EviNote-RAG引入“笔记+奖励”新范式,显著提升RAG系统稳定性与准确性,告别低信噪比和错误累积顽疾。
原文标题:告别错误累计与噪声干扰,EviNote-RAG 开启 RAG 新范式
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到低信噪比和错误积累是RAG的“两大顽疾”。在实际应用中,你觉得这两种问题哪一个对RAG系统的危害更大,或者更难解决?为什么?
3、EviNote-RAG通过轻量级自然语言推理模型作为“蕴含判别器”来确保笔记的逻辑支撑。这种“模型内部监督”的方法,与传统的外部数据标注或人工评审相比,有哪些潜在的优势和风险?
原文内容

本文第一作者戴语琴,清华大学博士生。该工作为戴语琴在蚂蚁大安全实习期间完成,该工作属于蚂蚁集团大安全 Venus 系列工作,致力于打造搜索智能体 / UI 智能体。本文通讯作者为该校副教授吕帅,研究方向包括大语言模型、多模态生成、AI4Design。共同通讯作者沈永亮,浙江大学百人计划研究员,博士生导师,研究方向包括大模型推理、RAG 检索增强生成、多模态生成模型等。
在检索增强生成(RAG)飞速发展的当下,研究者们面临的最大困境并非「生成」,而是「稳定」。
低信噪比让关键信息淹没在冗余文档里,错误累计则让推理链像骨牌一样层层坍塌。这两大顽疾,使得现有 RAG 系统在复杂任务中难以真正可靠。
近期,一项由蚂蚁集团、清华大学、浙江大学、MIT、UC Berkeley、香港大学和新加坡国立大学等机构联合完成的研究提出了全新方案——EviNote-RAG。它不仅在多个权威基准上实现了显著性能提升,更在训练稳定性与推理可靠性上带来了质的飞跃。
核心秘诀在于两个创新:
-
支持性证据笔记(Supportive-Evidence Notes, SEN):像人类一样「先做笔记」,用结构化方式过滤噪声、标记不确定信息。
-
证据质量奖励(Evidence Quality Reward, EQR):通过逻辑蕴含监督,确保笔记真正支撑答案,避免浅层匹配和错误累积。
这一组合带来的改变是革命性的:训练曲线不再震荡,答案推理更加稳健。消融与补充实验进一步验证了这一点——SEN 是性能提升的基石,而 EQR 则是质量提升的关键。两者相辅相成,使 EviNote-RAG 成为当前最稳定、最可信赖的 RAG 框架之一。
换句话说,EviNote-RAG 不仅解决了性能问题,更为复杂推理场景下的检索增强开辟了一条全新的发展路径。
