ICML 2025论文APEC,利用模仿学习自动生成偏好数据,实现奖励模型泛化能力质的飞跃。告别繁琐人工标注!
原文标题:ICML 2025 | 奖励模型还用人标?APEC用对抗模仿生成偏好,泛化能力直线上升
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、奖励欺骗(Reward Hacking)一直是强化学习领域的一个老大难问题,APEC通过提升数据泛化性来有效规避了它。除了APEC这种利用数据生成提升泛化性的思路,大家还知道或认为有哪些其他的技术路线或方法,也能有效地应对或减轻奖励欺骗现象呢?
3、APEC的一大核心优势是提升了偏好数据的“覆盖范围”和“多样性”。如果我们把这个思路推广一下,在其他需要大量数据标注或生成样本的机器学习任务中(比如图像识别、自然语言处理、推荐系统等),有没有类似“从模型学习过程中自动生成多样化、高质量数据”的方法?或者说,APEC的这种理念可以给我们带来哪些启发?
原文内容

来源:PaperWeekly本文约2200字,建议阅读5分钟
本文提出了一种自动化偏好数据生成方法——APEC。
本文提出了一种自动化偏好数据生成方法——APEC。
非常高兴我们的工作《Improving Reward Model Generalization from Adversarial Process Enhanced Preferences》已被 ICML 2025 接收!这是我们在奖励建模(Reward Modeling)领域的一些探索。在这里分享一下这篇工作。

