字节跳动Robix发布,赋能机器人“思考、规划与灵活交互”。它将推理、规划及人机交互一体化,让机器人不再是工具,更能理解并适应复杂任务。
原文标题:字节跳动Seed推出「机器人大脑」Robix:让机器人学会思考、规划与灵活互动
原文作者:机器之心
冷月清谈:
Robix采用层次化机器人系统架构,将“大脑”(高阶认知层)与“小脑”(低阶控制层)解耦。Robix正扮演着“决策大脑”的角色,负责理解人类模糊指令、多模态推理,并制定适应性的任务规划,而“小脑”则负责精准执行原子命令。通过这种分工,机器人系统在高层次上维持灵活性,在低层次上保证动作的精准性。搭载Robix的机器人已展现出一系列令人印象深刻的能力,包括在做饭时主动发现缺少配料并询问,在用户中途改变主意时立即中止并执行新指令,甚至能识别用户涂鸦并给予自然回应。它还能主动发起对话、准确理解真实的三维空间,并成为一个富有乐趣的“聊天搭子”。
Robix的实现得益于其创新的三阶段训练策略:首先,在通用视觉语言模型(Qwen2.5-VL)基础上进行持续预训练,通过海量数据强化3D空间理解、视觉定位和任务推理等“物理直觉”,构建对物理世界的基本认知。其次,团队设计了“交互合成”流水线,将现有机器人操作数据转化为包含七种复杂人机交互场景的数据集,让模型在模拟环境中学会灵活应对人机交互。最后,引入强化学习,设计“思想-行动一致性”奖励函数,不断纠正Robix的逻辑偏差,确保其思考与行动的严谨性和可靠性。
评估结果显示,Robix在具身推理、任务规划与人机交互方面表现出色。在离线基准测试中,其在3D空间理解、视觉定位和具身任务推理上均有显著提升,优于基座模型和部分闭源模型。在离线交互任务中,Robix-32B-RL在复杂指令理解、长程任务规划和OOD(Out-of-Distribution)泛化能力上超越了现有的开源和闭源基线模型。真实世界在线评估也证明了Robix在厨房、超市等日常生活场景中的高任务完成率,甚至高于Gemini-2.5-Pro和GPT-4o。研究同时发现,高阶VLM与低阶VLA的“指令对齐”问题以及响应延迟是当前大型商业模型面临的挑战。
Robix的研究为通向更通用、更智能的具身智能体提供了一条可行路径,使其更接近“善解人意”的智能伙伴。尽管在高度动态场景和长期记忆机制方面仍有提升空间,但它已为实现通用机器人奠定了坚实基础。
怜星夜思:
2、Robix在演示中展现了很多酷炫的能力,但文章也提到了它在“高度动态场景”和“长期记忆机制”方面的局限。大家觉得在实际生活中,Robix这类机器人目前最适合的应用场景会是什么?哪些场景还需要更长时间去克服这些局限性呢?
3、Robix已经能“眼观六路”,甚至能成为“聊天搭子”了!未来像它这样有高级交互能力的机器人普及后,大家觉得可能带来哪些伦理或社会层面的讨论?比如,我们对机器人的情感期待会不会变高?
原文内容

近日,字节跳动 Seed 团队发布了最新的机器人研究成果——Robix,一个旨在提升机器人思考、规划与灵活交互能力的「机器人大脑」。

-
标题:Robix: A Unified Model for Robot Interaction, Reasoning and Planning
-
ArXiv:https://arxiv.org/abs/2509.01106
-
项目主页:https://robix-seed.github.io/robix/
长期以来,通用机器人在处理复杂、长程任务时,往往因依赖 “模块化” 拼接的设计而显得僵化。Robix 的核心亮点在于其一体化架构:将推理、任务规划与人机交互无缝整合到单个端到端多模态模型中。
根据报告与演示视频,搭载 Robix 的机器人已展现出一系列过去难以实现的复杂交互能力:
-
在做饭时,它不仅能根据菜名(如「鱼香肉丝」)准备食材,还能主动发现缺少配料并询问是否需要补齐;
-
在用户中途改变主意时,它可立即停止当前操作并灵活执行新指令;
-
在你随手涂鸦时,它能识别出画中的物体,并自然地给予回应与赞赏;
……
以下演示视频将直观展示 Robix 在真实互动场景中的工作方式。
核心思想:
从「指令执行器」到「统一思考者」
在将 AI 从数字世界带入物理现实的过程中,研究者们面临着巨大的挑战。一个真正的通用机器人,需要的远不止是执行「拿起杯子」这样的孤立指令。它必须在开放、动态的环境中,应对一系列复杂难题:
-
理解模糊指令:如何领会「等大家吃完再收盘子」这样带有隐含条件的指令?
