复旦&微软等团队发布StableAvatar,解决音频驱动数字人视频生成时长限制。实现无限时长、高保真视频,推动AI陪伴等领域发展,代码已开源!
原文标题:你能永远陪我聊天吗?复旦&微软提出StableAvatar: 首个端到端无限时长音频驱动的人类视频生成新框架!
原文作者:机器之心
冷月清谈:
为突破这一技术瓶颈,来自复旦大学、微软和西安交通大学等机构的研究团队共同提出了 **StableAvatar** 框架。这是一个全新的端到端解决方案,旨在实现无限时长、高保真的音频驱动人类视频生成。该框架的核心技术包含了多项创新:
首先,研究团队设计了 **Timestep-aware Audio Adapter**,专门用于优化音频嵌入与潜在变量之间的交互。以往的方法由于缺乏音频相关的先验知识,在嵌入过程中会累积潜在分布误差,导致长视频的面部和身体扭曲。该适配器通过与时间步嵌入和潜在特征进行交互,强制模型在每个时步上建模音频-潜在变量的联合特征分布,有效缓解了长期生成中潜在分布误差的累积,从而显著提升了视频的一致性。
其次,StableAvatar 引入了创新的 **Audio Native Guidance** 机制,取代了传统的分类器自由引导(CFG)方法。该机制通过修改去噪得分函数,将优化的音频嵌入视为扩散模型的内部特征,能够更直接地作用于扩散模型的采样分布,将生成过程引导至音频-潜在变量的联合分布,从而在整个去噪过程中持续优化唇形同步和面部表情的自然性。
最后,为了确保视频在长时间序列中的平滑过渡,框架还采用了 **Dynamic Weighted Sliding-Window Strategy**。该策略在相邻窗口的重叠潜在变量上引入了滑动融合机制,并依据相对帧索引采用对数插值分布的融合权重,实现了视频片段之间平滑无缝的衔接,避免了传统分段拼接带来的突兀感。
StableAvatar 的推出,不仅为音频驱动数字人视频生成领域带来了革命性的进步,其开源代码也为后续研究和应用提供了宝贵基础,有望推动数字人在电影、游戏、虚拟现实以及人工智能陪伴等更广泛领域内的深入应用。
怜星夜思:
2、除了电影、游戏和直播带货,你们觉得这种能“一直聊下去”的数字人技术还能用在哪些意想不到的地方?有没有什么实际应用场景会因为“无限时长”这个特性变得特别厉害?
3、StableAvatar 解决了长时间视频的面部和身体变形问题,那下一步对于数字人来说,最大的技术挑战会是什么呢?是更自然的表情、情绪,还是更智能的实时交互?或者说,离“以假乱真”还有多远?
原文内容

在《流浪地球 2》中图恒宇将 AI 永生数字生命变为可能,旨为将人类意识进行数字化备份并进行意识上传,以实现人类文明的完全数字化。
如今随着扩散模型的兴起极大,涌现出大量基于音频驱动的数字人生成工作。具体而言,语音驱动人类视频生成旨在基于参考图像与音频,合成面部表情与身体动作与音频高度同步的自然人像视频,在电影制作、游戏制作、虚拟现实、直播带货等领域具有广泛的应用前景。
但是,现有方法仅能生成时长不足 15 秒的短视频,一旦模型尝试生成超过 15 秒的视频,就会出现明显的身体变形与外观不一致现象,尤其集中在面部区域,这使目前数字人技术还无法达到《流浪地球 2》中图恒宇所创造的 AI 永生数字生命那样的程度,严重限制了其实际应用价值。
为了解决这一问题,一些方法尝试在音频驱动人类视频生成中引入一致性保持机制,但很少有工作深入探讨问题的根本原因。现有策略——无论是利用运动帧(Motion Frame),还是在推理过程中采用多种滑动窗口机制——都只能在一定程度上提升长视频的平滑性,却无法从根本上缓解无限时长头像视频的质量退化问题。
另一种可行方案是将长音频切分为多个片段,分别处理后再拼接成连续的视频。然而,这种方式不可避免地会在片段衔接处引入不一致和突兀的过渡。
因此,对于语音驱动的人类视频生成而言,实现端到端的无限时长高保真视频生成依然是一项极具挑战性的任务。

为了解决上述问题,来自复旦、微软、西交等研究团队提出 StableAvatar 框架,以实现无限时长音频驱动的高保真人类视频生成,目前代码已开源,包括推理代码和训练代码。