在多个开放域问答基准上,EviNote-RAG 取得了显著突破:
-
在 HotpotQA 上相对提升 20%(+0.093 F1 score),
-
在 Bamboogle 上相对提升 40%(+0.151 F1 score),
-
在 2Wiki 上相对提升 91%(+0.256 F1 score),不仅刷新了当前最优表现,还表现出更强的泛化能力与训练稳定性。

-
论文标题:EviNote-RAG: Enhancing RAG Models via Answer-Supportive Evidence Notes
-
论文地址:https://arxiv.org/abs/2509.00877v1
-
Github 地址: https://github.com/Dalyuqin/EviNoteRAG
研究背景与动机
在如今这个信息爆炸的时代,检索增强生成(RAG)技术已经成为大型语言模型(LLM)在开放问答(QA)任务中的得力助手。通过引入外部知识,RAG 能够有效提升回答的准确性和时效性。
但一个现实问题是:LLM 的知识固定在训练时刻,容易输出过时甚至错误的信息。于是,检索增强生成(RAG)被提出:在问答时,从外部知识库中检索最新信息,辅助模型生成更准确的答案。然而,现有 RAG 系统依然存在两个核心痛点:
-
低信噪比。在开放域检索场景中,真正与答案相关的证据信息往往稀缺且难以识别,大量无关或冗余内容充斥在检索结果中,导致模型在有限的上下文窗口里难以高效聚焦关键信息。
-
错误累计。当推理跨越不完整或噪声证据时,错误会在多跳链路中层层放大,最终严重削弱答案的准确性和稳定性。这一问题在多跳问答场景中尤为突出。
过去的研究尝试通过改进检索质量、引入重排序或摘要压缩、以及对特定语料进行监督微调来缓解上述问题。虽然这些方法在一定程度上降低了噪声、减轻了推理负担,但它们普遍依赖标注的信息提取数据或外部启发式规则,缺乏一种端到端、稳健且可泛化的解决路径。如何从根本上突破低信噪比与错误累计这两大瓶颈,成为推动 RAG 演进的核心动因。
因此,研究者提出了新的框架——EviNote-RAG。

EviNote-RAG 与传统方法的对比:EviNote-RAG 通过证据注释提取关键信息,并在蕴意法官的指导下,确保保留的内容直接支持答案,从而减少噪音并提高性能。
传统的「检索-回答」范式不同,EviNote-RAG 将流程重构为「检索-笔记-回答」的三阶段结构。
