华中科技大学团队在大数据挑战赛中,通过情绪特征挖掘与多模型协同,构建了高精度股价预测模型,荣获全国第六名,并分享了宝贵经验与未来展望。
原文标题:2025大数据挑战赛全国八强团队获奖经验+ppt分享(三)
原文作者:数据派THU
冷月清谈:
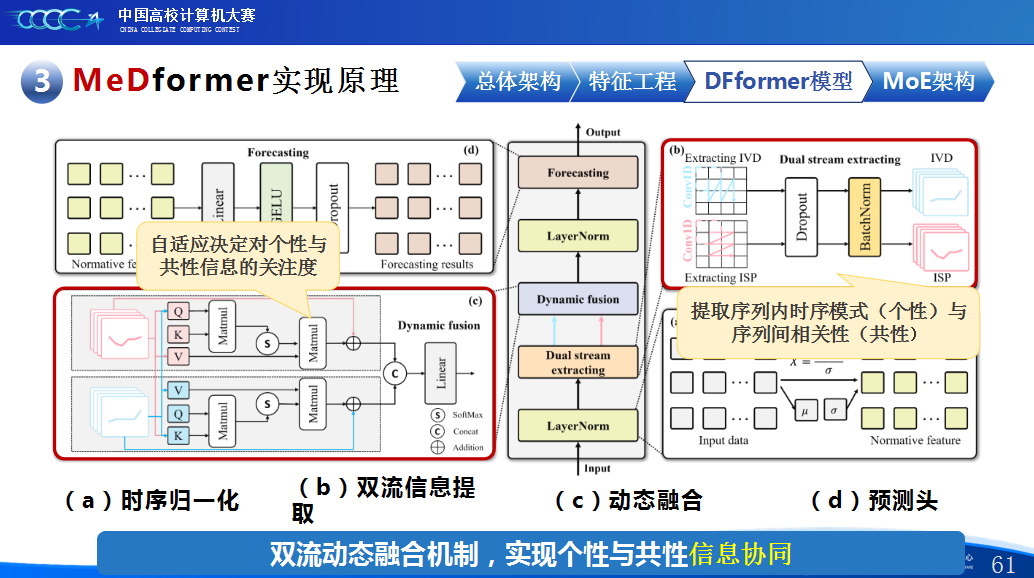
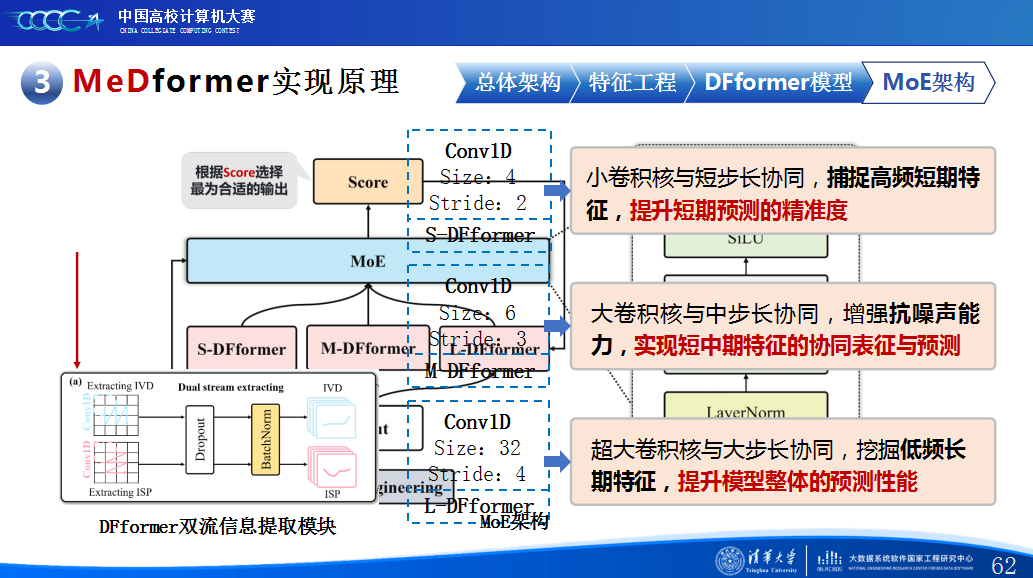
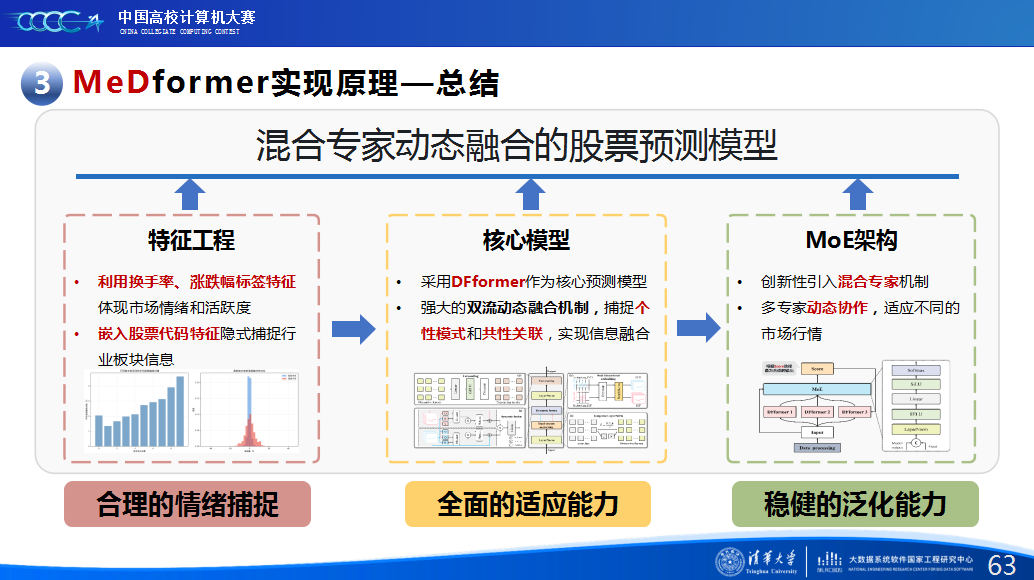
在实践过程中,团队积累了宝贵的经验。首先,他们强调特征工程的重要性,通过将换手率作为情绪指标、嵌入股票代码以学习行业板块信息,并构造涨跌幅标签来强化对极端波动的关注,显著提升了模型感知能力。其次,团队自研了DFformer模型,该模型采用双流结构,能动态提取单支股票的时间模式(个性)和捕捉股票之间的关联(共性,并通过动态融合机制高效结合两者。此外,为提升模型鲁棒性,他们创新地引入了包含S-DF、M-DF、L-DF三种结构的混合专家系统(MoE),使其能动态适应不同市场风格,避免单一模型失效。最后,团队还通过注意力矩阵、火山图等可视化手段,增强了模型决策过程的可信度和可解释性。
通过此次比赛,团队不仅提升了在时序预测、特征工程和模型融合方面的技术理解,也锻炼了团队协作能力,并意识到将模型应用于实际场景时需关注数据、行情等现实问题。他们也清醒地认识到,模型在多模态信息(如新闻、舆情)融合方面仍有很大的提升空间,并将其作为未来的努力方向。
怜星夜思:
2、文中提到了用图表可视化模型决策过程,大家觉得这在实际的金融投资中有多重要?特别是当模型给出买卖建议时,普通投资者或基金经理能多大程度上信任它?
3、团队最后提到未来会尝试多模态信息融合(新闻、舆情)。大家觉得这方面最大的挑战会是什么?比如怎么处理大量非结构化数据,或者怎么避免“噪音”影响预测?
