快手OneSearch:业界首个生成式端到端电商搜索框架。AI赋能精准匹配,彻底解决传统搜索痛点,大幅提升用户购物体验,尤其在中长尾与冷启动场景表现卓越。
原文标题:OneSearch,揭开快手电商搜索「一步到位」的秘技
原文作者:机器之心
冷月清谈:
为突破这些限制,快手推出了业界首个工业级部署的电商搜索端到端生成式框架——OneSearch。这个框架的核心创新在于:
1. **关键词增强层次量化编码(KHQE)模块**:针对商品标题混乱的问题,OneSearch能够精准提取商品的核心属性(如品牌、品类、颜色),并采用RQ-OPQ编码方案,为每个商品生成一个包含从粗粒度到细粒度属性的“智能身份证”。这种5层编码结构增强了Query-商品相关性约束,显著提升了检索的区分度和准确性。
2. **多视角用户行为序列注入策略**:传统用户ID缺乏语义信息,难以捕捉用户偏好。OneSearch通过结合用户显式的短期行为(近期搜索、点击)和隐式的长期行为序列(历史购买),构建了富有语义信息的“用户标识”。它以高效的SID维度嵌入方式,全面而精准地建模用户兴趣,即使是新用户也能获得更好的体验。
3. 引入偏好感知奖励系统(PARS):OneSearch通过多阶段监督微调(SFT)和自适应奖励强化学习机制,让生成式模型不仅理解Query与Item的相关性,还能根据用户个性化偏好进行排序。它将用户行为划分为不同等级并赋予动态奖励权重,并通过奖励模型对齐线上精排分布,最终突破排序性能上限。
经过离线与在线的严格评测,OneSearch V2版本相比传统级联系统在CTR、CVR、订单量、买家数等核心指标上均有显著提升(订单量提升3.22%,买家数提升2.4%)。尤其在处理用户高、中、低频Query,以及中长尾和冷启动场景时,表现尤为突出。此外,OneSearch大幅提升了机器计算效率(MFU提升8倍)并降低了线上推理成本(OPEX降低75.40%)。这些成果验证了生成式模型在电商搜索全链路的落地可行性,为数百万用户带来了更精准、更流畅的购物体验。未来,快手团队将继续探索在线实时编码与多模态特征融合,持续提升搜索的智能性和人性化。
怜星夜思:
2、文章里提到OneSearch会根据用户长短期行为序列构建独特的“用户标识”来推断偏好,听起来很智能。但现在大家对数据隐私越来越看重,电商平台在追求精准推荐的同时,怎么平衡好用户隐私保护和个性化服务这俩事儿呢?
3、OneSearch未来规划里提到要搞在线实时编码,还要结合图像、视频等多模态特征,听起来酷毙了。但快手这种体量的平台,做这些会有哪些技术大挑战?对咱们用户的体验和系统反应速度会不会有影响呢?
原文内容
机器之心编辑部
还有一个多月,一年一度的“双十一”购物节就要来了!
作为消费者,你通常会如何寻找心仪的商品呢?或许你兴致勃勃地在搜索框里敲下关键词,却发现呈现出来的商品列表总是差强人意。那么,问题究竟出在哪里?
