苹果BED-LLM新研究:无需重训,AI提问智能提升6.5倍,解决LLM“遗忘症”!
原文标题:苹果新研究:不微调、不重训,如何让AI提问效率暴增6.5倍?
原文作者:机器之心
冷月清谈:
怜星夜思:
2、这种让AI更主动、更精准提问的能力,在数据隐私、信息茧房或AI伦理方面可能带来哪些新的挑战或机遇?
3、文章提到BED框架通过“预期信息增益(EIG)”来选问题,这和我们平时训练AI时常用的“梯度下降”或者强化学习中的“探索-利用”策略有什么底层联系或区别?是不是可以理解成一种更高级的“探索”机制?
原文内容
编辑:Panda
在这场以大型语言模型(LLM)为核心的 AI 浪潮中,苹果似乎一直保持着低调,很少出现在技术报道的前沿。尽管如此,时不时地,该公司也能拿出一些非常亮眼的研究成果,比如能在 iPhone 上直接运行的高效视觉语言模型 。
近日,苹果与牛津大学和香港城市大学合作的一项新研究吸引了不少关注。其中提出了一种名为 BED-LLM 的新方法,能让 AI 解决问题的能力直接提升 6.5 倍(成功率从 14% 暴增至 91%),而整个过程无需微调或重新训练,直接在当前模型上运行即可。
而实现这一突破的关键,便是让 AI 学会问出完美的问题。

那么,究竟该如何做到这一点呢?

-
论文标题:BED-LLM: Intelligent Information Gathering with LLMs and Bayesian Experimental Design
-
论文地址:https://arxiv.org/abs/2508.21184
这要从 LLM 的一个不足之处说起,即难以智能且自适应的方式主动从用户或外部环境中获取信息。这就像是 LLM 的「多轮遗忘症」。
具体而言,虽然现代 LLM 通常能够一次性生成连贯且富有洞察力的问题(或其他外部查询),但它们通常难以根据先前在交互式任务中收集到的答案进行适当的调整。比如,已有研究证明,LLM 在多步猜谜游戏、任务澄清、IT 任务自动化以及迭代式外部工具使用等问题上表现不佳。
因此,提高 LLM 自适应地提出问题和有针对性地收集信息的能力是很有必要的。
简单来说,LLM 仅仅基于其庞大的知识库一次性生成好问题是不够的。真正的智能体需要能根据用户的实时反馈,动态调整策略,精准地提出下一个最有价值的问题 。
BED-LLM:让提问成为一门科学
牛津、苹果和香港城市大学的这个联合团队提出,可以使用序贯贝叶斯实验设计(Bayesian experimental desig/BED)框架来解决这一问题。
该框架提供了一种基于模型的信息论机制,可用于在给定实验的生成模型的情况下做出自适应设计决策。