论文链接:
https://openreview.net/pdf?id=2FGpL5Nd4C
代码仓库:
https://github.com/Zzl35/APEC
本文提出了一种自动化偏好数据生成方法——APEC (Automated Preference generation with Enhanced Coverage) ,该方法启发于对抗模仿学习(Adversarial Imitation Learning,AIL)的收敛过程。
利用策略在模仿(专家)轨迹时潜在的“从坏到好”过程,自动生成准确且覆盖广泛的偏好数据,从而提升基于偏好学习的奖励模型的准确性和泛化能力。
我们主要贡献包括:
-
提出方法:提出了一种自动化生成偏好数据的新方法 APEC,相比现有方法,APEC 能够显著提升偏好数据的多样性与覆盖范围,从而提升奖励模型的泛化能力。
-
理论分析:从理论上证明了 AIL 训练过程中策略价值随迭代次数递增,为偏好关系提供了依据;
-
实验验证:使用 APEC 训练出的奖励模型,在多个连续控制任务中实现了优于或接近专家表现的策略,在部分任务上超越了演示数据本身。
在强化学习(Reinforcement Learning,RL)中,奖励函数是指导智能体行为的核心信号。现有的奖励函数建模方法不仅费时费力,还容易出现“奖励欺骗”(reward hacking)等问题。
