rbio1用虚拟细胞为AI做“预实验”,让科学探索更严谨高效。
原文标题:从实验室到虚拟细胞,rbio1建立软验证框架,助力科研AI推理稳健升级
原文作者:数据派THU
冷月清谈:
rbio1的核心是“软验证”(soft verification)机制,它让AI在虚拟环境中与“数字细胞”进行交互,预先检验其假设。具体流程是:大型语言模型(LLM)提出科学假设,这些假设被输入虚拟细胞模拟器进行模拟,模拟器反馈结果,帮助AI筛选出可靠的推理。这相当于为AI配备了一台“随身实验机”,使其在真正动手实验前就能进行快速检验和修正。
通过这种方式,rbio1显著提升了AI在生物学推理任务中的表现,例如基因敲除对基因表达影响的预测。它纠正了传统LLM中常见的逻辑漏洞,使预测结果与真实生物数据更为一致,并能更准确地识别分子相互作用。研究表明,rbio1有效降低了AI的“幻觉率”,使其推理过程更贴近科学研究的“假设—实验—反馈—修正”闭环模式。
rbio1的优势不仅限于生物学领域,只要有足够精细的模拟器,其软验证思路也适用于物理、化学、材料科学等,预示着AI将成为科学家虚拟实验室中的得力助手,共同推进科学探索。
怜星夜思:
2、虽然软验证能帮AI在虚拟世界里“试错”,但毕竟不是真的实验室。大家觉得这种“虚拟预演”会不会让科学家们在新发现的直觉和真实动手能力上有所退化?或者说,我们未来该如何平衡虚拟验证和实际湿实验的关系?
3、文章说rbio1的思路可以推广到物理、材料科学这些领域。但这些领域,比如量子物理或复杂材料结构,跟生物细胞的模拟方式和挑战会很不一样吧?有没有懂行的朋友聊聊,在这些领域推行“软验证”,最大的难点会在哪?
原文内容

来源:ScienceAI本文约2000字,建议阅读5分钟AI 的嘴,终于学会了和科学的手配合。

在实验科学里,最大的痛点之一就是——实验费时又费钱。AI 模型虽然能“滔滔不绝”地输出推理和假设,但很多时候它们只是一本正经地胡说八道。
想验证对错?那你得拉着科学家在实验室里折腾大半天,成本高得吓人。有没有办法让 AI 自己先试试水,别动不动就给科学家添麻烦?有点难,但未必不行。
美国加利福尼亚的 Chan Zuckerberg 基金会提出的 rbio1 就是为了解决这个问题。它的核心思路是:在真正动手实验之前,让 AI 先在虚拟世界里和“数字细胞”对话,做一次快速检验。这就是所谓的 软验证(soft verification)。
该研究以「rbio1 - training scientific reasoning LLMs with biological world models as soft verifiers」为题,预印本发布在 biorxiv。

