4DNeX创新实现单图生成动态四维场景,利用真实世界数据,高效地产出高保真时空视频,超越现有方法。
原文标题:一张图,开启四维时空:4DNeX让动态世界 「活」起来
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到4DNeX大规模使用了“真实采集的数据”进行训练,并能实现“反事实”推演。那么,当这种技术普遍应用后,大家觉得它对内容创作、信息传播甚至社会信任会带来哪些潜在的挑战或伦理问题?比如,生成高保真的“时空视频”会不会让“眼见为实”变得越来越不可靠,或者加剧深度伪造(Deepfake)的风险?
3、4DNeX在“数据”和“表征”方面取得了显著突破,特别是构建了4DNeX-10M数据集和提出了6D统一表征以及“宽度融合”策略。那么,对于“架构”这个研究方向,也就是如何更好地继承现有模型先验、保障高质量输出,你们认为未来还有哪些值得探索和改进的空间?比如说,有没有可能结合其他更先进的神经网络结构,或者探索新的训练范式?
原文内容

仅凭一张照片,能否让行人继续行走、汽车继续飞驰、云朵继续流动,并让你从任意视角自由观赏?
南洋理工大学 S-Lab 携手上海人工智能实验室,给出肯定答案 ——4DNeX。作为全球首个仅依赖单张输入即可直接输出 4D 动态场景的前馈(feed-forward) 框架,4DNeX 摆脱了游戏引擎与合成数据的束缚,首次大规模利用真实世界动态影像进行训练,实现「时空视频」的高效、多视角、高保真渲染。
在多项基准测试中,4DNeX 以显著优势超越 Free4D、4Real 等当前最佳方法,真正把「一张图生成四维世界」的科幻概念带进了现实。
-
论文链接:https://4dnex.github.io/4DNeX.pdf
-
项目主页:https://4dnex.github.io/
1. 研究背景
