SFT与RL训练别再分开!本文解析大模型六大融合范式,突破传统瓶颈,实现高效统一,赋能LLM更强推理。
原文标题:别再分开训!SFT+RL融合范式全解析:统一视角下的六大方法
原文作者:数据派THU
冷月清谈:
这些策略包括:交替进行SFT和RL,利用SFT数据作为RL中的Off-Policy样本进行重要性采样修正,同时进行SFT和On/Off-Policy RL训练,以及将SFT用作对RL的引导提示(hint)。这些方法通过统一损失函数或巧妙设计训练流程,有效平衡了SFT提供的基础能力与RL带来的泛化探索,从而提升模型解决中低难度问题的能力,并增强其对复杂推理的鲁棒性,最终实现大模型更高效、稳定的性能提升。
怜星夜思:
2、文章里提到了SFT和RL的融合,但没怎么深入讲奖励模型(Reward Model)。在咱们这种融合范式里,奖励模型的设计是不是会变得更复杂或更关键?有没有啥特别的注意事项和常见的挑战?
3、咱们训练大模型,除了提升能力,很重要的还有“对齐人类价值观”和“减少有害输出”。这些SFT和RL融合的策略,是更利于模型对齐,还是说在融合过程中可能会引入新的对齐挑战,需要我们更小心地去平衡?
原文内容

来源:PaperWeekly本文约2800字,建议阅读5分钟
本文介绍 SFT 与 RL 融合必要性,及交替、样本复用、同时训练、hint 引导等融合方法。
本文介绍 SFT 与 RL 融合必要性,及交替、样本复用、同时训练、hint 引导等融合方法。