具体而言,该团队展示了如何将使用 LLM 进行交互式信息收集的问题表述为一个序贯实验设计问题,其中有一个迭代过程:
-
每次选择要问的问题(query),都要尽量最大化预期信息增益(Expected Information Gain, EIG)。
-
根据用户的回答更新信念(belief)。
-
再基于新的信念选择下一步要问的问题。
这就像科学实验:一步步设计实验、收集数据、更新假设,而不是一次性问到底。
这里,构成序贯 BED 程序的底层生成模型源自 LLM,该团队特别展示了该模型的构建方式,并为关键设计决策提供了广泛的见解。
该团队将这种方法命名为 BED-LLM,即 Bayesian Experimental Design with Large Language Models。
这种名为 BED-LLM 的方法之所以高效,源于其背后三重智慧的巧妙设计:
智慧一:追求真正的信息增益,而非表面上的不确定性
过去的方法常常让 AI 选择自己「感觉最不确定」的问题,但这并非最优解。BED-LLM 的核心是精确计算 EIG,确保问题能带来最大价值。
论文中一个生动的例子可以说明这一点 :假设 AI 想了解你的电影偏好,它有两个问题可选:
-
问题 A:「你最喜欢什么口味的冰淇淋?」
-
问题 B:「你最喜欢哪种电影类型?」
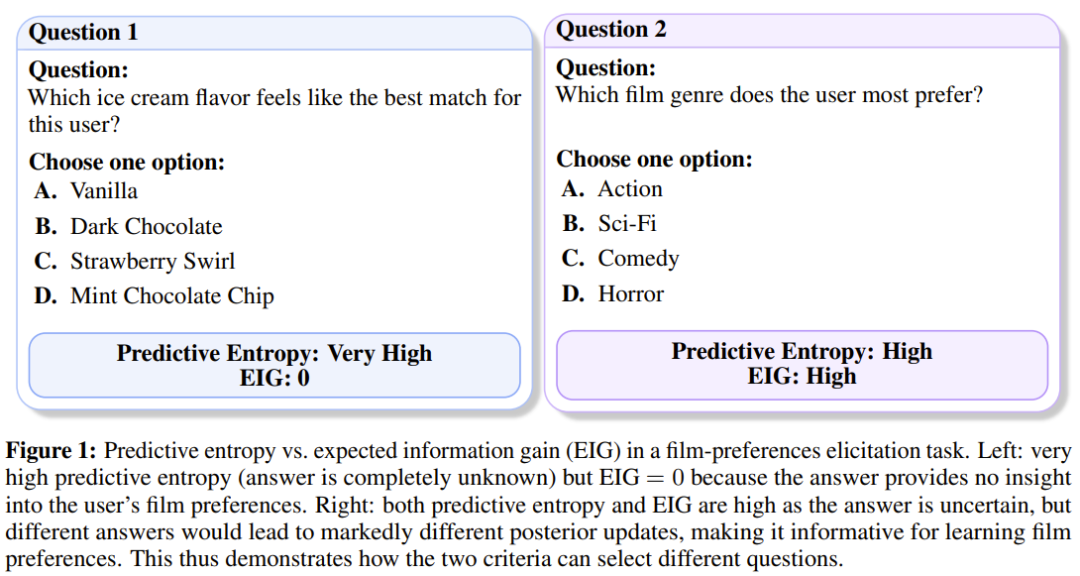
对于问题 A,AI 可能完全猜不到答案(即预测熵很高),但这个答案对于了解你的电影品味毫无帮助(EIG 为 0) 。而问题 B 的答案虽然也不确定,但无论你回答「科幻」还是「喜剧」,都能极大地帮助 AI 缩小猜测范围,因此它的 EIG 非常高 。BED-LLM 正是基于这种原则来选择问题的。
智慧二:强制逻辑自洽,纠正 LLM 的遗忘症
研究发现,即便是 GPT-4o 这样顶尖的模型,在多轮对话中也常常会忘记之前的约束,提出与历史回答相矛盾的假设 。
BED-LLM 引入了先采样后过滤 (sample-then-filter) 策略来解决这个问题。
它首先让 LLM 生成一批可能的答案(例如,在猜名人游戏中生成多个候选人),然后用一个「逻辑过滤器」逐一检查这些答案是否与用户之前的所有回答都兼容,将不符合逻辑的选项直接剔除。这确保了 AI 的每一步推理都建立在已知的事实之上。
智慧三:生成问题有的放矢,而非天马行空
在生成候选问题时,BED-LLM 采用了一种更具针对性的条件生成 (Conditional generation) 策略 。它会先参考当前已经过筛选、逻辑自洽的假设池,然后让 LLM 提出能够最高效「切分」这些假设的问题 。这使得提问从一开始就目标明确,直指核心。

结果如何?