在这一框架中,模型首先生成 Supportive-Evidence Notes(SENs)——类似人类笔记的精简摘要,仅保留与答案相关的关键信息,并对不确定或缺失的部分进行明确标注。这一过程有效过滤了无关内容,从源头上缓解了低信噪比问题。
进一步地,EviNote-RAG 通过引入 Evidence Quality Reward(EQR)——基于逻辑蕴含的奖励信号,对 SEN 是否真正支撑最终答案进行评估和反馈。这一机制促使模型避免依赖浅层匹配或片段化证据,从而大幅减轻了错误累计的风险。
得益于 SEN 与 EQR 的协同作用,EviNote-RAG 不仅在多个开放域问答基准上实现了显著性能提升,还在训练稳定性、泛化能力与推理可靠性方面表现突出,真正为解决 RAG 的两大顽疾提供了一条端到端的可行路径。
技术亮点
检索-笔记-回答新范式:不再直接依赖原始检索结果,而是通过结构化的笔记生成,主动过滤干扰信息,增强证据利用率。
类人笔记机制:SEN 模块模仿人类做笔记的习惯,用「*」标记关键信息,用「–」标记不确定信息,避免模型被误导。
逻辑蕴含驱动的奖励信号:引入轻量级自然语言推理模型作为「蕴含判别器」,确保笔记能够逻辑上支撑最终答案,从而在训练中提供更密集、更高质量的奖励信号。
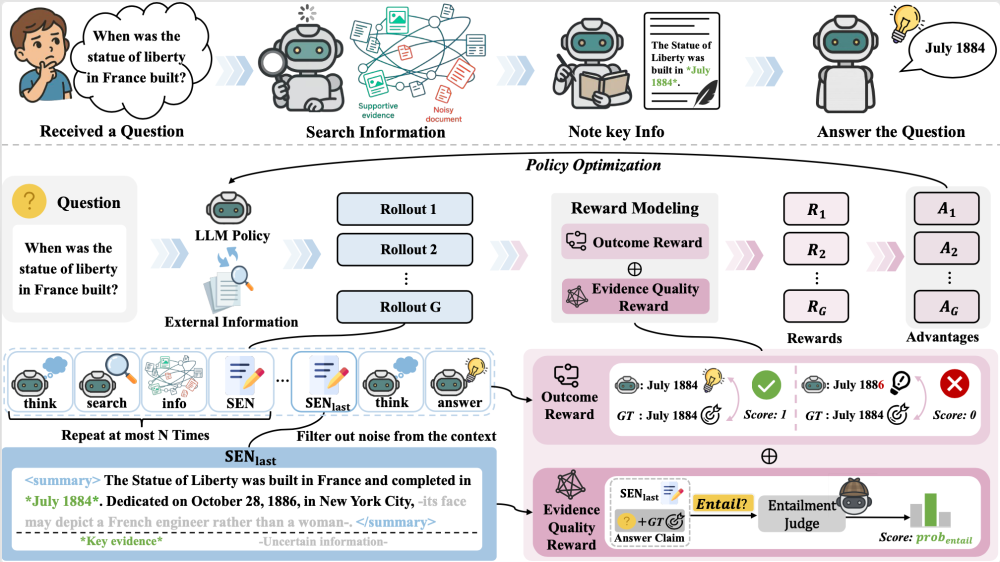
EviNote-RAG 概述:为了提高信息利用率,该方法引入了一个记录阶段,在这个阶段,模型生成支持性证据笔记(SENs),这些笔记只捕获回答所需的信息。基于蕴涵的证据质量奖励(EQR)进一步确保每个注释忠实地支持最终答案,引导模型走向更准确和基于证据的推理。
实验表现
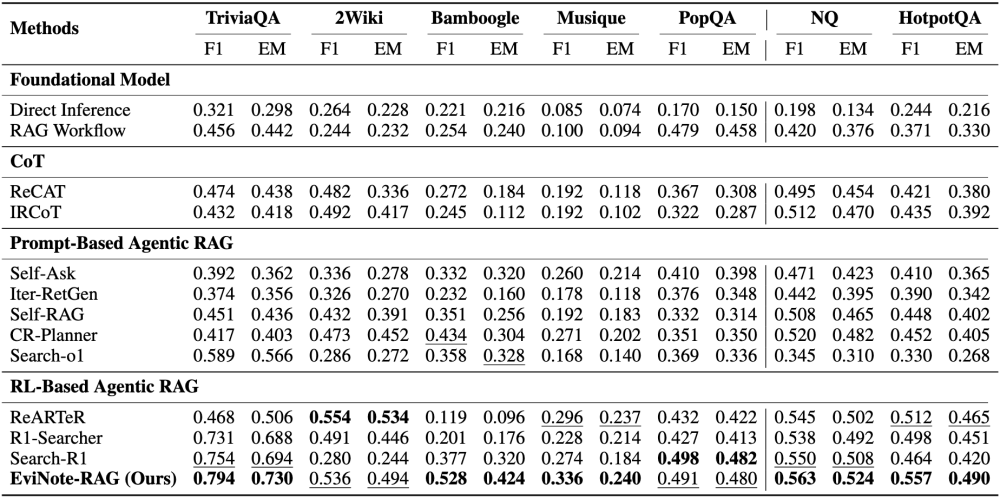
在 7 个主流 QA 基准数据集上测试了 EviNote-RAG,涵盖了 in-domain(同分布任务)和 out-of-domain(跨域任务)两大类。评价指标包括 F1 和 EM(Exact Match)。
结果非常亮眼:在 HotpotQA(多跳推理任务)上相比基础模型,F1 提升 +0.093(20%);在 Bamboogle(跨域复杂 QA)上 F1 提升 +0.151(40%);在 2Wiki(多跳跨域 QA)上 F1 提升 +0.256(91%)。
Training Dynamics:
从不稳定到稳健,RAG 训练的新范式
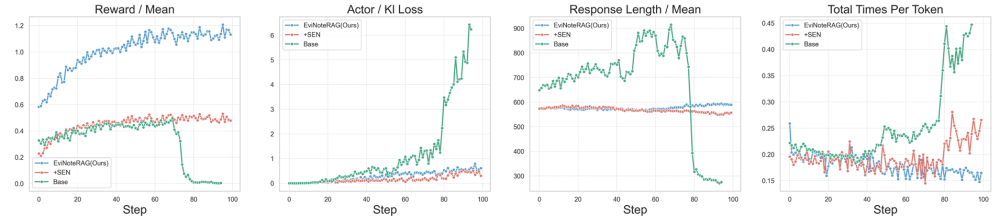