-
处理实时反馈:当用户突然说「那个杯子别动」时,如何实时中止并调整计划?
-
动态推理决策:在动态环境中,基于实时感知进行推理,并在物理约束下做出合理决策。
为此,Robix 采用了层次化机器人系统 (Hierarchical Robot System) 架构,将「大脑」与「小脑」解耦,实现「宏观思考,微观执行」:
-
高阶认知层 (High-level Cognitive Layer):扮演「决策大脑」的角色,负责处理复杂的任务。它需要理解人类的指令,进行多模态推理,并制定出适应性的任务规划。Robix 正是为这一层而设计的。
-
低阶控制层 (Low-level Controller Layer):扮演「行动小脑」的角色。它不负责「做什么」的决策,而是忠实地执行来自大脑的原子命令,如「拿起那个红色的苹果」、「向左移动 5 厘米」等。这一层通常由一个视觉 - 语言 - 动作(VLA)模型来实现。
通过这种分工,机器人系统既能在高层次上灵活地与环境和人类互动,又能在低层次上保证动作的精准执行,从而在真实场景中展现接近人类的适应性。
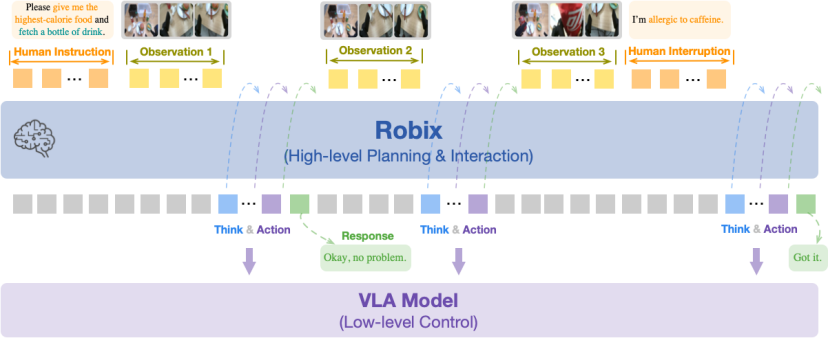
Robix 是一个统一的视觉语言模型,充当机器人系统的「大脑」。它能够接收来自摄像头的第一视角信息和用户的自然语言指令,通过推理思考,生成既能与人沟通的自然回复,也能驱动机器人执行的原子级动作指令。
Robix 技术报告指出,现有多模态模型在迈向通用机器人「大脑」的过程中仍面临两大瓶颈:一是具身推理能力不足,难以将语言和视觉中的抽象概念(如空间关系、物体属性)准确映射到物理世界并应用于推理与规划;二是灵活交互能力缺失,无法在端到端框架中将推理、规划与自然语言交互无缝结合。这些局限严重制约了多模态模型在真实环境中支撑通用机器人智能的潜力。
为此,Robix 采用统一视觉语言模型架构,通过持续预训练增强具身推理能力,并在内部原生整合推理、任务规划与人机交互三大核心功能,从而在端到端流程中实现连贯的复杂指令理解、长程任务规划与自然对话交流,有效提升机器人系统的通用性和稳定性。在此基础上,Robix 进一步展现出更强的交互智能:不仅能够在指令模糊或多解时主动发起澄清,还能在任务执行过程中实时响应中断并进行动态重规划,同时结合上下文与常识进行推理与决策,从而展现出超越以往模块化系统的灵活性与智能性。
现场实测:
Robix 具备基础世界知识,工作交流两不误
技术报告中的概念可能有些抽象,但通过演示视频里揭秘机器人行动前的「内心戏」,我们可以清晰地看到 Robix 是如何工作的。