1、为什么要融合SFT和RL
RL 虽然能够有效提升模型的推理能力,但一个重要的前提是基础模型本身具备了一定的相关能力。在 RL 训练中,通过多次 rollout 能够采样到正确的轨迹,这样通过 RL 才能进一步提升。这无疑限制了 RL 的探索空间。
因此,主流的方式是通过 SFT 赋予模型一些基础能力,然后在进一步利用 RL 来提升相关能力。但是一些研究认为两阶段的方式并不是最优的:
-
[1] 通过实验发现,RL 能改善中低难度问题的解决能力,SFT 则对高难度问题更有效;
-
[4] 则认为更大模型(或者专家)构造的 SFT 包含跳跃逻辑,通过 SFT 难以完全模仿这些逻辑,导致进行 RL 时难以 rollout 出有效的正样本;
-
[3] 和 [5] 则直接认为两个独立的阶段本身没有必要存在,应该统一;
-
[6] 进一步分析,发现 SFT 和 RL 之间存在着某种对抗,SFT 使模型大幅度偏离基础模型,而 RL 又会将其拉回基础模型;
综上,这些研究均认为有必要将 SFT 和 RL 融合为单一阶段。
2、基础知识
在标准的 LLM 训练流程中,通常包含三个阶段:Pre-training、SFT 和 RL。Pre-training 阶段采用自回归的方式在海量数据上完成预训练,为后续的 Post-training 奠定基础。Post-training 通常分为 SFT 和 RL,这两个阶段均需要一个多样性丰富的 prompt 集合 。