在传统 RAG 框架中,训练往往充满不确定性:奖励稀疏,KL 发散,甚至在训练中后期出现「坍塌」现象,模型陷入无效循环或生成退化答案。
EviNote-RAG 的引入,彻底改变了这一局面。通过在训练过程中加入 Supportive-Evidence Notes(SEN)与 Evidence Quality Reward(EQR),模型不仅学会了过滤无关信息,更获得了密集、稳定的奖励信号。这一结构化的「检索-笔记-回答」范式,使得训练曲线从动荡转向平滑,逐步提升性能的同时,极大增强了鲁棒性。
我们的分析揭示了三个关键发现:
Finding 1. 稳定性来自结构化指令,而非奖励本身。仅靠奖励设计无法避免模型漂移,唯有通过「先做笔记、再回答」的流程,把推理显式约束在证据之上,才能保证训练稳定增长。
Finding 2. 检索噪声过滤显著提升计算效率。SEN 在训练早期即丢弃无关证据,使输出更简洁聚焦,减少冗余推理,从而显著降低推理时延。
Finding 3. 行为监督不仅提升稳定性,更改善输出质量。EQR 的引入有效防止了「过短回答」与「循环生成」等退化模式,使模型在保持高效的同时,输出更忠实、更有逻辑支撑。
结果表明,EviNote-RAG 不只是性能提升,更是一种训练范式的革新:在噪声横行的检索环境中,训练终于能像一条清晰的轨道般稳定前行。
案例分析

一个直观的案例是回答「谁创作了《Knockin’ on Heaven’s Door》?」。
在传统 RAG 系统中,模型容易被检索文档中的噪声或误导性信息干扰。例如,某些文档强调 Guns N’ Roses 的翻唱版本,甚至用语暗示其「作者身份」。结果,模型很容易被这种表述带偏,最终输出错误答案「Guns N’ Roses」。
而在同样的场景下,EviNote-RAG 展现出了截然不同的表现。通过生成 Supportive-Evidence Notes(SEN),模型能够主动筛除无关或误导性的片段,仅保留和问题直接相关的核心证据。多份文档反复提及「Bob Dylan 为 1973 年电影《Pat Garrett and Billy the Kid》创作了这首歌」,这些被标注为关键信息,最终帮助模型稳定输出正确答案「Bob Dylan」。
这一案例生动展示了 EviNote-RAG 在低信噪比环境下的优势:即便存在大量混淆性信息,模型依然能够通过「先做笔记、再给答案」的流程,构建出基于真实证据的推理链,从而避免被误导。换句话说,EviNote-RAG 不仅是在「回答问题」,更是在「学会像人类一样做判断」。
