2025大数据挑战赛亚军“留宿一宿”团队分享经验:攻克金融市场高波动数据难题,他们通过深入特征工程与策略调整最终脱颖而出。
原文标题:2025大数据挑战赛全国八强团队获奖经验+ppt分享(七)
原文作者:数据派THU
冷月清谈:
经过深入思考与实践,团队最终将重点从模块优化转向了特征工程的深度挖掘。他们基于时序特征,并以金融技术特征作为主要信息源,显著提升了模型表现。文章指出,由于金融数据的高波动性,模型在测评阶段的泛化能力成为关键考验,团队为此持续优化模型效果。此次比赛让团队成员学到了宝贵经验,并在不确定性中找到了可解释的规律,期待未来能有更多精彩的思维碰撞。
怜星夜思:
2、文章中提到金融数据的高波动性挑战了模型的泛化能力。除了特征工程,大家觉得还有哪些方法可以有效地提高模型在金融这类高波动数据上的泛化能力呢?
3、“留宿一宿”团队提到成员独到的思考方式对同一个赛题提供了不同解读视角,这在团队协作中非常重要。大家觉得在实际比赛或工作中,如何更好地融合不同背景或观点的成员,形成合力而不是内耗呢?
原文内容

留宿一宿
陈柯延(重庆邮电大学)
刘一凡(重庆邮电大学)
谭竣文(重庆邮电大学)
全国第二名
赛题描述说明介绍
关注微信公众号“数据派THU”,后台回复“20250522”,即可获取“赛题描述”和“代码规范”
参赛分享与收获
在本次比赛中,我们团队首次接触到了与金融市场相关的任务场景,其数据拥有的高波动性,强非线性的特点不止一次地为我们的解题过程带来了困扰。而股票市场的魅力正在于其永恒的不确定性,赛题的价值也正在于在这份不确定中寻找可解释的规律。