原文内容

小须鲸rvqp的团队
李鹏程(华中科技大学)
卢天浩(华中科技大学)
徐殊欣(华中科技大学)
全国第六名
赛题描述说明介绍
关注微信公众号“数据派THU”,后台回复“20250522”,即可获取“赛题描述”和“代码规范”
参赛分享与收获
首先非常荣幸能够参加本次的大数据挑战赛,我们想从三个方面分享一下我们团队的参赛体会和收获。
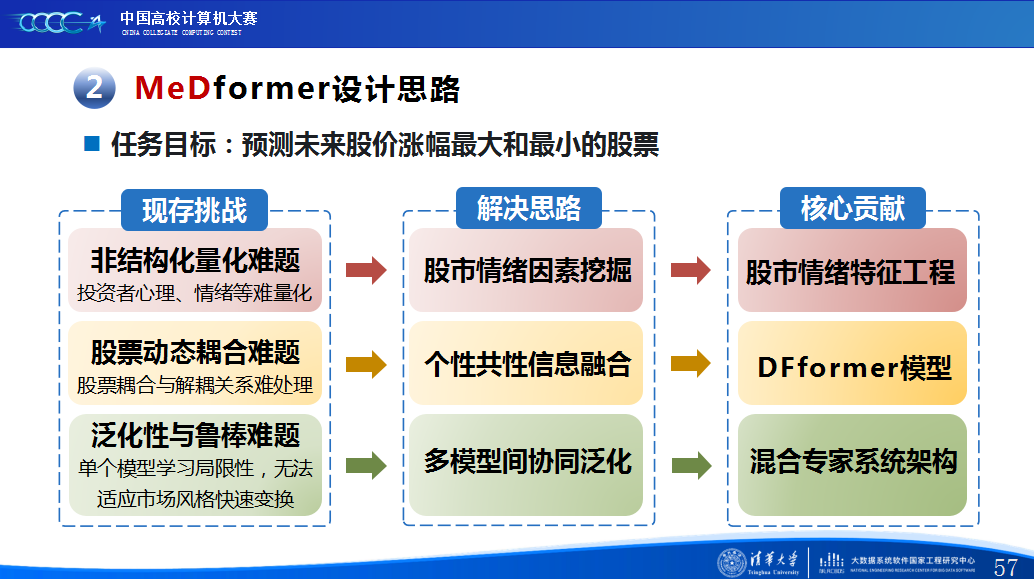
第一是我们对赛题的理解与兴趣。这次比赛的赛题是“预测未来股价涨幅最大和最小的股票”,这是一个非常具有挑战性也极具现实意义的题目。