这些方法大致可分为三类:
1. 人工设计:需要大量专家知识,人工成本高且难以扩展;
2. 逆强化学习:依赖于最优示范数据,而最优轨迹在有可能无法获得;
3. 基于偏好的奖励学习:从轨迹对的偏序关系中学习奖励函数,但仍然依赖大量人工标注。
为了减少人工干预,近年来出现了一些从次优示范数据中自动生成偏好数据的方法(如 D-REX、LERP)。然而,这些方法在偏好数据的覆盖性(coverage)方面存在明显不足,限制了奖励模型的泛化能力。
APEC 的灵感来自于一个关键观察:在对抗模仿学习(AIL)过程中,策略的质量会随着训练轮数逐渐提升。也就是说,越靠后的策略通常比早期策略更好。
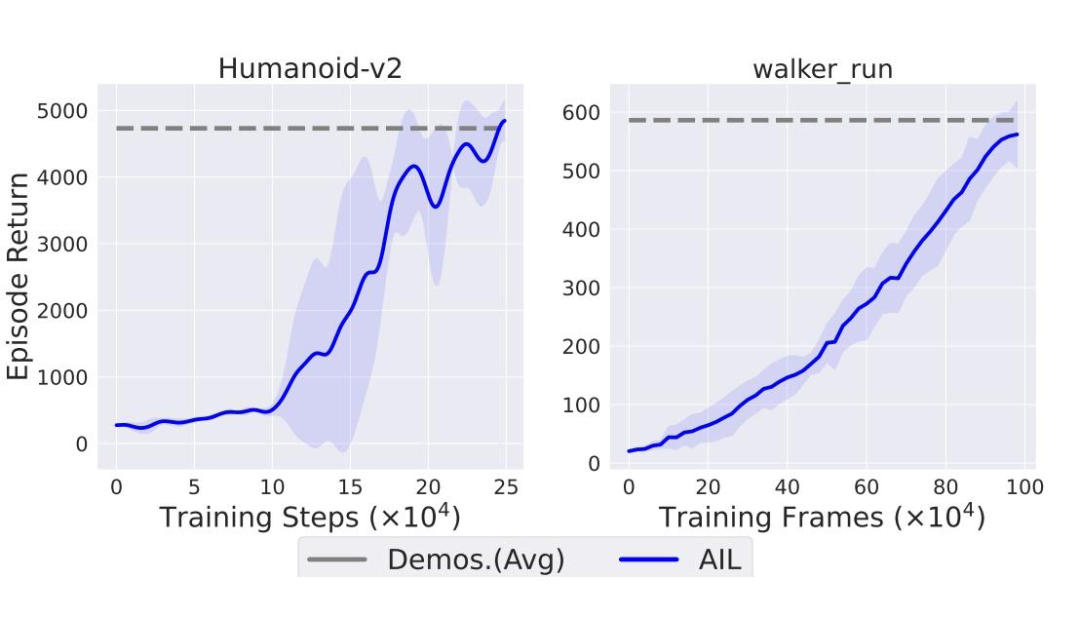
图1:对抗式模仿学习在 MuJoCo 和 DMControl 任务中的训练曲线
理论分析:AIL 训练过程中策略的误差上界会随着训练轮数k的增加而降低。

基于这一观察,APEC 的核心步骤如下:
1. 收集不同阶段的策略:在 AIL 训练过程中定期保存策略模型;
2. 构造策略对:选择具有显著迭代差异的策略对(例如第 10 轮 vs 第 200 轮);
3. 执行策略并生成偏好:让这对策略分别与环境交互,生成轨迹,并根据其性能确定偏好关系;
4. 双重鲁棒性筛选:引入 Wasserstein 距离准则,确保生成的偏好数据质量。
