通义实验室开源Mobile-Agent-v3,其GUI-Owl模型实现在桌面、移动和Web端的智能交互与任务执行,性能卓越。
原文标题:性能逼近闭源最强,通义实验室开源Mobile-Agent-v3刷新10项GUI基准SOTA
原文作者:机器之心
冷月清谈:
GUI-Owl模型具备“全栈 GUI 能力”,包括极致的UI元素定位(结合多维数据集和SAM+MLLM解决了PC端密集界面的定位难题)、深度的长任务规划与动作语义理解(融合历史经验和大规模语言模型知识),以及稳健的推理与泛化适配能力(通过多智能体框架蒸馏推理数据)。此外,团队还引入了可扩展的环境级强化学习(RL)体系,通过Trajectory-aware Relative Policy Optimization (TRPO) 算法解决长任务奖励稀疏问题,并利用Replay Buffer机制提升学习效率,确保模型在真实环境中持续稳定运行。
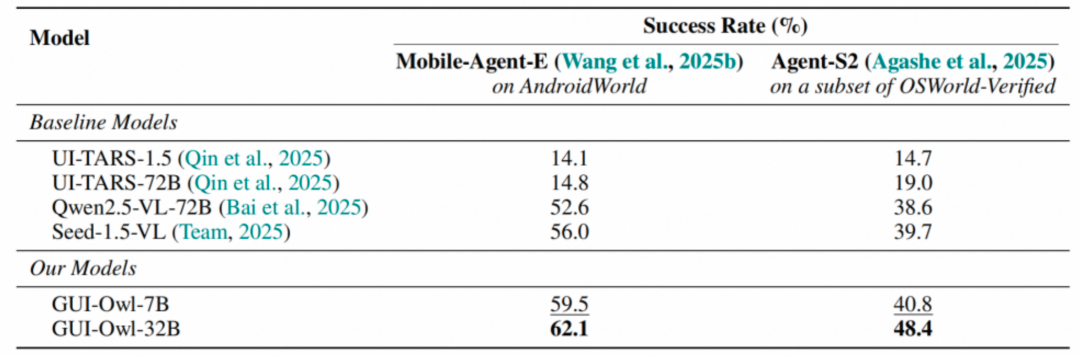
Mobile-Agent-v3在AndroidWorld、OSWorld等关键基准上刷新了开源模型的记录,其中32B版本在多项评测中性能已逼近甚至超越部分闭源顶级模型。这一单体模型不仅能胜任复杂的单一任务,还能在多智能体协作中扮演不同角色,显著降低了部署和资源开销。
怜星夜思:
2、文章强调了“自我进化 GUI 轨迹生产链路”的重要性,通过模型自己生成数据并优化。这种方式虽然高效,但会不会存在“AI自己教自己”导致陷入某种思维定势,或者在面对极端情况时缺乏人类的经验和常识?大家怎么看这种数据生产模式的局限性?
3、Mobile-Agent-v3开源了,这意味着更多开发者有机会接触和改进它。那么对普通开发者或者小型团队来说,如何将这种复杂的GUI Agent技术真正落地到自己的产品或服务中?有没有什么门槛是需要特别注意的?
原文内容

覆盖桌面、移动和 Web,7B 模型超越同类开源选手,32B 模型挑战 GPT-4o 与 Claude 3.7,通义实验室全新 Mobile-Agent-v3 现已开源。
一眼看到实力:关键成绩速览。
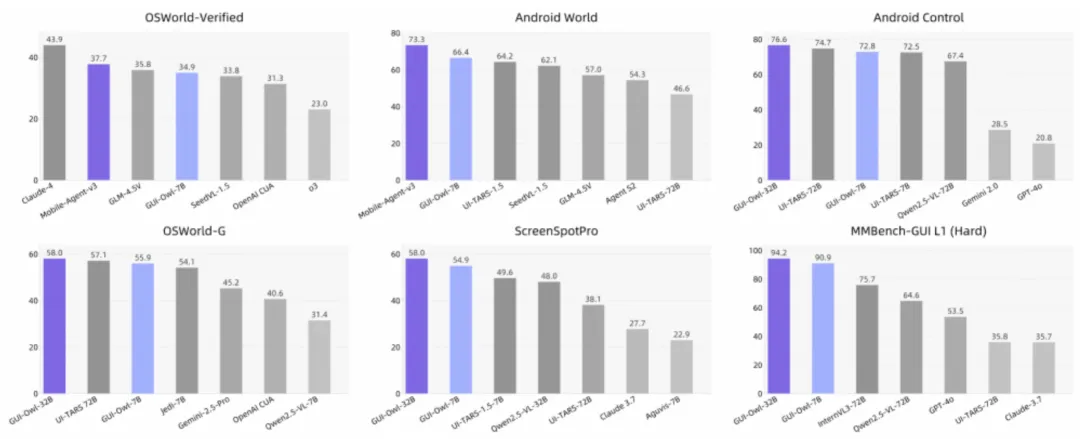
备注:分数来源于公开基准,包括桌面 + 移动环境的任务规划、定位、推理、执行等全链路能力
开源地址:https://github.com/X-PLUG/MobileAgent
背景:为什么 GUI Agent 要这么强?
