Higgsfield AI推出创新图生视频功能,用户在图片上“画两笔”即可让其动起来,告别文本提示,颠覆传统视频生成方式。
原文标题:图生视频新玩法刷爆外网:图上画两笔就能动起来,终于告别文本提示
原文作者:机器之心
冷月清谈:
Higgsfield AI还不断更新迭代,集成了诸多先进功能,如4K/8K视频画质提升、多参考图一致性、动作风格“窃取”以及一站式UGC内容构建工具。更值得一提的是,它还兼容并整合了多个主流视频生成模型如谷歌Veo 3和字节Seedance,打破了不同平台间的壁垒,提供统一便捷的创作体验。
公司的创始人Alex Mashrabov在生成式AI领域拥有丰富的背景,曾任Snap生成式AI负责人,并成功创业。Higgsfield AI 的出现,预示着空间提示将成为未来视觉交互的重要趋势,将用户从传统文本提示的限制中解放出来,有望引领个性化视频创作的新浪潮。
怜星夜思:
2、这类便捷的AI视频生成工具,对于广告、电影特效这类专业制作行业来说,是机遇还是挑战?会不会让很多人失业啊?或者是工作内容彻底变了?
3、文章里提到Higgsfield AI整合了谷歌Veo 3、字节Seedance等多种模型,这种“集成者”的模式在AI领域会成为主流吗?对于用户和开发者来说,是利大于弊还是反之?
原文内容
编辑:杜伟、杨文
现在,AI看你画的就能懂。
Higgsfield AI 这家公司,有点意思。