这一切,还要从电商平台常用的传统搜索架构说起。目前主流系统采用“召回 -> 粗排 -> 精排” 的级联式架构。
-
召回层:比如你搜索 “红色连衣裙”,系统会迅速从数亿商品中筛选出上万个包含 “红色”“连衣裙” 关键词的商品。这步追求快和全,但精度不高 —— 难免会出现一些标题党商品(比如标题强行蹭热点,写 “红色连衣裙” 但其实卖的是搭配的开衫)
-
粗排层:系统使用轻量级模型对这上万个商品粗略排序,去掉一些明显不相关的商品。
-
精排层:采用更复杂、精细的模型,对几百个剩余商品进行最终排序。它会综合考量点击率、销量、价格、用户历史偏好等多种因素,返回你最终看到的商品列表。
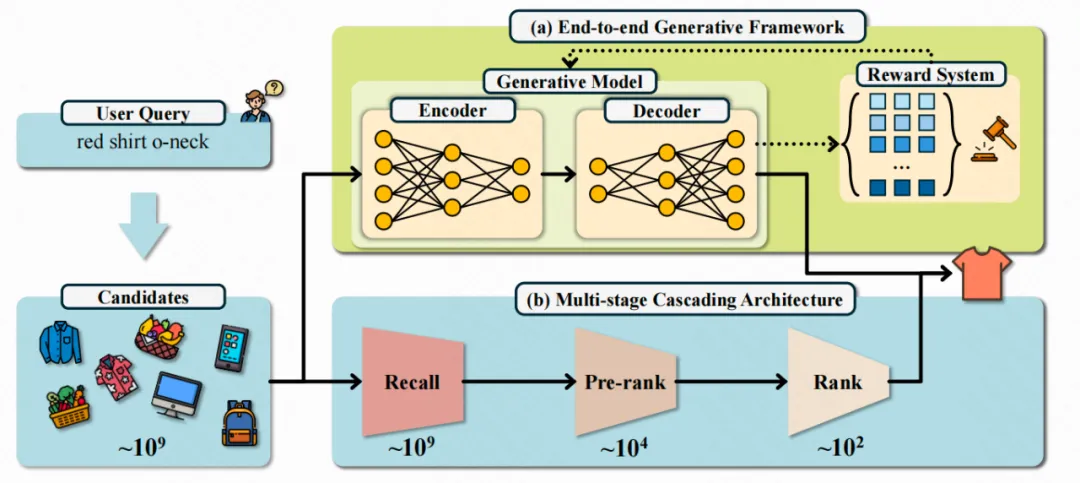
那么,到底是哪些环节导致我们总是看到不满意的商品?原因在于:
-
商品描述混乱:卖家为增加曝光,常在标题中堆砌大量不相关热词(如 “民族风复古流苏酒红色吊带连衣裙云南新疆西藏旅游度假长裙”),严重干扰系统判断。
-
相关性问题突出:用户搜索词往往很短(例如 “夏季阔腿裤”),但只要某一属性不匹配(如商品实际是 “裙裤” 款式),就不再相关,而系统难以精准捕捉这类差异。
-
级联结构存在瓶颈:级联式框架如同三道筛子,如果第一层召回效果差,后面再怎么排也难挽回。并且三层目标不一致,整体协同困难。
-
冷启动难题:新上架商品或搜索量极低的长尾词,因缺乏历史数据,很难被系统正确处理,导致曝光机会匮乏。
1、OneSearch:电商搜索端到端生成式框架
为解决传统电商搜索系统面临的诸多挑战,工业界通常采用级联式架构,以实现较高的商业效益和系统稳定性。然而,随着大语言模型的兴起,研究者开始探索如何借助其强大的语义理解与世界知识进一步优化搜索体验。
在此背景下,快手提出了业界首个工业级部署的电商搜索端到端生成式框架 ——OneSearch。

-
论文标题:《OneSearch: A Preliminary Exploration of the Unified End-to-End Generative Framework for E-commerce Search》
-
论文地址:https://arxiv.org/abs/2509.03236
该框架涵盖以下三大创新点:
1. 提出关键词增强层次量化编码(KHQE)模块,能够在保持层次化语义与商品独特属性的同时,强化 Query - 商品相关性约束;
2. 设计多视角用户行为序列注入策略,构建了行为驱动的用户标识(UID),并融合显式短期行为与隐式长期序列,全面而精准地建模用户偏好;