消融实验与补充实验:
拆解模块贡献,验证方法稳健性
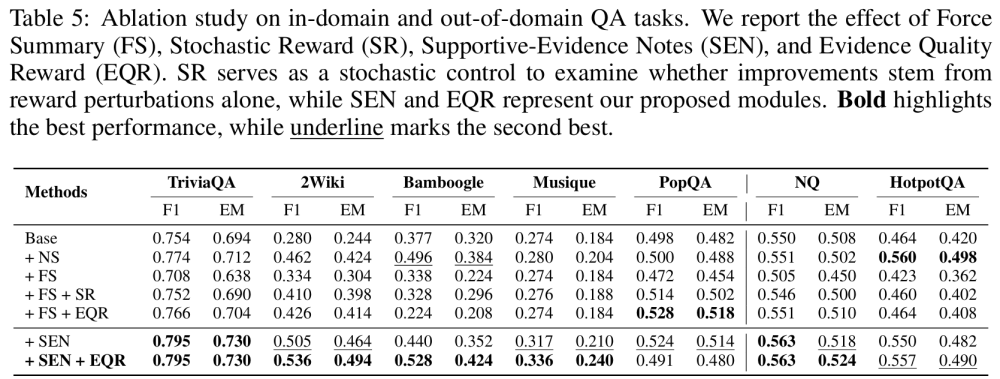
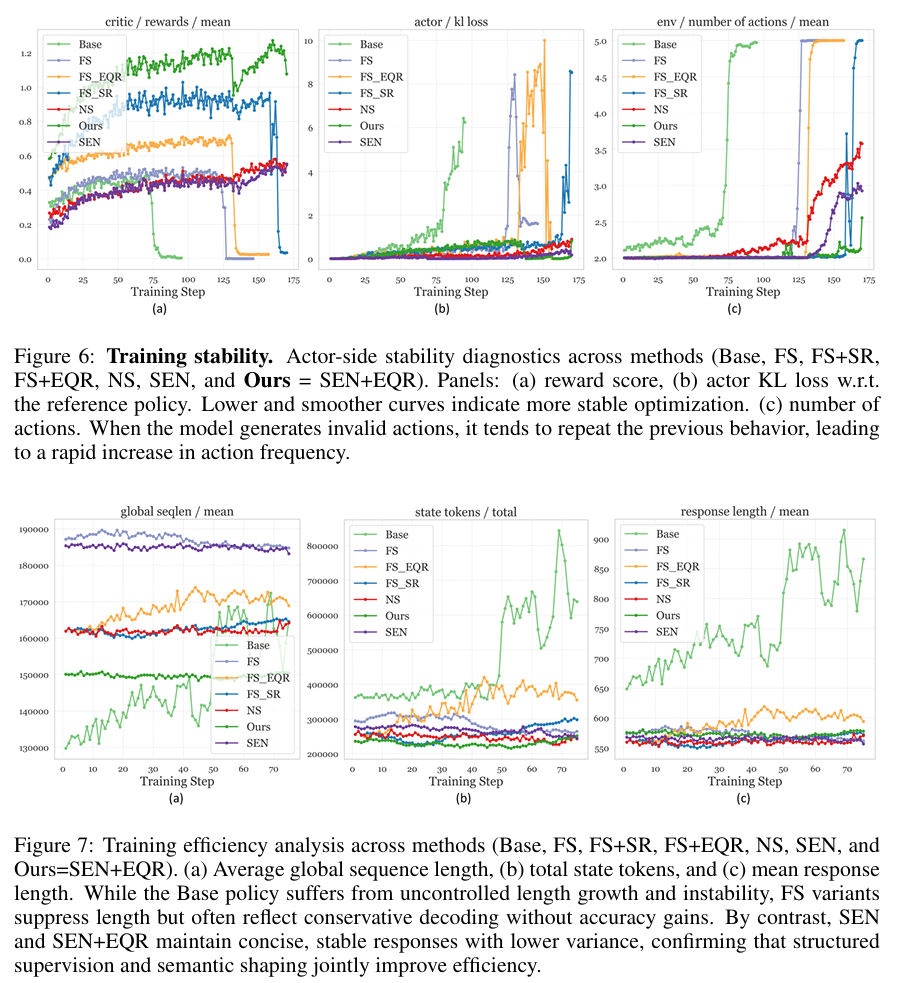
为了进一步理解 EviNote-RAG 的机制贡献,我们系统地进行了消融实验与补充实验。结果表明,我们的方法并非黑箱优化的「偶然胜利」,而是每一个设计环节都发挥了关键作用。
消融实验:SEN 与 EQR 缔造稳健推理在逐步剥离组件的实验中,基线模型(SEARCH-R1)在跨域和多跳任务中表现不稳定。引入 Supportive-Evidence Notes(SEN)后,模型性能显著提升:无关检索内容被过滤,答案相关性更强。在此基础上进一步加入 Evidence Quality Reward(EQR),模型在复杂推理链路中表现更加稳定,F1 和 EM 得到进一步提升。这一组合清晰地验证了我们的方法论逻辑:SEN 提供结构化约束,EQR 提供逻辑一致性监督,二者相辅相成,最终显著增强推理准确性。
补充实验:不同总结策略与奖励设计的比较我们进一步探索了不同的总结与监督方式:Naive Summary (NS)、Naive Evidence (NE)、Force Summary (FS) 等。结果显示,强行要求输出总结(FS)非但没有带来增益,反而由于奖励稀疏导致性能下降。
相比之下,SEN 在明确标注关键信息与不确定信息的同时,提供了更细粒度的监督信号,显著优于 NS/NE。实验还表明,单纯的奖励扰动(Stochastic Reward)难以带来稳定提升,而结合 EQR 的 SEN+EQR 则在稳定性与准确性上均达到最佳。这一系列对照实验凸显出一个核心结论:有效的监督不在于「要求总结」,而在于「如何组织与标记支持性证据」。
核心发现:
-
SEN 是性能提升的基础:通过强制模型「做笔记」,显著降低噪声干扰。
-
EQR 是质量提升的关键:通过逻辑蕴含约束,防止浅层匹配,强化因果一致性。
-
结构化监督胜于简单约束:相比强制总结或随机奖励,SEN+EQR 提供了稳定、密集且高质量的学习信号。
综上,消融与补充实验不仅验证了 EviNote-RAG 的有效性,更揭示了在 noisy RAG 环境中,结构化证据组织与逻辑监督是突破性能瓶颈的关键。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com