不仅三天两头上线新功能,在 X 上疯狂刷存在感,还一度被传出和 Meta 洽谈收购事宜,虽然最后不了了之。

据 The Information 报道,Meta Platforms 正在寻求与开发人工智能视频生成与编辑模型的初创公司建立合作关系,曾与视频生成初创公司 Higgsfield 探讨过潜在的收购事宜,但这些谈判目前已不再进行。
该公司专注于 AI 视频生成,最擅长电影级镜头控制技术,三个月前曾凭借 AI 运镜视频生成火出圈,我们还专门报道过:
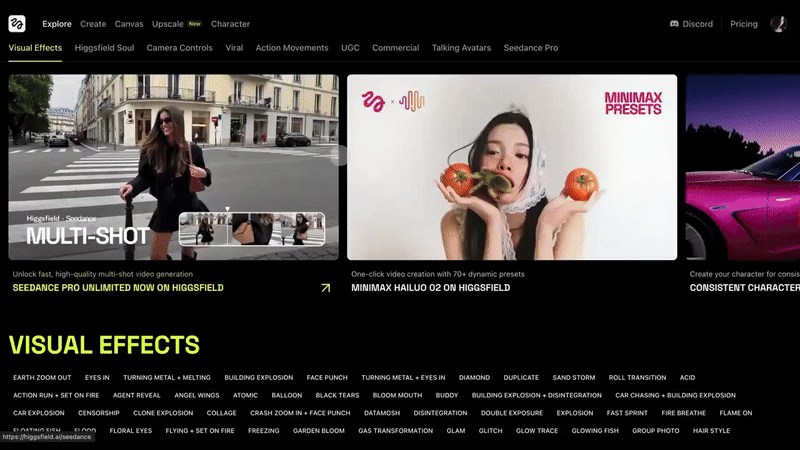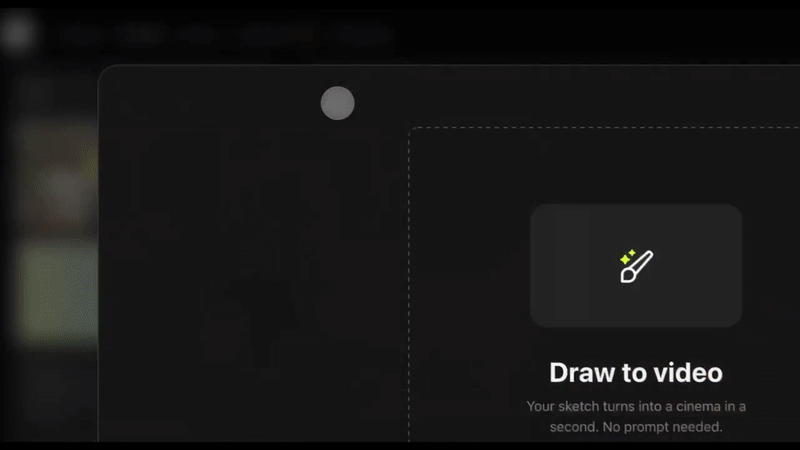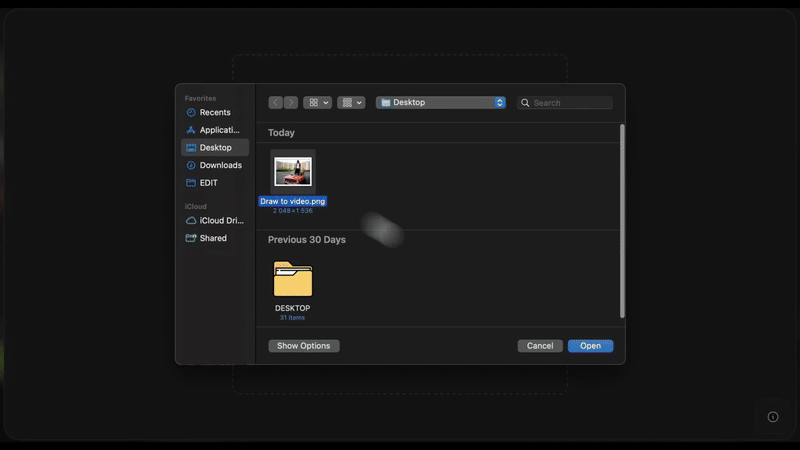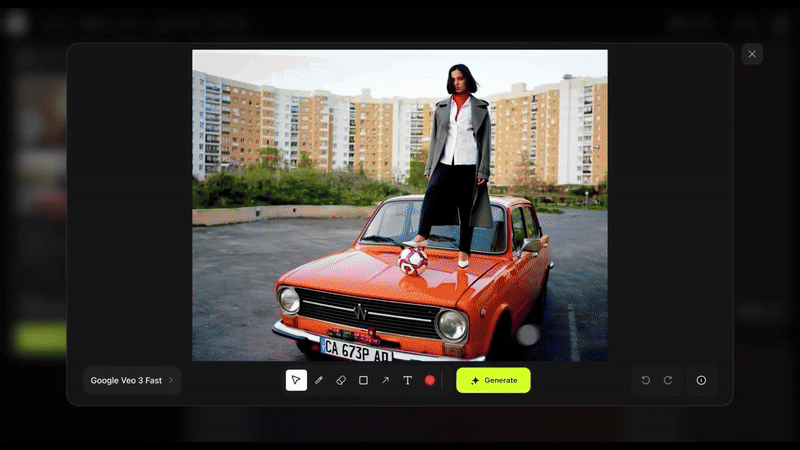
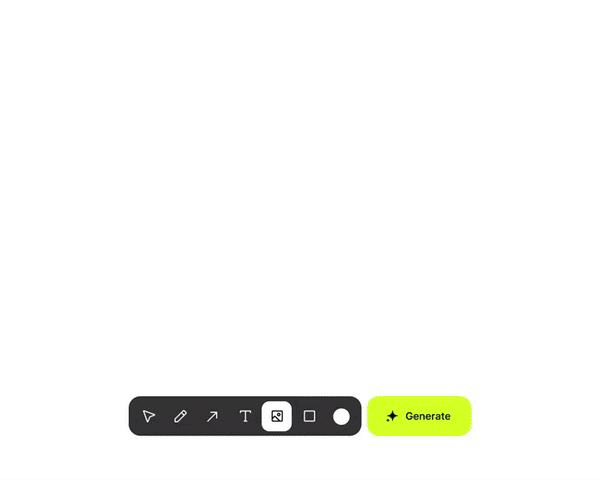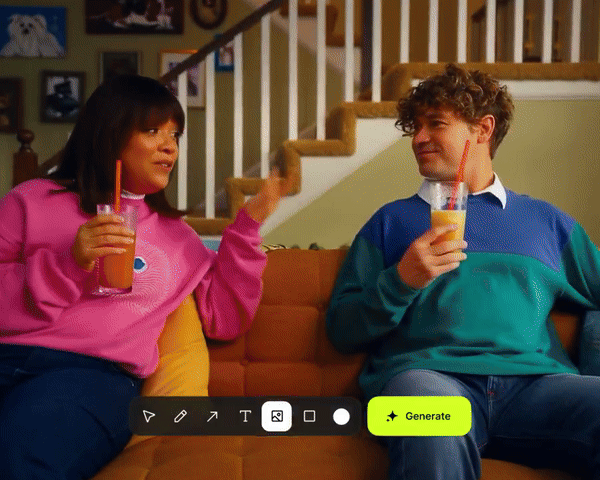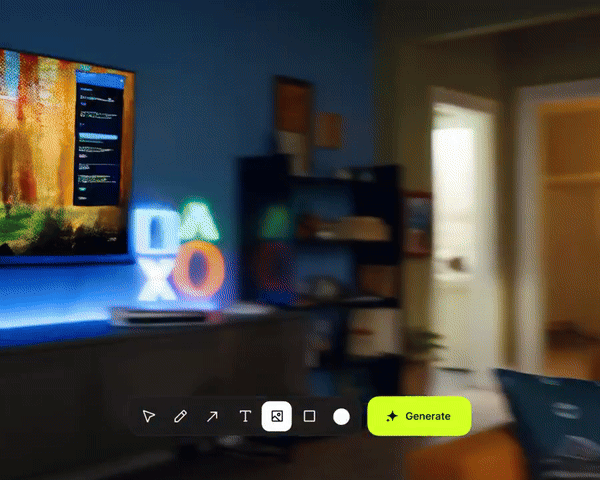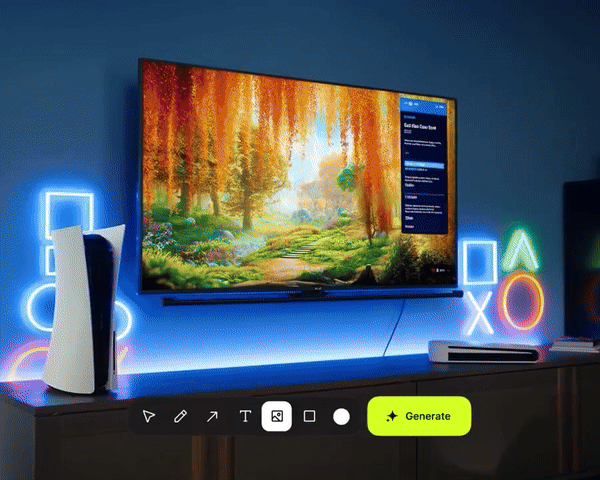
前几天,它又先后发布了 Draw-to-Video 和 Product-to-Video 功能。
