清华等团队详尽综述200+语音分离论文,系统解析“鸡尾酒会问题”研究,涵盖深度学习方法、模型架构、挑战与未来趋势,为理解前沿进展提供全面视角。
原文标题:语音分离最全综述来了!清华等团队深度分析200+文章,系统解析「鸡尾酒会问题」研究
原文作者:机器之心
冷月清谈:
该综述首先从宏观角度定义了语音分离任务,根据混合说话人数量是否已知,分为已知人数分离和未知人数分离,并提出了各自的挑战,如输出顺序不确定的“排列歧义”问题。
在学习范式方面,论文详细对比了有监督和无监督学习方法。有监督学习是目前最成熟的范式,其中排列不变训练(PIT)和深度聚类(DPCL)是解决标签置换问题的经典方案。无监督学习(包括自监督)则探索在不依赖纯净源数据的情况下训练模型,如MixIT通过巧妙设计损失函数实现无标签训练,为数据稀缺场景提供了新思路。
模型架构部分系统性地总结了从基于RNN、CNN到基于自注意力的Transformer及其变种的演进路线,以及混合架构的优势,强调了架构创新对性能提升的驱动作用。同时,评估指标和数据集部分则为研究者提供了衡量模型性能和选择适用场景的依据。
实验结果显示,语音分离技术在标准数据集上的表现持续提升,例如WSJ0-2mix数据集上的SDR指标逐年提高,部分先进模型已接近理论上限。然而,在含噪声和混响的复杂场景下,性能仍有显著下降,表明鲁棒性仍是重要挑战。
最后,综述展望了未来的研究方向,包括长时段音频处理、移动端和嵌入式应用中的轻量化模型、因果(实时)语音分离、生成式方法(GAN、扩散模型)的应用、预训练技术、目标说话人提取以及与其他任务的联合建模,为领域发展指明了方向。
怜星夜思:
2、语音分离领域现在也开始引入预训练模型了,像文章里提到的wav2vec 2.0。大家觉得这会给传统的语音分离方法带来哪些颠覆性的影响?会不会出现“通用语音分离模型”?
3、文章里提到了SDR之类的客观评价指标已经接近上限,但实际听感上,分离出来的语音有时候还是会有点“不自然”。大家觉得要达到真正“完美”的语音分离,除了这些客观指标的提升,还需要解决哪些问题?