3. 引入偏好感知奖励系统(PARS),结合多阶段监督微调与自适应奖励强化学习机制,以捕捉细粒度用户偏好信号。
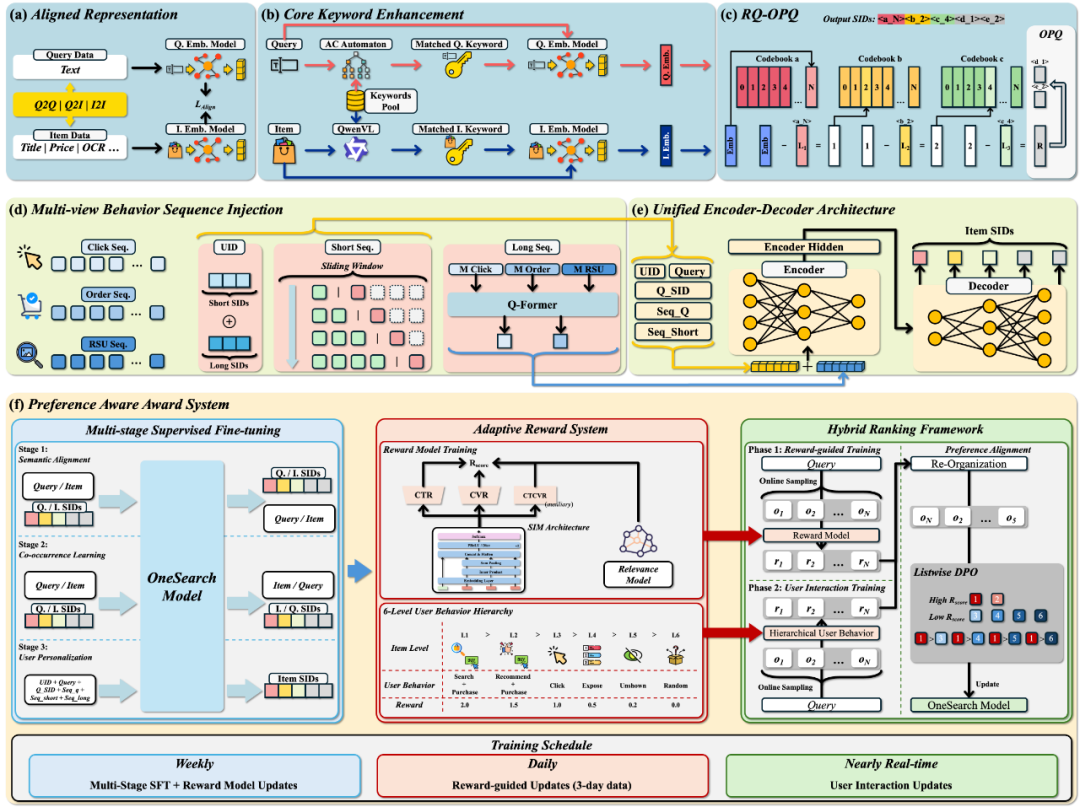
2、OneSearch 技术方案三大创新
2.1 关键词增强层次量化编码(KHQE)模块

商品语义涵盖标题、关键词、详情页、商家、价格、图片等多维度信息。然而,商家为提升曝光度,常在标题中堆砌大量关键词,导致出现多主体甚至属性冲突的问题,例如:“法式挂脖连衣裙女夏宽松显瘦绝美温柔初恋优雅皮靴搭配红色浅蓝色粉色”。此类混杂表述易掩盖商品的核心特征。
为实现多元化搜索意图下 query 与商品的精准匹配,首先必须对商品的丰富语义进行充分建模。快手团队设计了四个任务来对齐协同和语义表征:
1. Q2Q 和 I2I 对比损失:用于对齐协同相似对的表征;
2. Q2I 对比损失:增强 Query - 商品对的语义相关性,确保表征模型理解业务特性;
3. Q2I 边际损失:进一步学习具有不同行为级别(如曝光、点击、下单)的 < q, i > 对的协同信号偏差;
4. 基于 LLM 的难样本纠偏:保证难样本相关性水位。
第一步:提取核心属性
使用 Qwen-VL/AC 自动机分别识别出商品 /query 的关键属性(如品牌、品类、颜色、材质)。例如,从前述混乱标题中精准提取 “连衣裙”、“法式”、“挂脖”、“夏季” 等核心属性,弱化 “绝美”、“皮靴” 等无关或冲突词汇。
第二步:生成层次化编码(SID)
传统 SID 编码方法(如 RQ-VAE、RQ-Kmeans)倾向于编码商品间的共性特征,导致语义相近的商品被映射到相同编码中,无法充分保留个性化差异,从而制约生成式检索模型的性能。
为解决该问题,快手搜索技术团队提出 RQ-OPQ 编码方案,融合 RQ(残差量化)和 OPQ(优化乘积量化)的优势,从纵向与横向两个维度建模商品特征:
-
RQ:负责处理层次化语义特征,通过多层残差量化捕捉从粗粒度到细粒度的商品语义。
-
OPQ:负责量化独特特征,专门编码每个商品的差异化属性。
首先使用 RQ-Kmeans 进行 3 层层次化编码,构建商品的主体语义表示。可视为从粗到细的分类标签体系。例如:第一层为 “服装”,第二层为 “连衣裙”,第三层为 “法式款式”。经过聚类后所剩余的残差信息,包含商品最独特、最细粒度的属性。进一步对残差向量应用 OPQ 进行 2 层编码,以捕获商品的细微差异特征,如 “iPhone 17 Pro” 的 “星宇橙色”、“256GB 内存” 等关键属性。缺失此类信息将导致模型无法区分同类别商品的细微差别。