前者只需上传一张静态图像,在上面绘制图形、文字或箭头等元素,即可生成具有电影质感的视频画面。该功能一经发布就在外网爆了,短短 4 天时间 X 上的浏览量就超 530 万。
后者则可以通过简单的拖拽操作,免费生成精美的、电影级的广告视频。截至目前也已在 X 上收获 160 万次浏览量。

如果再往前扒拉扒拉,你会发现这家公司几乎每周都会发布新功能或新模板。
8 月 6 日,上线 UPSCALE 功能,能够将模糊的图片和视频升级到 4K 或 8K 分辨率。
8 月 2 日,推出全新升级的多参考图功能,支持最多 4 张参考图输入,实现高度一致的角色呈现,并彻底消除随机伪影。配合 Higgsfield Soul 使用后,整体效果更为真实,还能一键更换肤色、背景、服装。
7 月 24 日,推出全新功能 STEAL,搭配 Soul ID 使用,可以让用户「偷取」他人的动作、表演风格等,并将其应用到自己的虚拟角色或视频中。
7 月 17 日,发布全新的 UGC Builder 工具,只需通过一个界面上传人脸、设定人物动作、语音、情绪和背景音乐,即可生成无需剪辑的完整电影场景。
……
而且,哪家模型火了,它转头就将其「纳入麾下」,比如 GPT-5、MiniMax、Veo 3、Seedance Pro 等。
打开 Higgsfield 的官网,密密麻麻都是视频功能和模板。