GUI 智能体,就像你的跨平台虚拟操作员,能看懂屏幕、点鼠标、敲键盘、滑手机,在办公、测试、RPA 等场景自动执行任务。然而,要实现这一愿景,现有方案却面临重重挑战。它们往往能力割裂,比如精于定位 UI 元素却拙于长任务规划,或难以融入灵活的多智能体框架。
同时,许多方案严重依赖特定的硬件和操作系统,适配成本高昂;而依赖闭源模型的方案则缺乏灵活性,遇到全新任务时常常束手无策。
更现实的是,高昂的推理成本、多图输入带来的延迟以及部署困难,都成为阻碍 GUI 智能体广泛应用的瓶颈。
亮点一
GUI-Owl + Mobile-Agent-v3 + 云环境
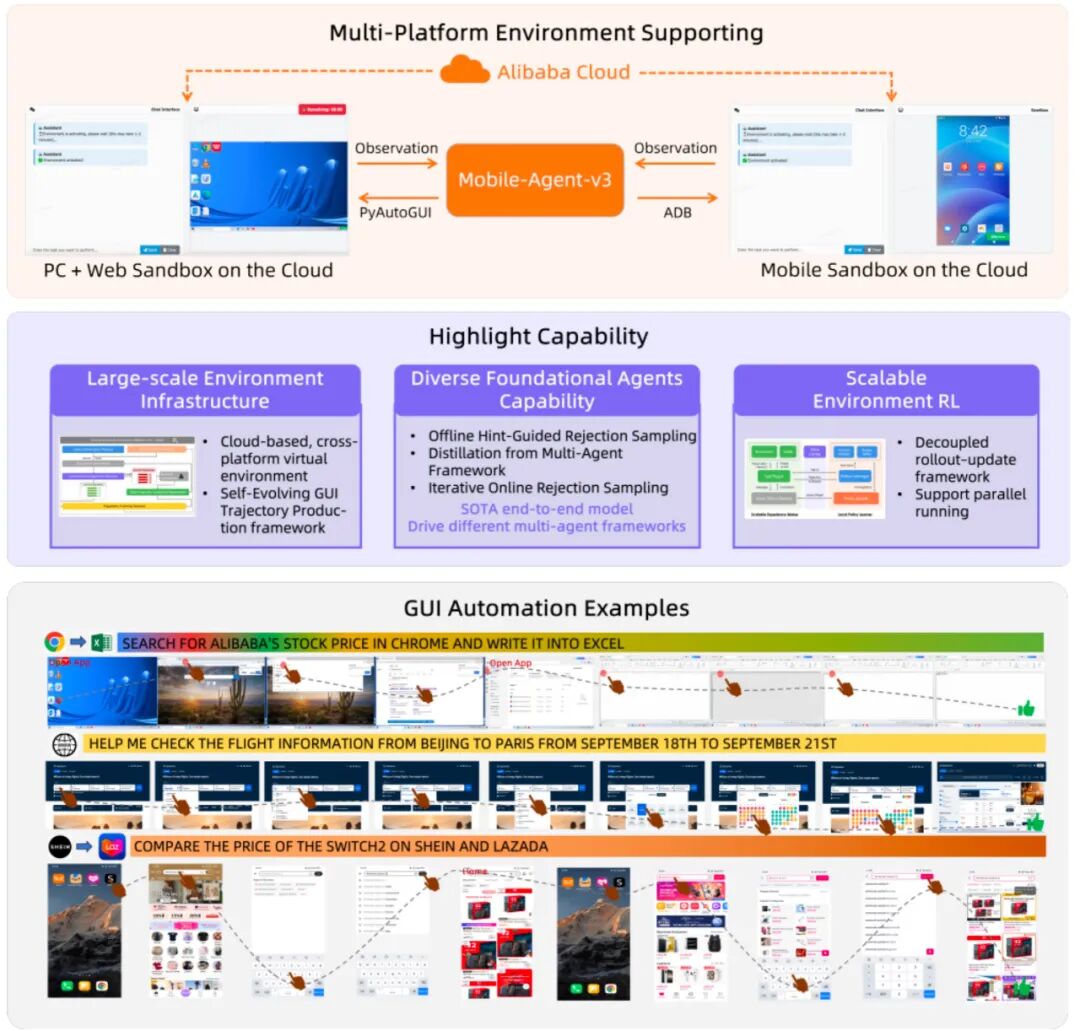
这是一个基于云环境的全链路开源解决方案 —— 它既是当前最强的开源单体 GUI Agent 模型,也包含为其深度优化的多智能体框架。我们通过搭建覆盖 Android、Ubuntu、macOS、Windows 的多操作系统云环境基础设施,并结合阿里云的云手机与云电脑,实现了直接在云端沙箱中运行、调试、采集数据的全新范式。
在大多数 GUI Agent 方案中,采集高质量训练数据是最大的瓶颈,不仅慢,而且贵。为此,我们没有走传统的人工标注老路,而是直接打造了一整套跨平台的云环境基础设施与一套名为「自我进化 GUI 轨迹生产链路」的数据闭环系统。这套系统让 GUI-Owl 和 Mobile-Agent-v3 自己生成任务轨迹、筛选出正确轨迹,再反过来对自身进行迭代优化,将人类的参与降到最低,形成一个跨平台、自动化、可持续的数据生产与模型优化循环。
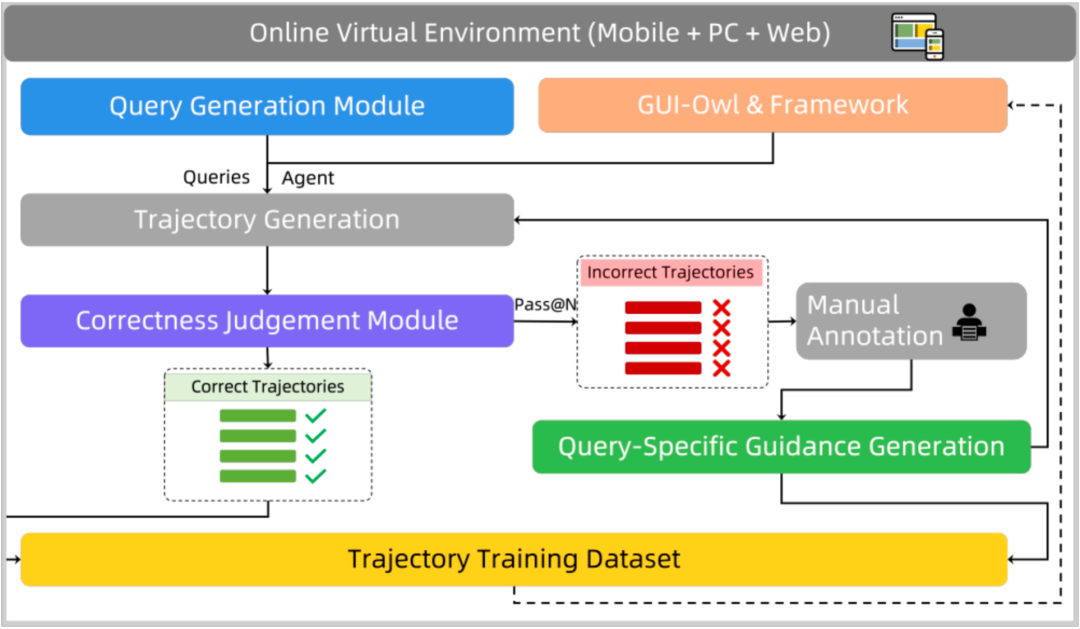