最终每个商品由 5 层 SID 组成:前 3 层来自 RQ 聚类中心,后 2 层来自 OPQ 量化结果。该结构相当于为每一个商品生成了一个具备丰富语义层次的 “智能身份证”,显著提升了生成式检索的区分能力和准确性。
2.2 多视角用户行为序列

传统搜索系统往往难以有效捕捉用户的近期偏好与长期兴趣。其核心原因在于传统排序模型中的用户 ID 仅为一串随机数字(如 “12345”),缺乏语义信息。而在 OneSearch 中,依据用户的长 / 短期行为序列构建具有区分性的用户标识(distinctive User ID)。例如,若用户近期频繁浏览露营装备,并长期表现出对高性价比商品的偏好,系统会为其生成一个精准描述这些行为的标识,而非无意义的编号。具体而言,采用有序加权方式基于用户的长 / 短期行为序列计算 distinctive User ID:
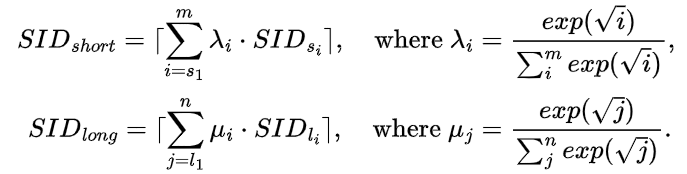
2.2.1 显式引入短行为序列
用户最近的搜索 Query 和点击商品可反映其即时意图。例如,若用户近期频繁搜索 “开学必备”、“宿舍神器”,系统可推断其可能为准大学生,进而在搜索结果页中围绕此进行展示。为实现这一目标,系统将用户最近的搜索 Query 序列和 SID 形式的点击商品序列直接编码至模型输入(prompt)中,以显式方式强调这些近期行为特征。同时,为缓解新用户行为稀疏性问题并模拟兴趣演化,采用滑动窗口策略进行数据增强。
2.2.2 隐式引入长行为序列
长期行为序列旨在从用户历史行为(如点击、购买等)中提炼稳定的偏好特征,形成整体用户画像。例如,用户长期购买高端电子产品和小众设计师品牌,可体现其消费层次和审美倾向。
在电商场景中,用户行为序列长度常高达~10³,无法以显式方式完整引入。考虑到 BART 等模型的最大输入长度限制(如 1024)以及长序列对线上推理延迟的影响,可通过嵌入(embedding)方式隐式融合用户个性化信息。与 OneRec 等方法直接对海量视频 ID 进行建模(嵌入维度达几十亿)不同,OneSearch 提出基于 SID 维度建模,具有以下优点:
-
embedding 维度低,仅几千维 emb 即可表征全量商品
-
SID 本身已经包含了类目、材质等层级化信息,无需引入额外特征
为进一步降低线上计算复杂度,对用户行为 SID 序列分层(L1/L2/L3)进行均值池化,并利用 QFormer 对序列表征进行压缩,最终得到一组(n, 768)维向量,即 n 个用户序列 token。消融实验表明,去除长期行为序列会导致离线性能显著下降,证明了隐式引入长序列的必要性。