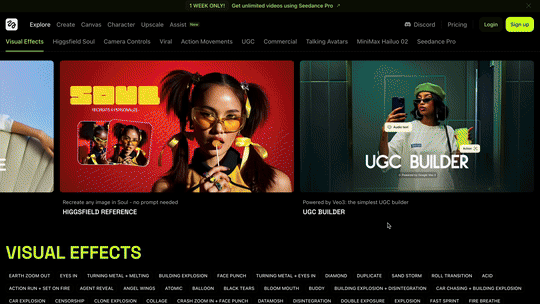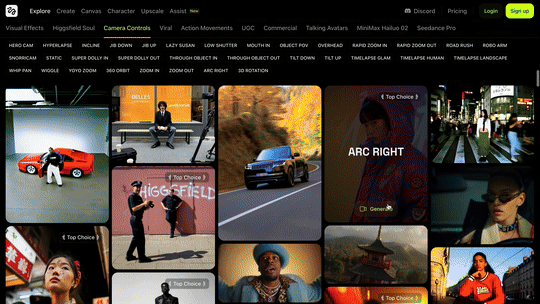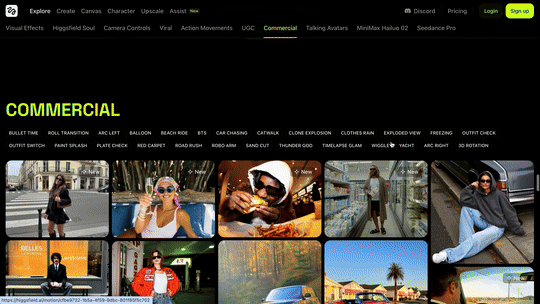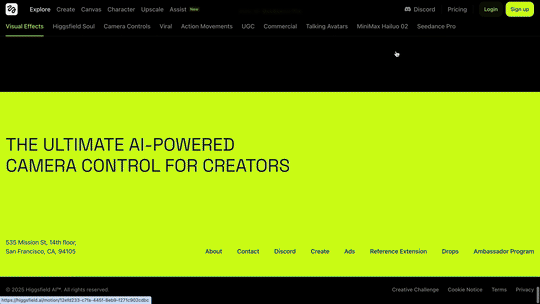
体验链接:https://higgsfield.ai/
网友一手实测
Higgsfield 的功能一上新,就有网友亲自上手体验,整出了不少花活。
就以最新的 Draw-to-Video 为例。
其玩法相当简单。打开 Higgsfield AI 官网,选择 Create-Draw to Video,上传任意一张图片。
然后直接在画面上绘制箭头、图形等元素,并输入动作指令,比如「演员跑进来」、「这里爆炸」或「镜头移动」,AI 会立即执行,并生成极具真实感的动态画面。
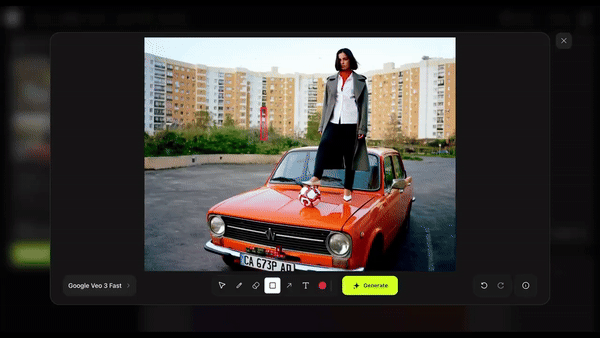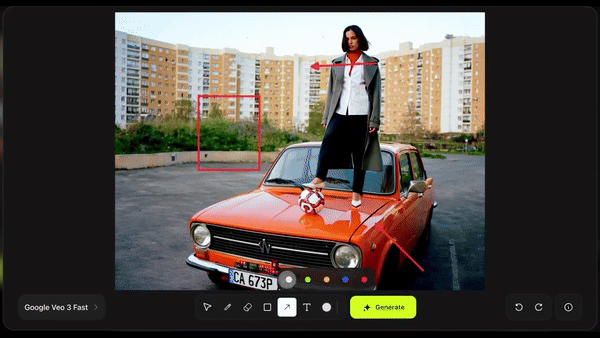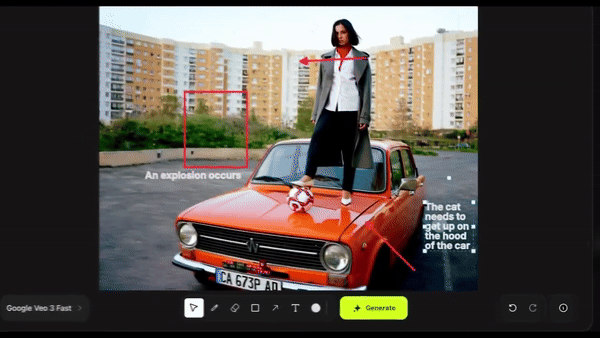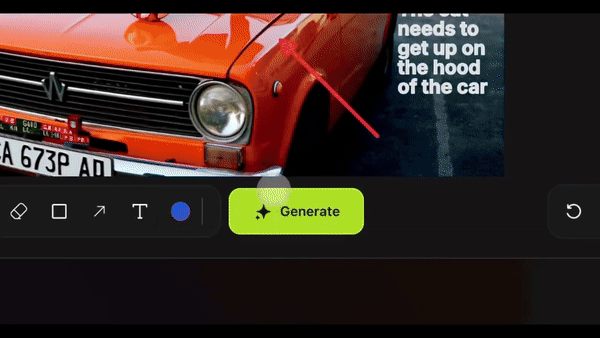
过去需要工作室、演员和高昂成本的大片场景,如今只需几分钟就能完成。它可以凭空生成一只猫,还能自由控制镜头运动和演员的入场位置。

