练阶段随机引入不同比例的信号层时长缩放 (如 0.75×、1.25×) 任务,使模型可以学会在各种长度要求下仍然保持语义连贯和情感自然。
实验表明,这种方法在不同语言(中 / 英)上的 token-number error rate 非常低,即模型几乎能严格按照指定的 token 数量生成语音,同时在合成质量、情感保真度和自然度上保持较好表现。换句话说,IndexTTS2 实现了在 AR 模型中罕见的高精度时长控制,使其既能保持逐帧生成带来的细腻表达,又能满足视频配音、音画同步等对时长严格敏感的场景需求。
2、多模态的情绪控制
IndexTTS2 对情感表达和说话人身份进行了有效解耦。模型不仅支持从单一参考音频中复刻音色与情感,还支持分别指定独立的音色参考和情感参考。这意味着用户可以用一个人的音色,说出另一个人的情感,极大地提升了控制的灵活性。
为了降低使用门槛,模型集成了两种情感控制方式。除了通过音频参考进行情感迁移,还引入了基于自然语言描述的情感软指令机制。通过微调大型语言模型(LLM),用户可以使用文本(如自然语言描述、场景描述)来精确引导生成语音的情绪色彩。
3、S2M 模块
为了提升在高强度情感(如哭腔、怒吼)下的语音清晰度,模型引入了 GPT 式潜在表征,并采用基于流匹配(Flow Matching)的 S2M 模块,显著增强了语音生成的鲁棒性和梅尔频谱图的重建质量。
研究结果
1、时长控制的准确性
IndexTTS2 在时长控制方面展现了极高的精确度。在对原始语音时长进行 0.75 倍至 1.25 倍的变速测试中,生成语音的 Token 数量误差率几乎不超过 0.03%,在多数情况下低于 0.02%,证明其时长控制能力精准可靠。
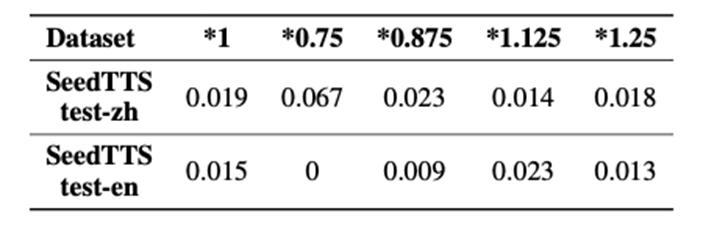
Table 1:不同设置下对持续时长控制的 token 数错误率
2、情感表现力
在情感表现力测试中,IndexTTS2 显著优于其他 SOTA 模型。其情感相似度(ES)高达 0.887,情感 MOS(EMOS)评分达到 4.22,合成的语音情绪饱满、渲染自然,同时保持了极低的词错误率(WER, 1.883%),实现了表现力与清晰度的完美结合。
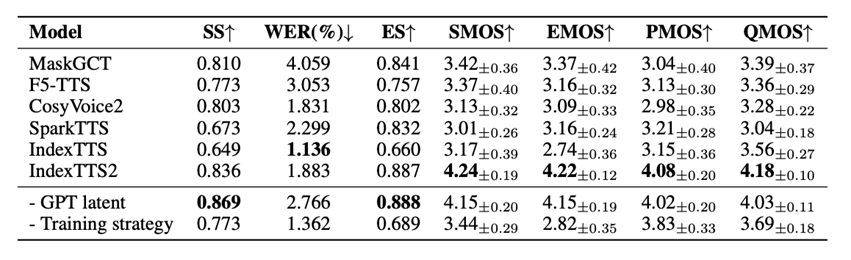
Table 2:在情感测试集上的结果
3、零样本语音合成能力
在多个公开基准测试集(如 LibriSpeech, SeedTTS)上,IndexTTS2 在客观指标(词错误率 WER、说话人相似度 SS)和主观 MOS 评分(音色、韵律、质量)上均达到或超越了当前最先进的开源模型,包括 MaskGCT, F5-TTS, CosyVoice2 等,展现了其强大的基础合成能力和鲁棒性。
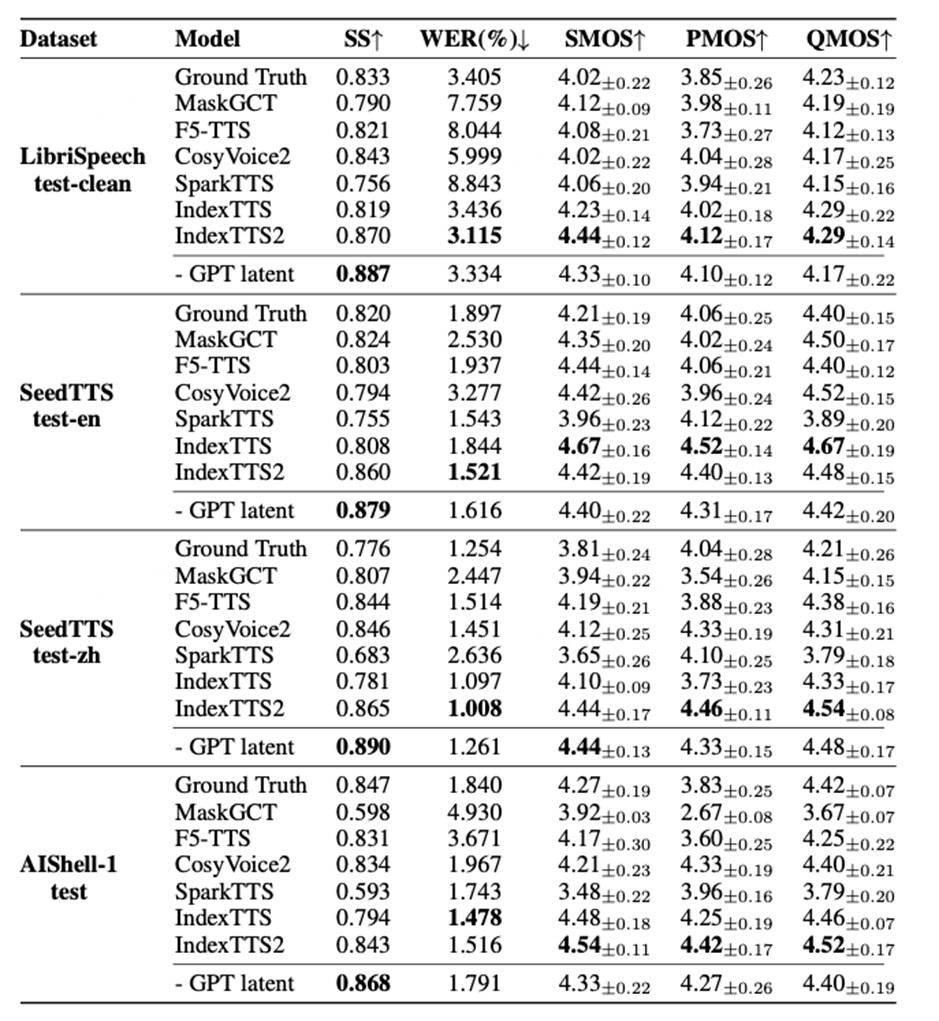
Table 3:在公开测试集上的结果
4、消融实验验证
实验证明,模型中的 GPT 潜在特征对于保证语音清晰度和发音准确性至关重要;而基于流匹配的 S2M 模块相比于传统的离散声学 Token 方案,极大地提升了合成语音的保真度和自然度。
