涂鸦秒变迪士尼动画?多款AI工具让静态画作活起来,轻松生成有声有色动态视频!
原文标题:又多了一个哄孩子AI神器,一张破涂鸦竟能秒变迪士尼动画
原文作者:机器之心
冷月清谈:
这些工具的操作普遍简化,用户只需上传图片或提供简单提示词(Prompt),即可将天马行空的想象力转化为富有情节和动态的视频。值得一提的是,即梦、Veo3、可灵等工具已能实现音视频同步生成,显著简化了传统视频制作流程,为用户带来更便捷的创作体验。其中,谷歌Veo3在音效的清晰度和同步性上表现尤为出色。
而Meta Animated Drawings专注于将画作中的卡通角色制作成多种姿态的动画,通过识别肢体关节实现更精细的动作捕捉。
这些AI神器不仅为家长提供了将孩子涂鸦变为动画的便捷方式,也为广大创意内容生成者开辟了高效的动画制作新途径,让高质量动画创作不再局限于专业人士。
怜星夜思:
2、这类把涂鸦变动画的AI工具,对儿童的想象力培养和教育发展有什么好处?另一方面,过度依赖AI或者AI生成的内容质量参差不齐,会不会带来一些新的挑战,比如版权问题、内容审查或者对孩子艺术创作本能的影响?
3、文中对比了几款工具的优缺点,比如Veo3在音效方面更成熟。大家觉得未来这些AI视频生成工具还会往哪些方面发展?比如,会不会出现更强的交互性,让用户能实时调整动画角色动作,或者能直接生成带情感表达的微电影?
原文内容
编辑:杨文
家长直呼太香了!
年轻父母又多了一个哄小孩法子。