整个流程的核心是让模型在实践中自我成长。 首先,系统会在覆盖 Android、Ubuntu、macOS 和 Windows 的云端环境中动态构建虚拟实验室,确保每次任务都在贴近真实用户场景的干净快照中运行。随后,高质量的任务生成模块会为模型「出题」,它针对移动端,通过人工标注的有向无环图(DAG)来模拟真实 App 流程,并用 LLM 生成多约束的自然语言指令;而对于元素更密集的桌面端,它则结合可访问性树(Accessibility Tree)与深度搜索链来挖掘复杂软件的操作路径,确保生成的任务既真实又可控。
有了任务,GUI-Owl 模型和 Mobile-Agent-v3 框架便开始在虚拟环境中执行操作,产出完整的交互轨迹。然而,并非所有轨迹都是完美的。因此,一个精密的轨迹正确性评估模块会介入,它包含一个「Step-Level Critic」,能细致分析每一步操作前后的界面变化,判断其有效性;还有一个「Trajectory-Level Critic」,采用纯文本和多模态双通道机制,从全局视角评估整个任务是否成功。只有通过双重校验的轨迹才会被采纳。
对于那些模型反复尝试依旧失败的困难任务,系统还会启动困难任务指南生成模块。它会分析已有的成功轨迹(可能来自人工或其他模型),用 VLM 提炼出每一步的关键动作描述,并由 LLM 总结成一份「通关攻略」。这份指南将在后续尝试中作为提示,有效提高成功率。最后,所有经过筛选和强化的优质轨迹数据,都会被用于对 GUI-Owl 进行强化学习微调,让模型的能力在真实交互中稳步增强,最终实现真正的自我进化。
亮点二:全栈 GUI 能力构建
从「看得懂」到「想得全」到「做得准」