原文内容

语音分离领域针对具有挑战性的 “鸡尾酒会问题”,随着深度神经网络 (DNN) 的发展,该领域取得了革命性的进展。语音分离可以用于独立应用,在复杂的声学环境中提高语音清晰度。此外,它还可以作为其他语音处理任务(如语音识别和说话人识别)的重要预处理方法。
为了应对当前的文献综述往往只关注特定的架构设计或孤立的学习方法,导致对这个快速发展的领域的理解碎片化的现实情况,清华大学、青海大学、南京大学、南方科技大学、中国科学院大学、字节跳动的研究者们全面调研了该领域的发展和最前沿的研究方法,在深度学习方法、模型架构、研究主题、评测指标、数据集、工具平台、模型效果比较、未来挑战等多个维度,撰写了一项统一、全面的综述论文,对 200 余篇代表性论文进行了系统归纳和分析。

表1 基于深度学习的语音分离最新调查与综述的比较分析

-
论文链接:https://arxiv.org/abs/2508.10830
-
Methods Search:https://cslikai.cn/Speech-Separation-Paper-Tutorial/
-
Github链接:https://github.com/JusperLee/Speech-Separation-Paper-Tutorial
问题定义
作者们从语音分离领域的宏观角度出发,根据混合说话人数量是否已知将已知人数分离和未知人数分离两类。当说话人数固定且已知时,网络输出固定个数的通道,可以通过深度聚类 (Deep Clustering) 或 Permutation Invariant Training(PIT,排列不变训练)等策略解决输出顺序不确定的 “排列歧义” 问题。对于未知人数的情况,模型需要动态决定输出通道数并判断何时结束分离。这带来巨大挑战:如说话人排列组合随人数增加呈指数扩展、需要在分离质量与终止时机之间权衡避免欠分离或过分离等。为应对这些问题,研究者提出了递归分离、动态网络等框架来逐步提取不定数量的声源。作者们从问题定义部分明确了语音分离任务的目标和难点,为后续技术讨论奠定了基础。