2.1 SFT
在该阶段对于 prompt ,会采用专家撰写、人工合成或者强模型蒸馏的方法来构造高质量的响应 。这里不妨假设 ,其中 代表人类专家或者更强的模型等。那么,SFT 训练的损失函数为:
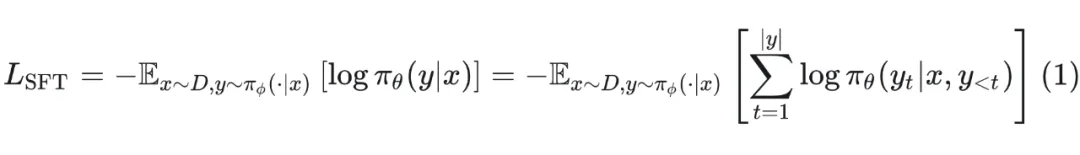
该损失函数的梯度表示为:
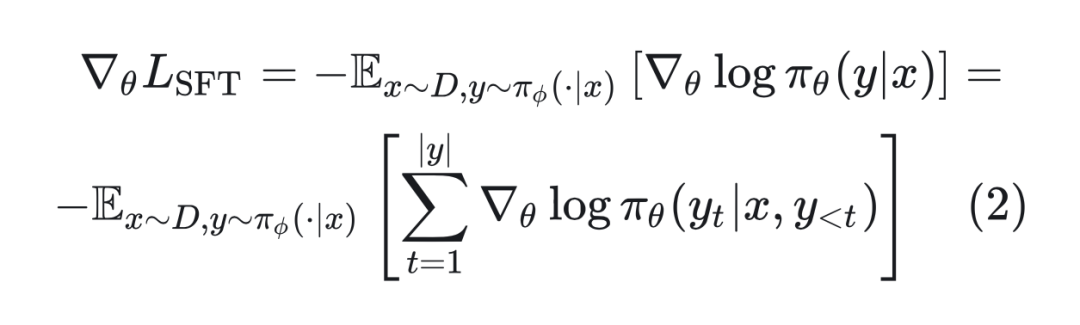
2.2 RL
RL 通常在 SFT 阶段后进行。在 On-Policy 的设定下,对于 promt ,通常会从当前策略 中采样响应 。RL 的损失函数为:
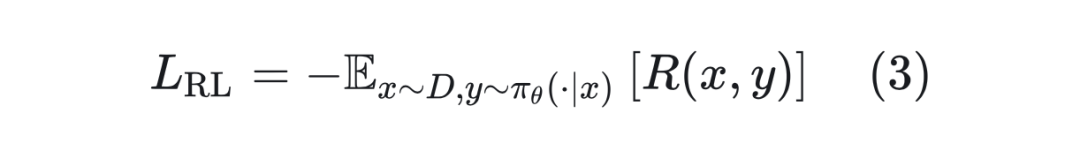
该损失函数的策略梯度为:
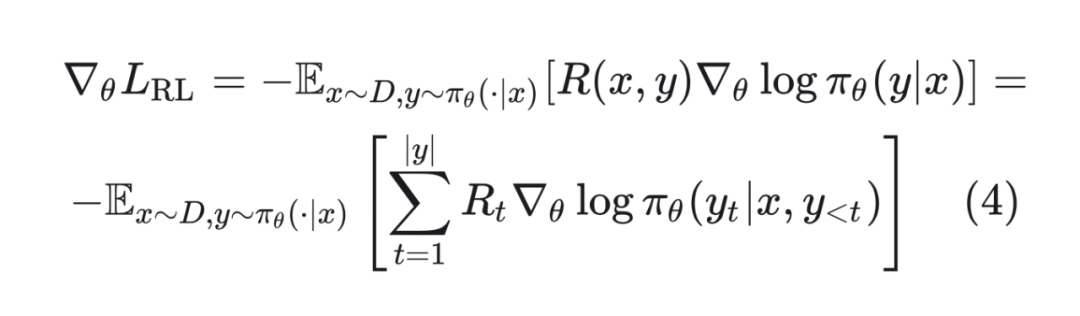
其中, 是针对 的奖励。公式(4)是标准 REINFORCE 的梯度,在实际中通常为了降低方差会采用带基线的 REINFORCE。
带基线的 REINFORCE 本质上是用优势函数来代替奖励,相比于奖励的直接含义,优势函数代表相对于平均状况的改善程度。因此,带基线的 REINFORCE 的梯度为:
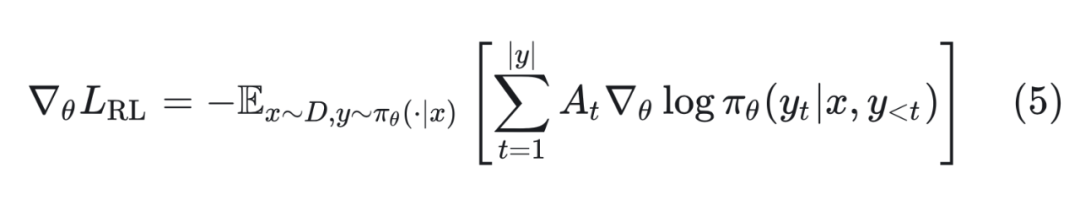
其中, 是 的优势。
2.2.1 GRPO