世界模型正成为 AI 研究的高频热词。 Google DeepMind 近期迭代的 Genie 3 已能在高质量游戏数据上生成长达数分钟的交互式视频,但目前尚且缺乏在诸多真实场景上的验证。
世界模型发展的一个重要拐点在于:让模型学会刻画我们身处的动态 3D 世界,并服从其物理定律。 唯有如此,生成的内容才能既逼真又可导,进而支持「反事实」推演 —— 在虚拟中重放、预测甚至改写现实。这一能力不仅可构成下一代 AR/VR 与具身智能的重要研究基石,更是迈向可信 AGI 的必经之路。
构建 4D 世界模型的关键能力,在于能否持续产出高保真、可扩展的 4D 内容,其主要在于以下三个方面的研究:
-
数据 – 相较于游戏等引擎合成的数据,真实采集的数据虽能保留物理属性,却难以大量获取,更难标注;
-
表征 - 如何兼顾不同模态(如材质和几何等)特性,设计选取高效的 3D/4D 表征仍是学界长久未竟的科研命题;
-
架构 – 当前的不同生成模型架构互有优劣,如何更好地继承现有模型先验,保障高质量仍需探索。
鉴于此,「真实高效」的 4D 世界模型构建非常重要,也充满挑战。
2. 4DNeX-10M Dataset
近千万帧带 4D 标注的视频集
为破解高质量真实 4D 数据稀缺的瓶颈,4DNeX 首度发布 4DNeX-10M—— 近千万帧、多场景、带伪标签的超大规模 4D 视频数据集。其覆盖室内外环境、自然景观与人体运动等多元主题,尤以海量「以人为中心」的 4D 数据为特色,囊括丰富的物理属性、动态细节与交互行为,为 4D 世界模型的构建奠定坚实基础。

图 1 4DNeX-10M Dataset 包含了不同来源且丰富多样的动态数据
为支撑 4DNeX-10M 的构建,研究者们同步设计了一条全自动的数据–标注管线(见下图)。
-
数据源:单目实拍视频数据,其中动态场景取自 Pexels、Vimeo 等公开视频库;静态场景则整合 RealEstate-10K、DL3DV 等。
-
首轮清洗:基于光流一致性、亮度统计、运动强度及 OCR 文字检测,剔除低质片段。