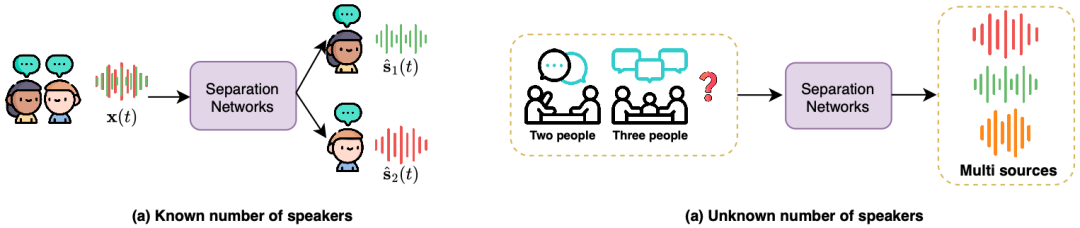
图 1 已知 / 未知声源数量的语音分离概述。
学习范式
作者们分类总结了学习范式,比较了不同方法的适用场景和优缺点,为读者理解监督与非监督方法在语音分离中的权衡提供了清晰脉络。重点对比了有监督和无监督(含自监督)学习方法。有监督学习利用配对的混合音频及纯净源音频进行训练,是目前最成熟的范式。针对有监督训练中不同源输出无法一一对应的标签置换问题,研究者提出了两类经典方案:
一是深度聚类方法(DPCL),通过神经网络将混合语音的时频单元映射到高维嵌入空间,再将嵌入向量聚类以生成每个声源的掩膜,从而避免直接输出固定顺序的源信号;
二是 Permutation Invariant Training(PIT)方法,在训练时对网络输出的来源标签进行动态匹配,只保留误差最小的排列来更新模型,从而使网络学习到与输出排列无关的分离能力。
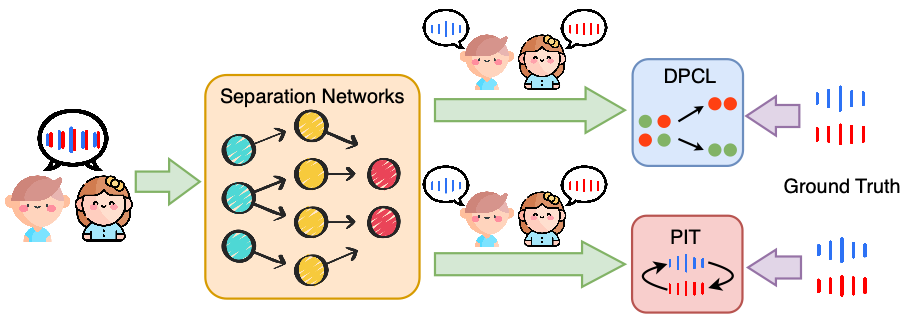
图 2 受监督的语音分离工作流程。
无监督学习则不依赖配对的干净源参考,探索利用未标注的混合语音直接训练分离模型。例如,MixIT(混合 - 分离训练)方法通过将两段混合语音再混合作为输入,让模型输出更多分量并设计损失函数仅依赖输入混合物,实现无需纯净源标签的训练。这类方法以及基于生成模型的自监督策略(如变分自编码器 VAE 方法、扩散模型等)为无法获得干净训练数据的场景提供了新思路。
模型架构
模型架构部分系统总结了语音分离模型的核心组成和演进路线。典型架构包含编码器、分离网络和解码器。
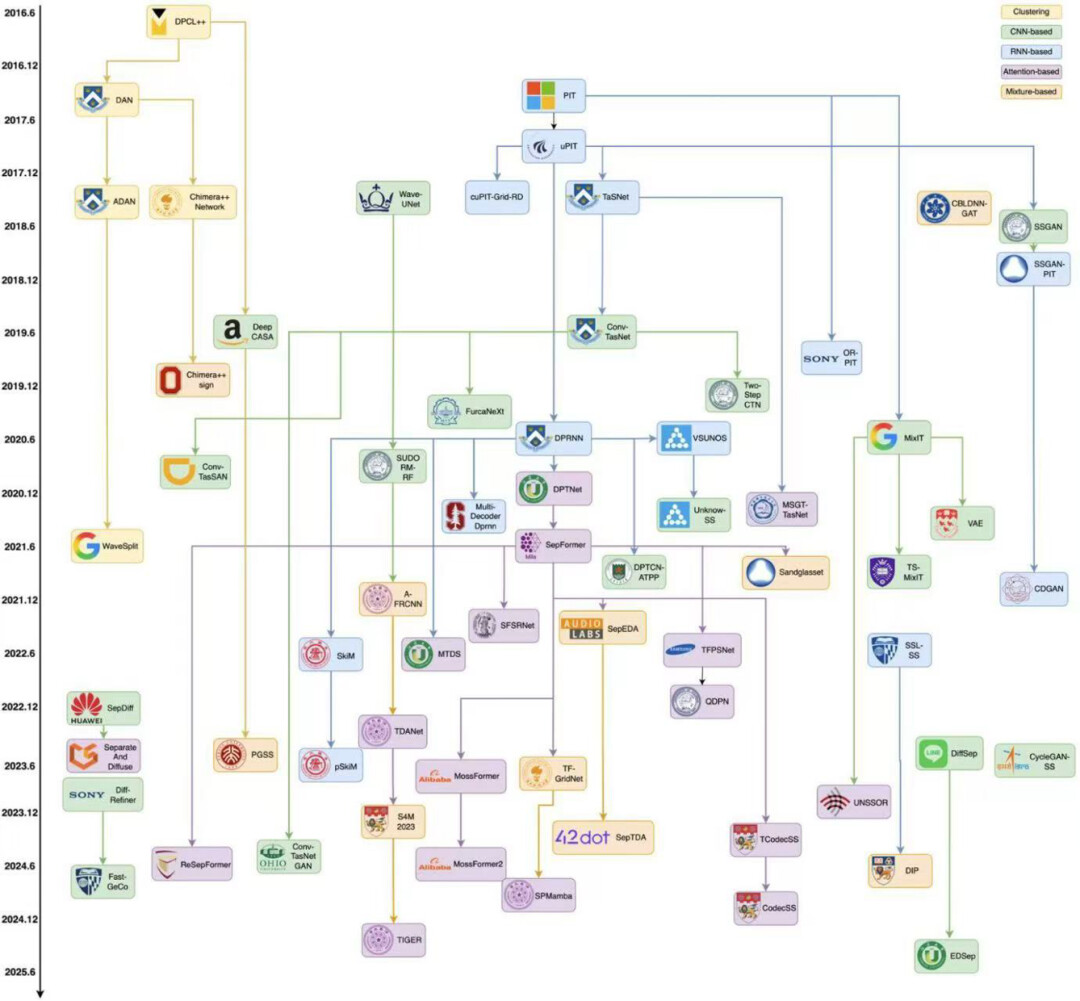
图 3 不同方案的发展脉络
综述按网络类型归纳了主要的分离器架构:
基于 RNN 的模型利用循环神经网络擅长捕获语音信号中的长时依赖关系。早期很多方法在频域用双向 LSTM 生成掩膜;后来出现直接处理时域波形的端到端模型(如 TasNet 系列 ),避免了相位重建难题并提升效率。代表性的 Dual-Path RNN(双路径 RNN)通过划分长序列为短块并在块内和块间双路径循环处理,高效建模长序列,被视为 RNN 架构的里程碑。
基于 CNN 的模型利用卷积神经网络强大的局部特征提取能力,适合直接对原始波形建模。Conv-TasNet 等时域卷积模型通过空洞卷积等技术兼顾短时细节和长程依赖,在无需频域处理的情况下取得了优异分离效果。基于自注意力的模型(Transformer 及其变种)引入了全局序列建模能力,在语音分离中用于捕获长距离依赖并建模复杂场景下源间关系。
近年来出现的 SepFormer 等 Transformer 架构进一步刷新了分离性能。还有混合架构将上述优势结合,例如将 CNN 的局部建模和 RNN/Transformer 的长程建模相融合,以兼顾不同尺度的信息。
除了分离网络,综述还讨论了音频重构策略:一类是掩膜估计,即模型输出每个源的时间频率掩膜,乘以混合后再重建源信号;另一类是直接映射,即模型直接输出各源的波形或特征表示。掩膜方法简单直观且易于结合频域特征,而直接法避免误差传播,有望获取更高保真度。
总体而言,本节脉络清晰地展现了模型架构从早期循环网络到卷积、再到自注意力和混合模型的演进,以及各种重构方式的权衡,凸显了架构创新对性能提升的驱动作用。
评估指标
评价语音分离效果需要科学全面的指标体系,以便衡量模型性能、指导算法优化并确保满足实际应用需求。该综述将评估指标分为主观和客观两大类。综述对比了各种指标的优劣:主观评价贴近人耳体验但难以大规模获取,客观指标高效客观但各自侧重不同方面,需要结合使用。综合运用主客观评价能够更完整地刻画语音分离系统的性能,为研究和应用提供可靠依据。
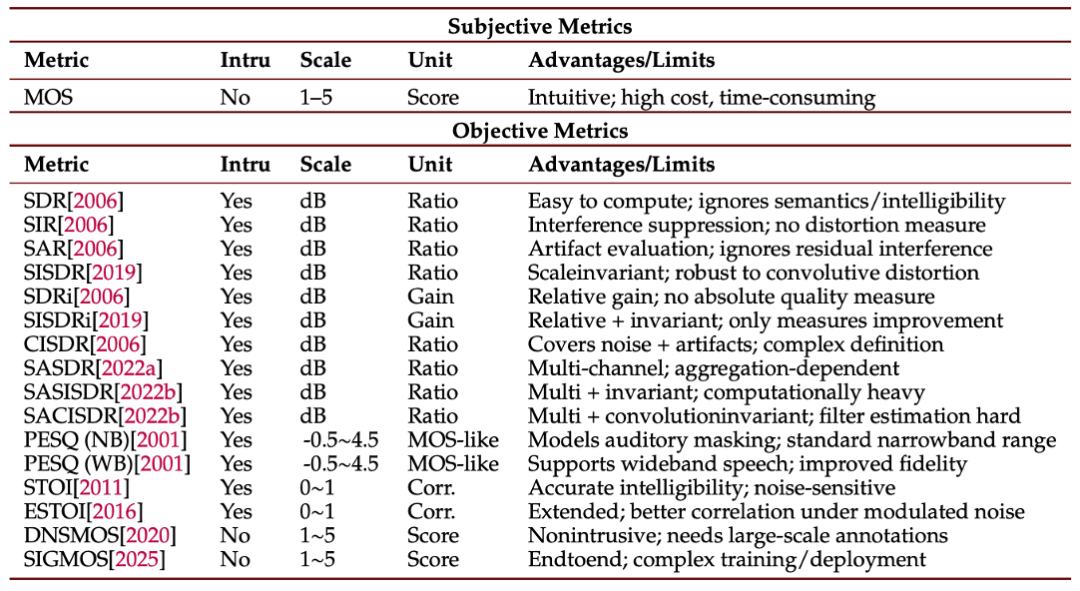
表 2 不同评价指标的对比
数据集