股票市场不仅受历史数据影响,还深受投资者情绪、市场热点、政策新闻等多重因素影响,是一个典型的多源、动态、非结构化的复杂系统。我们团队对此一直很感兴趣,尤其是如何将人工智能技术应用于真实的金融市场预测中。我们认为,传统的时序预测模型往往只关注历史价格,忽略了市场情绪和个股之间的关联,导致泛化能力不足。因此,我们决定从“情绪特征挖掘”和“多模型协同”两个角度入手,设计一个既能捕捉个股特性、又能理解市场共性的混合预测模型。
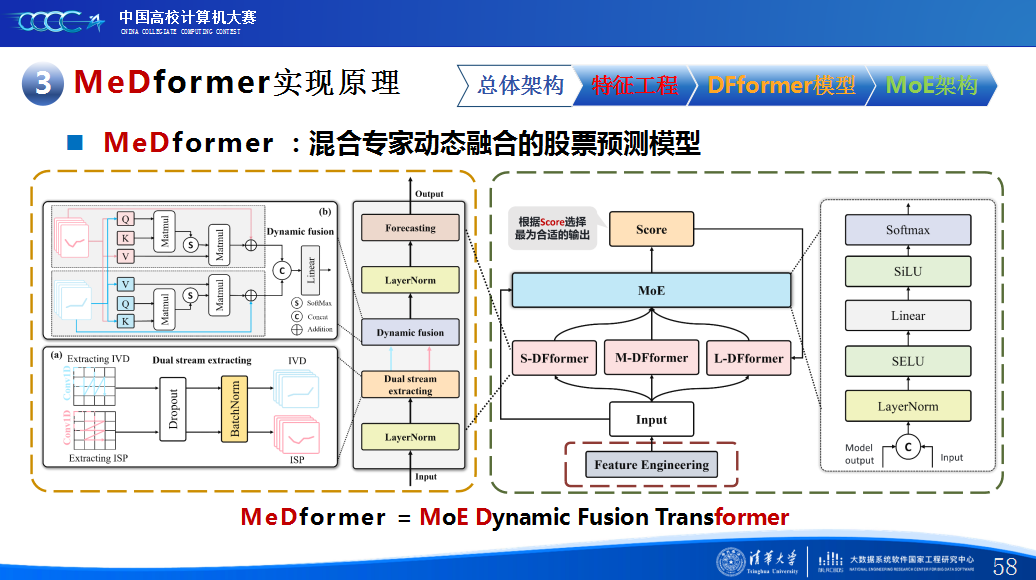