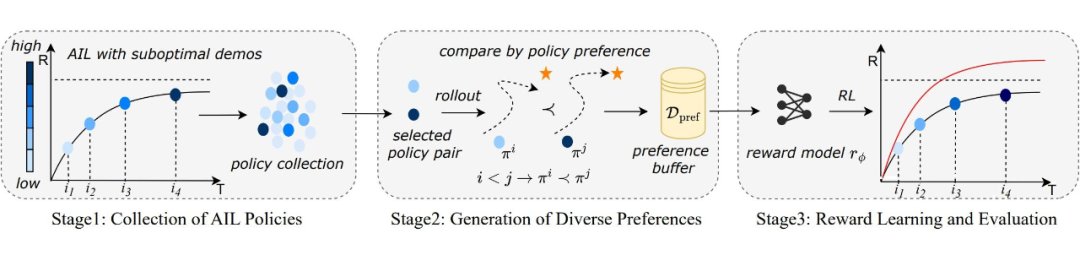
图2:APEC 的训练流程
我们在 5 个任务(MuJoCo)和 3 个图像输入任务(DMControl)上进行了全面评估。
与之前的工作相比,我们的实验设置更具挑战性:不仅引入了基于图像的连续控制任务,并且可用的演示数据更少,MuJoCo 仅提供 1 条次优演示,DMControl 提供 10 条次优演示。
4.1 奖励相关性(Reward Correlation)
奖励相关性是指模型学到的奖励函数与真实环境奖励之间的皮尔逊相关系数。它衡量了智能体对状态-动作对所预测的奖励值与实际环境中该状态-动作对的真实奖励之间的线性相关程度。APEC 在大多数任务上的奖励相关性显著优于基线方法。
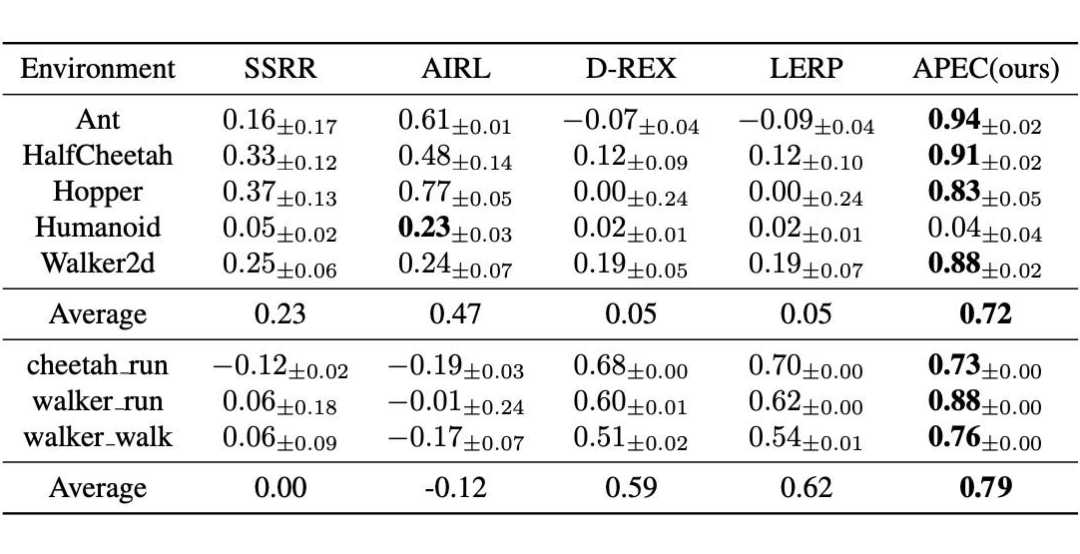
4.2 偏好一致性(Preference Accuracy)
偏好一致性是指模型根据学到的奖励函数判断出的偏好顺序是否与真实偏好数值一致的比例 。它是通过在测试集中随机生成轨迹对,并比较模型预测的偏好与真实偏好是否一致来评估的。
APEC 学到的奖励函数能更准确地预测真实回报。
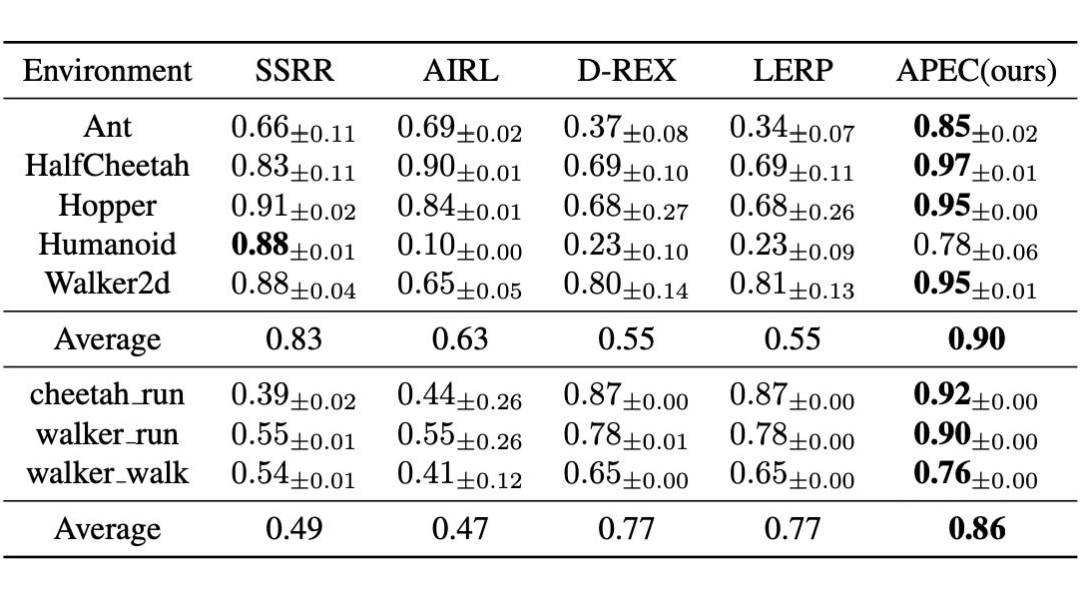
4.3 策略学习效果(Policy Performance)
我们还尝试使用学习到的奖赏函数训练策略。我们采用 SAC(MuJoCo)或 DrQ-v2(DMControl)作为策略训练算法,其结果如图 5 所示。
