DiT架构缺陷引争议,谢赛宁回应指出架构硬伤及未来优化方向。
原文标题:DiT在数学和形式上是错的?谢赛宁回应:不要在脑子里做科学
原文作者:机器之心
冷月清谈:
博主将DiT的两个设计点视为“可疑”:一是全程使用Post-LayerNorm,认为其在处理扩散过程这类数值范围剧烈变化的任务时不够稳定;二是adaLN-zero机制,指出它在处理指导信息时采用简单MLP而非Transformer,并可能通过注入偏置来限制模型表达能力。
对此,DiT的作者谢赛宁教授做出回应。他强调科学研究需基于实验而非臆测,并坦诚DiT架构确实存在一些“硬伤”。他澄清TREAD的收敛优势更接近于正则化效应,并提出DiT的改进方向:例如,推荐使用结合swiglu、rmsnorm等的Lightning DiT版本;强调内部表示学习的重要性;建议始终优先采用随机插值或流匹配;以及针对不同嵌入类型,智能选择AdaLN-zero或交叉注意力。谢赛宁特别指出,DiT中使用的sd-vae才是“真正的硬伤”,它臃肿低效且非端到端,是当前亟待解决的核心瓶颈。
怜星夜思:
2、从DiT和谢赛宁教授的这次公开回应来看,学术界对新技术的质疑和讨论,是怎样地推动AI领域发展的?这种公开的“辩论”对AI领域的发展是利大于弊还是反之?
3、文章提到了DiT的Post-LayerNorm和adaLN-zero设计引发的争议,以及谢赛宁教授指出的sd-vae是其“真正的硬伤”。作为开发者或者使用者,在选择和部署类似模型时,我们应该如何评估和权衡这些潜在的结构性缺陷和模型已有的高性能优势?
原文内容
编辑:冷猫,+0
「兄弟们,DiT 是错的!」
最近一篇帖子在 X 上引发了很大的讨论,有博主表示 DiT 存在架构上的缺陷,并附上一张论文截图。
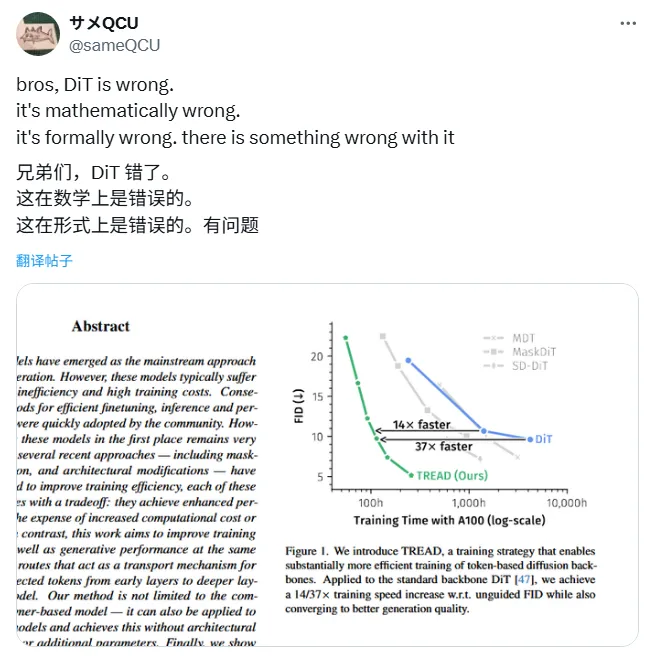
图 1. 我们引入了 TREAD,这是一种能够显著提升基于 token 的扩散模型骨干网络训练效率的训练策略。当应用于标准的 DiT 骨干网络时,我们在无引导 FID 指标上实现了 14/37 倍的训练速度提升,同时也收敛到了更好的生成质量。
图中横轴代表训练时间(以 A100 GPU 的小时数为单位,log 尺度,从 100 小时到 10000 小时),纵轴代表 FID 分数(越低越好,代表生成图像质量越高)。
博主认为,这个图的核心信息不是 TREAD 的速度优势,而是 DiT 的 FID 过早稳定,暗示 DiT 可能存在「隐性架构缺陷」,导致其无法继续从数据中学习。
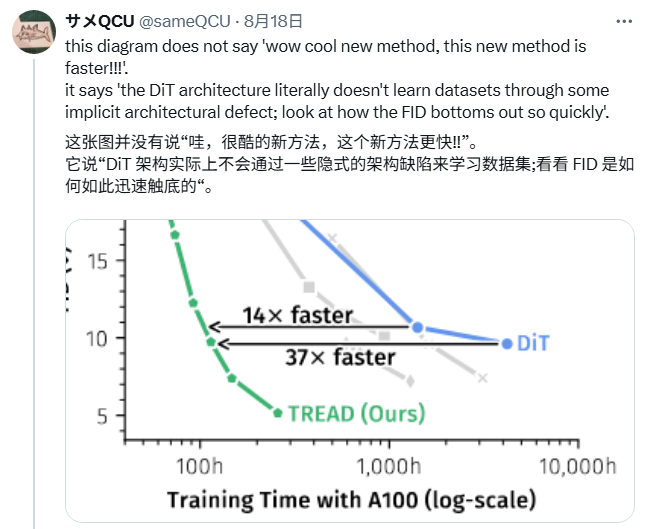
博主提到的论文发表于今年 1 月(3 月更新 v2),介绍了一种名为 TREAD 的新方法,该工作通过一种创新的「令牌路由」(token routing)机制,在不改变模型架构的情况下,极大地提升了训练效率和生成图像的质量,从而在速度和性能上都显著超越了 DiT 模型。
具体而言,TREAD 在训练过程中使用「部分令牌集」(partial token set) vs 「完整令牌集」(full token set),通过预定义路由保存信息并重新引入到更深层,跳过部分计算以减少成本,同时仅用于训练阶段,推理时仍采用标准设置。这与 MaskDiT 等方法类似,但更高效。