公开数据集为语音分离研究提供了标准测试,他们按照单通道和多通道对主流数据集进行了总结。通过对数据集的梳理,研究者可以了解各数据集所覆盖的场景和难度,有助于选择合适的数据集来评估算法并发现当前研究还未覆盖的场景(例如更长时段对话、开放域噪声环境等),从而指导未来数据收集和模型开发。
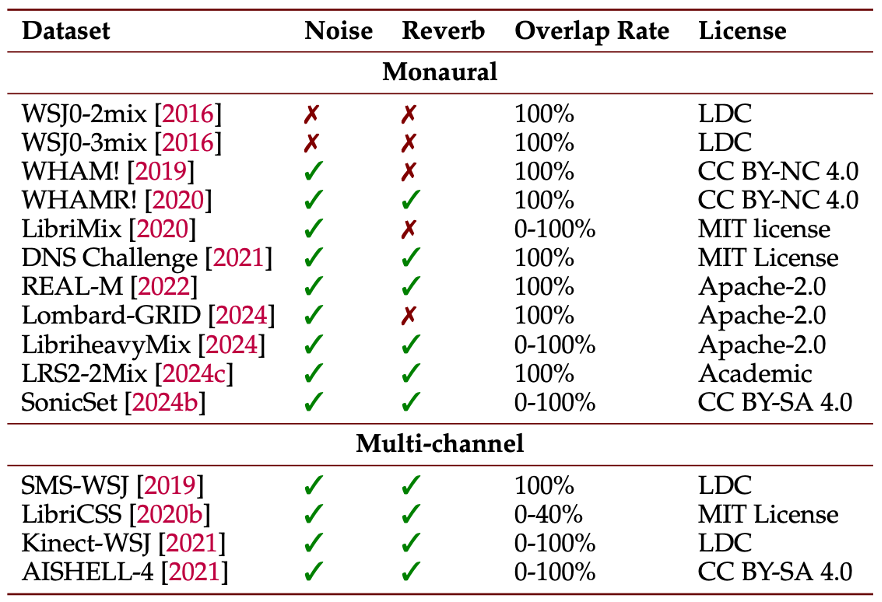
表 3 不同数据集的比较
实验结果
他们汇总了不同模型在各标准数据集上的分离性能对比,勾勒出语音分离技术近年来的进步轨迹。作者列举了众多具有代表性的模型在若干公开基准上的评测结果,并通过图表展示性能随时间的提升趋势。
例如,在经典数据集 WSJ0-2mix 上,早期模型(如 DPCL、uPIT-BLSTM 等)能达到约 10 dB 的 SDR;随后基于深度学习的端到端模型(如 Conv-TasNet)将性能推升到 12 dB 以上;最近两三年的先进架构(如 SepFormer、DPRNN 系列、双路 Transformer 等)更是将 SDR 提升到 20 dB 左右,接近定量评测所能达到的上限。这些结果直观证明了架构创新和训练范式改进对分离效果的巨大推动作用。
不仅如此,综述还比较了模型在不同数据集上的表现差异:例如在含噪声混响的 WHAM! 和 WHAMR! 上,模型性能相对无噪条件下降明显,说明噪声鲁棒性仍是挑战;这种多维度的结果对比帮助读者了解各类方法的优势和局限:有的模型在干净近场语音下接近完美,但在远场或噪声场景下性能下滑;有的方法擅长分离两三人对话,但扩展到更多说话人时代价巨大。通过统一的结果汇总与分析,作者提供了对当前最先进技术水平的客观评估,并据此指出了亟待攻克的薄弱环节。
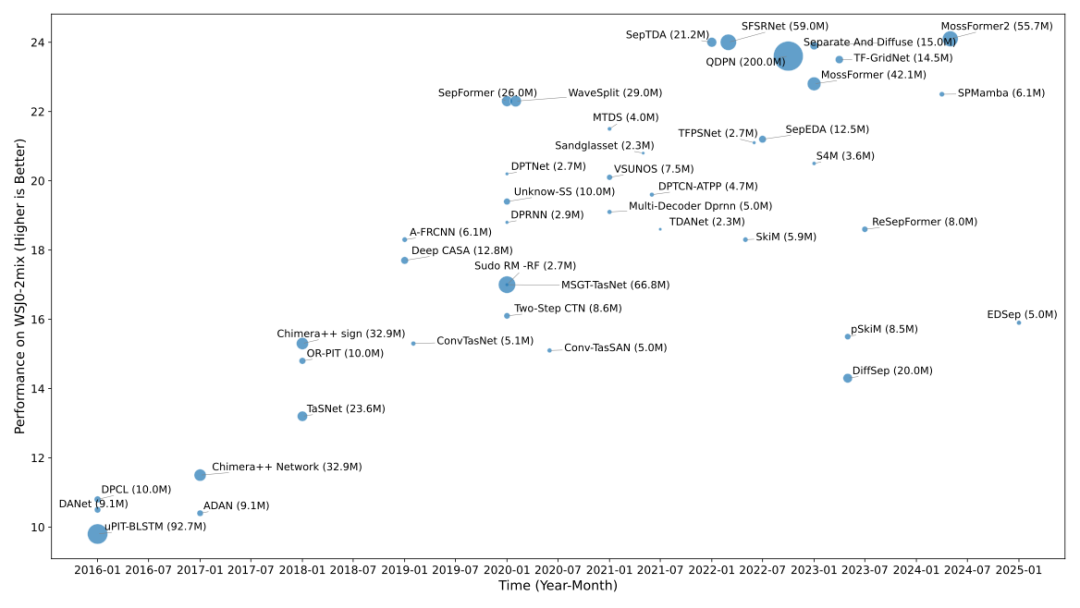
图 4 语音分离模型在 WSJ0-2mix 上随时间的变化表现
工具平台
为了推动研究复现和应用落地,综述还介绍了当前常用的开源工具和平台,这些软件库为语音分离任务提供了便利的开发接口和训练框架。对比了各工具的功能侧重点,例如有的注重学术研究易用性,有的侧重工业优化和实时性能,也指出了当前工具链存在的局限,如对最新算法的支持仍需跟进等。通过了解这些平台,研发人员可以更高效地复现论文结果、搭建原型系统,加速从研究到应用的转化。