前段时间,博主 Rory Flynn 在 X 上发了个帖子,说他妈妈发来一张 30 年前的涂鸦画,他反手就用 Midjourney 做成了「妈妈拿彩虹木勺大战巨龙」动画。

虽然有点粗糙,但整体效果还不错,完美还原了童年那种天马行空、乱七八糟的想象力。
他还附上了提示词:
We crash zoom into an immersive scene, where a mother holding a magical wooden spoon is fighting off a ferocious dragon with intense cinematic action.(我们快速推镜进入一个沉浸式场景,一位母亲手握魔法木勺,正与一条凶猛的巨龙激烈战斗,充满强烈的电影感。)
并总结了提示词框架「we crash zoom into an immersive scene, [subject + action], intense cinematic action」,照葫芦画瓢即可。
我们也试了下,上传一张网友小时候的墙上涂鸦照,输入提示词:we crash zoom into an immersive scene,Three little people are happily dancing,intense cinematic action.(我们快速推镜进入一个沉浸式场景,三个小人开心地跳着舞,充满强烈的电影感。)

即梦立马将涂鸦中的三个小人活灵活现地呈现出来,动作自然流畅,没有出现画面崩坏或者卡顿的现象。
我们还可以在生成视频后点击 AI 配乐按钮,选择根据画面自动配乐或自定义 AI 配乐,即梦就能一口气生成三首符合画面风格的曲子。
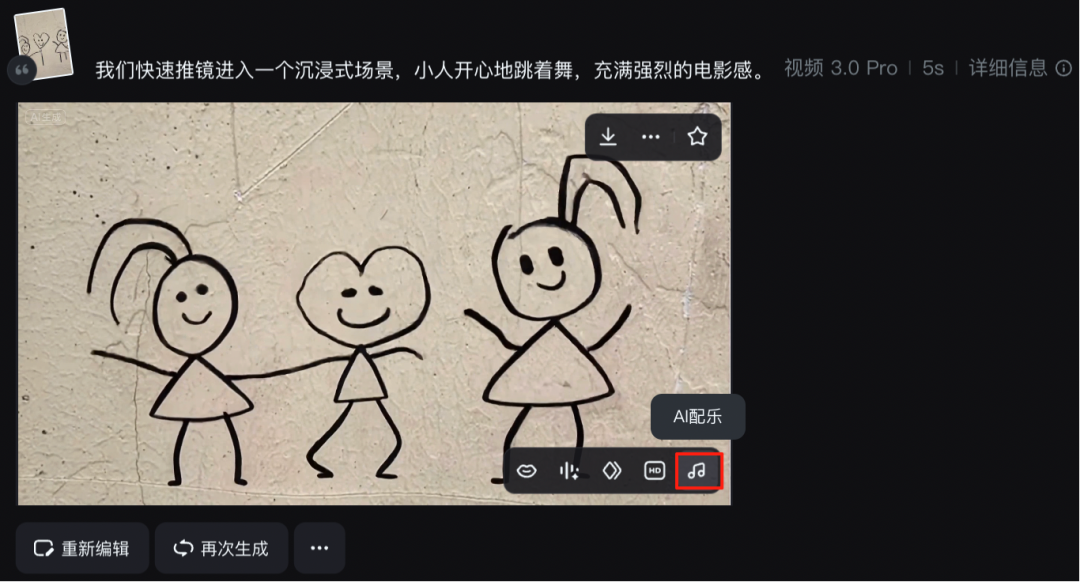
以下就是即梦根据画面自动配乐的效果:
我们又派出了谷歌 Veo3,直接在谷歌 Gemimi 网页选择 Tools-Greate video with Veo 使用即可。
链接:https://gemini.google.com/
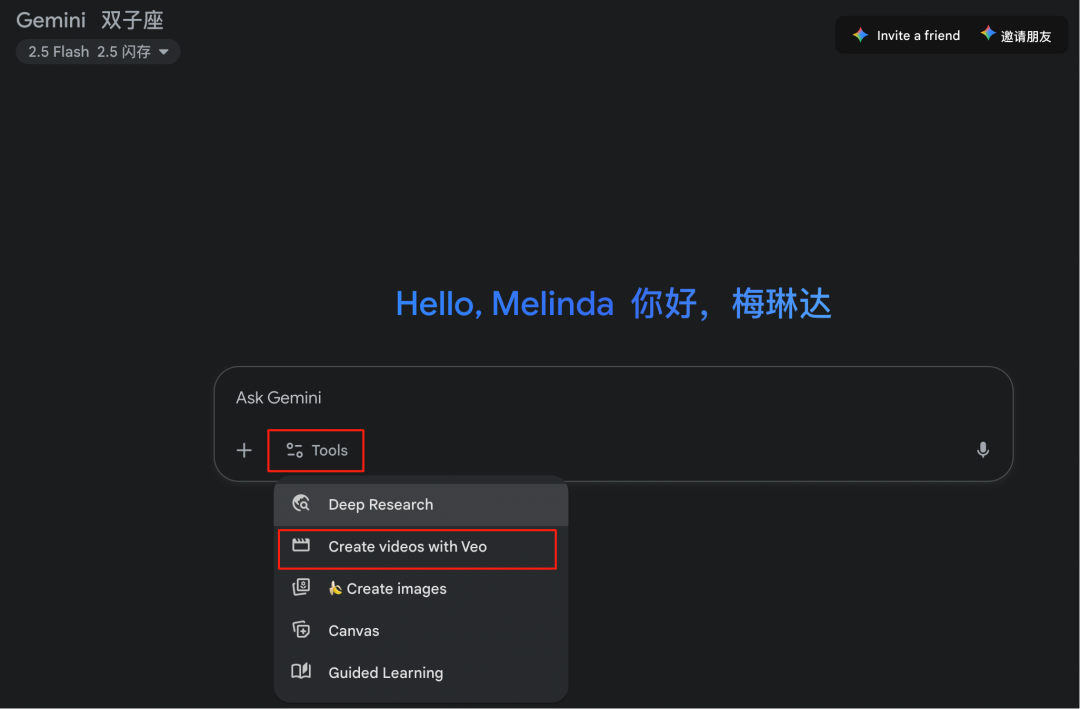
Veo3 的优势在于,它能够让音视频一锅出,尽管这三个小人最后变了模样,但整体效果毫无违和感,竟有种卡通电影片头的 feel。
再来一个,提示词:we crash zoom into an immersive scene,the child is walking briskly with a lotus leaf in hand, while the snail crawls slowly behind,intense cinematic action.(我们快速推镜进入一个沉浸式场景,小孩拿着荷叶大步向前走,身后的蜗牛慢慢蠕动。)
即梦生成的动画效果相当治愈,它能够精确地捕捉角色的动作轨迹,小女孩手臂摆动和步伐配合得恰到好处,没有出现同手同脚的不协调现象,也没有出现多胳膊少腿儿的错误。
即梦生成无音效效果👆