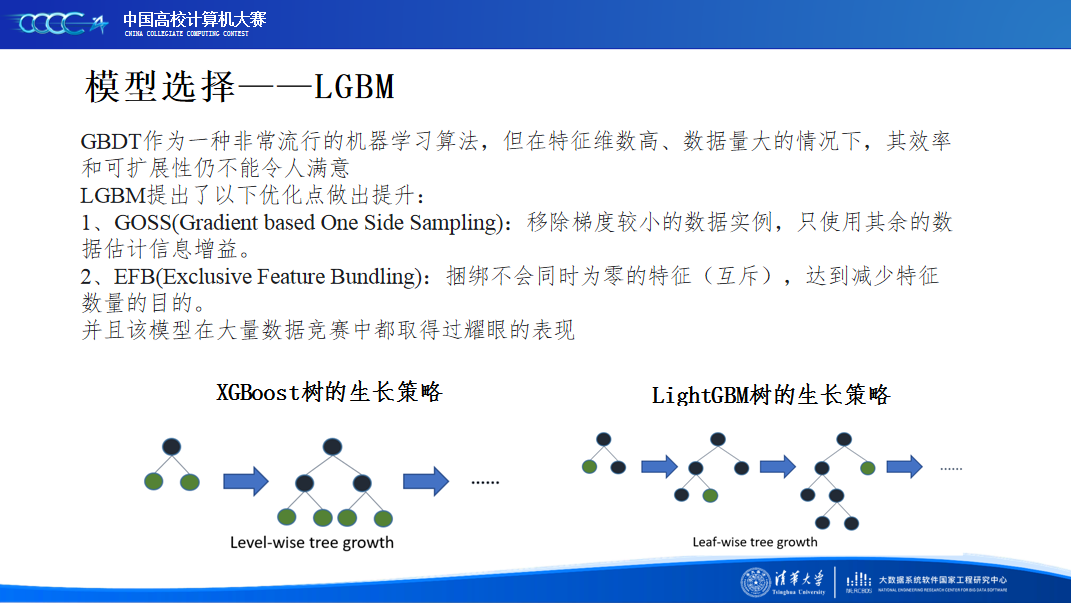
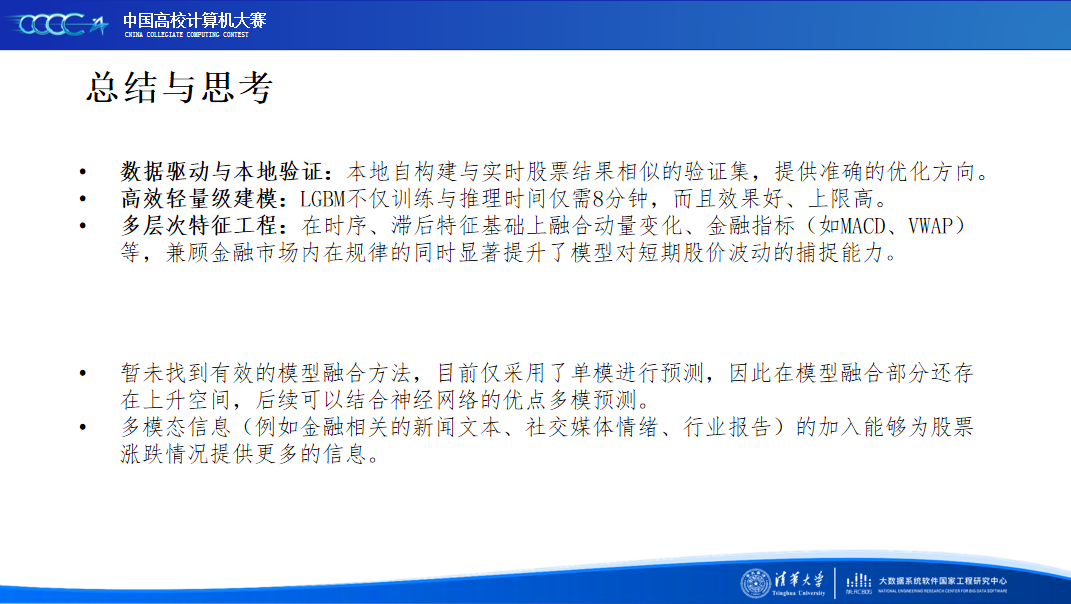
为了了解这个对我们而言并不熟悉的领域,我们团队积极调研相关资料。在比赛初期,解题的方向其实并不明了,我们团队在时序方法和有监督学习之间徘徊很久,群内选手的讨论也时不时给予我们一些灵感。从赛方baseline到sota模型,我们在不同的模型和特征之间做出权衡。在不断试错中,我们意识到不能单纯地关注模型的理论性能指标,针对实际场景选择恰当的模型反而能得到更佳的表现。
经过我们长时间的理论思考与实践操作,尝试了目前表现较好的时间序列模型、反复修改模块后仍难以有起色,于是最终将方向修改到了有监督学习方面,上分策略也从模块优化转向了特征工程的挖掘。