APEC 在 8 个任务中的 7 个达到了优于或接近示范数据的表现,而其他方法在我们的具有挑战性的设置下(如更少的示范、更复杂的任务)表现不佳。
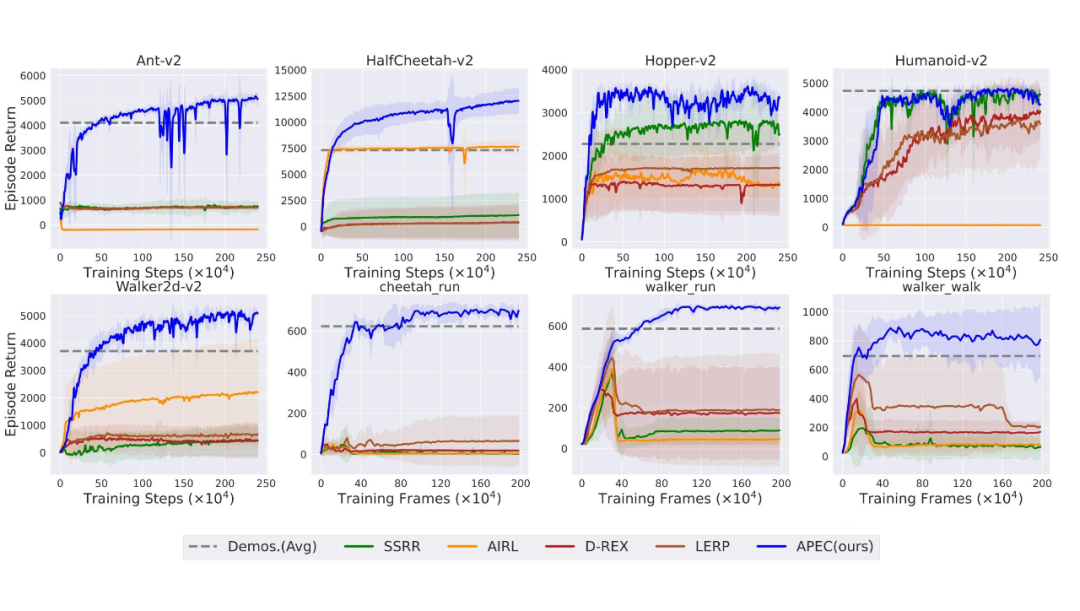
图3:策略学习评估结果。图中 x 轴表示训练步数(对于基于像素的任务为帧数),y 轴表示策略的回报值
我们通过进一步实验分析发现,以往方法表现不佳的原因在于其学习到的奖赏函数在被用于策略训练的过程中会出现 reward hacking 的现象(图 4),即在学习到的奖励函数下策略的累积回报会随着学习过程在逐渐上升,但是该策略的真实累积回报却没有提升甚至下降。
而 APEC 受益于其覆盖更广的训练数据学习到了泛化更好的奖赏函数,从而避免了 reward hacking(图5)。
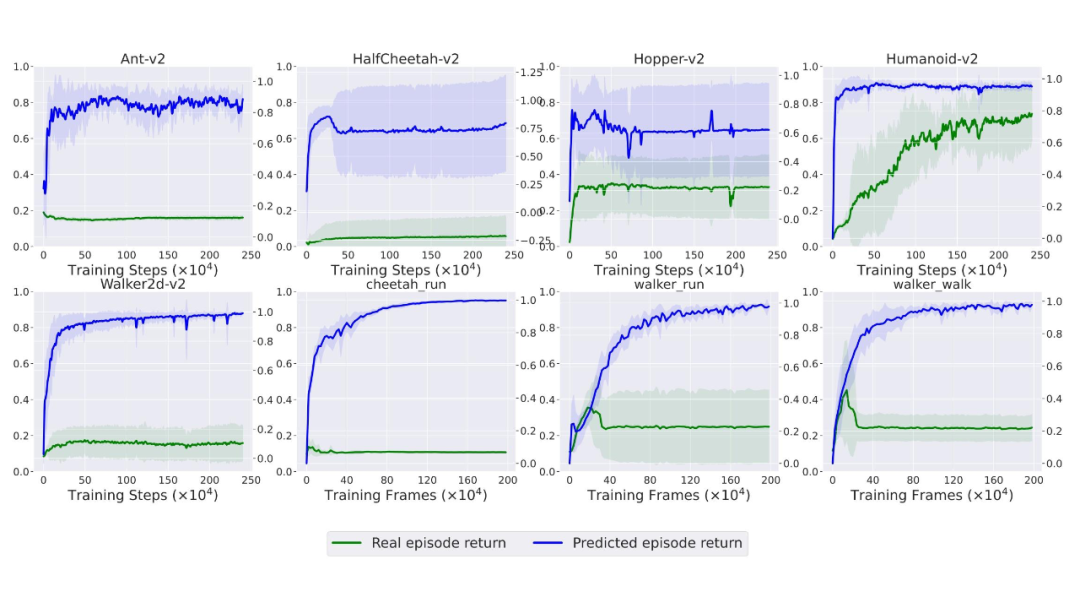
图4:D-REX 的策略训练过程
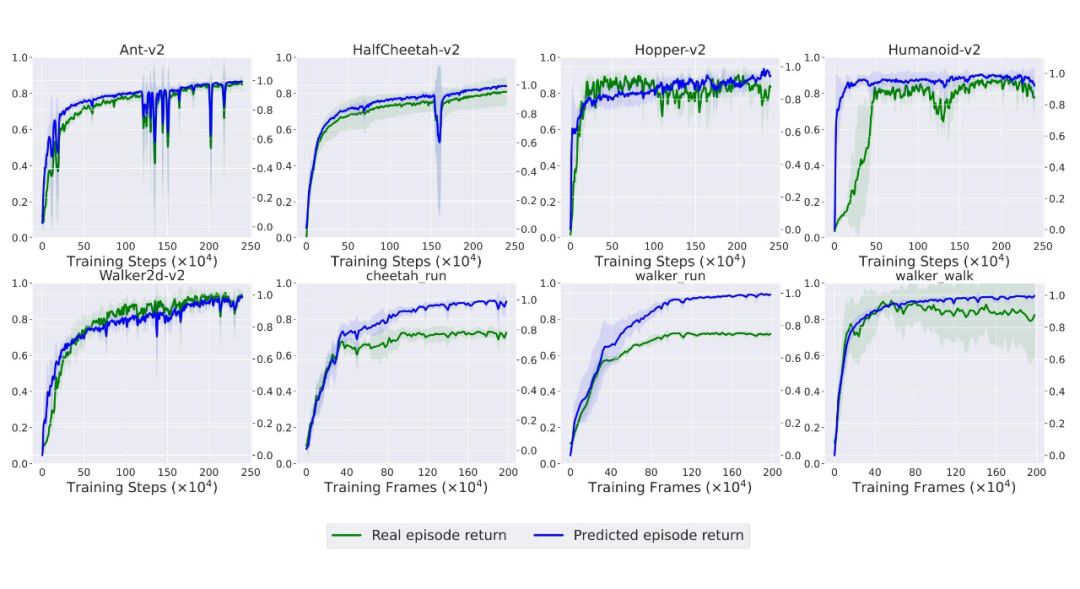
图5:APEC 训练过程
4.4 消融实验
我们进一步验证了 APEC 中的关键组件(如 Wasserstein 筛选准则、用于构造数据的策略数量)对最终性能的影响,并展示了生成的偏好数据在状态空间中的覆盖情况:
-
Wasserstein 准则能够提升生成偏好数据的准确性,让奖赏函数能更好地和真实奖励对齐。