到目前为止,GRPO 已经近乎于 LLM 后训练中 RL 算法的事实标准了。GRPO 是 PPO 的一种无 critic 模型的变种,针对同一个 promt ,会同时采样 个响应 ,每个响应 对应于一个标量奖励 。
在标准的 PPO 中需要 critic 模型来辅助计算优势,GRPO 则采用组内标准化实现优势的近似计算:
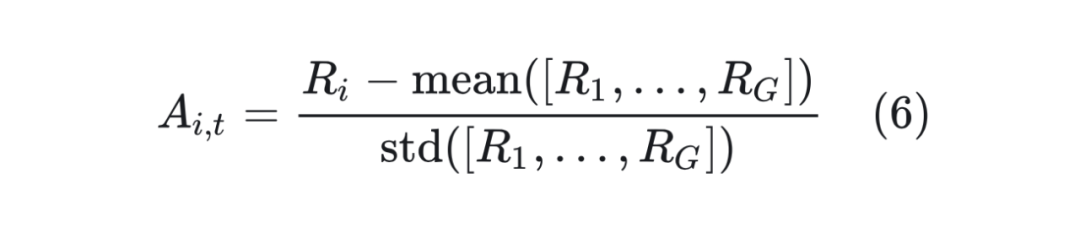
这里 是指第 个响应的第 个 token 的优势。除了优势的计算外,损失函数与 PPO 类似:

其中 是重要性采样。
3、交替进行SFT和RL
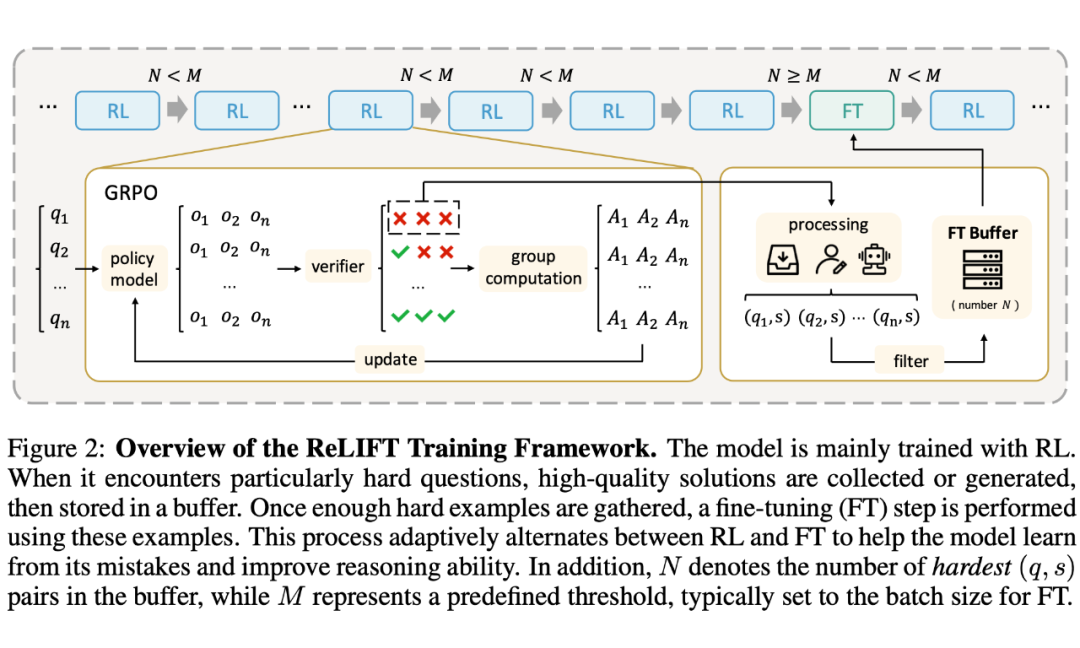
ReLIFT [1] 认为 RL 改善中低难度问题,SFT 改善高难度问题。因此,设计了一种交替方案。具体来说,在 RL 过程中将 rollout 过程中完全错误的样本放入缓冲池。当缓冲池满时,利用这些样本进行 SFT。
4、将SFT用作RL中的Off-Policy样本
相比于交替进行 SFT 和 RL,LUFFY [2] 则将 SFT 用作 Off-Policy 样本,然后通过重要性采样将其统一在 RL 过程中。显然,这样的方式更自然一些。
4.1 符号
表示直接使用策略进行 rollout 得到的 Non 条轨迹。
则是 条 SFT 数据。
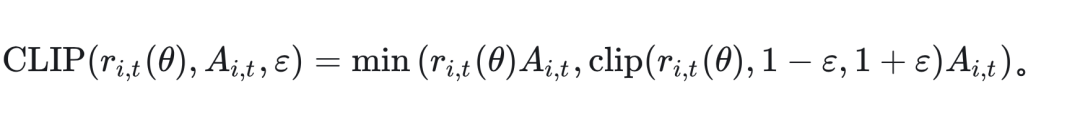
4.2 混合On和Off的样本
最简单的方式是直接将 Off-Policy 的样本混合到 On-Policy 数据中进行训练,那么损失函数可以写为:
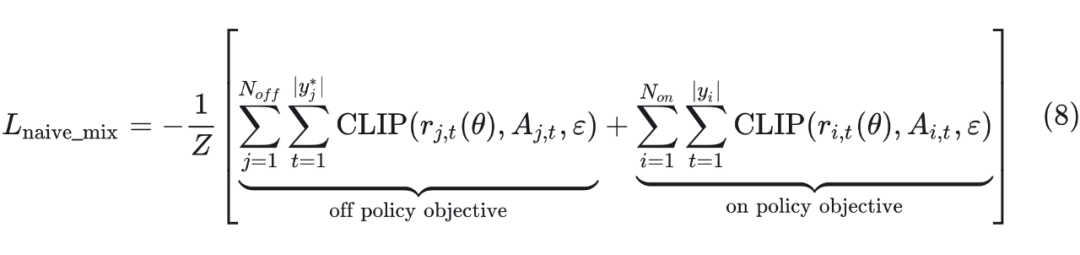
其中 是归一化因子。
但是上式中的 off policy objective 中的重要性采样 如果仍然使用 并不合适,因为分母中的 并不是产生 off policy 数据 的分布。因此,第一项应该采用新的重要性采样:
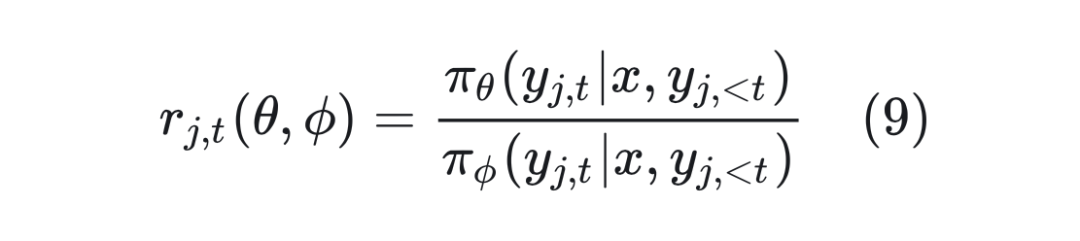
将新的重要性采样系数(9)替换公式(8)就得到了最终的混合损失函数:
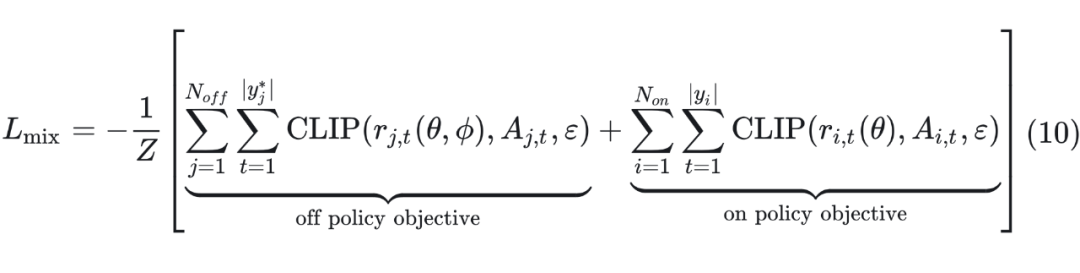
4.3 重要性采样修正
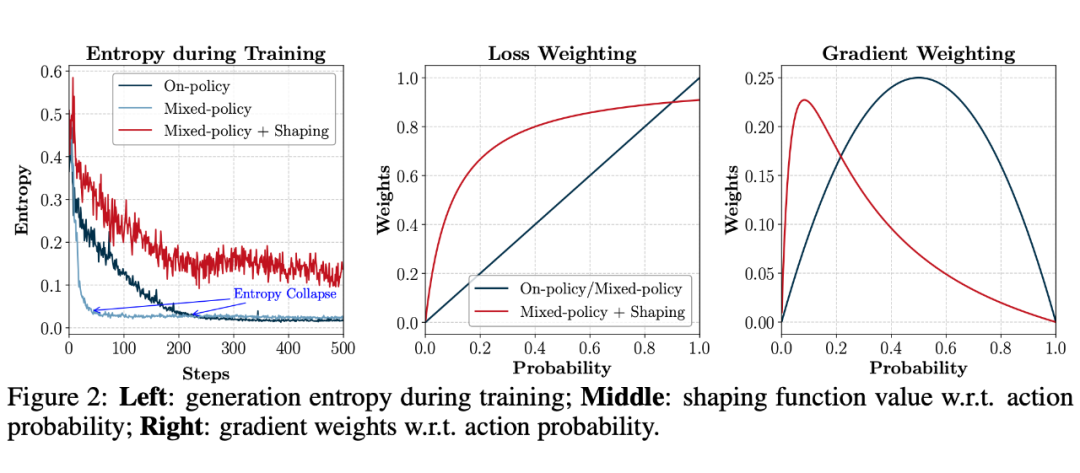
依照公式(10)进行训练,虽然解决了梯度偏差的问题。但是,训练中发现其加速收敛的同时,也显著抑制了探索,导致快速的熵坍缩,如上图左所示。
进一步的分析认为,当模型同时接收 On 和 Off 的信号时,其倾向于优先加强那些既存在于 On-Policy 轨迹中,也存在于 Off-Policy 轨迹中的概率较高 token。
那些来自于 Off-Policy 轨迹中的低概率 token,对于推理至关重要,但是由于 太小导致学习信号微弱。
因此,[2] 提出利用一个修正函数 来调整重要性采样 ,即使用 替换公式(10)中的 。
为什么能放大 Off-Policy 轨迹中的低概率 token?