为了生成效果更佳,有网友总结出一个教程。
使用 Higgsfield 的 Draw-to-Video 时,要先确保图片主体清晰,若需要加入人物或物体,可以提前去掉背景,用透明 PNG 格式。
画箭头可以清晰指示人物或物体的出现方向,画爆炸标记可以很好地引导爆炸场景。在画布上直接写文字提示,能显著提升成功率。如果有出现顺序,务必清晰写明 「Step 1, Step 2, Step 3」,避免 AI 出错。
在价格上,使用Seedance Pro 的 480p 生成 5 秒视频是免费的,其他如 Hailuo02、Seedance Pro 和 Veo3 都有不同分辨率和时长对应的点数消耗。其中最贵的是 Veo3 ,标准版本 720p 分辨率需要 150 个点数。
因此,我们可以先用免费 480p 版本不断尝试和调整提示词,满意后再生成 720p 或更高分辨率,最后通过 Upscale 功能提升清晰度,就能在保证质量的同时最大限度降低成本。
在此基础上,Higgsfield 又推出了 Product-to-Video 功能,只需上传一张人物照片,然后拖拽产品图片、添加文字,就能生成广告大片。
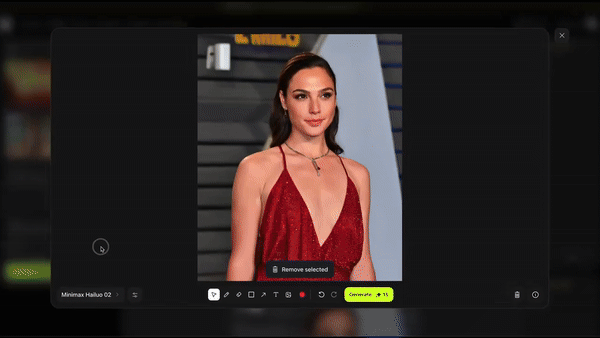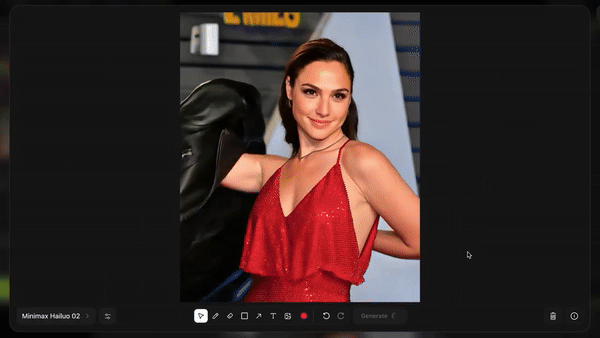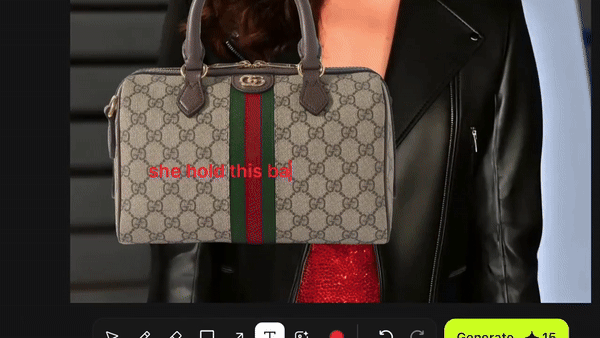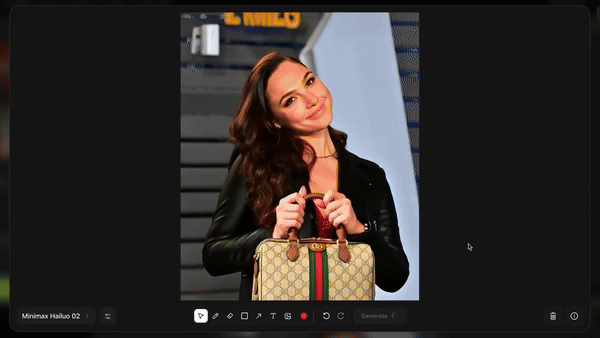