GUI-Owl 在安卓和桌面两端同时拿下 SOTA,关键在于我们为其构建了全栈式的 GUI 能力,确保它不仅「看得懂」,更能「想得全」、「做得准」,并具备天然的泛化与适配能力。
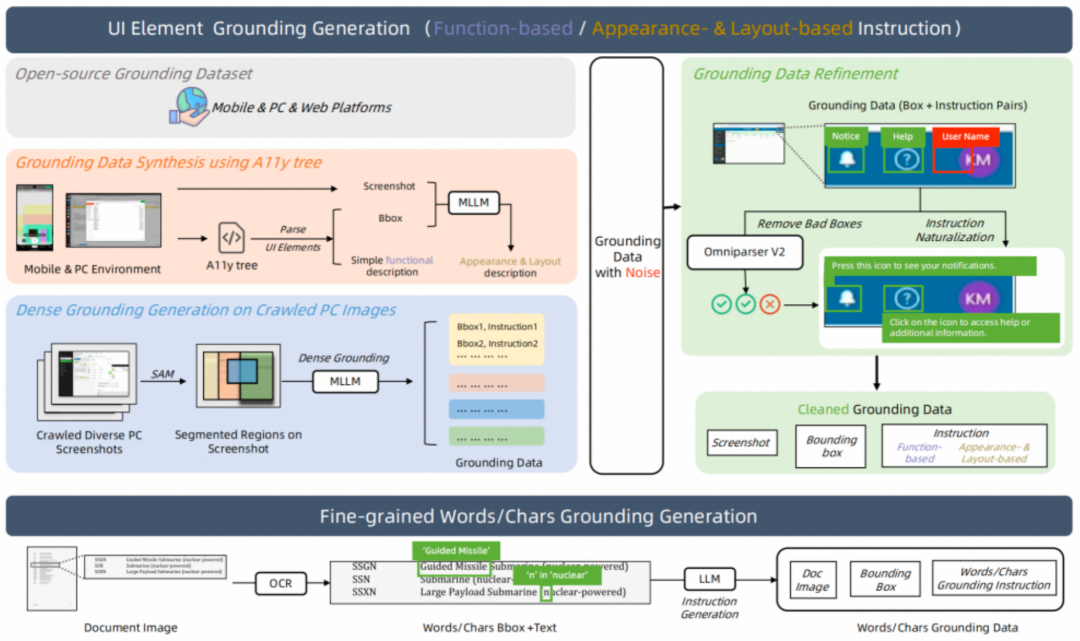
首先是极致的 UI 元素定位(Grounding)能力。 为了让模型精准找到屏幕上的目标,我们构建了涵盖功能、外观、布局等多维信息的复合型 Grounding 数据集。我们不仅融合了 InternVL、UI-Vision 等多个主流开源数据集,还创新地利用 Accessibility Tree 自动生成带有功能描述的标注数据,并辅以多模态模型补全外观和布局信息。
特别针对元素密集的 PC 界面,我们开创性地使用 SAM 对截图进行子区域分割,再让 MLLM 在小范围内进行精细定位,有效解决了定位难题。所有数据都经过严格清洗,包括与 Omniiparser V2 的检测结果进行比对筛选,并用 LLM 将生硬的指令改写得更自然,确保了训练数据的质量与真实性。
其次是深度的长任务规划(Task Planning)与动作语义理解(Action Semantics)。 为了应对复杂任务,GUI-Owl 的规划能力来自两个方面:一方面,它能从历史成功轨迹中「蒸馏」出经验,形成可复用的任务执行手册;另一方面,它也从 Qwen3-235B 这样的大规模语言模型中学习跨应用、跨功能的通用规划知识,使其面对全新场景也能从容制定计划。
更重要的是,模型通过学习海量的「操作前 / 后」截图对比,深刻理解了每个动作与界面状态变化之间的因果关系,真正做到了知其然,更知其所以然。