-
论文标题:TREAD:Token Routing for Efficient Architecture-agnostic Diffusion Training
-
论文地址:https://arxiv.org/abs/2501.04765
-
代码:https://github.com/CompVis/tread
博主在后续回复中逐步展开了对 DiT 的批判,并解释 TREAD 如何暴露这些问题。
博主指出,该论文揭示了 DiT 模型的设计缺陷。具体来说,研究发现在训练过程中,如果将模型中的一部分计算单元替换为「恒等函数」(Identity Function)—— 也就是让这些单元什么计算都不做,仅仅是「直通」数据,相当于被临时禁用了 —— 模型的最终评估分数反而会提高。

接着博主指出 DiT 的两个「可疑」的设计:
-
整个架构都使用「后层归一化」(Post-LayerNorm)
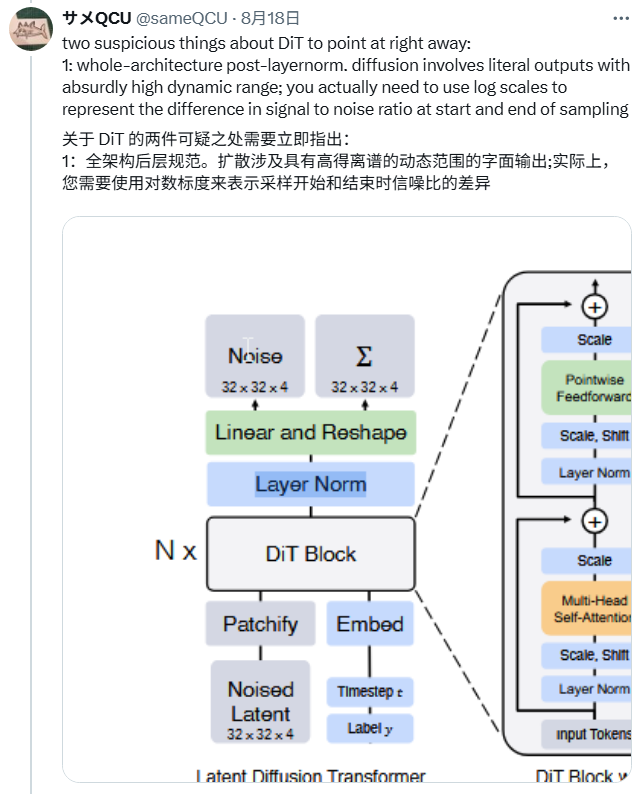
博主认为 DiT 使用了一种已知不太稳定的技术(后层归一化),来处理一个数值范围变化极其剧烈的任务(扩散过程)。
-
adaLN-zero