-
标签制作:
-
内容:LLaVA-Next Video 给视频片段打标。
-
几何:静态场景使用 Dust3R 三维重建,动态场景使用 Monst3R / MegaSam 四维重建,输出 Semi-Dense 3D/4D 点云图、几何标签。
-
质量把关:联合置信度(MCV、HCPR 等)与运动平滑度等多重阈值,筛除几何漂移或动态异常序列。
最终打标完成的 4DNeX-10M 数据集构成如图右下角统计所示。
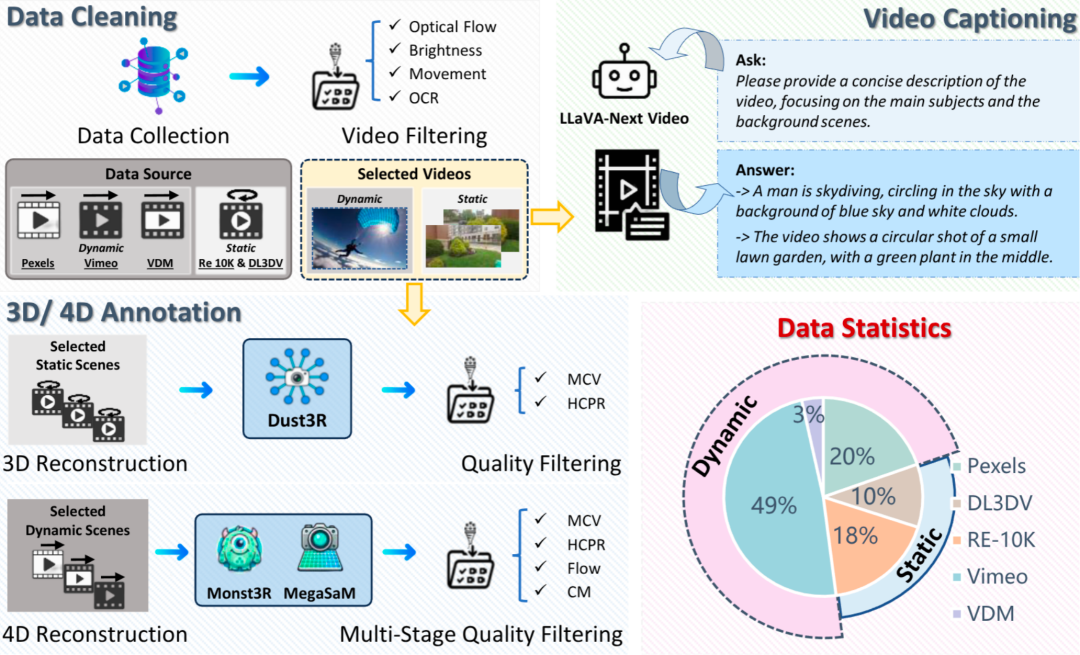
图 2 4DNeX-10M 构建管线以及数据统计情况
3. 4DNeX 方法架构
表征选取
在 4D 内容生成中,传统「4D」指 3D 空间几何外加时间轴;而在世界模型的语境下,RGB 视频携带的材质、光照与语义信息同样关键。4DNeX 因而提出 6D 统一表征:以 RGB 序列刻画外观(3 维)并以 XYZ 序列编码几何(3 维)。该设计无需显式相机控制,即可同步生成多模态内容,兼顾真实感与物理一致性。
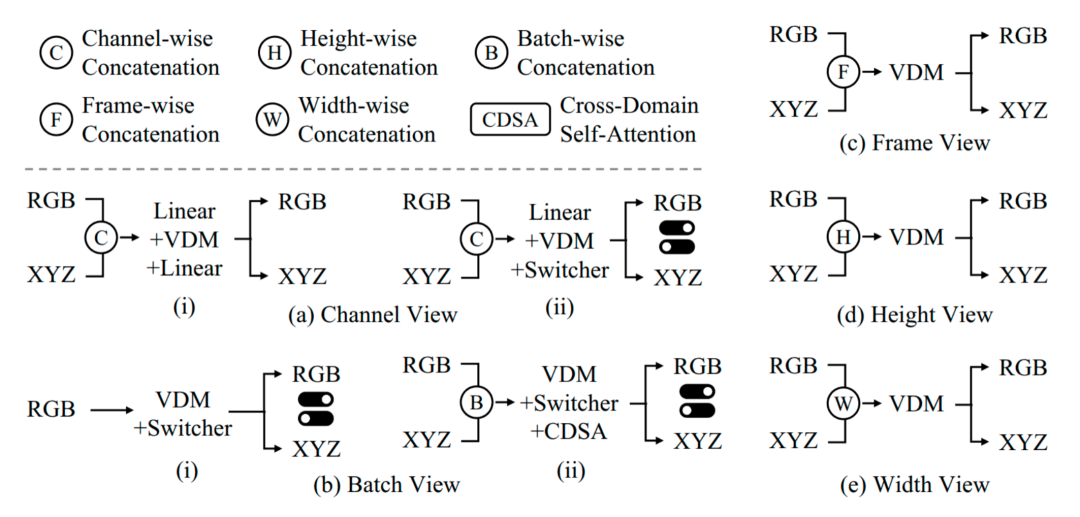
图 3 不同的 RGB 和 XYZ 模态融合策略
算法框架
4DNeX 框架的技术突破在于「宽度融合」这一关键策略:系统比较五种方案后,研究者们发现将 RGB 与 XYZ 在 token 宽度维度直接拼接,可将跨模态距离压到最低。 相比之下,通道融合会扰乱预训练分布,批处理融合又无法保证对齐。
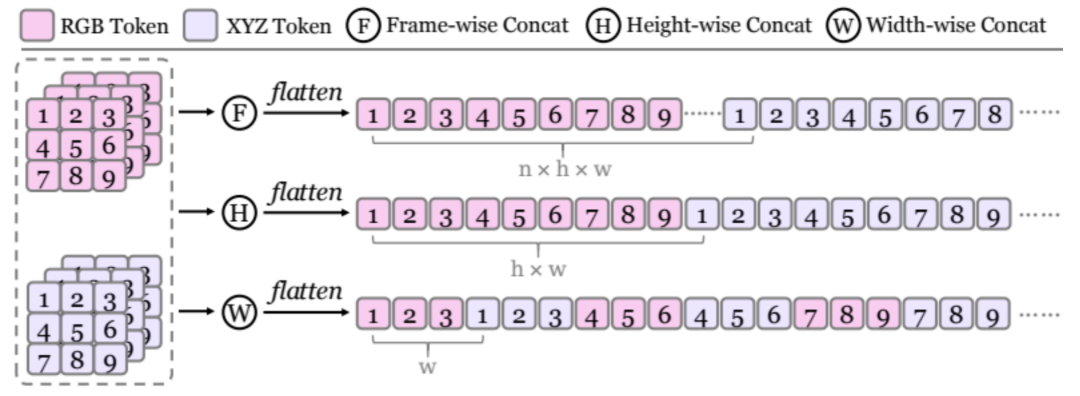
图 4 不同的空间融合策略对比
网络骨架沿用 Wan2.1 视频扩散模型,通过轻量级 LoRA 微调完成适配,主要的策略包括有:
-
输入端以斜坡深度初始化,先验地逼近自然场景的深度梯度;
-
XYZ 坐标经归一化校正,彻底消除 VAE 潜在空间的分布错位;
-