我们相信这也是团队的特色所在,成员们独到的思考方式为同一个赛题提供了不同的解读视角,而相互鼓励的氛围也让我们在一次次失败中也能相互扶持着前进。
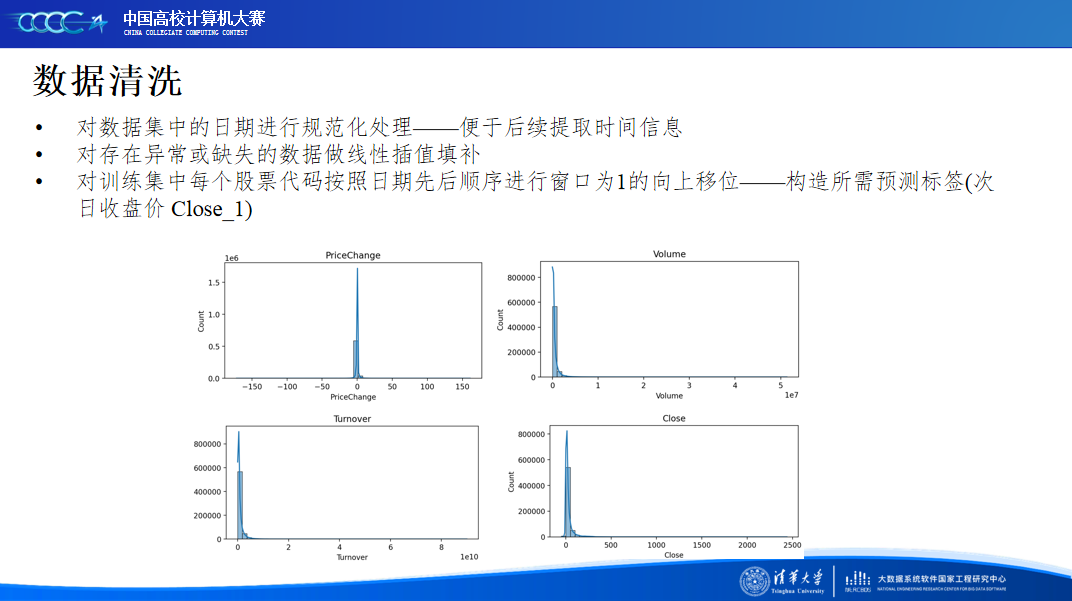
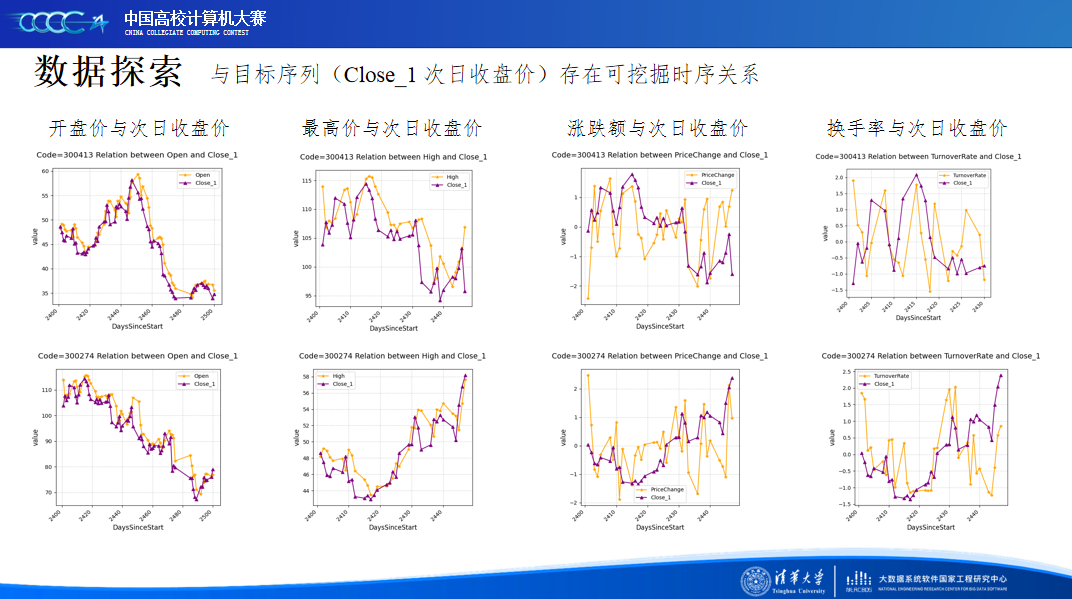
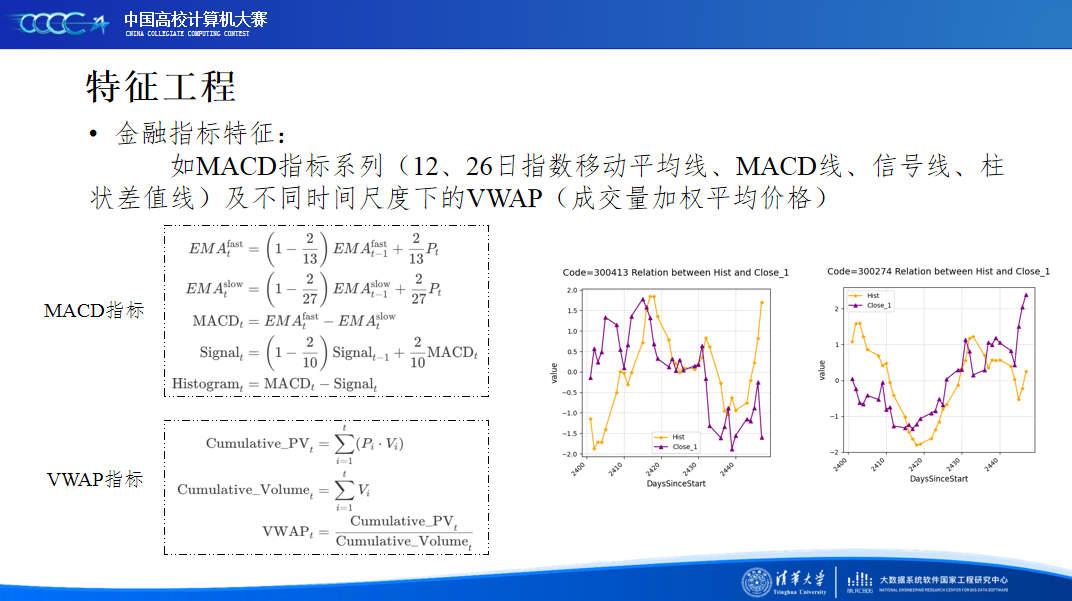
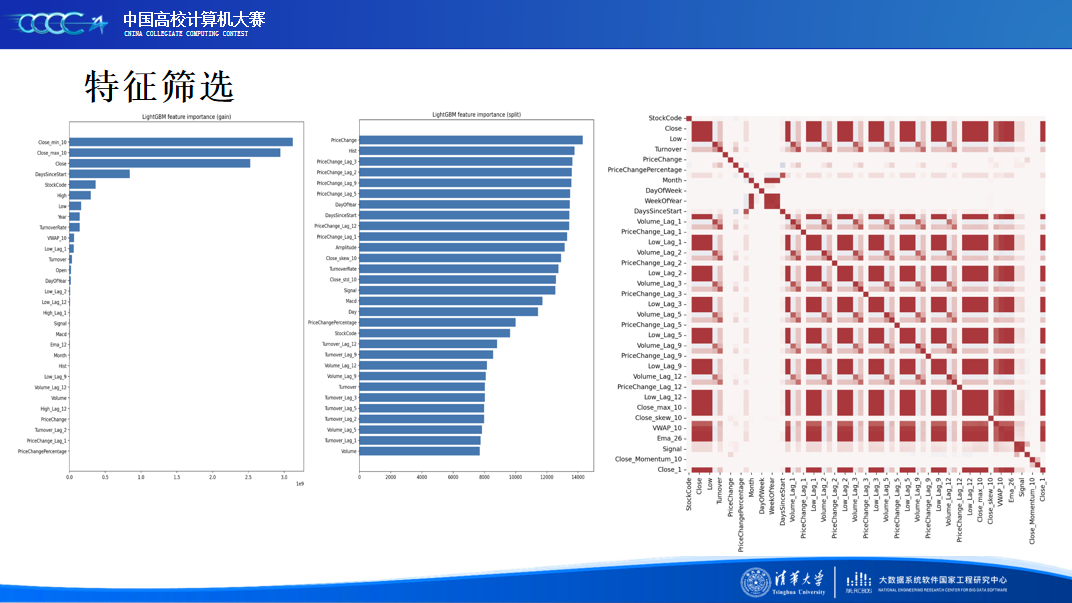
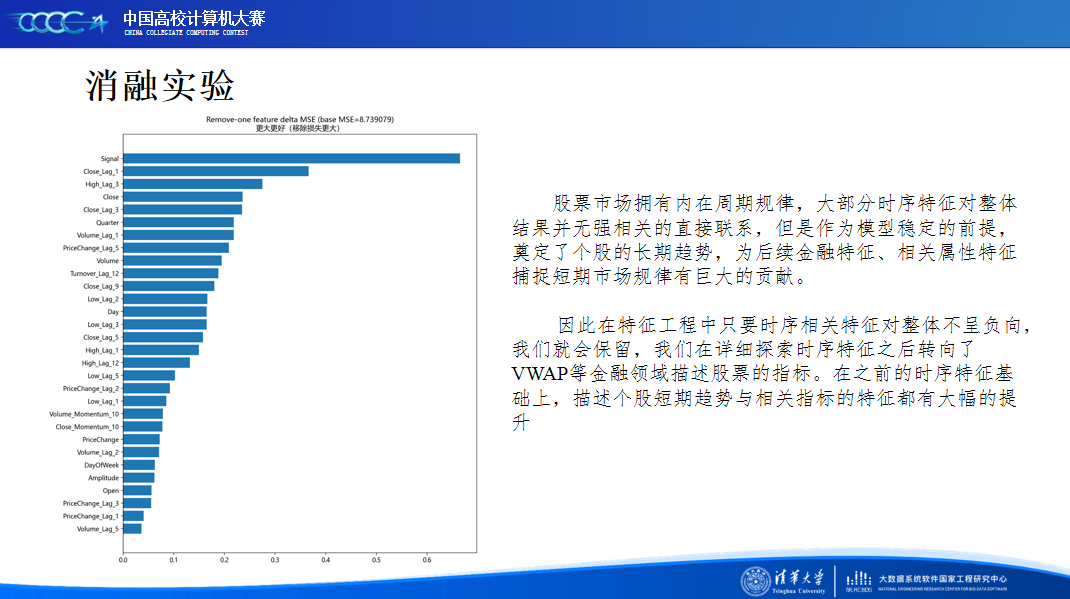
在比赛后半段,我们结合现实金融市场特点和本地的模型验证,着重将精力放在赛题数据分析和特征工程上,并确定了以时序特征作为基础,金融技术特征作为信息重点的探索大方向,让模型性能得到进一步的提升。