博主认为,这个模型虽然整体上自称是「Transformer」架构,但在处理最关键的「指导信息」(即条件数据)时,并没有使用强大的 Transformer,而是用了一个非常简单的 MLP 网络(多层感知机)。
更具体地,adaLN-zero 通过完全覆盖注意力单元的输入,并注入任意偏置来覆盖输出,这限制了模型的表达能力,相当于「讨厌注意力操作」(hate the attention operation),从而削弱了 DiT 的整体潜力。

博主还提到与早期论文相关的 LayerNorm 研究,指出 LayerNorm 的偏置和增益参数可能对梯度调整影响更大,而非真正改善模型性能。他认为,adaLN-zero 正是利用了这一点,名为「梯度调节」,实则像是在「给小模型偷偷注入过拟合的偏置」。

-
论文标题:Understanding and Improving Layer Normalization
-
论文地址:https://arxiv.org/abs/1911.07013
看了这篇帖子,DiT 的作者,纽约大学计算机科学助理教授谢赛宁有些忍不住了。
在 2022 年,谢赛宁发表了 DiT 的论文,这是扩散模式首次和 Transformer 相结合。

-
论文标题:Scalable Diffusion Models with Transformers
-
论文链接:https://arxiv.org/pdf/2212.09748
在 DiT 问世之后,Transformer 逐步代替原始扩散模型中的 U-Net,在图像和视频生成任务中生成高质量的结果。
其核心思想是采用 Transformer 代替传统的卷积神经网络作为扩散模型的主干网络。
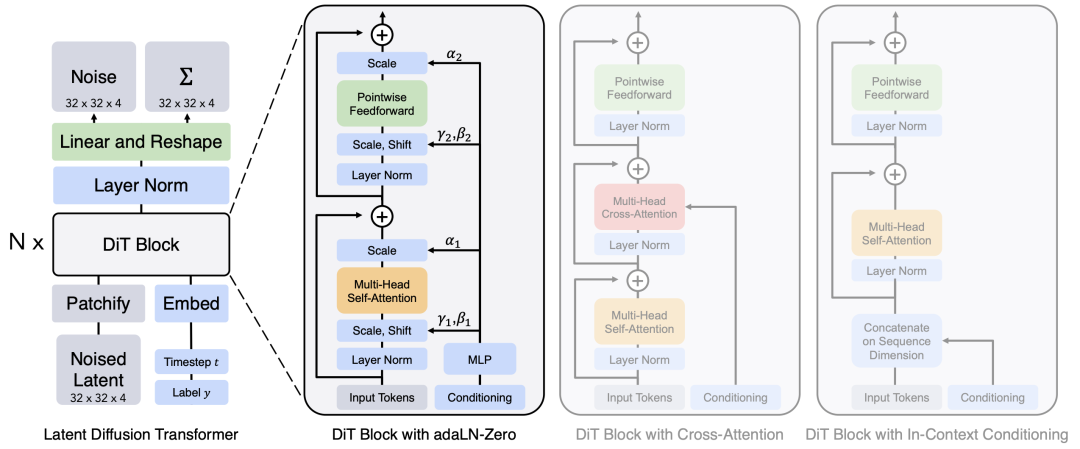
这一方法业已成为 Sora 和 Stable Diffusion 3 的基础架构,同时也确定了 DiT 的学术地位。
在 DiT 论文刚刚问世时,就已接连受到质疑,甚至以「缺乏创新」为由被 CVPR 2023 拒稿。
这一次面对 DiT 在数学和形式上都「是错的」的论调,谢赛宁发推做出了几点回应。