-
论文标题:StableAvatar: Infinite-Length Audio-Driven Avatar Video Generation
-
论文地址: https://arxiv.org/abs/2508.08248
-
项目主页: https://francis-rings.github.io/StableAvatar/
-
项目代码: https://github.com/Francis-Rings/StableAvatar
-
项目 Demo: https://www.bilibili.com/video/BV1hUt9z4EoQ
方法简介
如下图所示,StableAvatar 是基于 Wan2.1-1.3B 基座模型开发的,首先将音频输入 Wav2Vec 模型中提取 audio embeddings,随后通过我们提出的音频适配器(Audio Adapter)进行优化,以减少潜变量分布误差的累积。
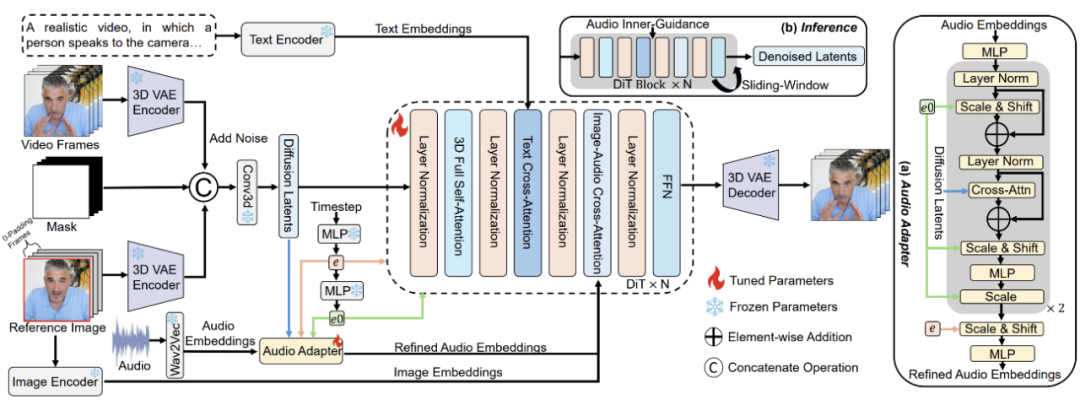
经过优化的 audio embeddings 会输入至去噪 DiT 中进行处理。参考图像的处理通过两条路径输入扩散模型:
-
沿时间轴将参考图像与零填充帧拼接,并通过冻结的 3D VAE Encoder 转换为潜变量编码(latent code)。该潜变量编码在通道轴上与压缩后的视频帧及二值掩码(第一帧为 1,后续所有帧为 0)拼接。
-
通过 CLIP Encoder 编码参考图像以获得 image embeddings,并将其输入到去噪 DiT 的每个图像-音频交叉注意力模块中,用于约束生成对象的外观。
在推理阶段,我们将原始输入视频帧替换为随机噪声,而保持其他输入不变。我们提出了一种新颖的音频原生引导(Audio Native Guidance)方法,以替代传统的 Classify-Free-Guidance,从而进一步促进唇形同步与面部表情生成。此外,我们引入了一种动态加权滑动窗口去噪策略,通过在时间维度上融合潜变量,以提升长视频生成过程中的视频平滑性。
Timestep-aware Audio Adapter
以往的方法在生成超过 15 秒的虚拟人视频时,往往出现明显的面部与身体扭曲,以及颜色漂移。这主要源于它们的音频建模方式:直接将第三方预训练的音频嵌入通过交叉注意力注入扩散模型。由于当前的扩散主干缺乏音频相关的先验知识,在注入过程中会在跨片段之间逐步累积潜在分布误差,使得后续片段的潜在分布逐渐偏离最优解。
为了解决这一问题,本文提出了一种新颖的 Timestep-aware Audio Adapter,其中音频嵌入通过多个仿射调制和交叉注意力模块与时间步嵌入和潜在特征进行交互,如上图(a)所述。
具体而言,初始音频嵌入(Query)依次与初始潜变量(Key 和 Value)进行交叉注意力计算,随后结合 timestep embeddings 进行 affine modulation,从而得到优化后的音频嵌入。由于 timestep embeddings 与潜变量高度相关,这一设计潜在地迫使扩散模型在每个时步上建模音频–潜变量的联合特征分布,从而有效缓解因缺乏音频先验而导致的潜变量分布误差累积,优化后的音频嵌入(Key 和 Value)最后通过交叉注意力与潜变量(Query)交互后注入扩散模型。
Audio Native Guidance
为了进一步增强音频同步性和面部表情,本文提出了一种新颖的 Audio Native Guidance 机制,用以替代传统的 CFG,它未考虑音频与潜在特征的联合关系。本文修改了去噪得分函数,以引导去噪过程朝着最大化音频同步性与自然性的方向前进。