比如让金刚狼从冰箱里掏出一瓶可口可乐:

甜茶在线安利巧克力:

此外,该功能还有四大亮点:
1. 它支持谷歌 Veo 3、字节 Seedance、MiniMax Hailuo02 等视频生成模型,无需切换不同平台,只在一个界面就能完成图像和视频的创作。

2. 可以在成片基础上叠加特效(Effects)、Flux Kontext、UGC Builder 等功能模块,进一步丰富广告内容。
3. 还能添加片头 / 片尾帧,或用「修补(inpaint)」来精细修改。
4. 渲染速度更快,不再需要繁琐的导入导出。
看了一圈网友生成的效果,感觉还不错,感兴趣的朋友可以去体验一下。
公司及创始人介绍
根据公开资料显示,Higgsfield AI 创立于 2023 年 10 月,总部位于美国旧金山,专注于为内容创作者打造个性化 AI 视频工具。目前,团队规模约为 11-50 人。
2024 年 4 月,Higgsfield AI 完成了由 Menlo Ventures 领投的 800 万美元种子轮融资,用于推动视频生成工具、社交媒体创作平台的发展。2025 年 8 月,Meta 被传出曾与 Higgsfield AI 进行过收购层面的讨论,但最终不了了之。
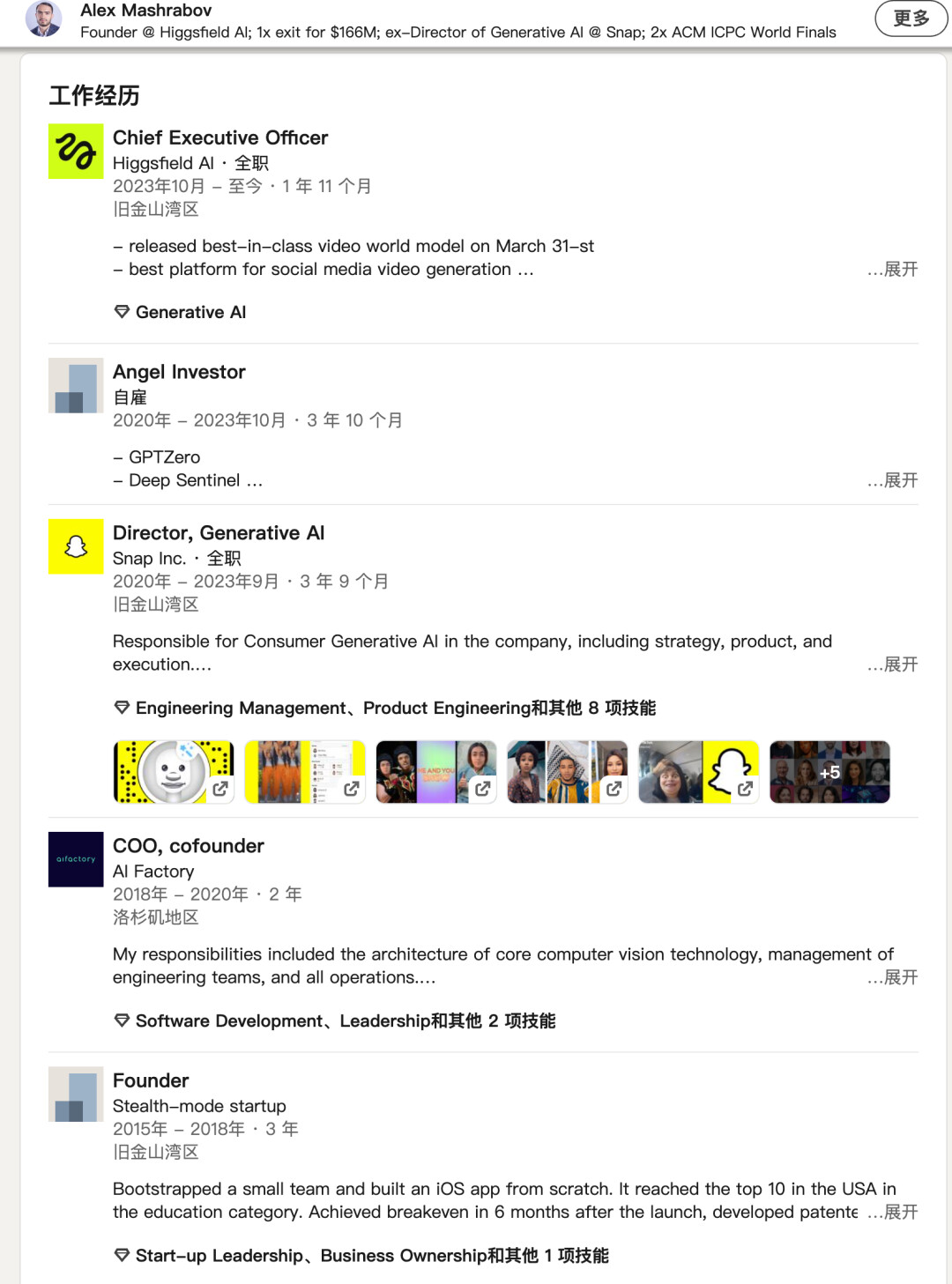
公司创始人兼 CEO Alex Mashrabov 此前曾任 Snap 公司(以构建顶级社交媒体应用 Snapchat 而闻名)的生成式 AI 负责人,旗舰负责开发 MyAI 对话式聊天机器人、生成式 AI 增强现实(AR)特效、Cameos Stories(个性化的 AI 驱动的视频内容形式)以及 3D 合成数据框架。
而更早之前他创立的图像和视频识别公司 AI Factory 以 1.66 亿美元的金额被 Snap 收购。
2023 年 9 月,Alex Mashrabov 从 Snap 离职并开始自己创业。
自创立以来,Higgsfield AI 先后推出了旗舰产品 Diffuse、Diffuse 2.0,支持用户免费上传单张自拍照或输入文本,利用最新的生成式 AI 技术来生成个性化视频内容,甚至用户自己自然地插入场景中。

图源:https://www.trydiffuse.com/
2025 年 3 月,Higgsfield AI 推出了最新的视频生成模型 DoP I2V-01-preview,以专业级镜头控制、世界建模和电影级叙事意图为主要特征,尤其在精准性、真实性与风格表现力方面出色。

此外,Higgsfield AI 还对世界模型有所涉猎。今年 4 月,Mashrabov 曾表示,「我们正在构建世界模型,它可以提供顶级的视频生成与编辑体验,并能实现直观的细粒度控制。」