最后,我们为其注入了强大的稳健推理(Robust Reasoning)与泛化适配能力。 GUI-Owl 不只是机械地模仿操作,而是理解其背后的决策逻辑。我们开创性地从 Mobile-Agent-v3 多智能体框架中蒸馏推理数据,让单一模型学会从管理者、执行者、反思者等多个角色的视角进行思考,显著减少了决策盲区。
同时,结合离线提示式拒绝采样和迭代式的在线训练,模型的推理能力在真实任务中被反复打磨和验证。这种全面的训练方式,使得 GUI-Owl 不再是为某个特定框架「定制」的,而是天然具备了跨环境、跨角色的泛化能力。
实验证明,即使将其「即插即用」到从未训练过的第三方 Agent 框架中,其性能依旧远超其他专用或通用模型。
亮点三:可扩展环境强化学习(RL)
让模型「更稳、更聪明、更贴近真实使用」
仅靠离线数据还不足以让一个 GUI Agent 在真实环境中长期稳定运行,它需要真正「泡在环境里」边做边学。为此,我们专门为 GUI-Owl 设计了一套可扩展的环境级强化学习(RL)体系,旨在让模型「更稳、更聪明、更贴近真实使用」。
我们的 RL 训练基础设施在设计上兼顾了灵活性与效率。它采用统一的任务插件接口,无论是「一步到位」的短任务还是跨应用的长链路任务,都能无缝接入。其核心是将经验生成(Rollout)与策略更新完全解耦,这意味着我们可以将数据采集部署在为推理优化的硬件上以最大化吞吐量,同时在训练端保持策略更新的稳定性,从而在优化质量、速度与成本之间取得最佳平衡。
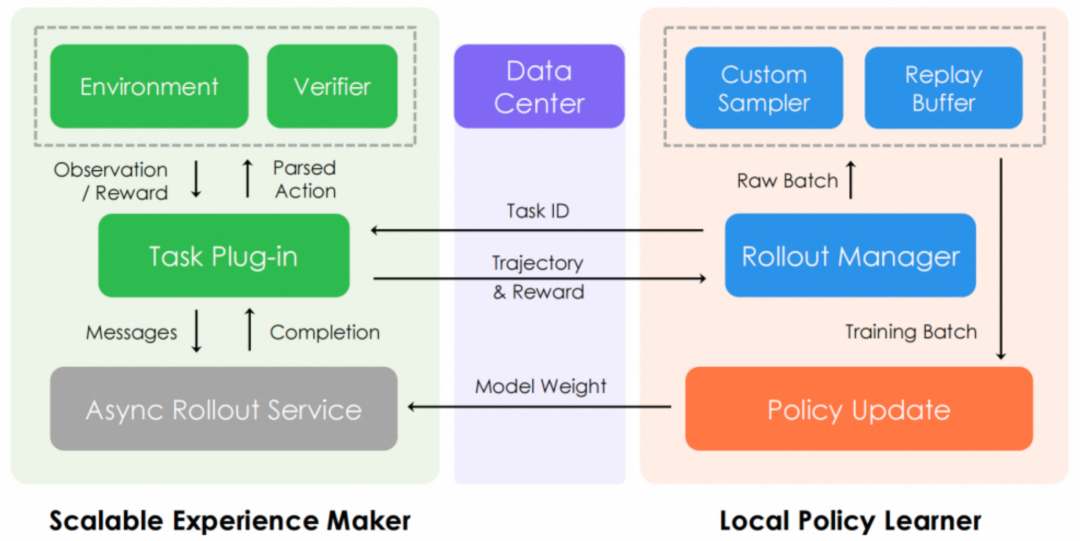
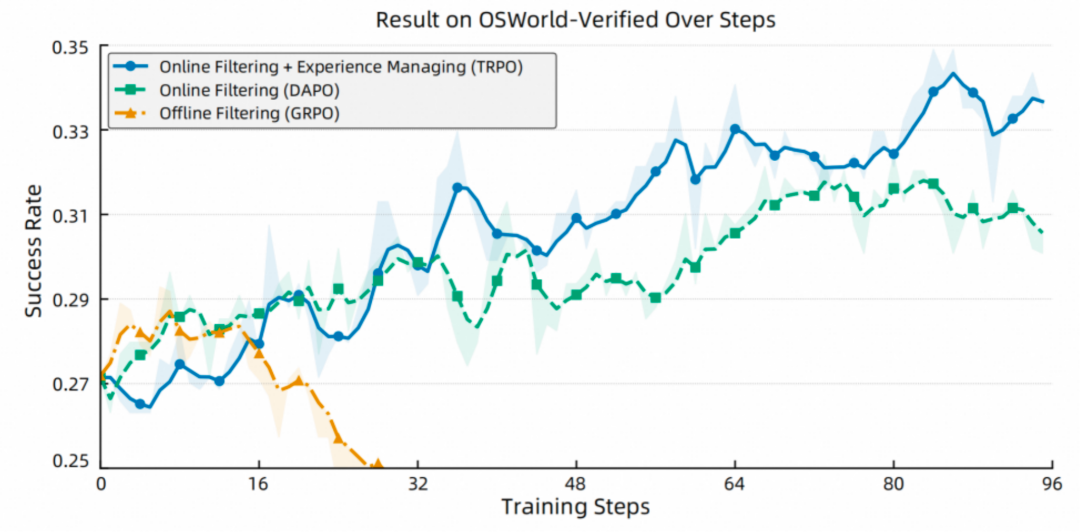
