RobustSplat通过延迟高斯致密化和尺度级联掩码,显著提升3DGS在动态场景的重建质量,减少伪影。
原文标题:ICCV 2025 | RobustSplat: 解耦致密化与动态的抗瞬态3DGS三维重建
原文作者:机器之心
冷月清谈:
为解决这一挑战,中山大学等团队提出了全新的鲁棒性解决方案 RobustSplat。其核心在于两大创新策略:
首先是首创延迟高斯生长策略。该策略旨在推迟高斯致密化操作,让模型优先专注于优化静态场景结构。通过在初期减少对动态物体的过拟合,它为后续的掩码学习提供了更加稳定和准确的基础。
其次是设计了尺度级联掩码引导方法。该方法首先利用DINOv2特征在低分辨率下进行初始的瞬态掩码估计,利用其卓越的语义一致性和抗噪声特性,确保初始判定的可靠性。随后,系统逐步过渡到高分辨率监督,以实现对动态区域的更精确预测,从而有效规避静态区域被误判的风险。
实验结果表明,RobustSplat在NeRF On-the-go和RobustNeRF等数据集上表现出显著优势,各项指标全面超越了现有的3DGS基线方法,能够有效处理复杂动态场景并保留丰富的细节。
怜星夜思:
2、RobustSplat通过“延迟高斯生长”和“尺度级联掩码引导”来处理动态场景,有效地提升了3DGS的重建质量。然而,这种改进是否会大幅增加模型的训练时间或推理时间?对于追求实时性应用的场景(例如AR/VR),RobustSplat的实际部署成本和可行性如何?
3、RobustSplat致力于消除动态物体在3DGS重建中引起的伪影。这自然引出了一个更深层次的伦理和真实性问题:在精确重建中“抹去”或“隔离”动态物体的信息,是否会在某些应用场景中引发关于数据真实性或“数字造假”的争议?例如,在证据记录、历史档案重建等对客观性要求极高的领域,这种处理方式是利大于弊,还是可能带来新的挑战?
原文内容

3DGS (3D Gaussian Splatting) 技术凭借在新视角合成与 3D 重建中实现的实时照片级真实感渲染,已成为研究热点。然而,现有方法在建模含动态物体的场景时精度不足,常导致渲染图像出现伪影。
在最近的一项研究中,来自中山大学、深圳市未来智联网络研究院、港中深的研究者提出鲁棒性解决方案 RobustSplat,其核心设计包含两点:一是首创延迟高斯生长策略,在允许高斯分裂 / 克隆前优先优化静态场景结构,从而减少优化初期对动态物体的过拟合;二是设计尺度级联掩码引导方法,先利用低分辨率特征相似度监督进行可靠的初始动态掩码估计(借助其更强的语义一致性与抗噪声特性),再逐步过渡到高分辨率监督,以实现更精准的掩码预测。

-
论文标题:RobustSplat: Decoupling Densification and Dynamics for Transient-Free 3DGS
-
论文链接: https://arxiv.org/abs/2506.02751
-
论文主页: https://fcyycf.github.io/RobustSplat
-
代码链接: https://github.com/fcyycf/RobustSplat
研究动机
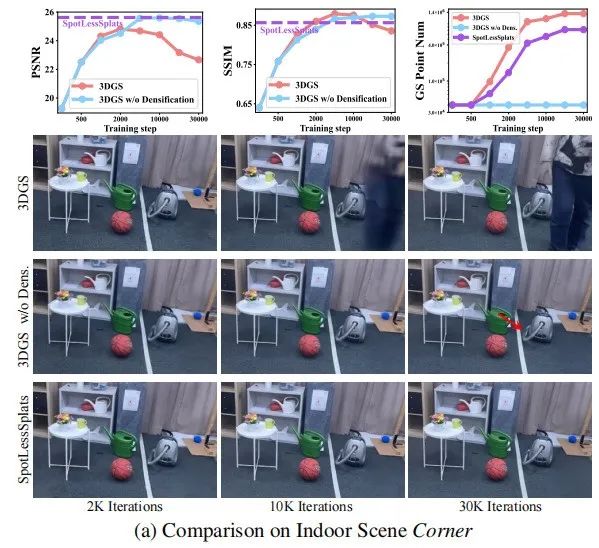
我们通过分析揭示了高斯致密化 (densification) 在 3D Gaussian Splatting 中的双重作用机制。具体来说,致密化过程在增强场景细节表达方面具有显著优势,但同时也会促使模型过早拟合动态区域,导致伪影和场景失真。这一发现表明,传统的致密化策略在存在有动态物体的场景建模中存在依赖性风险,即其所带来的细节提升可能以牺牲静态区域的重建质量和引入伪影为代价。