1. 不仅听懂「话」,更能领会「意」(常识推理)
在演示中,当用户提出要做一道「鱼香肉丝」时,Robix 的表现远超一个搜索引擎。
-
知识调用:它首先根据内置的知识,回答出做这道菜通常需要木耳、胡萝卜、青椒以及葱姜蒜等配料。

演示视频截图 03:24
-
视觉结合:接着,它观察桌上现有的食材,识别出其中有任务所需的胡萝卜和青椒。

演示视频截图 03:36
-
主动规划:最关键的是,在备好现有蔬菜后,它能意识到任务并未完全满足,并主动提出帮助:「我把需要用到的蔬菜都放进去了。不过看起来你好像还缺木耳呢,需要我帮你找找吗?」

演示视频截图 03:44
2. 随时变通,从容应对「我改主意了」 (实时打断)
真实的人机交互充满了不确定性。在清理桌面的任务中,用户多次打断了 Robix 的操作。
当 Robix 正要将一罐可乐放入收纳盒时,用户突然说:「等等,我讨厌喝可乐,你把它扔了吧。」
Robix 立刻理解了这条与原计划完全不同的新指令,中止了「放入收纳盒」的动作,转而执行「扔进垃圾桶」。这种无缝的计划切换能力,是机器人在家庭环境中服务的关键。

演示视频截图 00:49
3. 从「被动响应」到「主动交互」(主动对话)
除了响应用户的指令,Robix 还能主动对话。
在清理任务的结尾,Robix 观察到桌子上只剩下一串葡萄。它没有被动等待新指令,而是主动进行任务总结并发起对话,询问用户:「桌子上就剩下这些葡萄了,要不要帮你打包?」,以此来确认下一步的行动。

演示视频截图 01:15
4. 「眼观六路」,理解真实的三维空间 (空间理解)
Robix 对空间的理解不是平面的,而是立体的。当面对一桌琳琅满目的物品时,用户提出了一个非常考验空间感的问题:「离你较远的这一排,从左往右数的第三个是什么物体?」
Robix 清晰地推理出桌上有远近两排物体,并准确地在远排从左到右定位到第三个物体,回答出:「这是一瓶矿泉水」。这背后是其训练数据中包含的大量多视角对应、深度估计、空间关系等 3D 空间理解任务的支撑。

演示视频截图 02:47
5. 不止是「工具人」,还能成为「聊天搭子」(通用交互)
除了完成任务,Robix 还展现了广泛的通用交互能力。
-
视觉识别:它可以准确读出手机屏幕上的时间「16:17」,也能识别白纸上手写的汉字「测试用,勿动」。
-
开放式对话:当用户展示一幅自己画的简笔画时,Robix 不仅能认出是「一头大象」,还能自然地给出「我觉得你画得非常棒!这头大象看起来很可爱,线条也很流畅」这样的评价,展现了成为一个有趣互动伙伴的潜力。

演示视频截图 02:30
