华为开源openPangu-Embedded-7B-V1.1,首次实现AI模型“快慢思考”自适应。它能智能切换推理模式,复杂问题深入思考,简单问题快速响应,兼顾效率与精度。
原文标题:自适应快慢思考,华为openPangu-Embedded-7B-V1.1刚开源了
原文作者:机器之心
冷月清谈:
怜星夜思:
2、这种“快慢思考”模式如果普及开来,除了文章里提到的数学和编程,大家觉得在咱们日常生活中或者其他AI应用场景里,比如智能客服、内容创作啥的,还能带来哪些有趣的改变或突破呢?
3、文章里提到了“数据质量驱动的学习策略”来让模型学会自适应。好奇问一下,这种策略具体是怎么训练模型的呢?是不是需要特别标注哪些是“快思考”题、哪些是“慢思考”题的数据集啊?
原文内容

AI模型「快思考」与「慢思考」,终于可以自适应切换了。
刚刚开源的昇腾原生openPangu-Embedded-7B-V1.1模型,首次实现了这一能力。
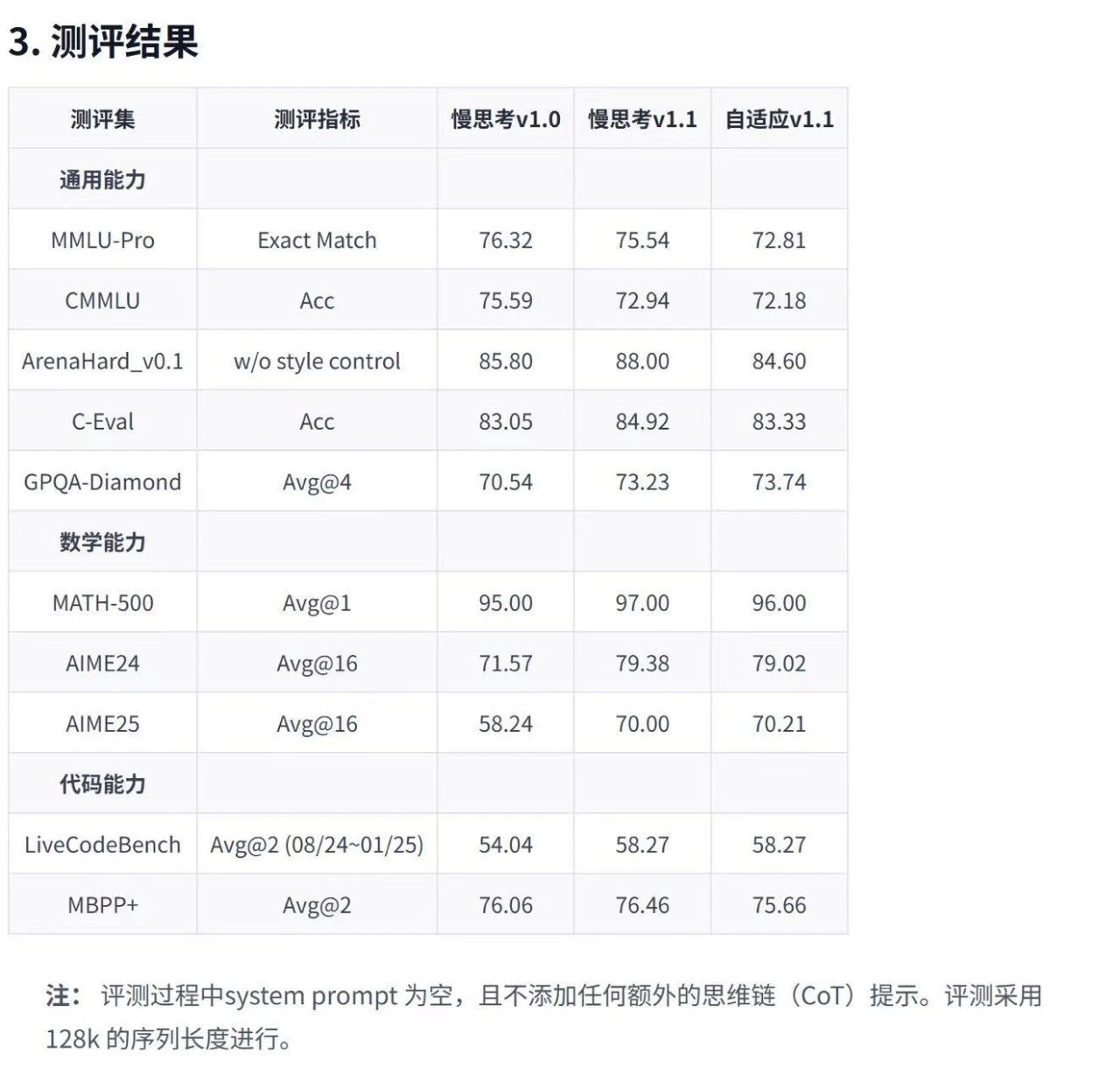