该方法使系统能够更全面、深层地理解用户意图,显著提升了个性化搜索的准确性与用户体验。
2.3 引入偏好感知奖励系统(PARS)
当然,光能识别商品和理解用户还不够,最终得把所有匹配的商品排好顺序。
相比于推荐系统中的序列一致性,搜索中 query 和 item 之间的强相关性约束对生成式模型提出了更大的挑战。对于 GR 模型,不仅需要实现 SID 与 query/item 之间的语义对齐,还需要根据序列信息直接生成满足相关性约束和用户偏好的 item。因此,OneSearch 提出了一个偏好感知奖励系统,包括多阶段监督微调(SFT)和自适应奖励系统,以增强模型的个性化排序能力。
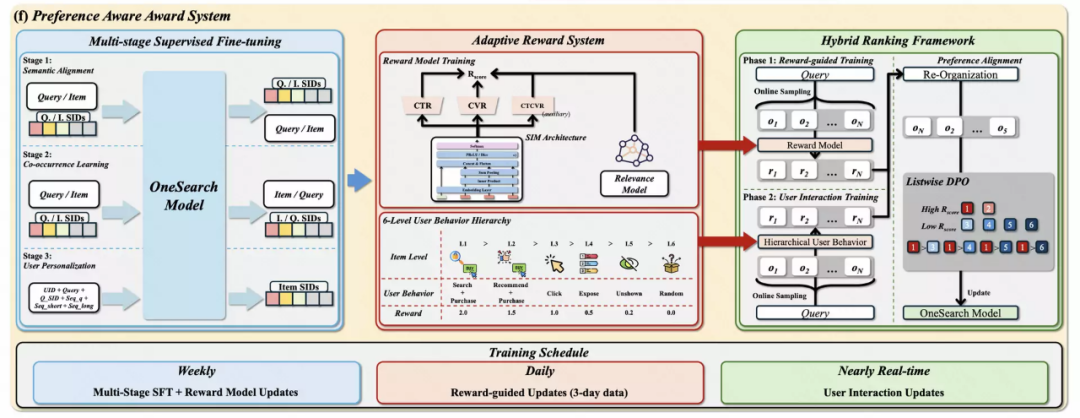
2.3.1 监督微调(SFT)阶段
用于搜索的生成式模型,需要同时准确把握〈query, item〉对的相关性以及用户的个性化偏好。OneSearch 创新性地设计了三阶段 SFT 训练任务:分别实现语义内容对齐、协同信息对齐、用户个性化建模。这就类似于 “上课” 的过程,从易到难,进行课程学习。
-
第一节课:认识 query/item 的 SID 与类目(比如 “薄款衬衫” 对应哪个 SID、哪一类目);
-
第二节课:学习 query 和 item 的共现关系(比如搜索了 “极简风” 的用户,常买哪些商品);
-
第三节课:结合用户的兴趣档案做练习(比如给 近期看露营 + 长期爱性价比 的用户,高优展示哪款类型帐篷)。

这一分阶段的学习策略有效提升了模型对相关性约束和用户偏好的联合建模能力。
2.3.2 强化排序学习(RL4Ranking)阶段
为了使生成式模型具备排序能力,一种直观的思路是借助强化学习,对用户有交互和无交互行为的区别学习。OneSearch 引入了一套自适应的奖励系统,首先通过 reward model 实现与线上精排模型的分布对齐,再结合用户真实交互行为进行监督训练,进一步激发生成式模型的推理能力。
样本自适应权重构建
电商搜索场景中用户意图多样,既包括强购买意图,也包含浏览、比价等弱意图行为。与视频推荐使用时长、次留等指标不同,电商搜索更关注 CTR、CVR、订单量与营收等直接转化指标。因此,如何对不同行为样本赋予合理的奖励权重,就显得非常重要。OneSearch 引入规则奖励机制(reward model),将用户行为划分为六个等级,并为每一类设置基础奖励值。在此基础上,进一步引入动态调节因子,基于商品近 7 天内的 CTR、CVR 等实时表现动态微调样本权重,缓解新品曝光不足带来的偏差。这种机制使得即使同为高等级样本(如两个成交商品),也会因历史转化效率的不同而在奖励权重上呈现细微差异,从而帮助模型捕捉更细粒度的用户偏好。
