快手可灵MIDAS框架实现实时多模态数字人生成,延迟低于500ms,为交互带来突破。
原文标题:快手可灵团队提出MIDAS:压缩比64倍、延迟低于500ms,多模态互动数字人框架实现交互生成新突破
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到MIDAS把延迟降到了500ms以内,这在实际使用中对用户体验到底有多大的提升?或者说,这个500ms的门槛,对于实时交互来说意味着什么?
3、数字人技术发展这么快,以后会不会有那种几乎看不出是AI的数字分身出现?如果真的到了那一天,大家觉得对社会、对个人隐私会有哪些影响或挑战呢?
原文内容

数字人视频生成技术正迅速成为增强人机交互体验的核心手段之一。然而,现有方法在实现低延迟、多模态控制与长时序一致性方面仍存在显著挑战。大多数系统要么计算开销巨大,无法实时响应,要么只能处理单一模态输入,缺乏真正的交互能力。
为了解决这些问题,快手可灵团队(Kling Team) 提出了一种名为 MIDAS(Multimodal Interactive Digital-human Synthesis)的新型框架,通过自回归视频生成结合轻量化扩散去噪头,实现了多模态条件下实时、流畅的数字人视频合成。该系统具备三大核心优势:
-
64× 高压缩比自编码器,将每帧压缩至最多 60 个 token,大幅降低计算负荷;
-
低于 500ms 端到端生成延迟,支持实时流式交互;
-
4 步扩散去噪,在效率与视觉质量间取得最佳平衡。
该项研究已被广泛实验验证,在多语言对话、歌唱合成甚至交互式世界建模等任务中表现出色,为数字人实时交互提供了全新解决方案。

-
论文标题:MIDAS: Multimodal Interactive Digital-humAn Synthesis via Real-time Autoregressive Video Generation
-
论文地址:https://arxiv.org/pdf/2508.19320
-
主页地址:https://chenmingthu.github.io/milm/
核心创新
1. 多模态指令控制机制
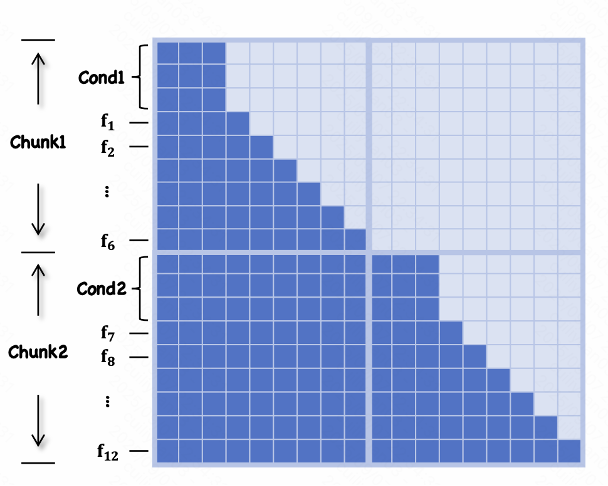
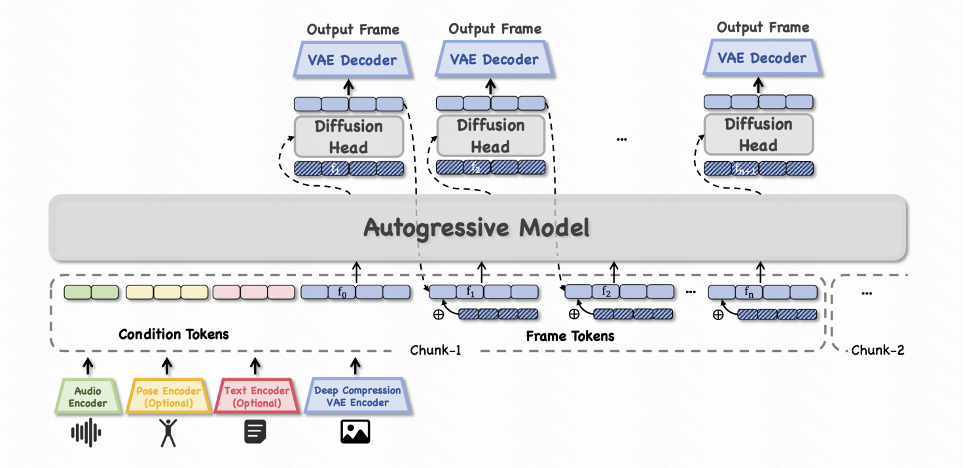
MIDAS 支持从音频、姿态到文本等多种输入信号。通过一个统一的多模态条件投影器,将不同模态编码到共享潜在空间,形成全局指令令牌,构建 frame-by-frame 的 chunk 注入,引导自回归模型生成语义和空间一致的数字人动作与表情。