揭秘背后:
Robix 的「养成三部曲」
如此流畅智能的表现,背后是一套严谨而创新的三阶段训练策略。
第一步:打好基础 —— 学习物理世界的规则
为了让模型具备机器人的「物理直觉」,构建对物理世界的基本认知,研究团队在通用视觉语言模型(Qwen2.5-VL)的基础上,用约 2000 亿 token 的海量数据进行「补课」,重点强化三大机器人核心能力:
-
3D 空间理解:通过多视角对应、3D 边界框检测、深度排序与估计等任务,让模型理解三维世界。
-
视觉定位:通过边界框和中心点标注,让模型能准确地「看到」并定位用户指令中提到的物体。
-
任务推理:基于海量机器人和第一视角数据集,训练模型判断「任务是否完成」、「这个动作可行吗」、「下一步该做什么」。
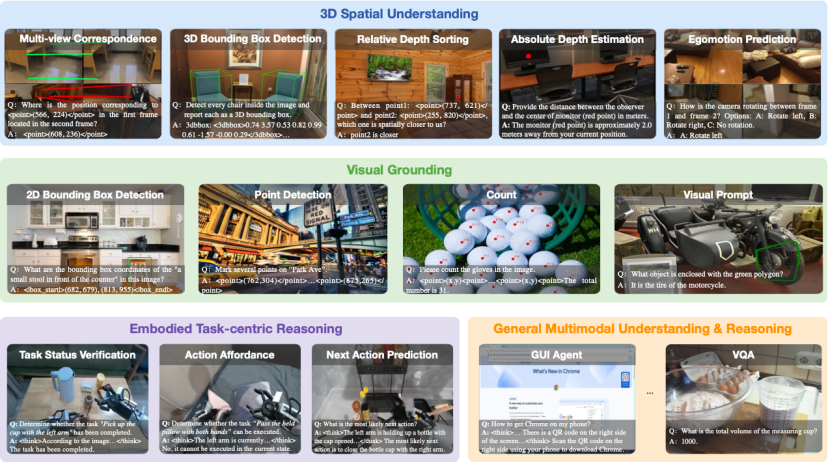
Robix 通过在海量数据上持续预训练构建对物理世界的基本认知
第二步:学会互动 —— 情景模拟中的「社交演练」
真实世界中复杂的人机交互数据非常稀缺。为此,团队设计了一套创新的「交互合成」流水线,将现有的机器人操作数据转化为包含七种复杂人机交互场景的数据集,包括:多阶段指令、约束指令、开放式指令、随时打断、无效 / 非法指令、模糊指令和人机闲聊。这相当于让 Robix 在模拟环境中经历了各种「极限拉扯」,学会了如何灵活应对。

Robix 训练数据构造「流水线」,涵盖了多种复杂的人机交互场景
第三步:自我完善 —— 纠正「思想与行动的偏差」
SFT 之后的模型有时仍会犯一些逻辑错误,比如「想法与行动不一致」(心里想着扔纸巾,手上却要去拿杯子)。为了解决这个问题,团队引入了强化学习,设计了一个特殊的「思想 - 行动一致性」奖励函数 ,这个机制就像一位严格的导师,不断纠正 Robix 的逻辑偏差,让 Robix 的思考逻辑更严谨,行动更可靠。
评估结果:
Robix 在具身推理、任务规划与人机交互方面表现出色
研究团队通过一系列离线基准和在线真实任务测试,对 Robix 进行了全面的评估。
1. 基础感知与推理能力评估
在 31 个公开基准测试中,预训练后的 Robix-Base 模型在 3D 空间理解、视觉定位和任务推理等具身推理能力上表现出明显提升。
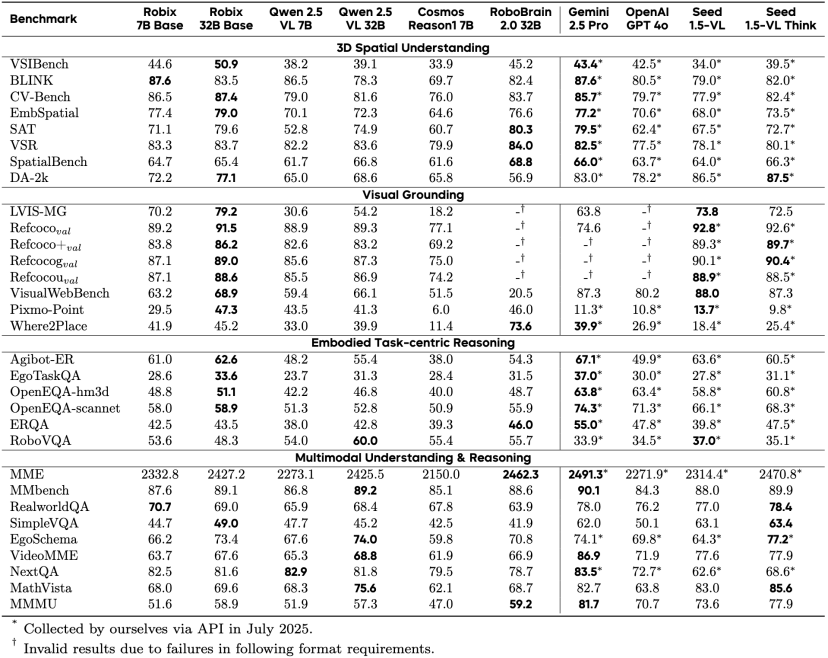
Robix 展现出比较强的具身推理和多模态理解能力
-
3D 空间理解:在 8 个空间推理基准测试中,Robix-7B 和 Robix-32B 在其中 7 个任务上均优于其基座模型 Qwen2.5-VL,平均准确率分别提升 6.5 和 5.1 个绝对点;同时在 5 个任务中超过了业界代表性闭源多模态模型 Gemini-2.5-Pro,展现出优异的空间理解能力。