对于 Off-Policy 部分的损失函数针对 的梯度可以表示为
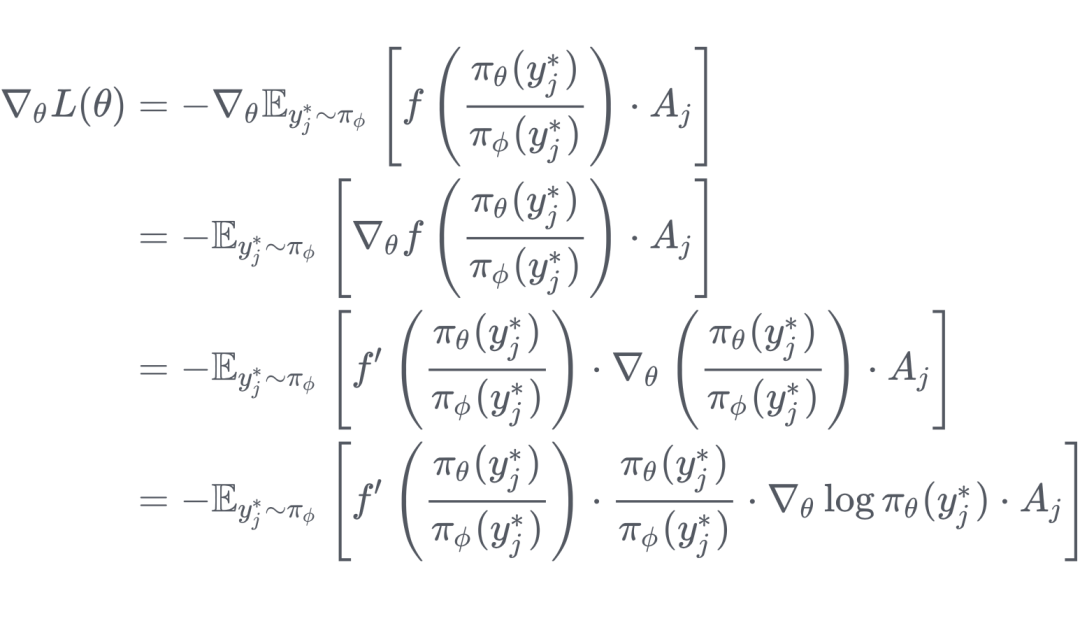
观察上式可以发现新损失函数相当于在原始策略梯度的基础上添加了一个权重因子 。为了简化分析,可以合理假设离策略对其生成样本的置信度为 1,即 。那么权重因子进一步简化为 。由于 ,当 时, ,相当于放大梯度。反之,当 时, ,这是一个非常小的数,相当于缩小梯度。
5、同时进行SFT和RL
相较于 LUFFY [2] 通过将 SFT 视为 Off-Policy 样本,从而统一至 RL。SRFT [6] 则进一步采用了偏向于实践的风格,即同时采用 SFT 和 RL 损失。
SFT 损失函数。标准的 SFT 损失函数为如公式(1)所示,但是若一个样本的熵太高,则表明该样本对当前模型来说比较陌生。应该降低 SFT 损失的比例,因此采用带有权重的 SFT 损失函数:
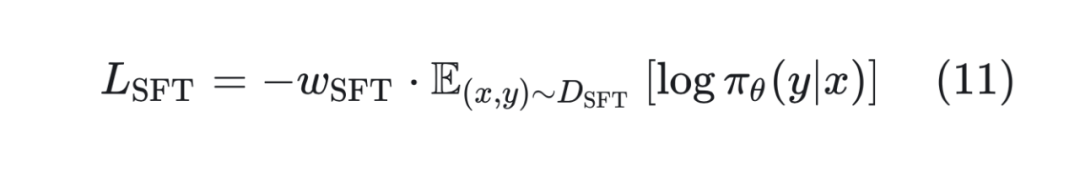
其中 。
Off-Policy RL 损失函数。类似于 LUFFY,将 SFT 视为 Off-Policy 样本:
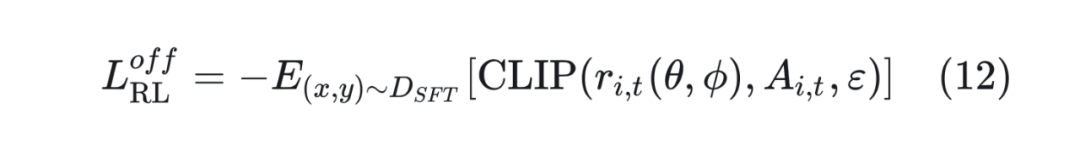
其中 同 LUFFY 的公式(9)。