2. 因果潜在预测 + 扩散渲染
模型可嵌套任意类似大语言模型的自回归架构,逐帧预测潜在表示,再由一个轻量级扩散头进行去噪和高清渲染。这种设计既保证了生成的连贯性,也大幅降低了计算延迟,适合实时流式生成。
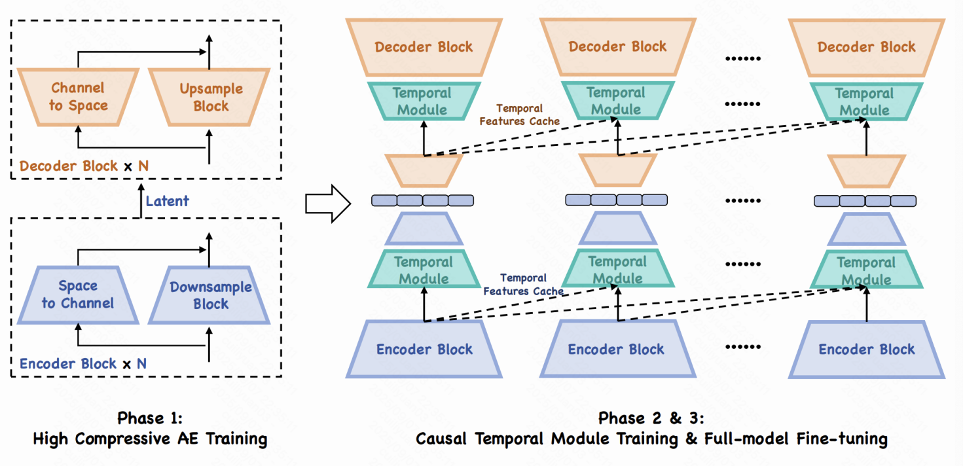
3. 高压缩率自编码器(DC-AE)
为实现高效的自回归建模,团队设计了压缩比高达 64 倍的 DC-AE,将每帧图像表示为最多 60 个令牌,支持分辨率最高达 384×640 的图像重建,并引入因果时序卷积与 RoPE 注意力机制保障时序一致性。
4. 大规模多模态对话数据集
为训练模型,研究者构建了一个约 2 万小时的大规模对话数据集,涵盖单人、双人对话场景,涵盖多语言、多风格内容,为模型提供了丰富的语境与交互样本。
方法概要
-
模型架构:采用 Qwen2.5-3B 作为自回归主干网络,扩散头基于 PixArt-α /mlp 结构。
-
训练策略:引入可控噪声注入,通过 20 级噪声桶和对应嵌入,缓解自回归模型在推理阶段的曝光偏差问题。
-
推理机制:支持分块流式生成,每块 6 帧,可实现 480ms 级别的低延迟响应。
效果展示
1. 双人对话生成
系统可实时处理双人对话音频流,生成与语音同步的口型、表情和倾听姿态,支持自然轮流对话:
双工对话示例
2. 跨语言歌唱合成
在没有显式语言标识的情况下,模型精准实现中文、日文、英文歌曲的唇形同步,生成视频可达 4 分钟无显著漂移:
多语言歌唱合成效果
3. 通用交互世界模型
通过在 Minecraft 数据集上训练,MIDAS 可响应方向控制信号,展现出良好的场景一致性与记忆能力,验证了其作为交互式世界模型的潜力:
Minecraft 环境下的交互生成示例
总结
MIDAS 在双边对话、多语言生成等任务中,MIDAS 均实现实时生成(<500ms 延迟), 并且扩散头仅需 4 步去噪,在效率与质量间取得最佳平衡,支持长达几分钟的连续生成,且质量衰减显著低于基线方法。
MIDAS 不仅为实时数字人生成提供了端到端的解决方案,更探索了多模态自回归模型在交互式媒体生成中的潜力。其模块化设计允许灵活扩展至更多模态与控制信号,为虚拟人直播、元宇宙交互、多模态 AI 智能体等应用奠定了技术基础。
团队表示,未来将进一步探索更高分辨率、更复杂交互逻辑下的生成能力,并推进系统在真实产品环境中的部署。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com