-
视觉定位:在 8 个视觉 Grounding 基准测试中,Robix 均取得明显提升,其中 Robix-32B 在多个任务中优于闭源大规模模型。尤其是在多物体定位的 LVIS-MG 基准上,Robix-7B 和 Robix-32B 的 F1 分数较 Qwen2.5-VL-7B/32B 分别提升 39.6 和 25.0 个绝对点,显示出强大的目标定位能力。
-
具身任务推理:在团队构建的 Agibot-ER 真实世界具身任务推理基准上,Robix-7B 和 Robix-32B 的准确率相比 Qwen2.5-VL-7B/32B 分别提升 12.8 和 7.2 个绝对点,体现了其在任务级推理上的优势。
2. 离线交互任务评估
为系统评估模型的长程任务规划和任务泛化能力,研究团队构建了三个离线评估集:AGIBot OOD(Out-of-Distribution)、Internal OOD 和 Internal ID(In-Distribution)。它们涵盖整理桌面、超市购物、制作三明治、洗衣服等二十余种日常任务类型,同时包含多阶段任务、约束性指令、交互式中断等多类指令形式,用于全面测试模型在复杂环境下的推理、规划与交互表现。
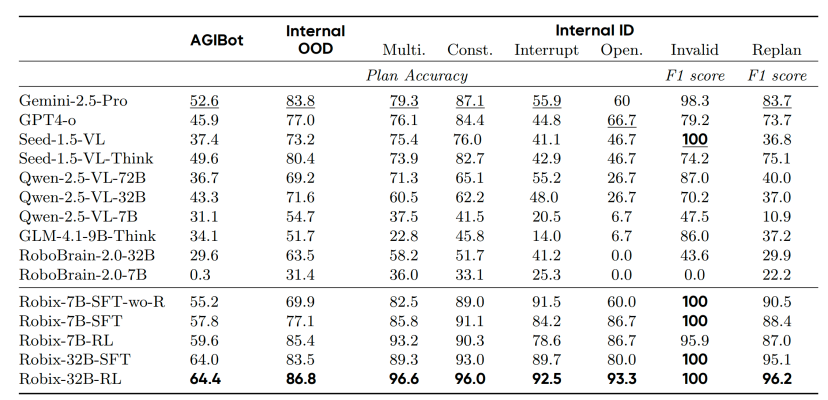
在离线交互数据测试中,Robix 展示了优异的复杂指令理解、任务规划和 OOD 泛化能力
-
整体表现:Robix-32B-RL 在所有评估集上排名第一,优于目前的开源和闭源模型基线,展现出优异的推理、规划与交互能力。
-
跨领域泛化:在两项跨领域(OOD)任务测试中,Robix-32B 的准确率分别领先 Gemini-2.5-Pro 11.8 和 3.0 个百分点,凸显较强的泛化能力。
-
思维链推理:显式思维链显著增强了模型在 OOD 任务泛化与复杂指令理解上的表现。去除思维链的基线模型在 Internal OOD 基准上准确率下降 7.2 个点,在 Open Instruction 任务中更是下降 26.7 个点。
-
强化学习增益:RL 阶段带来进一步提升。相比仅经 SFT 训练的版本,Robix-7B 与 Robix-32B 在 Internal OOD 基准上的准确率分别提升 8.3 和 3.3 个点,验证了 RL 在增强具身推理能力方面的有效性。
3. 真实世界在线评估