从字里行间来看,谢赛宁对这个帖子多少有些情绪:
我知道原帖是在钓鱼骗点击率,但我还是咬一下钩……
坦白讲,每个研究者的梦想其实就是发现自己的架构是错的。如果它永远都没问题,那才是真正的大问题。
我们每天都在用 SiT、REPA、REPA-E 等方法试图打破 DiT,但这需要基于假设、做实验、进行验证,而不是只在脑子里扮演式地做科学…… 否则,你得出的结论不仅仅是错的,而是根本连错都谈不上。
也难怪谢赛宁语气有些不善,原帖博主的一些说法可能有些拱火的嫌疑:
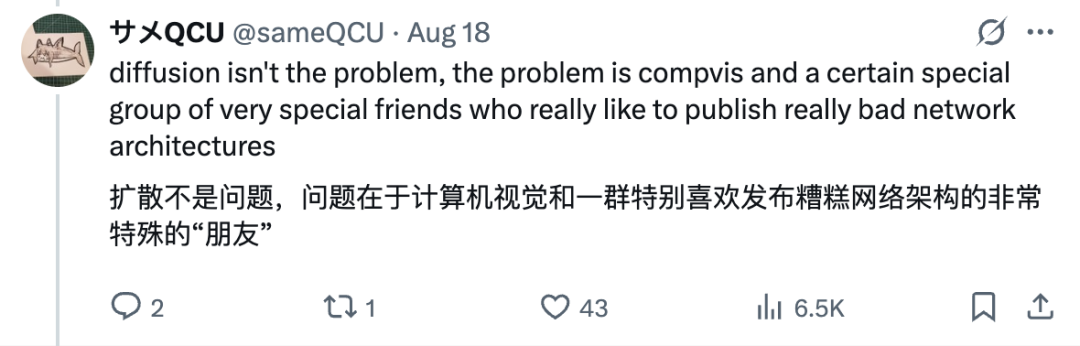