如果想给视频加上音效,与前文操作一样,只需点击「AI 音效」按钮即可自动生成。
即梦生成有音效效果👆
与 Veo3 一样,现在可灵也能自动让视频和音频同步生成了,这一进步简化了视频创作的流程,减少传统视频制作中分别处理音频和视觉效果的繁琐操作。
可灵生成效果👆
谷歌 Veo3 生成效果👆
总体来看,即梦、可灵和 Veo3 都能够在较短时间内完成视频和音频内容的生成。
在音频生成效果方面,Veo3 在清晰度和同步性上表现得更为成熟,能够较好地处理多层次的音效和画面同步;即梦和可灵在复杂或动态场景中同样能够实现音效与动作的同步,尽管音效的清晰度和丰富度上还有一定的提升空间,但整体表现也还不错。
之前我们还介绍过 Meta 出品的一款神器 ——Animated Drawings,可以让涂鸦立马变成动画。
链接:https://sketch.metademolab.com/
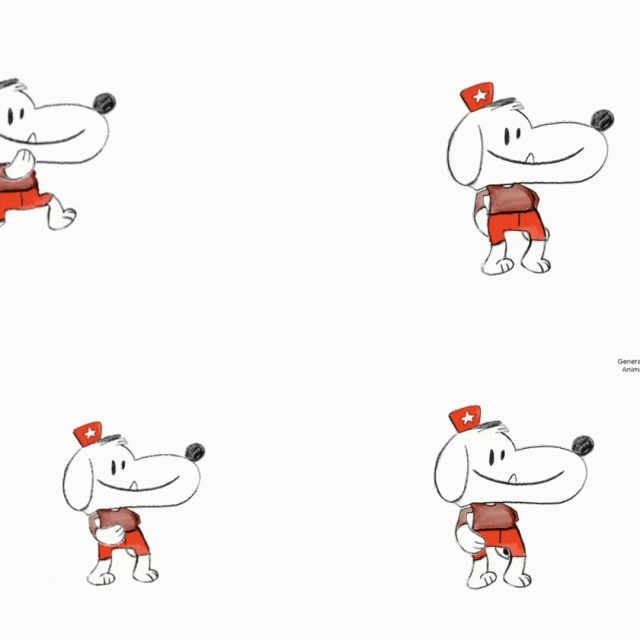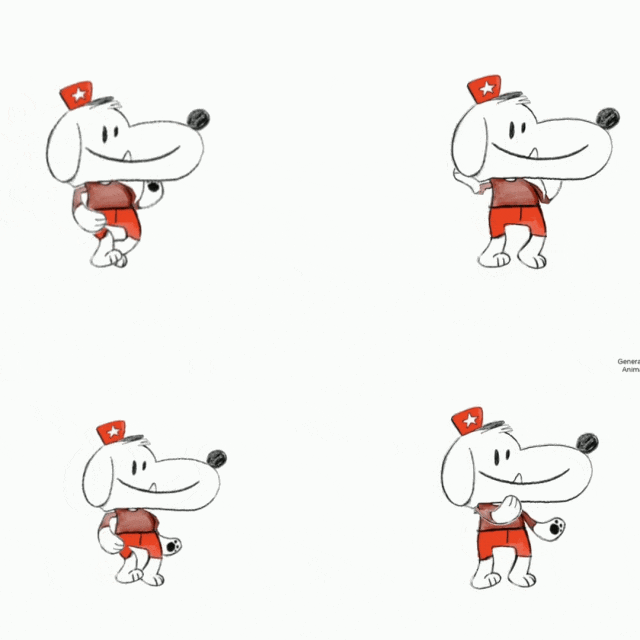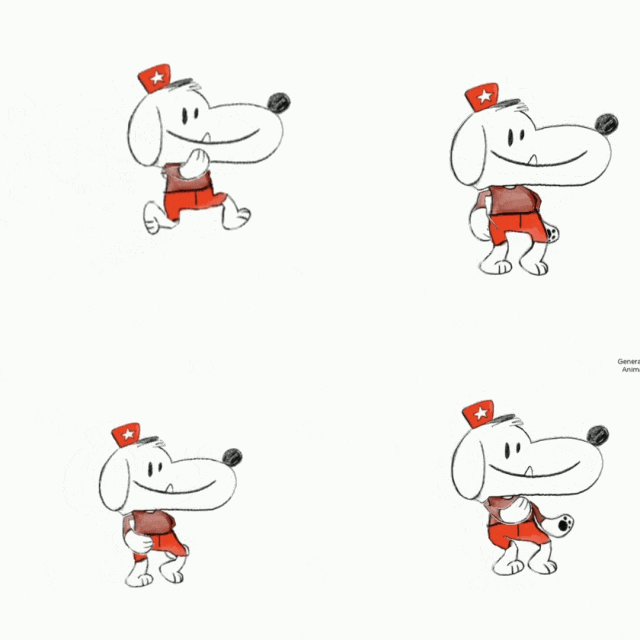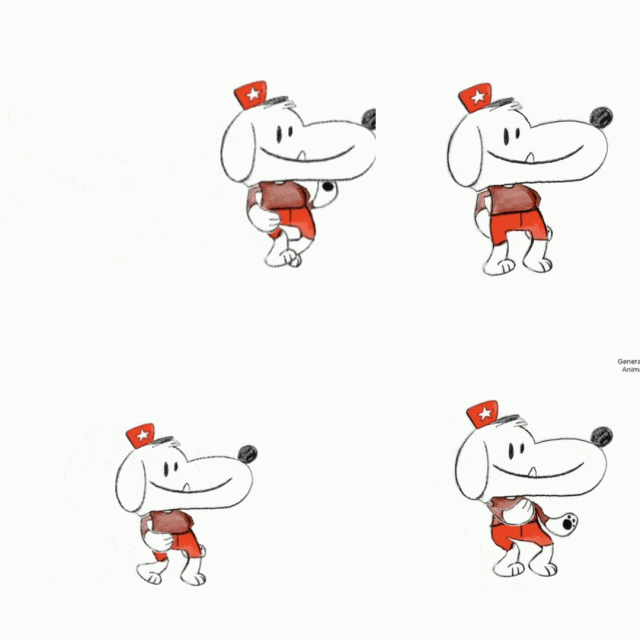
其玩法也很简单,访问上述链接,上传图片。
为了保证最佳生成效果,上传的图片最好满足以下要求:
-
图片中的主角,胳膊和腿儿不能与身体重叠;
-
确保角色绘制在干净、没有线条、皱纹或撕裂的白纸上。
