Meta开源MobileLLM-R1,不到1B参数,用1/10训练数据量,在数学编程等领域性能超越竞品,小模型部署潜力巨大。
原文标题:Meta开源MobileLLM-R1模型,不到1B参数,用1/10的训练就超越了Qwen3
原文作者:机器之心
冷月清谈:
MobileLLM-R1 与现有全开源模型相比,性能提升显著。最引人注目的是,它仅使用了约2T高质量token进行预训练,总训练token量少于5T,但在MATH、GSM8K、MMLU和LiveCodeBench等基准测试中,其性能与使用36T token训练的Qwen3 0.6B相当或更优。特别是在MATH基准测试上,MobileLLM-R1 950M的准确率比Olmo 1.24B高出约五倍,比SmolLM2 1.7B高出约两倍,并在编码测试中刷新了完全开源模型的最高水平。
这些模型并非通用聊天模型,而是监督微调 (SFT) 模型,专门针对数学、编程(Python、C++)和科学问题进行训练。 Meta不仅开源了模型本身,还发布了完整的训练方案和数据源,以确保可重复性和促进后续研究。
此次发布在机器学习社区引发热议,因为它证明了小体量模型在特定领域内也能实现极高的效率和性能。这意味着训练成本更低廉,便于快速尝试最新技术;更重要的是,模型体量的下降使其能够适配更多的端侧设备,推动AI在更广阔的应用场景落地。 该项目由三位华人研究科学家Zechun Liu、Ernie Chang和Changsheng Zhao领衔研发。
怜星夜思:
2、文章里说MobileLLM-R1只用了不到5T的训练token,就实现了这么好的效果,尤其对比竞品训练数据量小很多。大家觉得**这种“少而精”的训练方式,到底是不是未来小模型的主流方向?** 是因为数据筛选更严格,还是模型架构有特别优化?
3、MobileLLM-R1是SFT模型,专门针对数学、编程这些领域优化。这听起来很专业,但如果它不是通用聊天模型,大家觉得**这种“专精型”AI,在哪些方面会有优势,又会在哪些方面遇到瓶颈呢?** 会不会以后每个领域都搞一个这样的专用AI?
原文内容
编辑:泽南、杨文
与其他全开源模型相比,性能提升2-5倍。