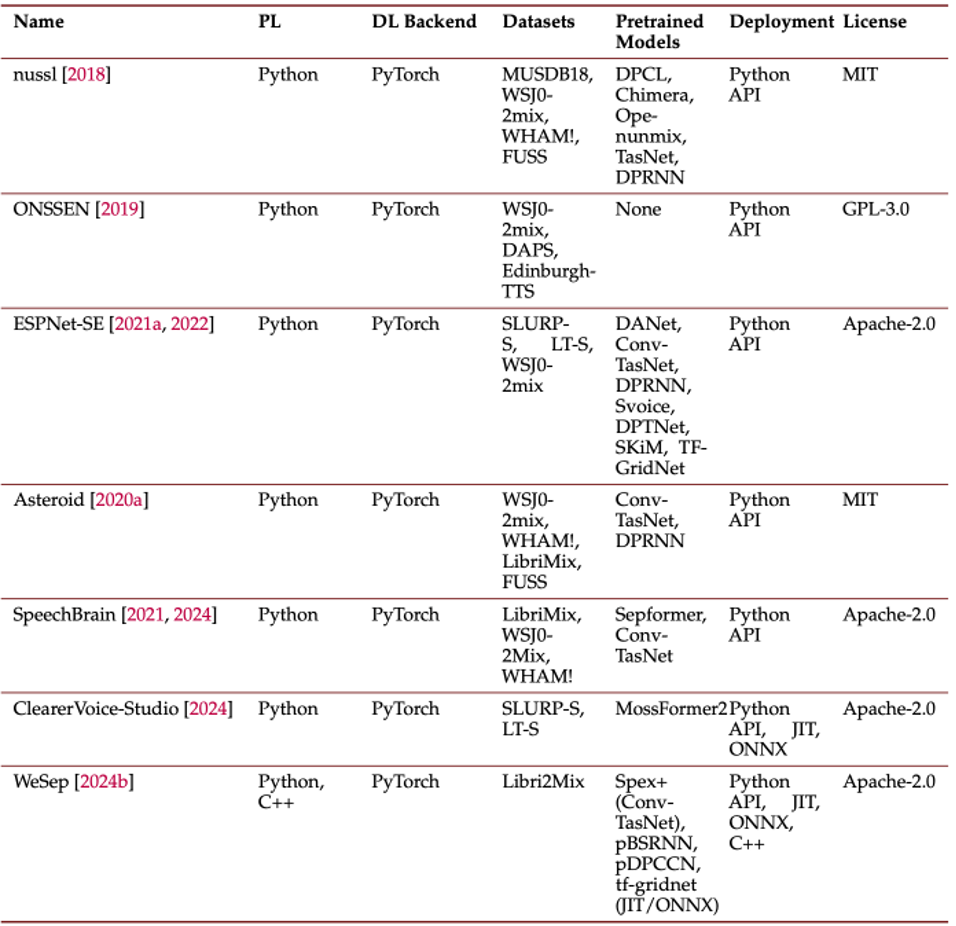
表 4 不同开源工具的对比
挑战与探索
在对现状全面总结的基础上,深入讨论了语音分离领域当前存在的热点难题和未来可能的探索方向。
首先,长时段音频处理,在实际应用中(如会议记录、连续对话)需要处理数分钟甚至更长的音频,如何在保证分离连续性的同时控制模型复杂度和内存开销。
其次,移动端和嵌入式应用要求分离模型具备较小的参数量和计算量,因此研究者正探索剪枝、量化、知识蒸馏以及新的高效架构(如高效卷积、高效自注意力等)来减小模型体积,同时维持性能。
第三,因果(实时)语音分离也是热点之一:实时通信和在线处理要求算法只能利用当前及过去帧的信息,不能窥视未来,这对模型的延时、缓存机制提出严格要求。如何在严格的因果约束下仍然取得接近离线模型的分离效果。
第四,生成式方法的崛起为语音分离提供了新思路:包括生成对抗网络(GAN)和扩散模型在内的新型生成模型开始用于语音分离,以期生成更逼真的语音并改善分离质量,尤其在弱监督或无监督场景下展示出潜力。
第五,预训练技术正逐步引入本领域:借鉴 ASR 等领域的成功,大规模自监督预训练(如 wav2vec 2.0 等)或基于音频编码器的预训练模型可以提供强大的通用特征,在低资源分离任务上显著提升性能。未来可能出现专门针对语音分离预训练的模型或利用语音神经编码器压缩感知混合信号的新范式。
第六,目标说话人提取作为语音分离的变种也备受关注:即利用已知的目标说话人特征(如说话人注册音频)从混合中提取该说话人的语音,相比盲分离加入了先验信息,如何高效利用目标说话人嵌入并与分离网络融合是研究重点。最后,综述强调了与其他任务的联合建模趋势:语音分离正日益与语音识别、说话人识别 / 分离、语音增强等任务结合,形成端到端的联合优化框架。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com