研究团队进一步将 Robix 部署到真实机器人系统(字节跳动 Seed 自研 ByteMini 双臂机器人)上,并在厨房、超市等贴近日常生活的场景中设置了五项在线评测任务:
-
Table Bussing(桌面清理):清理使用过的餐具、器皿和食物。
-
Checkout Packing(结账打包):在结账环节整理购买的商品并将其放入袋子或盒子中。
-
Dietary Filtering(饮食筛选):根据饮食限制(如无咖啡因)选择或排除食物与饮品。
-
Grocery Shopping(杂货店购物):根据用户指令推荐并选购杂货商品。
-
Tableware Organization & Shipment(餐具整理与运输):分类、打包餐具并将其运送到指定位置。
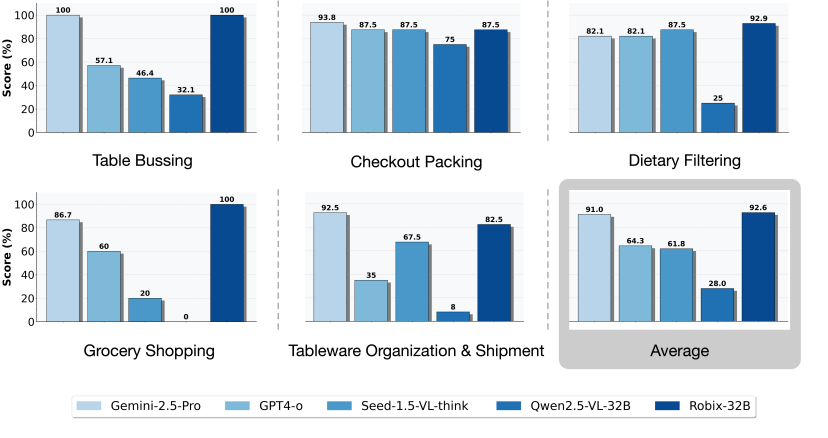
Robix + UMI 测试结果
在由人类标注员通过 UMI 设备充当低层控制器的测试中,Robix-32B 的平均任务完成率达到 92.6%,略高于 Gemini-2.5-Pro 的 91.0%,并显著优于 GPT-4o (64.3%) 和 Qwen2.5-VL-32B (28.0%)。
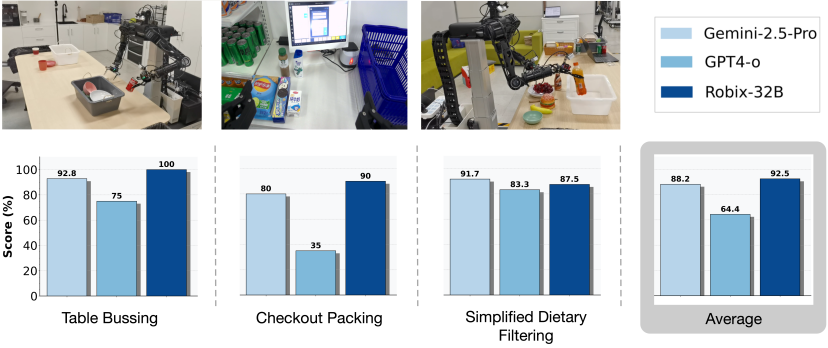
Robix + GR-3 联合评测结果
在与 Seed 自研的 VLA 模型 GR-3 结合进行端到端测试时,Robix-32B 的平均任务完成率达到 92.5%,同样优于 Gemini-2.5-Pro (88.2%) 和 GPT-4o (64.4%)。
研究人员进一步分析发现,基线模型性能下降的一个重要原因在于 VLM–VLA 的「指令对齐」问题。具体而言,高阶 VLM 生成的文本指令在语义上正确,但低阶 VLA 模型无法识别。例如,VLA 可以识别「奥利奥」,却无法理解「饼干盒」。此外,响应延迟也是大型商业模型在真实场景中面临的实际挑战,其响应时间有时超过 30 秒,难以满足实时交互需求。
总结与展望
Robix 的研究为通向更通用、更智能的具身智能体提供了一条可行路径。通过将推理、规划与交互融为一体,它使机器人更接近「善解人意」的智能伙伴。
当然,通往通用机器人的道路仍然漫长。研究团队也坦言,Robix 在高度动态场景中依旧存在局限,且亟需更强大的长期记忆机制。但可以肯定的是,Robix 已经为这一目标奠定了坚实基础。我们有理由相信,在不远的将来,一个既能高效完成任务、又能自然交流的智能机器人,将真正走入人类生活。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com