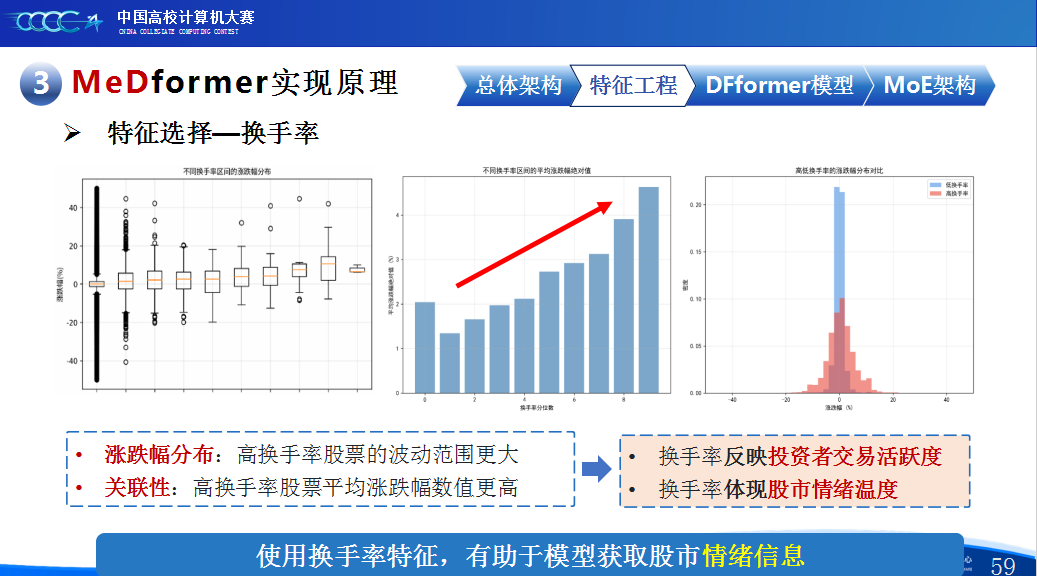
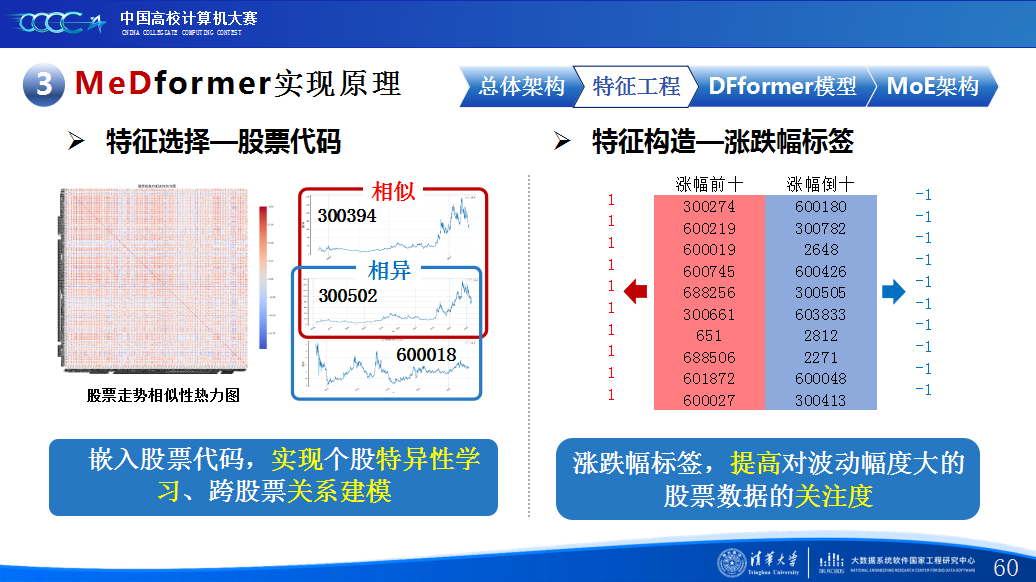
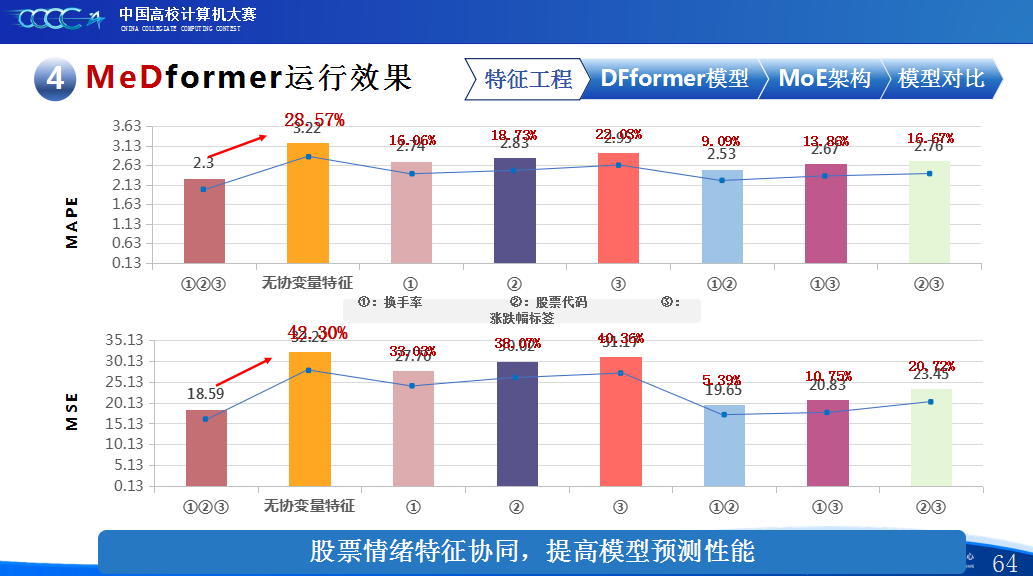
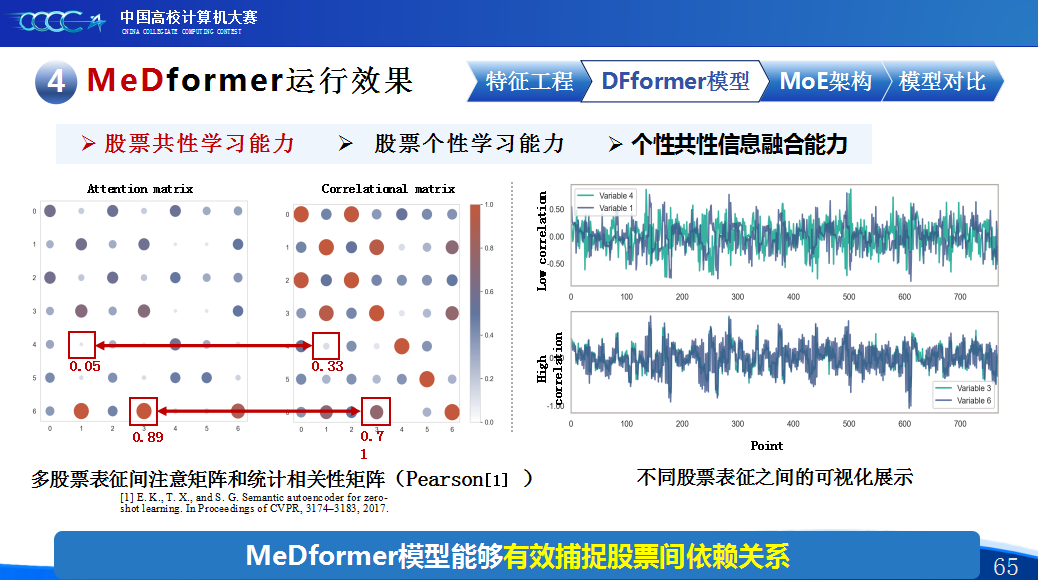
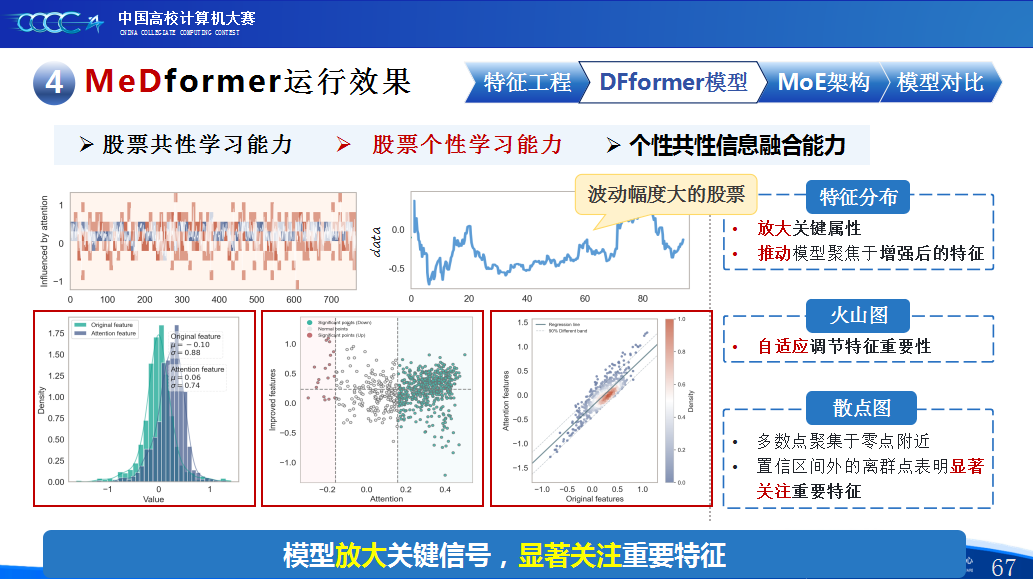
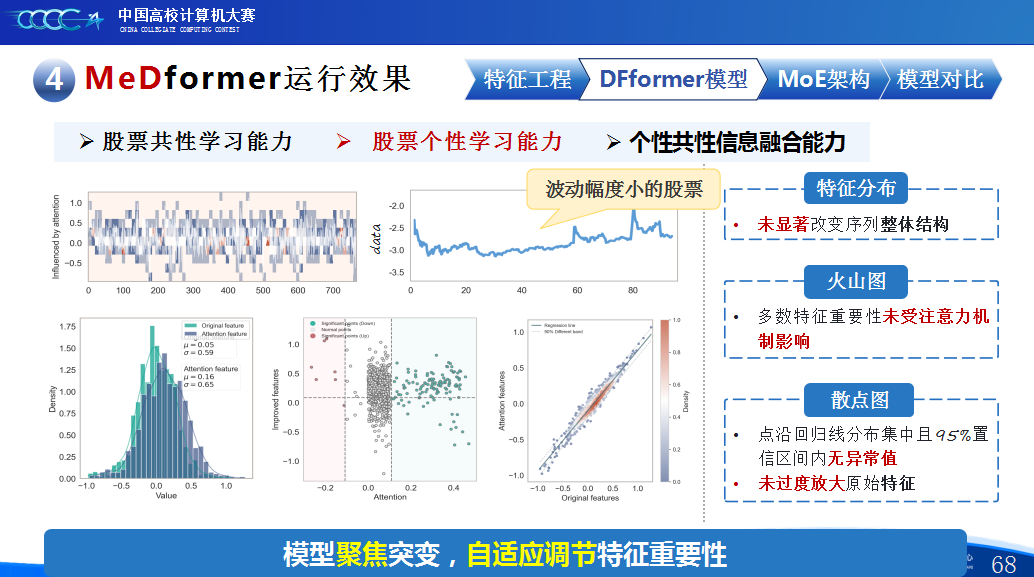
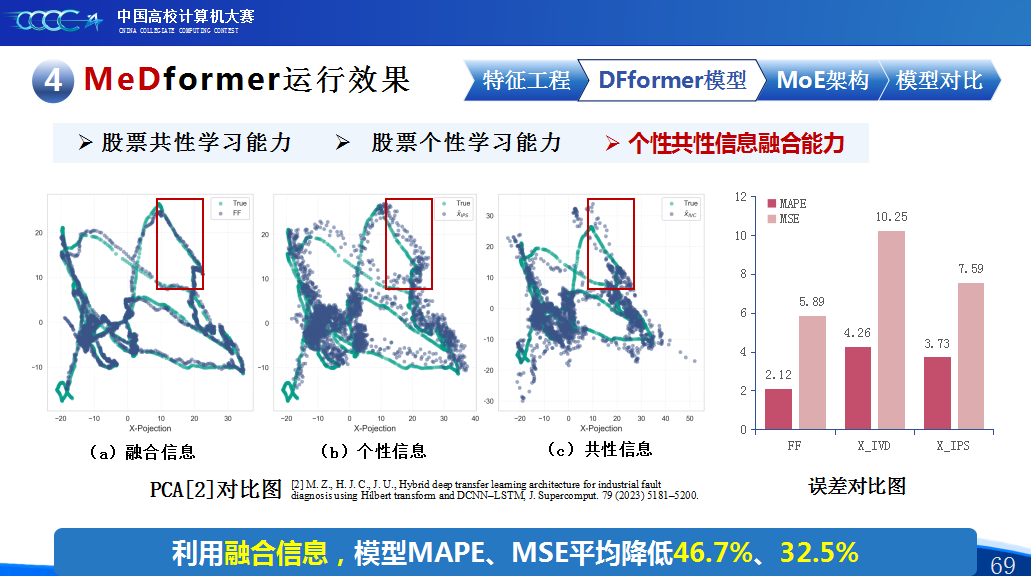