为了验证 BED-LLM 的效果,研究团队将其与两种主流基准进行了对比:
-
Naive QA:完全依赖 LLM 的「直觉」来提问。
-
Entropy:采用简化的 EIG 版本,即只考虑预测不确定性的方法 。
结果显示,无论是在「20 个问题」猜谜游戏还是电影偏好推荐任务中,BED-LLM 的表现都全面超越了基准方法 。
具体而言,该团队首先发现,BED-LLM 在各种 LLM 和目标数量下,显著提升了 20 个问题问题的成功率。例如,在使用 Mistral-Large 预测名人时,该团队观察到成功率从 14% 提升至 91%。
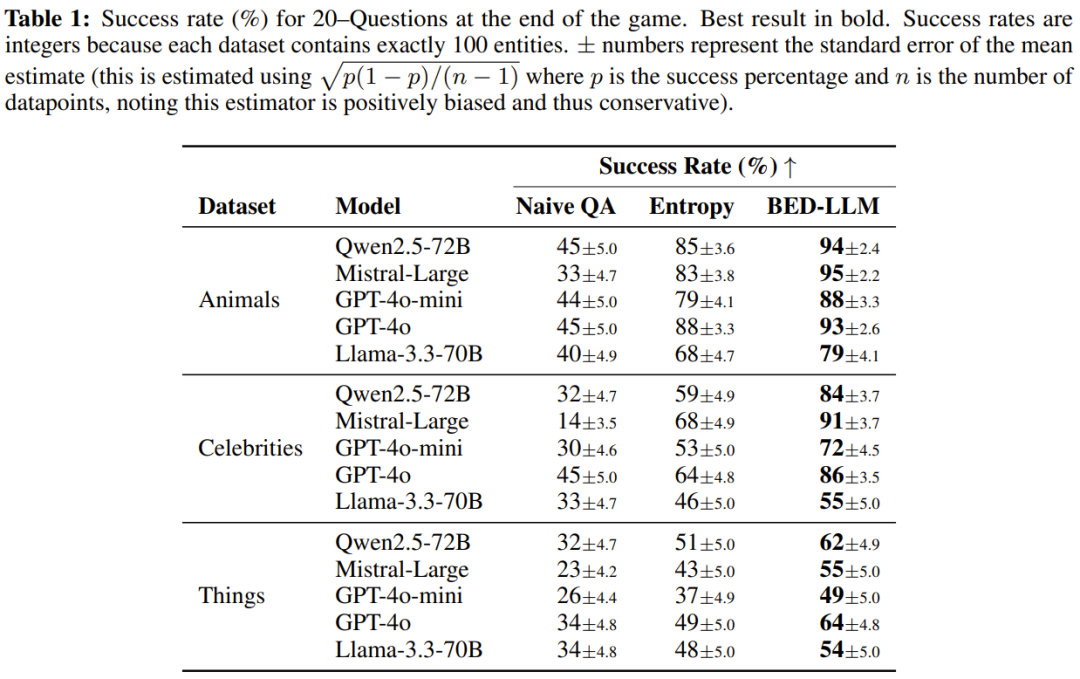
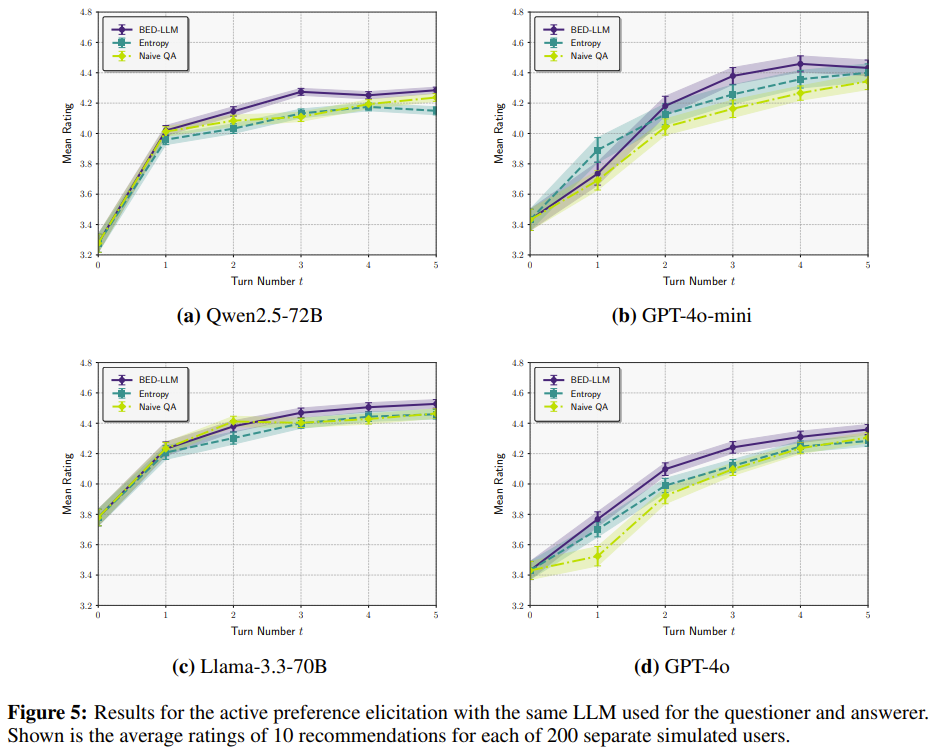
其次,该团队展示了 LLM 在电影推荐方面取得的显著改进,表明即使 LLM 的预测模型与回答者的预测模型不同,这些优势依然有效。