On-Policy RL 损失函数。在二元奖励 {+1, -1} 设定下,标准的 On-Policy RL 损失函数为:
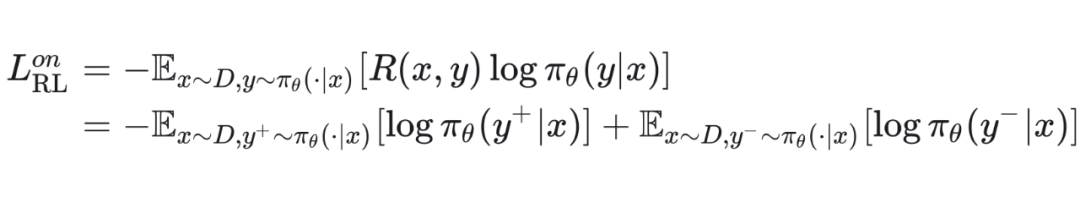
但是,SRFT 为了缓解熵坍缩,对正样本部分的损失添加了一个基于熵的权重:
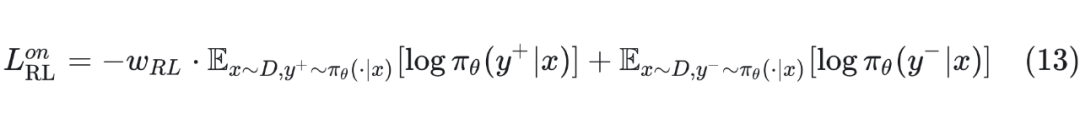
其中 。当熵较大时,意味着模型对这个样本不太确定,较大的 强制模型更多的学习该样本。
最终的损失函数。将公式(11)、(12)和(13)求和得到最终的损失函数:
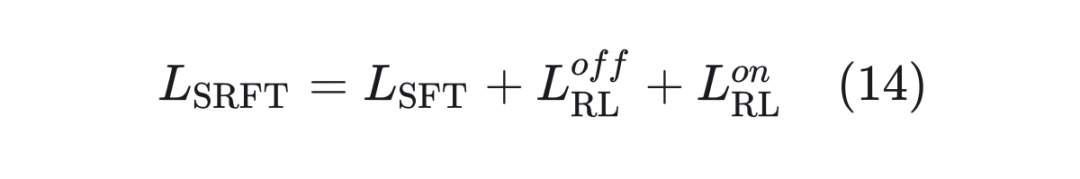
因此,该方法同时进行 SFT、Off-Policy RL 和 On-Policy RL。
6、将SFT用作hint
hint 是指问题和部分正确答案的拼接。标准 RL 的主要问题是针对难问题无法 rollout 出正样本。SFT 作为天然正样本,可以将其一部分响应与问题进行拼接,从而构造出一个 hint。策略基于 hint 进行 rollout,而不是原始的 prompt。
基于 hint 的方法主要围绕两个问题:a. 如何构造合适的 hint?b. hint 部分在训练中怎么处理?