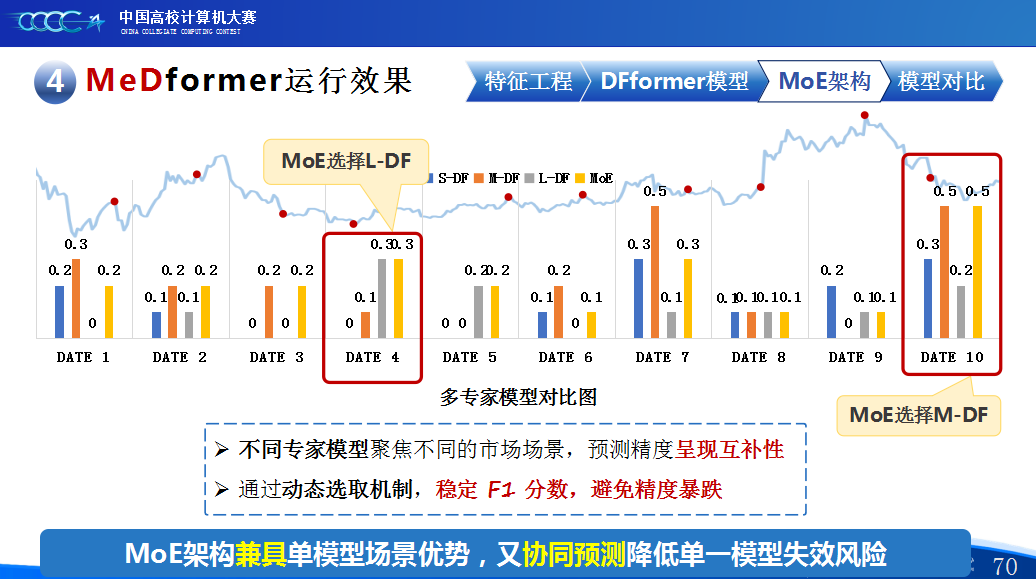
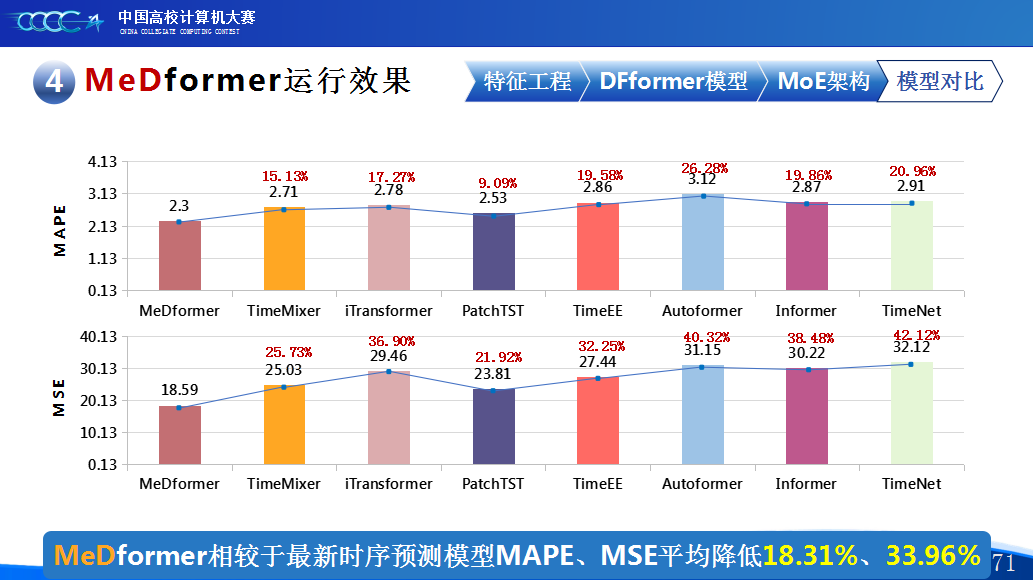
第二是我们团队的经验分享。在设计MeDformer的过程中,我们经历了多次迭代和优化,也积累了不少实战经验:1.特征工程是关键:我们使用了换手率作为情绪指标,发现高换手率股票波动更大,更能反映市场情绪;同时嵌入股票代码来隐式学习行业板块信息;还构造了涨跌幅标签来强化对极端波动的关注。这些特征显著提升了模型的感知能力。2.