-
图片画质要清晰,主角不能过小,不要有阴影,给涂鸦拍照时可以保持相机距离较远,并放大画作。
-
不要使用任何可识别信息、冒犯性内容或侵犯他人版权的图画。

AI 会自动识别角色,并用方框将其围起来,调整方框的大小以确保它紧贴角色。

然后,AI 自动分离角色与背景,如果 AI 无法正确识别,我们还可以用「钢笔」和「橡皮擦」按钮手动微调;若是胳膊、腿粘在一起,也使用橡皮擦工具将它们分开。
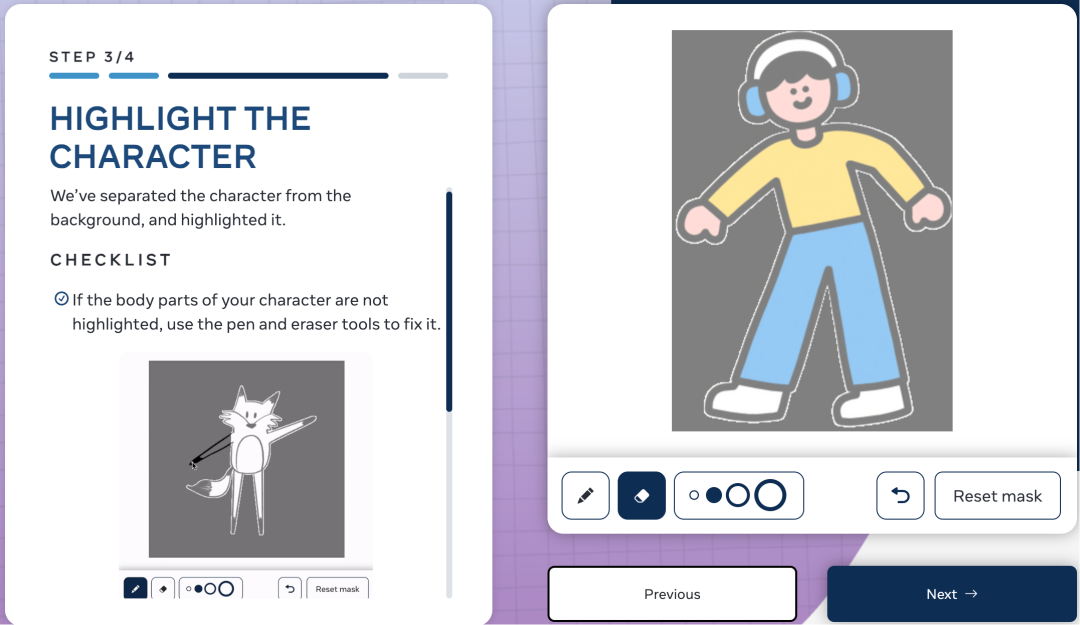
标记角色关节,方便下一步通过运动捕捉数据制作动画。如果角色没有胳膊,则将肘部和腕部的关节点拖远,它仍然可以制作动画。

最后,我们使用官方提供的 32 种动画模版,让角色动起来,包括走、跑、跳以及其他各种奇葩的姿势。
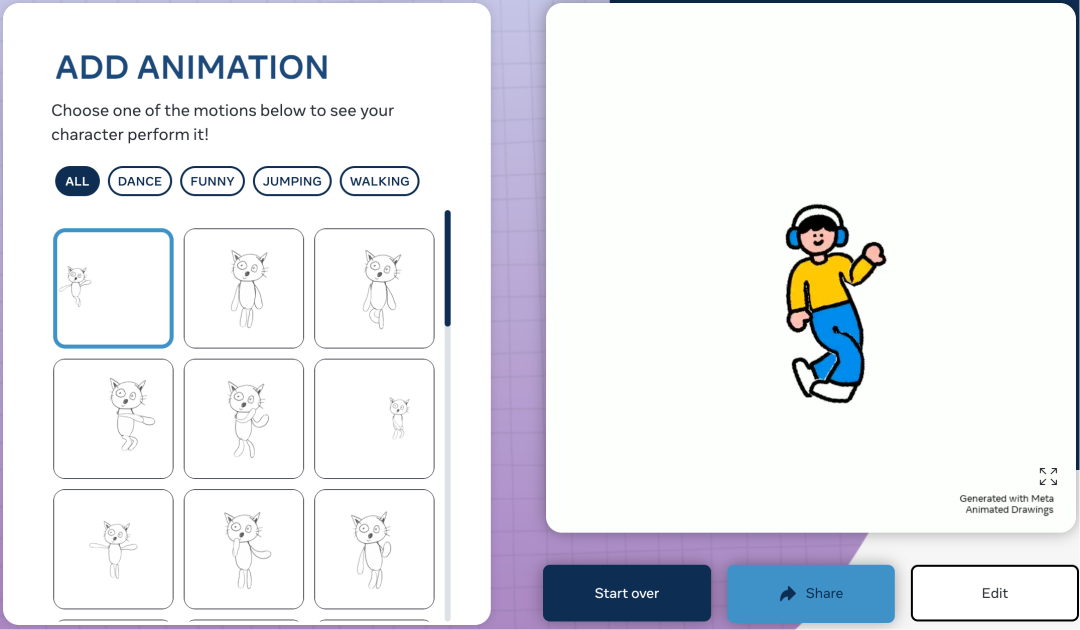
来看看效果:
小朋友们快去体验一波吧。
工具链接:
可灵:
https://app.klingai.com/cn/
即梦:
https://jimeng.jianying.com/ai-tool/home/
Veo3:
https://gemini.google.com/
Animated Drawings:
https://sketch.metademolab.com/

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com