6.1 如果构造合适的 hint
动态调整 hint 的长度。[3] 和 [5] 采用了动态调整 hint 长度的方式,从而构造出难度循序渐进的 hint。这种方式即能调整难度,也能缓解训推不一致的问题。假设一条 SFT 样本的完整长度为 ,[3] 使用余弦退火的方式动态调整 hint 的占比系数 。但不直接使用 作为 hint 的长度,而是将 视为试验数, 作为成功概率的二项分布,然后基于该分布采样 hint 长度 。[5] 则是从动态区间 中进行采样,其中上界 high 是固定的,下界 low 则是通过余弦函数从 high 一直衰减到 0。这样,模型能够从刚开始基于较多提示才能回答对问题,逐步能够独立回答对问题。
基于 rollout 的结果调整 hint。[4] 提出二分搜索的方式寻找合适的 hint。具体来说,分如下情况:
-
若基于当前的 hint 进行 rollout,所有 rollout 均失败,则加长 hint;
-
若基于当前的 hint 进行 rollout,所有 rollout 均成功,则缩短 hint;
-
介于二者之间则认为是难度适宜的 hint。
6.2 训练方式
标准 RL 训练方式。[4] 和 [5] 均是将基于 hint 得到的 rollout 当做普通 rollout,采用标准 RL 进行训练。相比于 [4] 仅使用基于 hint 的 rollout,[5] 则会将标准 rollout 和基于 hint 的 rollout 混合在一起进行训练。此外,[5] 认为 hint 部分直接加入到强化学习中,会强制模型学习概率降低的 token,产生巨大梯度,从而导致训练不稳定。因此,需要对来自于 SFT 部分的 token 进行筛选,仅保留熵最高的 top-k% 个 token 的梯度。
结合 SFT 和 RL 训练方式。[3] 对于 hint 部分和 rollout 部分采用了不同的损失函数。对于 hint 部分使用 SFT 损失函数,对于 rollout 部分使用 RL 损失函数。具体来说,在 GRPO 的设定下,每个 prompt 会产生 个 response ,每个 的前 部分属于 hint。那么,损失函数为:
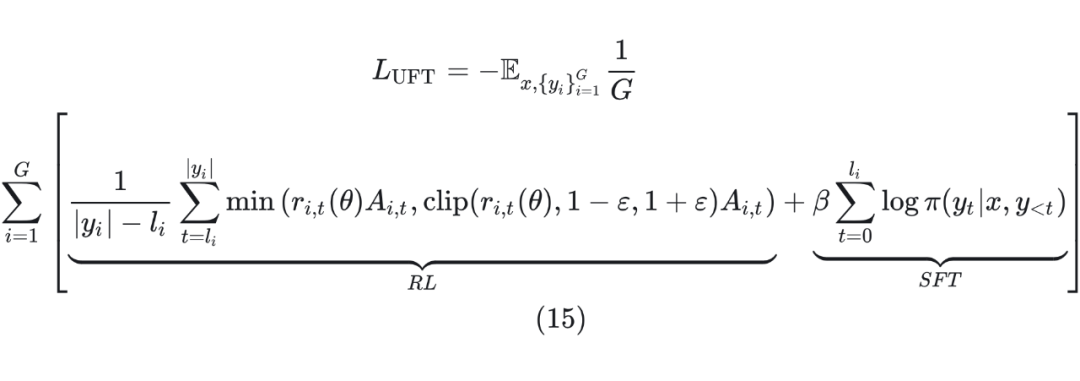
参考文献
[1] Learning What Reinforcement Learning Can't: Interleaved Online Fine-Tuning for Hardest Questions
https://arxiv.org/pdf/2506.07527
[2] Learning to Reason under Off-Policy Guidance
https://arxiv.org/pdf/2504.14945
[3] UFT: Unifying Supervised and Reinforcement Fine-Tuning
https://arxiv.org/pdf/2505.16984
[4] BREAD: Branched Rollouts from Expert Anchors Bridge SFT & RL for Reasoning
https://arxiv.org/pdf/2506.17211
[5] Blending Supervised and Reinforcement Fine-Tuning with Prefix Sampling
https://arxiv.org/pdf/2507.01679
[6] SRFT: A Single-Stage Method with Supervised and Reinforcement Fine-Tuning for Reasoning
https://arxiv.org/pdf/2506.19767