双流机制捕捉个性与共性:我们自研的DFformer模型采用双流结构,一流动态提取单支股票的时间模式(个性),另一流捕捉股票之间的关联(共性),最后通过动态融合机制将两者结合,大大提升了信息的利用效率。3.混合专家系统(MoE)提升鲁棒性:我们创新地引入了MoE架构,包含S-DF、M-DF、L-DF三个不同结构的专家模型,分别捕捉短期、中期、长期特征。通过动态选择机制,模型能适应不同市场风格,避免单一模型失效的风险。4.我们通过注意力矩阵、火山图、散点图等方式可视化模型决策过程,发现模型能自动聚焦关键时间点和特征,增强了结果的可信度和可解释性。通过本次大赛,我们不仅积累了宝贵的实践经验,还提升了算法设计和创新的能力,尤其意识到在将模型应用到实际场景中时,需要关注数据、行情等现实问题从而贴合实际需求。在和其他队伍的交流中,也极大地拓宽了我们的视野和思路,他们的巧思也给我们提供了新的启发。
最后,我们想由衷感谢大赛主办方提供了这样一个高水平的竞技和交流平台。也感谢评委老师们的中肯意见和建议,让我们看到了模型的不足和优化方向。通过这次比赛,我们不仅提升了对时序预测、特征工程、模型融合等技术的理解,也锻炼了团队协作和项目推进的能力。当然,我们也清醒地认识到,模型在多模态信息(如新闻、舆情)融合方面还有很大提升空间,这也是我们未来继续努力的方向。
决赛答辩ppt分享