由于优化后的 audio embeddings 本质上也依赖于潜变量,而不仅仅依赖外部音频信号,我们的 Audio Native Guidance 不再将 audio embeddings 作为一个独立于潜变量的外部特征,而是将其作为一个与潜变量相关的扩散模型的内部特征,我们的引导机制能够直接作用于扩散模型的采样分布,将生成过程引导至音频–潜变量的联合分布,并使扩散模型在整个去噪过程中不断优化其生成结果。
具体而言,被 Timestep-aware Audio Adapter 优化后的音频嵌入特征依赖于潜在变量和给定音频,因此我们将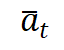 也作为去噪 DiT 的一个额外的预测目标,从而引导扩散模型捕捉音频-潜变量联合分布,去噪过程如下:
也作为去噪 DiT 的一个额外的预测目标,从而引导扩散模型捕捉音频-潜变量联合分布,去噪过程如下:
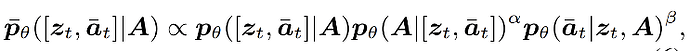
其中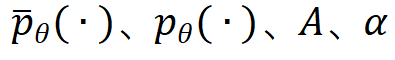 和
和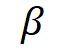 分别指修改后的采样过程、原始采样过程、输入外部音频和两种引导尺度参数,依据贝叶斯公式可以将上述化解为:
分别指修改后的采样过程、原始采样过程、输入外部音频和两种引导尺度参数,依据贝叶斯公式可以将上述化解为:
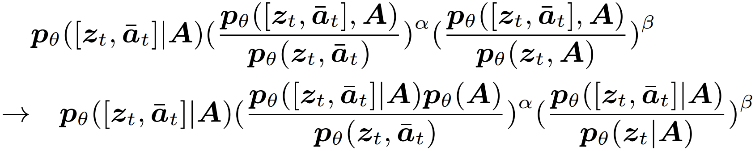
由于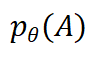 是常数,因此去掉这一项后公式化解为:
是常数,因此去掉这一项后公式化解为:
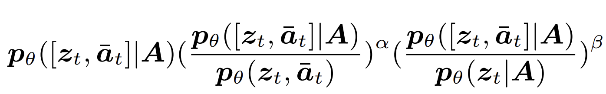
我们进一步将上述公式转化为得分函数形式:
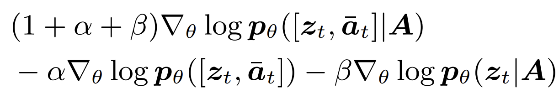
因此最终推导公式为:
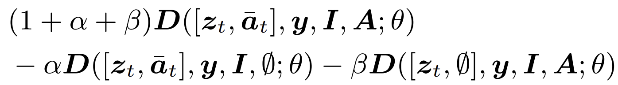
其中 和
和![]() 分别表示扩散模型、文本描述和参考图像。Audio Native Guidance 机制将
分别表示扩散模型、文本描述和参考图像。Audio Native Guidance 机制将![]() 视为扩散模型的一个额外预测目标,使模型在去噪过程中受联合的音频—潜变量分布引导,从而强化音频与潜变量之间的相关性。即便基础模型缺乏音频先验,该方法也能有效抑制音频驱动视频生成中的分布误差累积。
视为扩散模型的一个额外预测目标,使模型在去噪过程中受联合的音频—潜变量分布引导,从而强化音频与潜变量之间的相关性。即便基础模型缺乏音频先验,该方法也能有效抑制音频驱动视频生成中的分布误差累积。
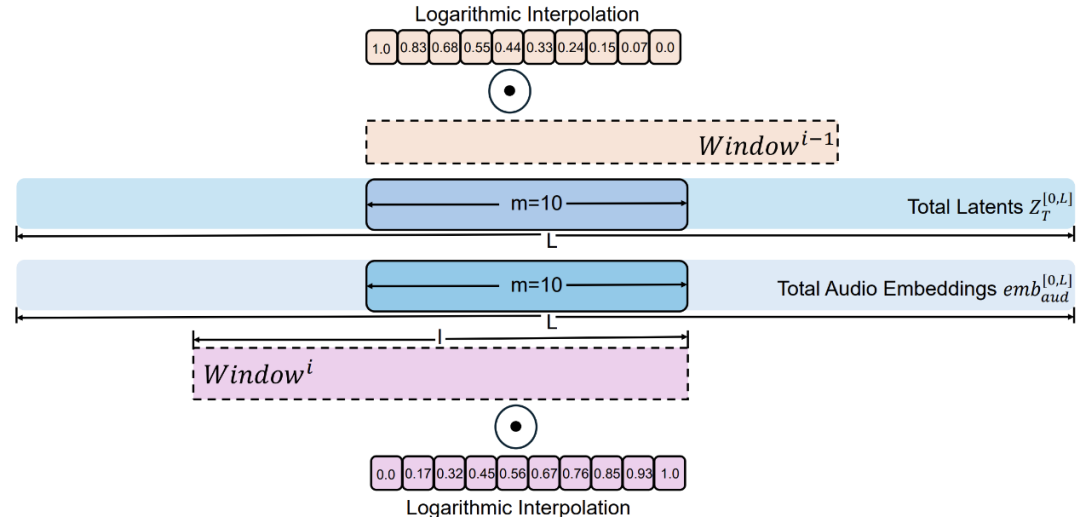
Dynamic Weighted Sliding-Window Strategy
与先前的滑窗去噪策略相比,我们在相邻窗口的重叠潜变量上引入了滑动融合机制,其中融合权重依据相对帧索引采用对数插值分布。融合后的潜变量会回注到两个相邻窗口中,从而保证中央窗口的两侧边界均由混合特征构成。
借助对数加权函数,可在视频片段之间的过渡中引入一种渐进式平滑效果:早期阶段的权重变化更为显著,而后期阶段变化趋于平缓,从而实现跨视频片段的无缝衔接,具体算法流程如下面算法表和图像所述。

生成结果示例
实验对比

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com