生成效果
语速控制:支持自定义输入合成时长,精准控制语速
音色克隆:同时参考音色和情绪韵律,实现语音特征的高度还原
合成文本:你就需要我这种专业人士的帮助,就像手无缚鸡之力的人进入雪山狩猎,一定需要最老练的猎人指导
多元化的情绪输入:提供独立的情感参考音频、情感向量或文本描述等多种方式,显著提升生成语音的表现力与适用性
-
独立参考音频控制:
合成文本:你看看你,对我还有没有一点父子之间的信任了。
-
情绪向量控制:提供高兴、生气、悲伤、恐惧、讨厌、低落、惊喜、平静 8 种情绪向量,支持自由调整情绪权重,并提供随机采样
情绪向量 - 惊喜 0.45
合成文本:哇塞!这个爆率也太高了!欧皇附体了!
-
描述文本控制:还支持通过自然语言描述来判断情绪
情绪文本 - You scared me to death! What are you, a ghost?
文本:快躲起来!是他要来了!他要来抓我们了!
跨语种:支持中英文双语
合成文本:Translate for me,what is a surprise!
该模型凭借高质量的情感还原与精准的时长控制,广泛提升了 AI 配音、视频翻译、有声读物、动态漫画、语音对话等系列下游场景的可用性,尤其值得关注的是,IndexTTS-2.0 为 B 站优质内容的出海提供了关键技术支持,在充分保留原声风格与情感特质的基础上,让海外用户享受更加自然、沉浸的听觉感受。这一技术突破不仅极大降低了高质量内容跨语言传播的门槛,也为 AIGC 技术在全球范围内的实际应用奠定了坚实基础,堪称零样本 TTS 技术迈向实用化阶段的重要里程碑。
总结
IndexTTS2 的提出标志着零样本 TTS 进入「情感可控 + 时长精确」的双维度时代。它不仅大幅提升了 AI 配音、视频翻译等多种下游场景的可用性,同时,也为未来语音合成技术的发展指明了重要方向:如何在 AR 框架下实现对情感、语调等更复杂语音特征的细粒度控制,并持续优化模型性能,为更广泛的交互式应用提供支持。
研究团队现已开放模型权重与代码,这意味着更多开发者和研究人员能够基于 IndexTTS2 构建个性化、沉浸式的语音交互应用。
作者介绍:
本论文主要作者来自哔哩哔哩 Index 语音团队(Bilibili IndexTTS),Index语音团队是一支专注于音频技术创新的研究团队,致力于音频生成、语音合成与音乐技术的前沿探索,重点研究高保真、自然真实、可控性强的语音生成模型。团队推出的全新一代 zero-shot TTS 自回归大模型 IndexTTS2,具备出色的情感表现力,支持音色与情感的自由组合,并创新性地设计了“时长编码”,实现了模型层面的精准时长控制。团队通过深度学习与神经网络技术的不断突破,持续为学术界与工业界提供高质量的语音合成技术支持与创新方案,助力创作者用声音打破表达边界。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com