软掩码机制在扩散过程中动态约束几何细节,引导结构收敛;
-
旋转位置编码维持像素级 RGB-XYZ 对齐。
最后,仅需一次轻量重投影即可反算出相机参数,确保输出在物理层面严密自洽。
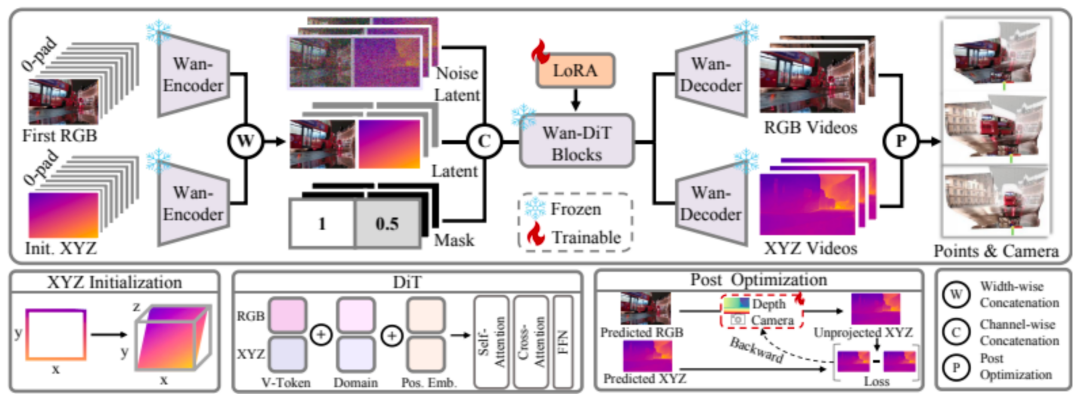
图 5 4DNeX 框架总览
4. 实验结果
实验验证显示 4DNeX 在效率与质量上实现双重突破:VBench 测试中,其动态幅度达 100%(超越 Free4D 的 40.1%),时空一致性 96.8% 领先业界。用户研究(23 人评估)更显示 85% 用户偏好其生成效果,尤其在运动幅度与真实感方面优势显著。
生成效果可视化证明模型能力 —— 单图输入可输出连贯动态点云序列(图 5),新视角合成在真实场景(in-the-wild)中保持几何一致性(下图 6);与 Animate124、4Real 等基线对比(下图 7),4DNeX 在树叶摇曳幅度、人体动作自然度等细节表现更优。
图 6 4DNeX 生成的视频效果(RGB & Point Map)
图 7 4DNeX 生成未经训练真实世界视频的新视角视频

图 8 4DNeX 对比其他方法的生成效果
User Study 用户调研结果显示 4DNeX 生成的效果优于 Free4D、4Real、Animate124、GenXD 方法。
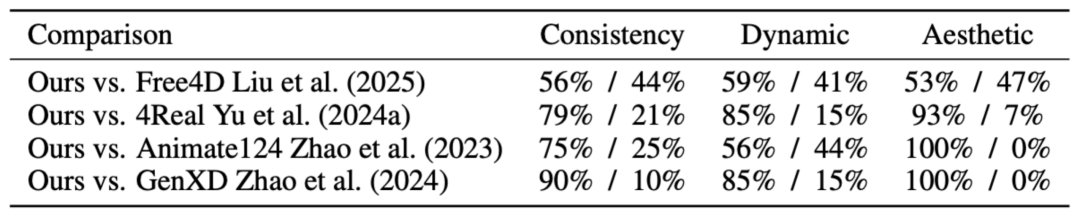
表格 1 User Study 结果对比
消融实验
研究者们还对比了五种融合 RGB 以及 XYZ 的策略,以发现最佳的多模态融合策略。实验一步证实宽度融合策略的关键作用,消除其他方案(如通道融合)的噪声或对齐失败问题。
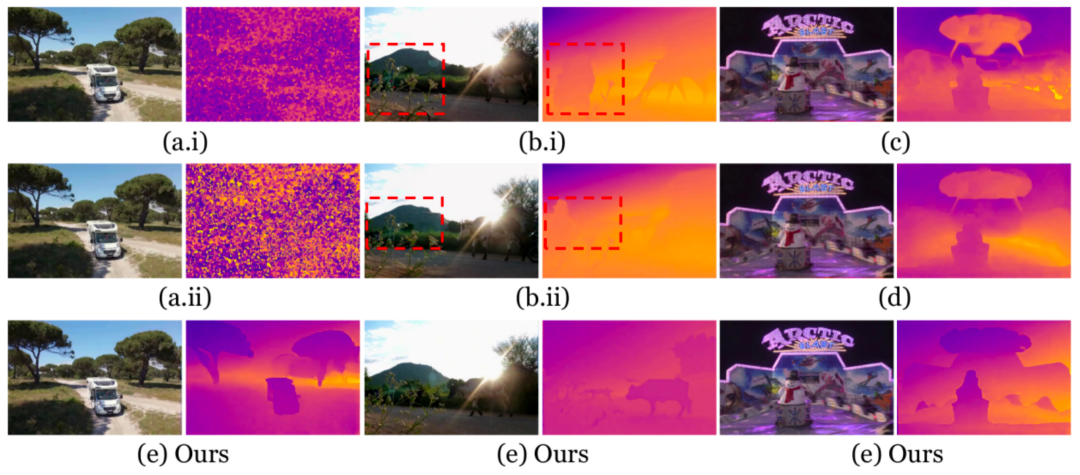
图 9 不同融合策略的结果可视化展示

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com