论文链接:https://www.biorxiv.org/content/10.1101/2025.08.18.670981v3
软验证,怎么做
生物学研究的实验代价极高:一个基因表达实验可能需要数周,一个分子动力学模拟可能需要几天甚至几周的计算资源。传统 AI 模型虽然能生成实验假设,但往往说得好听,做不出来。
rbio1 是一种生物学推理模型,使用强化学习从预训练的LLM进行后训练,以此躲避硬验证中,推理错误所导致的人力物力的浪费。rbio1 的突破在于它让语言模型(LLM)不再单打独斗,而是与虚拟细胞模拟器(Virtual Cell)形成搭档。
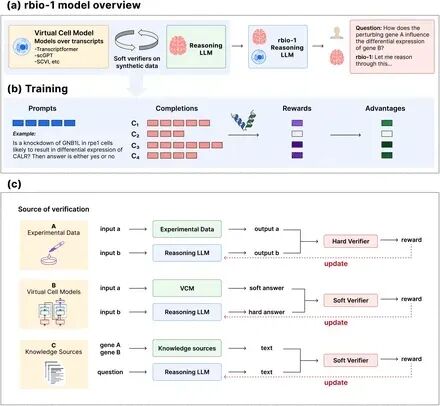
图 1:rbio1 概述。
在实验中,团队证明 rbio1 可以通过与模拟任务的模型交互来学习推理任务,例如预测基因敲除对细胞中其他基因差异表达的影响,其性能与针对硬实验数据训练的 rbio1 模型相当。
rbio1 的流程大致分为三步:(1)LLM 提出科学推理或假设,比如某基因调控的预期效应;(2)这些假设被送入虚拟细胞,在数字环境中模拟实验;(3)模拟器反馈结果,帮助 AI 筛选哪些推理靠谱,哪些只是空想。
换句话说,rbio1 就像是给 AI 配了一台「随身实验机」。实验虽然是虚拟的,但反馈是真实有效的,从而让模型的科学输出更稳健。而这些随身实验,预计也可以接入其他的虚拟实验模型,完成更广泛的实验适配。
关注更为硬核的结果
研究团队表示,在扰动预测设置中,他们关注的是扰动一个基因是否会显著影响细胞中的其他基因,因此会更重视 TPR(真正阳性率)而不是 TNR(真正阴性率)——因为真正阳性的情况较少但更为重要。通过软验证机制,团队得以将生物学世界的模型知识提炼到推理模型中,并在多个科学任务上与传统 LLM 做对比。
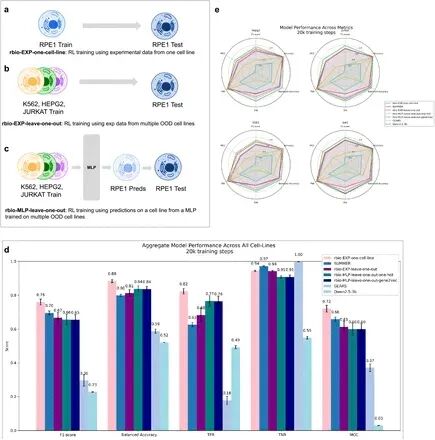
图 2:针对使用 MLP 信号进行实验和软验证训练的模型性能。
基因表达预测任务中,传统 LLM 常常出现逻辑漏洞,预测的变化趋势和真实生物数据对不上。而 rbio 借助虚拟细胞的反馈,大幅减少了这类错误,使预测曲线与实验数据更一致。结果的分析表示,使用模型预测实验数据的结果,而不是实验数据,也可以达到近似的效果,这样就绕过了需要使用后者训练的需要。
而在分子相互作用推理中,rbio 能够更准确地识别关键分子之间的作用关系。在一些复杂网络里,它不仅比单纯的 LLM 错误更少,还能生成更接近实验验证的机制性解释。更令人惊喜的是,使用生物预测模型循环训练可以改进基础推理模型,这将是一种将生物信号嵌入推理 LLMs 的有效策略。
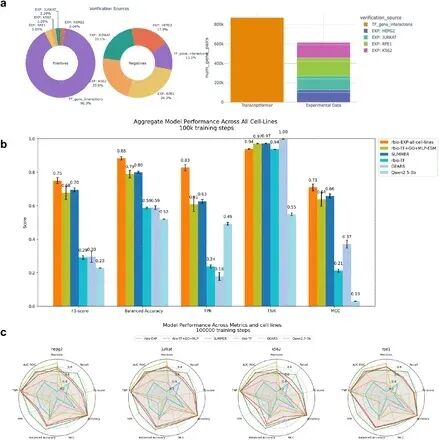
图 3:验证器组合训练模型的性能分析。
团队进一步统计发现:在多任务综合测试里,rbio 的表现不仅在单一任务上优于 LLM,还展现了跨领域的 泛化能力。这点尤为重要,意味着软验证不是某个特定数据集的「小技巧」,而是一种普遍可迁移的科学推理框架。
另外,在可靠性测试中,研究者专门引入了一些「陷阱问题」,即常让 AI 胡乱编造答案的场景。结果表明:传统 LLM 的「幻觉率」居高不下,而 rbio 借助虚拟反馈,可以剔除掉大部分伪造推理,使最终输出的结论更符合科学逻辑。
换句话说,rbio 不只是「听上去更对」,它真的能让 AI 的推理更接近科研工作的核心模式——假设—实验—反馈—修正的闭环。
科学 AI 的好搭档
rbio 的软验证机制,让 AI 轻巧地躲开了满嘴跑火车的境地,让它学会了在实验之前先打草稿。rbio 并不会直接代替湿实验,但能帮科学家提前筛掉大量不靠谱的假设,把真正的实验资源留给更有希望的方向。
更重要的是,这一思路不仅适用于生物学。只要有足够精细的模拟器,物理、化学、材料科学都可以尝试类似的做法。未来,科学家或许不再只是单打独斗,而是和虚拟实验室里的 AI 搭档一起迭代探索。
AI 的嘴,终于学会了和科学的手配合。
编辑:文婧