-
更多的策略带来了覆盖范围更广的生成数据,从而提升奖赏函数的泛化性。
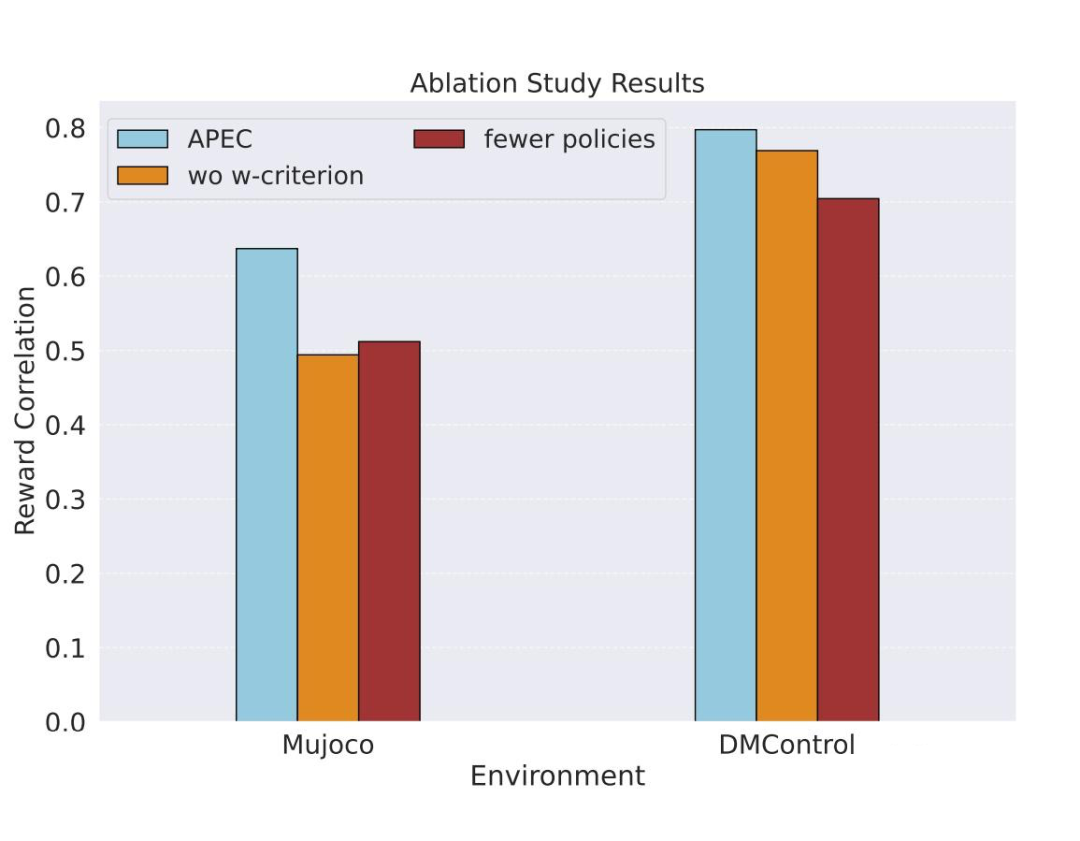
图6:消融实验结果
最后,我们我们通过可视化进一步验证了 APEC 生成的样本具有更广覆盖性。
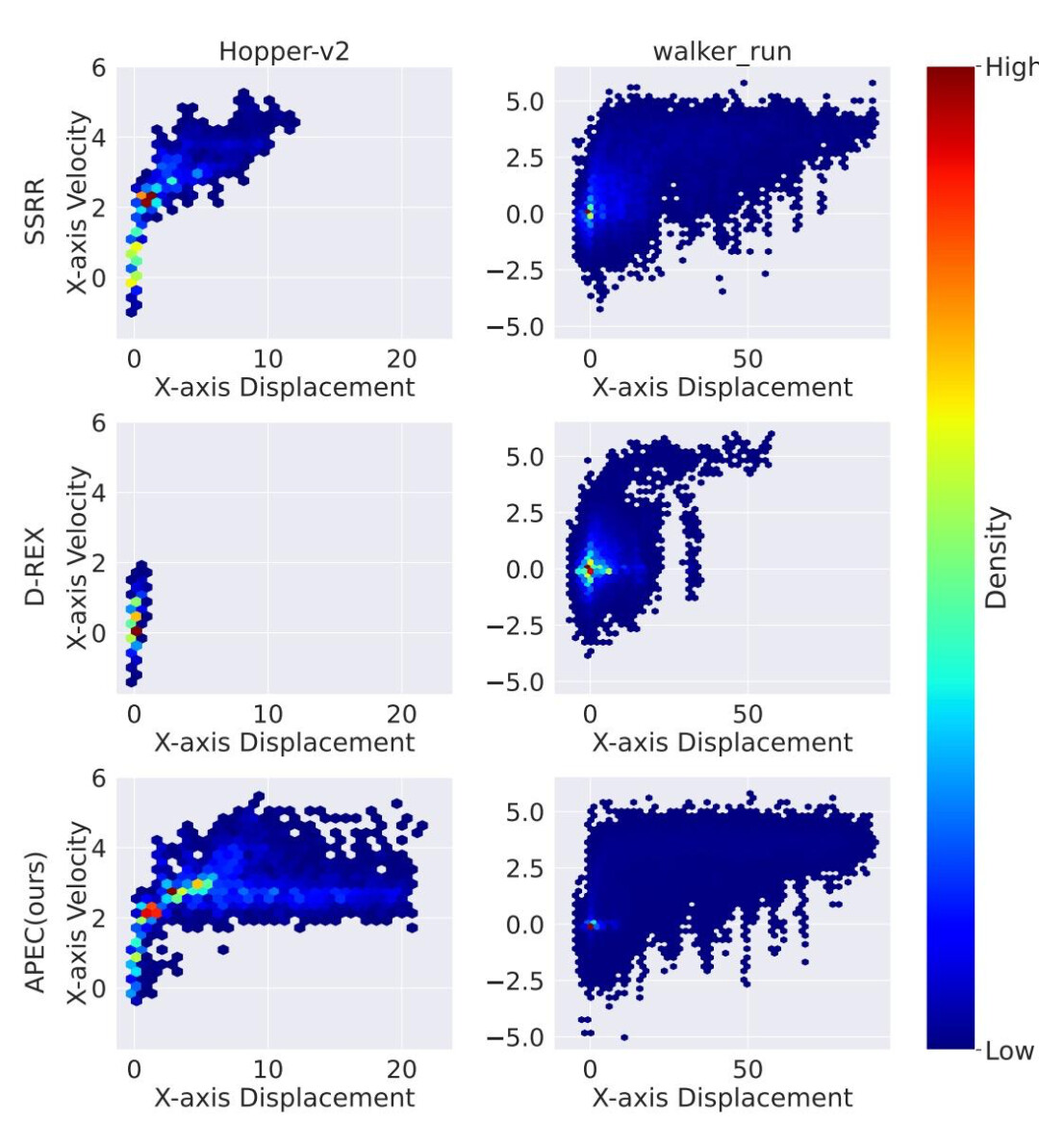
图7:不同方法在 Hopper-v2 和 walker run 任务上生成的偏好分布可视化 。从上到下,每一行分别表示 SSRR、D-REX 和 APEC 生成的样本。在每张图中,x 轴表示智能体在 x 轴上的位移,y 轴表示智能体在 x 轴上的速度
参考文献
[1] Brown, D. S., Goo, W., and Niekum, S. Better-thandemonstrator imitation learning via automatically-ranked demonstrations. In Conference on robot learning, pp. 330–359. PMLR, 2020.
[2] Chen, L., Paleja, R., and Gombolay, M. Learning from suboptimal demonstration via self-supervised reward regression. In Conference on robot learning, pp. 1262–1277. PMLR, 2021.
[3] Cao, X., Luo, F.-M., Ye, J., Xu, T., Zhang, Z., and Yu, Y. Limited preference aided imitation learning from imperfect demonstrations. In Forty-first International Conference on Machine Learning, 2024.
[4] Xu, T., Zhang, Z., Chen, R., Sun, Y., and Yu, Y. Provably and practically efficient adversarial imitation learning with general function approximation. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024.
[5] Xu, T., Li, Z., and Yu, Y. Error bounds of imitating policies and environments. In Advances in Neural Information Processing Systems 33, pp. 15737–15749, 2020.
编辑:王菁
关于我们