奖励模型(Reward Model)设计
为了对齐线上精排分布,OneSearch 首先设计了一个直观且高效的奖励模型。保持模型结构 & 损失函数与原精排一致、特征输入与 OneSearch 对齐,即用更少的特征拟合线上精排模型的分布,这样可以继承原有精排模型的稳定性。奖励模型训练好后,可以从线上日志中拉取用户真实搜索过的 query 等信息,使用 SFT 后的 OneSearch 模型生成候选 item 列表,再使用奖励模型进行进一步的排序;可以筛选出顺序发生变化的样本,这些差异样本反映了当前生成模型与线上精排在对用户偏好理解上的差距。利用这批数据进行监督训练,可有效增强模型的偏好学习能力。
用户交互引导,突破模型推理限制
在初步获得精排排序能力后,OneSearch 进一步引入用户真实交互数据监督训练,以激发生成模型的深层推理能力。训练中将以有点击、成交等正向反馈的样本作为正例,曝光未点击等作为负例,通过混合排序建模的方式,使模型在提升排序性能的同时,不损害生成多样性,避免 “奖励破解”(reward hacking)问题。
总结而言,OneSearch 的强化学习机制分为两步:首先通过奖励模型促使 OneSearch 拟合线上精排模型分布,学习基础的排序;再通过基于 Listwise DPO 进一步对齐用户偏好,突破排序性能的上限。
3、效果评测
离线实验效果
基于线上真实用户行为日志构建的离线测试集表明,OneSearch 提出的 RQ-OPQ 编码与自适应奖励系统相结合的方法效果最优,相比现有级联式系统(OnlineMCA),各项指标均有显著提升。
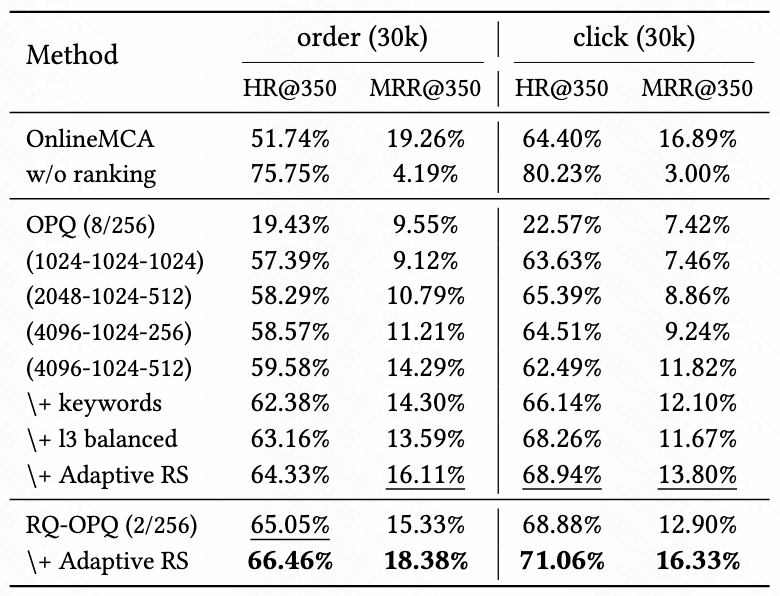
在线实验结果
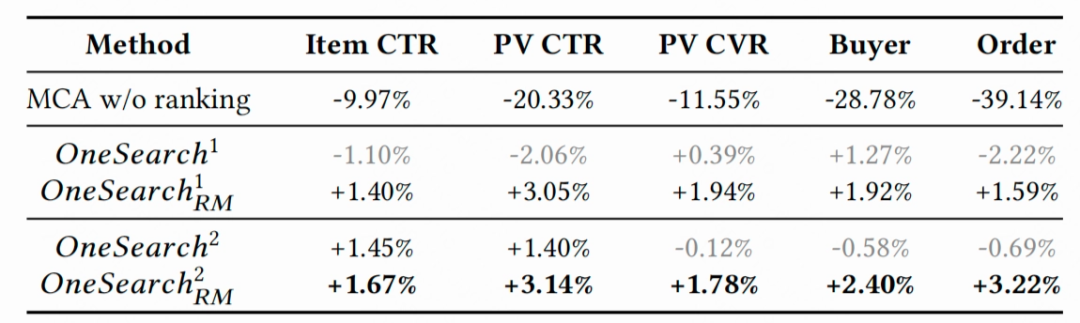
为了验证 RQ-OPQ 编码和用户序列引入的有效性,OneSearch 先后进行了两版实验,v1 版本仅使用 RQ 编码,取得了和线上级联式系统相近的效果;引入 RQ-OPQ 编码和用户序列建模后,v2 版本在 CTR 和 CVR 上有了显著的提升;额外地,在生成式模型的基础上进一步引入奖励系统,能获得转化指标的全面提升,最终版本订单量提升 3.22%,买家数提升 2.4%。