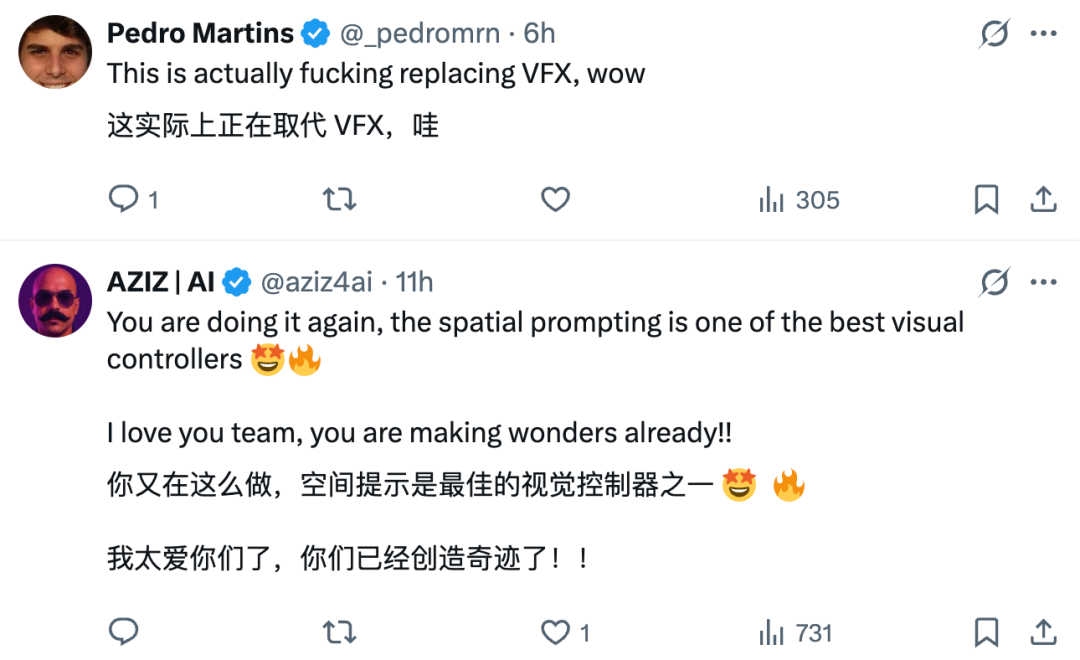
此次推出的 Draw-to-Video 功能更是 Higgsfield AI 在生成式视频交互方式上的一次突破,将用户从「写文本提示词」的困扰中解放出来,通过简单的图形动作(比如箭头)指引就能完成直观的创作。
网友盛赞,终于不用后期加特效了。而相比于文本提示,空间提示将成为最佳的视觉控制器之一。
参考链接:
https://www.aibase.tech/news/higgsfield-ai-is-bringing-personalized-video-creation-to-the-masses/?utm_source=chatgpt.com
https://x.com/higgsfield_ai/status/1955742643704750571
https://x.com/EHuanglu/status/1955762111344517310
https://x.com/MayorKingAI/status/1956823869689680247
https://x.com/KanaWorks_AI/status/1956589544285106617

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com