谢赛宁也从技术角度对于原帖子提出的一些问题进行了回复,在对原帖的部分问题进行了反驳后,他也同样说明了 DiT 架构目前存在一些硬伤。
截至今天,DiT 的问题:
-
tread 更接近于 stochastic depth,我认为它的收敛性来自正则化效应,这让表示能力更强(注意推理过程是标准的 —— 所有模块都会处理所有 token);这是非常有意思的工作,但和原帖说的完全不是一回事。
-
Lightning DiT 已经是经过验证的稳健升级版(结合了 swiglu、rmsnorm、rope、patch size=1),有条件就应该优先使用它。
-
没有任何证据表明 post-norm 会带来负面影响。
-
过去一年最大的改进点在于内部表示学习:最早是 REPA,但现在有很多方法(例如 tokenizer 层面的修正:VA-VAE / REPA-E,把语义 token 拼接进噪声潜变量、解耦式架构如 DDT,或者通过分散损失、自表示对齐等正则化手段)。
-
始终优先采用随机插值 / 流匹配(SiT 在这里应该是基线)。
-
对于时间嵌入,使用 AdaLN-zero;但遇到更复杂的分布(如文本嵌入)时,应采用交叉注意力。
-
不过要用对方式 —— 采用 PixArt 风格的共享 AdaLN,否则会白白浪费 30% 的参数。
-
真正的「硬伤」其实是 DiT 里的 sd-vae:这是显而易见却长期被忽视的问题 —— 它臃肿低效(处理 256×256 图像竟需要 445.87 GFlops?)、不是端到端的。像 VA-VAE 和 REPA-E 只是部分修复,更多进展还在路上。
评论网友也对回应中提到的技术细节感兴趣,谢赛宁也都对相关疑惑做出了回复:
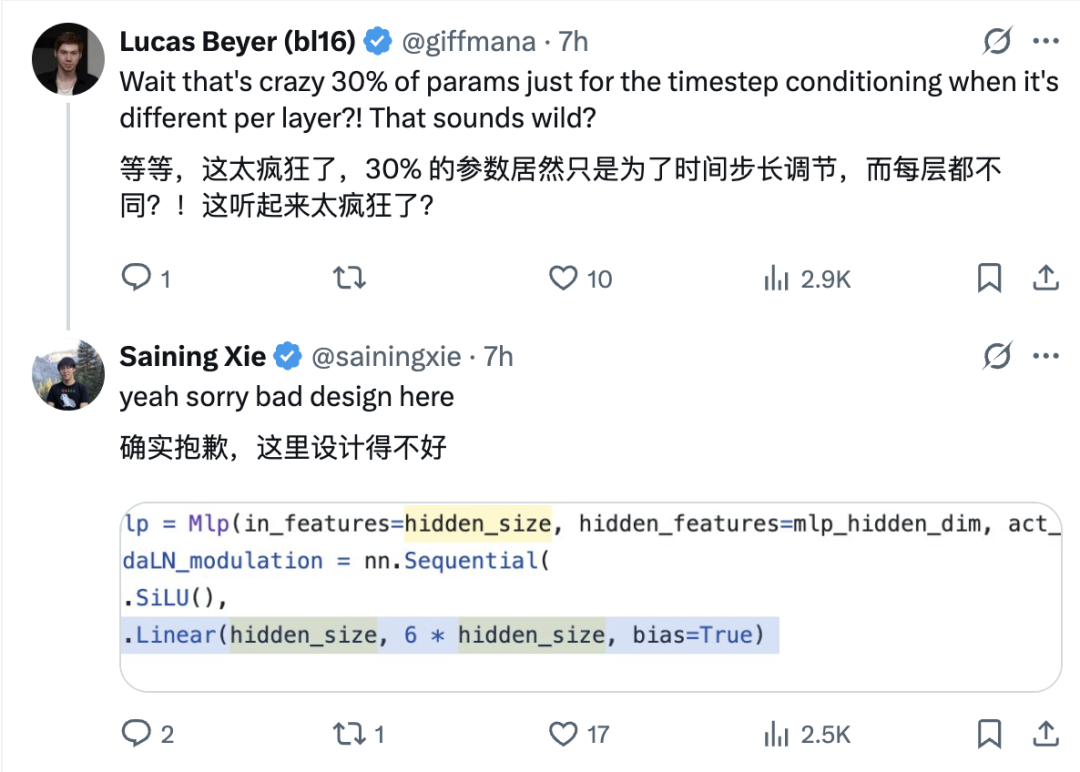
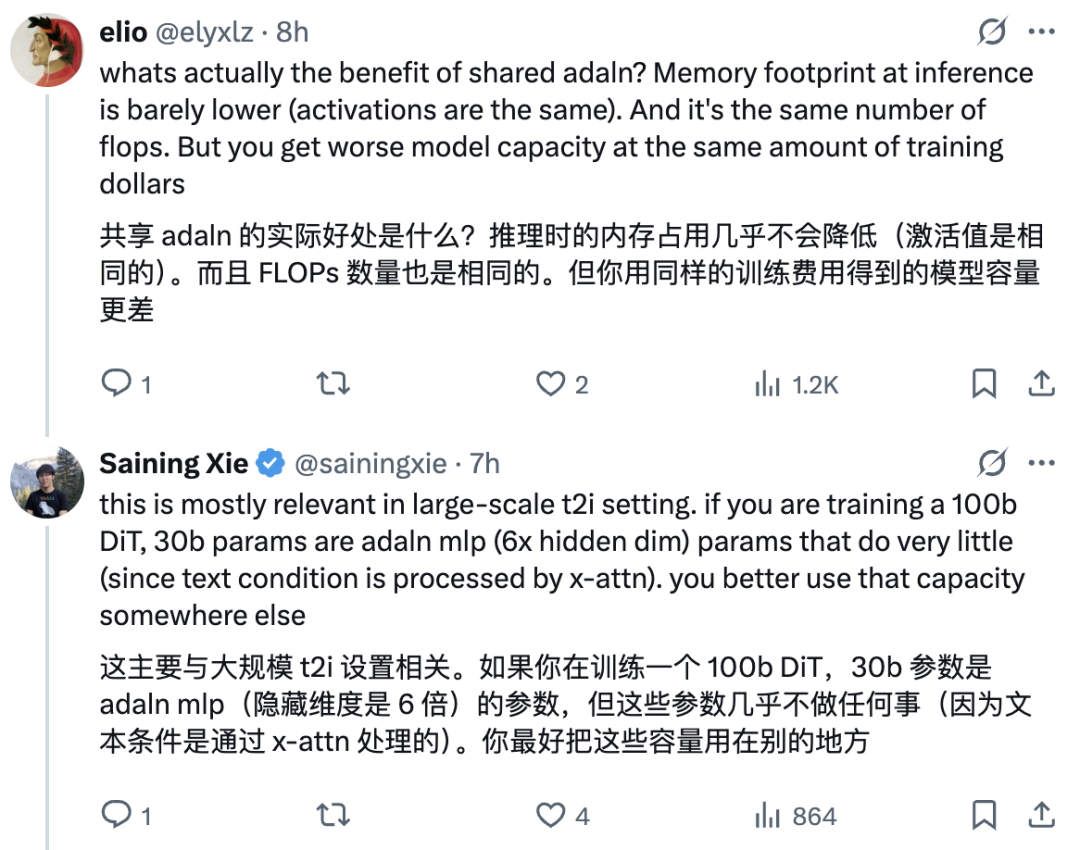
算法的迭代进步总是伴随着对现有算法的质疑,虽说所谓「不破不立」,但 DiT 仍然在擂台中央,不是么?

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com