从官方公布的评测结果来看,新模型展示了强大的性能,尤其是在数学和代码能力上。其「慢思考v1.1」版本在数学评测AIME24和AIME25上分别取得79.38和70.00的高分,在代码能力评测LiveCodeBench上也达到了58.27分,全面超越了v1.0版本。
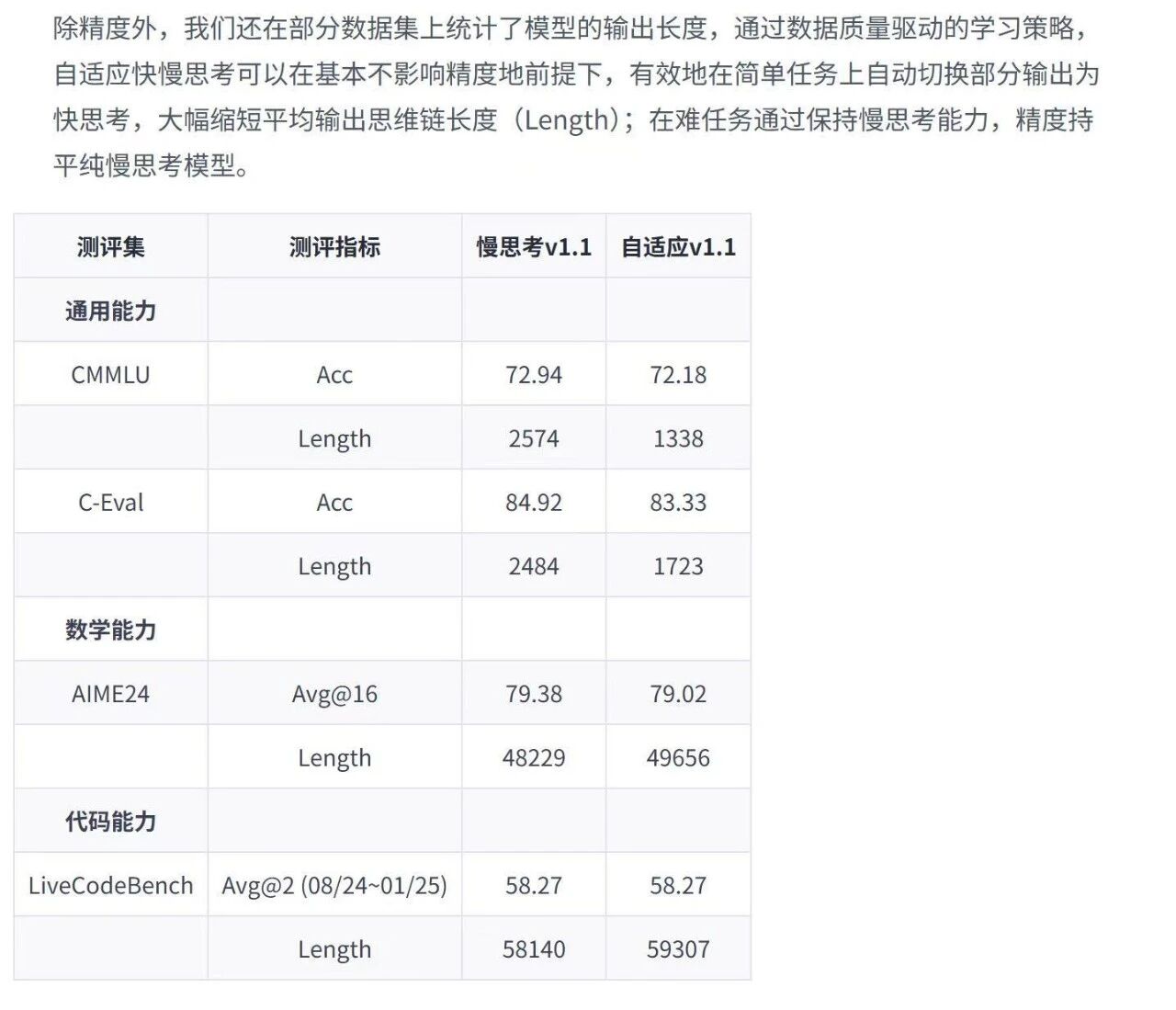
有趣的是,团队还推出了一个「自适应v1.1」版本。该版本通过数据质量驱动的学习策略,实现了效率与性能的平衡。
评测数据显示,在基本不影响精度的前提下,「自适应」模型能在简单任务上(如C-Eval)大幅缩短输出长度,从而降低推理成本和时间;而在困难任务上(如AIME24),则能保持与「慢思考」版本相当的输出长度和思考能力,以确保性能。
例如,在C-Eval上,自适应模型的输出长度从2484缩短至1723,减少了约50%,而精度仅从84.92微降至83.33。
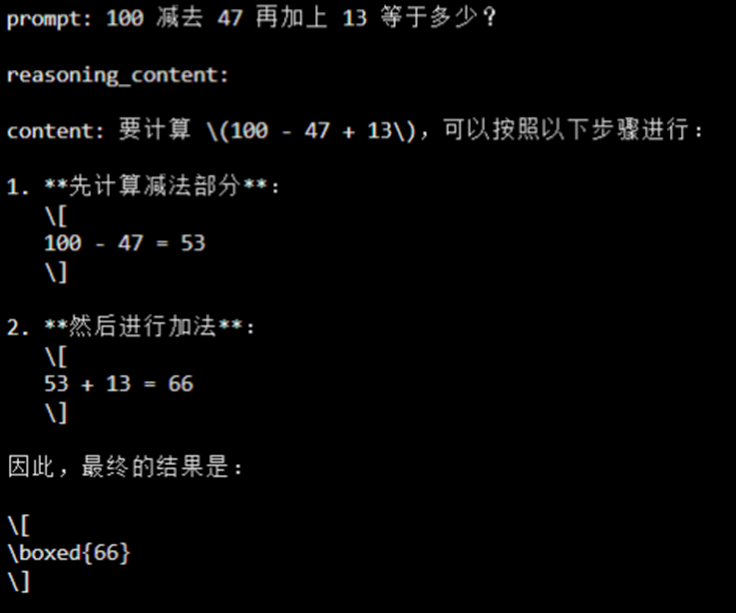
图中的几个案例,可以让我们直观感受openPangu的自适应思考能力。
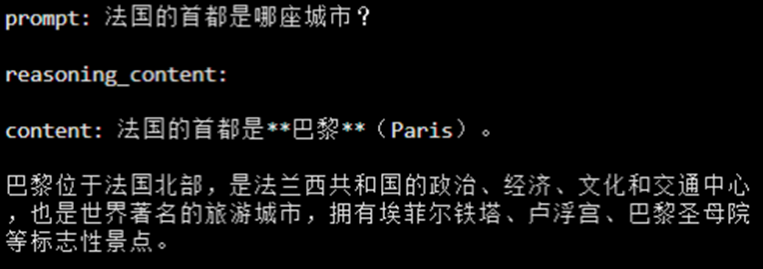
1)快思考:一步到位。对于“法国的首都是哪座城市?”这类简单的事实性问题,模型会启动「快思考」模式,迅速给出「巴黎」这个准确答案,没有任何多余的分析,高效直接。
2)慢思考:步步为营。面对稍微复杂的计算题,如「100减去47再加上13等于多少?」,模型则会自动切换到「慢思考」模式。它会像草稿纸一样,清晰地列出计算步骤,最终得出正确答案66。整个思考过程一目了然,保证了结果的准确性。
3)慢思考:应对复杂逻辑。对于「如何倒序拼写一个单词?」这类需要逻辑推理的复杂问题,openPangu会调用强大的「慢思考」能力,对问题进行庖丁解牛般的拆解:首先识别单词的每一个字母,然后从最后一个字母开始重新排列,最终精准地完成倒序任务。这个过程展示了模型处理复杂指令的严谨逻辑。
这种根据任务难度自适应切换思考模式的能力,确保了用户在提出简单问题时能获得闪电般的回应,而在处理复杂难题时,模型又能沉下心来,进行深入、严谨的推理。
想要体验更多?详见官方开源代码仓:https://ai.gitcode.com/ascend-tribe/openPangu-Embedded-7B-V1.1