针对 GUI 自动化任务奖励信号稀疏且延迟的特性,我们引入了 Trajectory-aware Relative Policy Optimization (TRPO) 算法。该算法不再试图为每一步操作精确分配奖励,而是在整个任务完成后,对整条轨迹进行一次性评估,并根据成功、失败或格式错误给予一个明确的轨迹级奖励。这个奖励信号经过归一化处理后,会均匀地分配到该轨迹的每一个步骤上,从而有效缓解了长任务中棘手的「信用分配问题」,让模型能够从最终结果中稳定地学习。
为了进一步提升学习效率,我们还引入了 Replay Buffer 机制,它会缓存历史上成功的案例。当某一轮训练中全是失败的尝试时,系统会自动从缓存中「注入」一个成功样本,确保模型在每个批次都能学到正向反馈。这些专门的优化,使得 GUI-Owl 在在线环境中能够持续提升长任务的成功率,表现更接近真实用户所需的高稳定性。
总结
GUI-Owl 的发布,为开源社区带来了一个能力强大的原生端到端多模态 GUI 智能体。它不仅在 AndroidWorld、OSWorld 等关键基准上刷新了开源模型的记录,其 32B 版本更是在多项评测中展现了超越闭源顶级模型的实力。更重要的是,它以单一模型之身,即可胜任复杂的单体任务与多智能体协作中的不同角色,显著降低了部署和资源开销。
而 Mobile-Agent-v3 框架则是为充分释放 GUI-Owl 潜力而生的最佳拍档。它通过精巧的多智能体协作机制,进一步提升了模型的跨任务执行能力,结合云端沙箱的灵活性,使其能够快速适应并解决各类新场景下的自动化难题。
一句话总结:开源,Mobile-Agent-v3 也能跑在最前面。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com