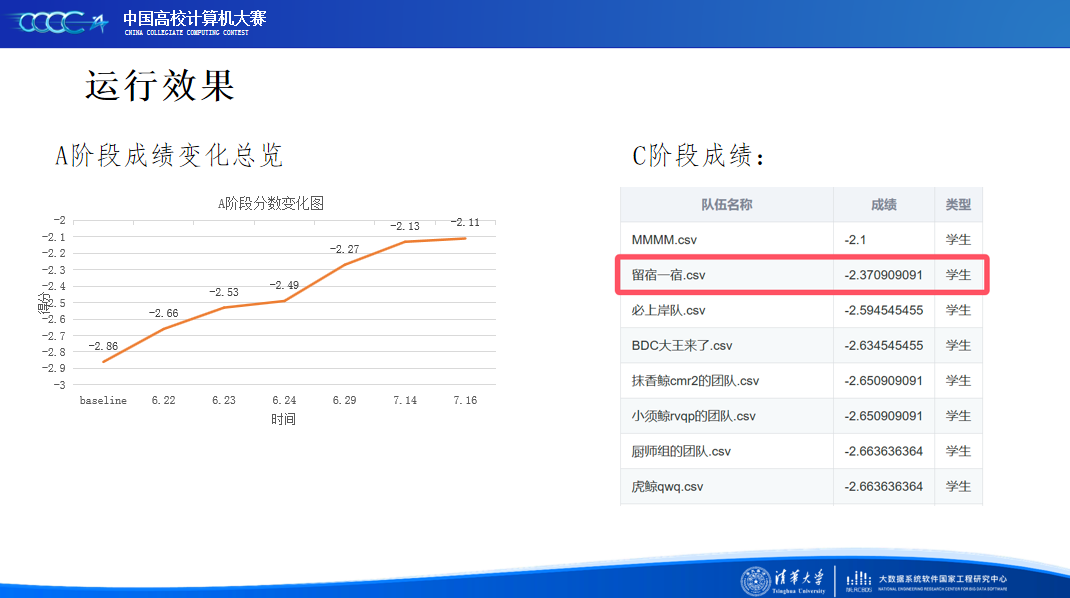
同时比赛的测评阶段带来的时间跨度也是我们担心的一个难点,股票指标的高波动性让模型的泛化能力成为重中之重,一方面扑朔迷离的A阶段排名让我们难以不心生气馁,另一方面我们的模型能否跨越时间在C阶段保持良好的分数也成为我们心中的担忧。但是我们团队依旧脚踏实地,一步一步推进模型效果的优化。
最后,我们非常荣幸能够参加这次比赛。感谢赛方能为我们提供这样一个锻炼自己的平台,我们在很多优秀的团队身上学到了很多,也会将这份宝贵的经验带到今后的比赛和工作当中。期待大赛未来会出现更多优秀的队伍,让我们再一次见证精彩的思维碰撞。
决赛答辩ppt分享