小参数模型也进入了 R1 时代,这次开源出新技术的是 Meta。
本周五,Meta AI 团队正式发布了 MobileLLM-R1。
-
HuggingFace 链接:https://huggingface.co/collections/facebook/mobilellm-r1-68c4597b104fac45f28f448e
-
试用链接:https://huggingface.co/spaces/akhaliq/MobileLLM-R1-950M
这是 MobileLLM 的全新高效推理模型系列,包含两类模型:基础模型 MobileLLM-R1-140M-base、MobileLLM-R1-360M-base、MobileLLM-R1-950M-base 和它们相应的最终模型版。
它们不是通用的聊天模型,而是监督微调 (SFT) 模型,专门针对数学、编程(Python、C++)和科学问题进行训练。
除了模型本身之外,Meta 还发布了完整的训练方案和数据源,以确保可重复性并支持进一步的研究。
值得注意的是,该系列参数最大的 MobileLLM-R1 950M 模型仅使用约 2T 高质量 token 进行预训练,总训练 token 量少于 5T,但在 MATH、GSM8K、MMLU 和 LiveCodeBench 基准测试中,其性能与使用 36T token 进行训练的 Qwen3 0.6B 相当或更佳。
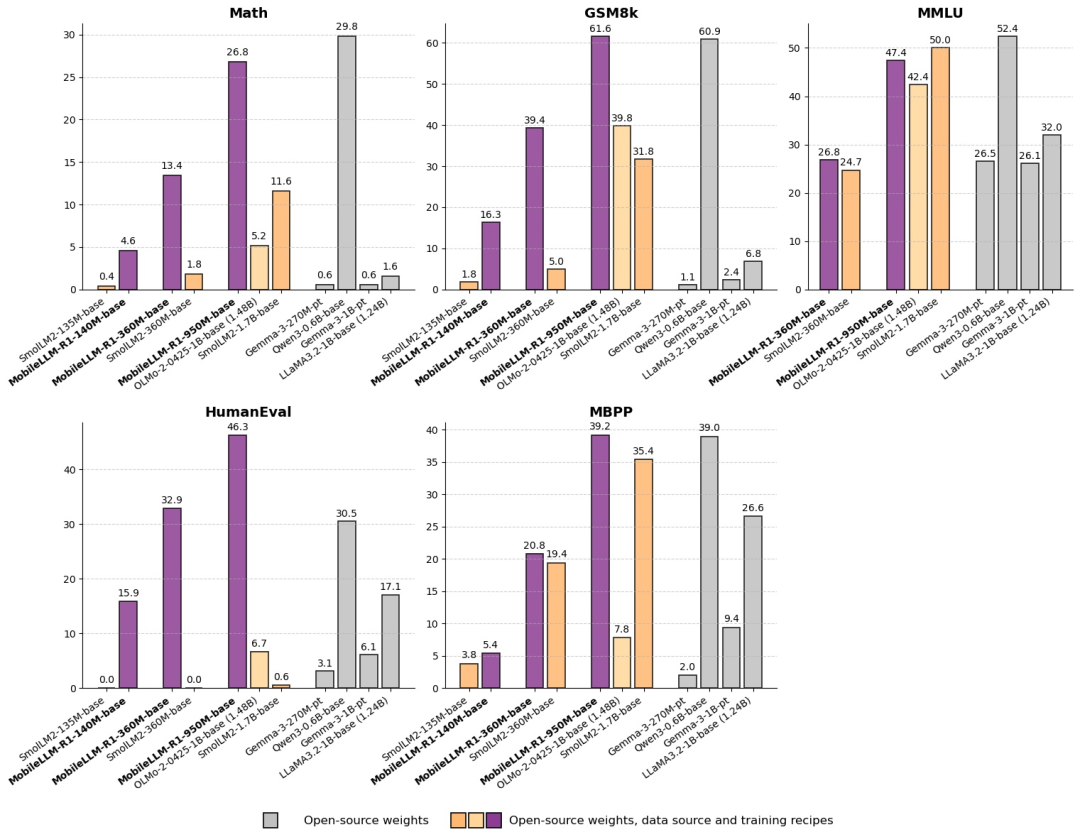
与现有的完全开源模型相比,尽管参数规模明显更小,MobileLLM-R1 950M 模型在 MATH 基准上的准确率也比 Olmo 1.24B 模型高出约五倍,比 SmolLM2 1.7B 模型高出约两倍。此外,MobileLLM-R1 950M 在编码基准测试中的表现远超 Olmo 1.24B 和 SmolLM2 1.7B ,在完全开源模型中创下了新的最高水平。
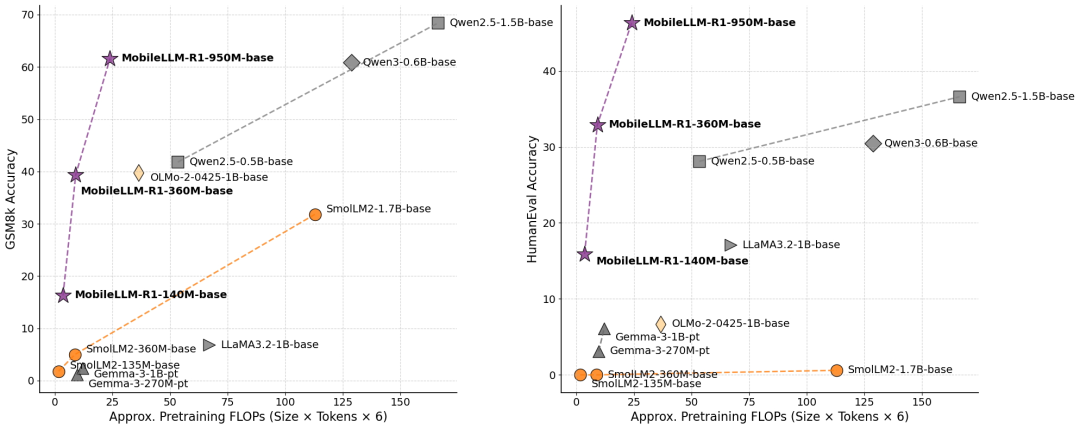
Token 效率的比较如下:
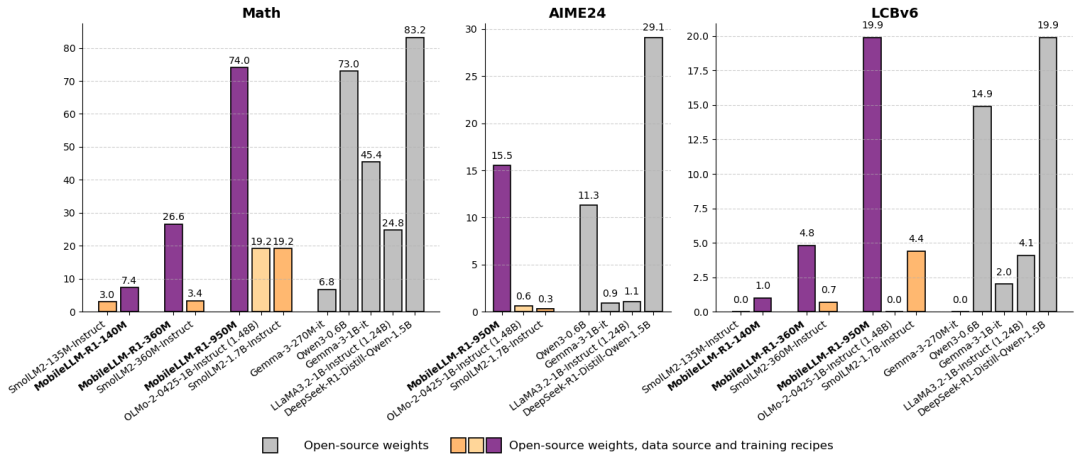
后训练比较:
模型架构:

MobileLLM-R1 的发布引起了机器学习社区的讨论。人们欢迎通义、Meta 等顶尖大模型团队基于小体量模型的探索。这一方向的训练成本较为低廉,可以更加方便尝试各类最新论文提出的技术,更重要的是,模型体量的下降也意味着它可以覆盖更多端侧设备,实现更大面积的落地。
随着训练成本普遍下降,我们将会得到更好的模型。
背后三位华人作者
在 MobileLLM-R1 系列发布的同时,背后的作者们也正式亮相,他们表示,该工作的研发时间有一年之久。该项目由华人领衔。
Zechun Liu

Zechun Liu 是 Meta AI 的研究科学家,专注于大模型和基础模型的高效部署与优化。
她的研究涉及大语言模型的预训练与后训练,神经网络架构设计与搜索,量化、剪枝与稀疏性,知识蒸馏以及高效的视觉 - 语言模型等,目标是在计算资源有限的环境中实现高性能模型的推理和部署。
2016 年,她在复旦大学获得本科学位,2019 年至 2021 年在卡内基梅隆大学担任访问学者,导师为 Marios Savvides 教授和 Eric Xing(邢波)教授。2021 年 6 月获得香港科技大学的博士学位,师从 Kwang-Ting Tim CHENG 教授。
Zechun Liu 在顶级会议和期刊上发表了 20 多篇论文,其论文引用量达到了数千次。
Ernie Chang
Ernie Chang 是 Meta AI 的研究科学家,专注于自然语言处理、多模态学习和高效模型部署等领域。

他于 2023 年 2 月加入 Meta,参与了多个前沿项目的研究和开发。
在他的研究中,Ernie Chang 参与了多个重要的项目和论文。例如,他是《Agent-as-a-Judge: Evaluate Agents with Agents》一文的共同作者,该论文提出了一种新的评估方法,通过代理模型对其他代理模型进行评估,从而提高评估效率和准确性。
此外,他还参与了《MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases》的研究,该研究致力于优化小语言模型,以适应移动设备上的应用需求。
Ernie Chang 的研究兴趣包括多语言处理、多模态系统等。
Changsheng Zhao(赵常盛)

Changsheng Zhao 是 Meta AI 的研究科学家,专注于自然语言处理、深度学习和大语言模型的高效部署与优化。
他本科毕业于北京大学,后在哥伦比亚大学攻读硕士学位,毕业后去了三星美国研究员担任研究员,2021 年加入 Meta。

在 Meta,Changsheng Zhao 参与了多个前沿研究项目,主要集中在模型量化、神经网络架构和多模态系统等领域。 部分代表性工作包括:
-
ParetoQ: Scaling Laws in Extremely Low-bit LLM Quantization:探讨极低比特量化在大语言模型中的缩放定律,帮助平衡模型大小与准确率。
-
Llama Guard 3-1B-INT4:参与开发 Meta 的开源 Llama Guard 模型变体,这是一个紧凑高效的 1B 参数 INT4 量化版本,于 2024 年 Meta Connect 活动中开源,用于 AI 安全和内容过滤。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com