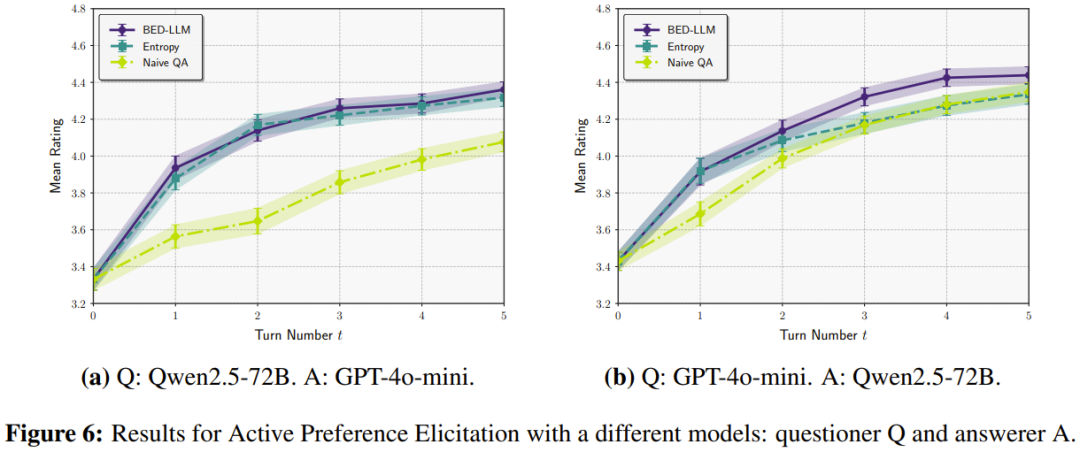
更具现实意义的是,研究团队还进行了一项「模型跨服聊天」的压力测试:让提问的 AI 和回答的 AI 使用完全不同的模型(例如,提问方是 Qwen,回答方是 GPT-4o-mini)。
这种设置更贴近真实世界,因为用户的思维模型与 AI 本就不同。即便在这种「模型失配」的情况下,BED-LLM 的性能优势依然稳固,展现了其强大的稳健性。
总而言之,这项研究为我们展示了如何通过严谨的数学框架,将 LLM 从一个被动的知识问答库,转变为一个主动、高效、且具备逻辑推理能力的信息收集者。这或许预示着,未来的 AI 交互将不再是简单的一问一答,而是真正意义上的「智慧对话」。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com