该实验验证了 OneSearch 模型在真实电商环境中的有效性。这是在大规模工业场景下,生成式模型第一次取代搜索全链路的可落地方案。目前该系统已在快手的多个电商搜索场景中成功部署,每日服务数百万用户,产生数千万 PV。
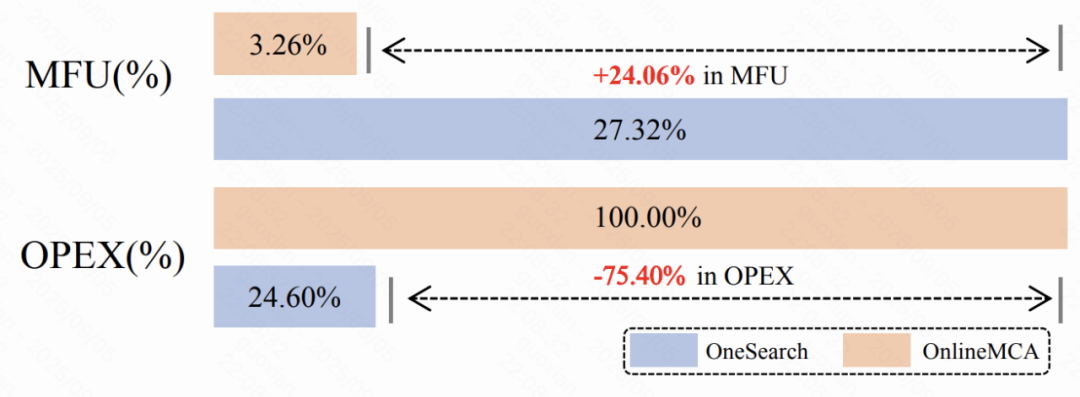
人工评测与在线性能
在人工评测中,OneSearch 系列模型不仅在 CVR 和 CTR 上表现优异,同时在页面整体满意度、商品质量及 query-item 相关性方面均显著优于线上级联式系统。此外,在线性能方面,机器计算效率(MFU)提升显著,从 3.26% 提高到 24.06%,相对提升达 8 倍;线上推理成本(OPEX)降低 75.40%,资源利用效率显著优化。

泛化性和场景分析
OneSearch 在绝大多数行业类别中均带来 CTR 的稳定提升,展现出良好的泛化能力。按 Query 频次、商品冷启动及用户层级下探表明,OneSearch 在高、中、低频 query 上均实现了 CTR 提升,尤其在中长尾 query 上的改善更为显著。此外,该系统在冷启动(cold-start)场景下表现尤为突出,效果显著优于常规(warm)场景,说明生成式检索模型能够更有效地应对长尾用户和新上架商品的排序挑战。


4、始终追踪技术前沿
快手搜索技术部作为公司的核心算法研发部门,始终站在大数据与人工智能技术发展的前沿,致力于将大模型(LLM)技术与海量数据深度融合,打造行业领先的智能搜索平台,持续推动用户体验与技术能力的协同进化。部门业务覆盖视频搜索、电商搜索与 AI 搜索等多个核心方向,聚焦于构建精准、高效、智能的新一代搜索系统。
其中,OneSearch 所属的电商搜索团队以实际业务需求为驱动,坚持 “技术‑业务” 双轮迭代机制,多项技术突破已发表在 RecSys、CIKM、KDD、EMNLP、AAAI、ACM MM 等国际顶级会议上,多次引起业界广泛关注。面向未来,团队将持续深耕多模态理解、生成式搜索与 AI 搜索等关键方向,致力于实现更智能、更流畅、更人性化的搜索交互体验,以技术驱动业务创新,不断攀登智能搜索的新高峰。
5、未来展望
在后续研究中,快手电商搜索团队将致力于探索在线实时编码方案,缩小预定义编码与流式训练之间的差异。此外,还将引入更强大的强化学习机制以更精准地匹配用户偏好,并结合图像、视频等多模态商品特征,进一步提升模型的推理效果与用户体验。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com