因此,本文的研究动机源于对该分析的深入理解,意在通过调节致密化过程的引入时机,有效平衡场景的静态结构表达与动态干扰的抑制。致密化既是优化细节的关键因素,也是动态干扰的放大器,为此提出「延迟高斯生长」策略,通过延后致密化过程实现静态部分的准确重建,同时结合多尺度掩码引导,系统抑制动态伪影,推动在复杂场景中实现鲁棒、细节丰富的 3D 场景重建。
方法
瞬态掩码估计
网络架构:采用含两层线性层的 MLP (Mask MLP),以图像特征为输入,通过 Sigmoid 函数输出逐像素的瞬态掩码 Mt(取值范围 [0, 1],0 表示瞬态区域,1 表示静态区域)。
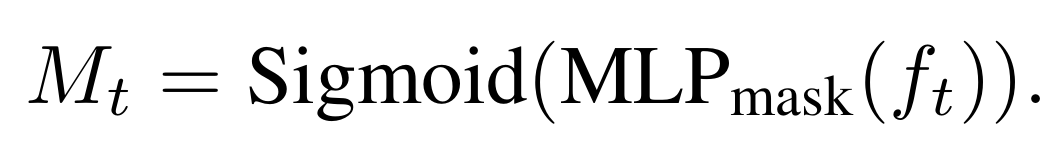
特征选择:选用 DINOv2 特征作为输入,原因是其在语义一致性、抗噪性和计算效率间取得很好的平衡。对比之下,Stable Diffusion 特征语义信息更强但计算成本高,SAM 特征边界精度高却易漏检瞬态物体的阴影区域,而 DINOv2 特征能稳定支撑掩码预测。
监督设计:掩码 MLP 的优化结合了图像残差损失和特征余弦相似度损失:使用基于渲染图像与真实图像的光度差异,捕捉像素级动态干扰,作为基础监督信号。在此基础上,将渲染图像与真实图像的 DINOv2 特征余弦相似度映射至 [0, 1] 范围作为特征监督,以增强语义级动态区域识别。
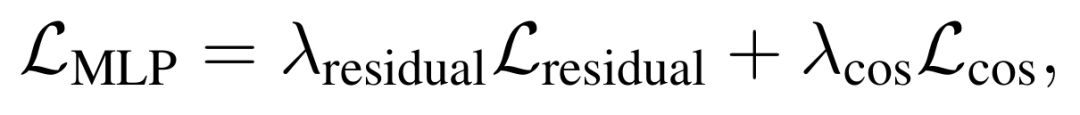
延迟高斯生增长策略
延迟高斯生长是 RobustSplat 针对 3DGS 优化中瞬态物体过拟合问题设计的核心策略,其核心思想是推迟高斯致密化过程(分裂 / 克隆操作),优先完成静态场景结构的优化,为掩码学习提供更稳定的基础。
掩码正则化:掩码正则化是针对早期优化阶段掩码估计不准确问题设计的关键策略,核心目标是减少静态区域被误分类为瞬态区域的风险,确保 3DGS 优先优化静态场景结构。
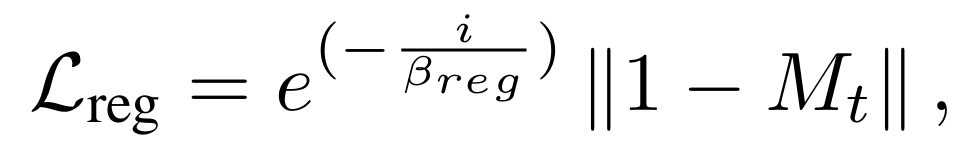
掩码学习的总损失:
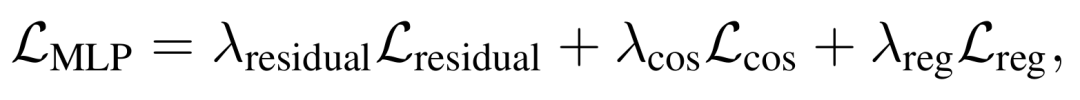
尺度级联掩码引导
先利用低分辨率特征相似性监督进行初始瞬态掩码估计,借助其强语义一致性和抗噪性;再过渡到高分辨率监督,实现更精确的掩码预测,降低静态区域误分类。
实验
下图分别展示了在 NeRF On-the-go 和 RobustNeRF 数据集上的实验结果。与 3DGS、SpotLessSplats、WildGaussians 等基线方法相比,RobustSplat 在 PSNR、SSIM、LPIPS 等指标上全面领先。


总结
通过实验分析发现,高斯致密化过程虽然提升了场景细节的捕捉能力,但也会生成额外的高斯来建模瞬态干扰,从而无意中导致了渲染伪影的产生。
RobustSplat 通过延迟高斯生长策略和尺度级联掩码引导方法,优化 3DGS 以减少瞬态物体导致的渲染伪影。
实验表明该方法在 NeRF On-the-go 和 RobustNeRF 数据集上,相比现有基线方法在各项指标上全面领先,能处理含多样瞬态物体的复杂场景并保留细节。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com