全面综述视觉强化学习进展,聚焦其在多模态大模型、视觉生成、VLA应用的前沿与挑战,指引未来研究方向。
原文标题:面向视觉的强化学习综述
原文作者:数据派THU
冷月清谈:
文章指出,视觉RL与多模态大模型的结合已在视觉-文本推理、GUI自动化、机器人操作和具身导航等任务中取得了显著成就,大幅提升了特定任务性能。此外,强化学习也在基于扩散的视觉生成模型中得到应用,用于提升生成结果的语义一致性与视觉质量,并驱动统一模型实现更强的泛化与任务迁移能力。尽管进展显著,该领域仍面临若干核心挑战,包括在复杂奖励信号下稳定策略优化、处理高维多样化视觉输入,以及设计可扩展的奖励函数以支持长时序决策。文章最后回顾了评估协议,并提出了样本效率、泛化能力与安全部署等开放挑战,展望了更高效多模态推理、稳健长时序学习策略及高保真奖励信号等未来研究方向。
怜星夜思:
2、文章中多次提及视觉强化学习,特别是结合生成模型和动作模型时,面临着“安全部署”的挑战。在像机器人操作、自动驾驶这类场景下,你觉得视觉强化学习的“安全部署”具体会面临哪些意想不到的风险?除了技术层面的缺陷,还有没有更深层次的问题?
3、文章提到了“统一模型框架”能实现“泛化与任务迁移能力”。未来,你觉得是否有可能出现一个真正意义上的“统一”视觉强化学习模型,它能够像人类一样,跨越理解、生成、行动等多种视觉任务,甚至适应完全陌生的环境和领域?如果能实现,你认为达到这种“通用视觉智能”最大的技术瓶颈会是什么?
原文内容

来源:专知本文约2000字,建议阅读5分钟我们的目标是为研究者和从业者提供一幅连贯的视觉RL领域全景图,并突出未来值得探索的方向。

https://arxiv.org/abs/2508.08189
1 引言
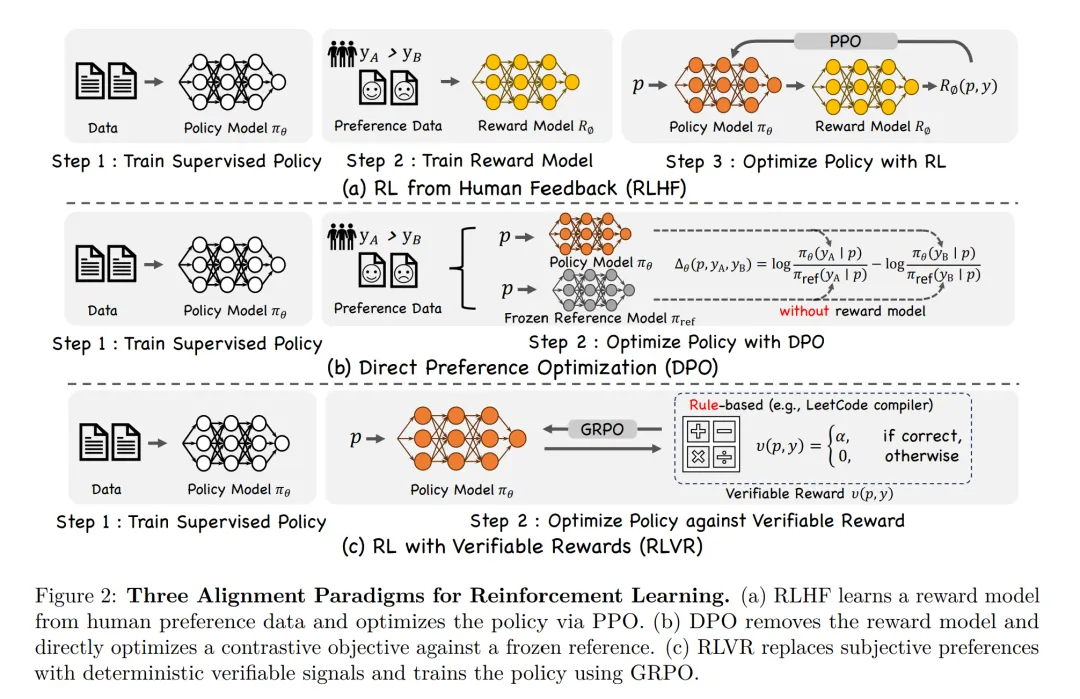
强化学习(Reinforcement Learning,RL)在大型语言模型(Large Language Models,LLMs)领域取得了显著成功(Jaech 等,2024;Rafailov 等,2023),其中最具代表性的范式包括基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)(Ouyang 等,2022)以及诸如 DeepSeek-R1(Guo 等,2025a)等创新框架。这些方法显著增强了 LLM 的能力,使生成结果更贴近人类偏好,并赋予其通过单纯监督学习难以获得的细腻、复杂的推理与交互能力。
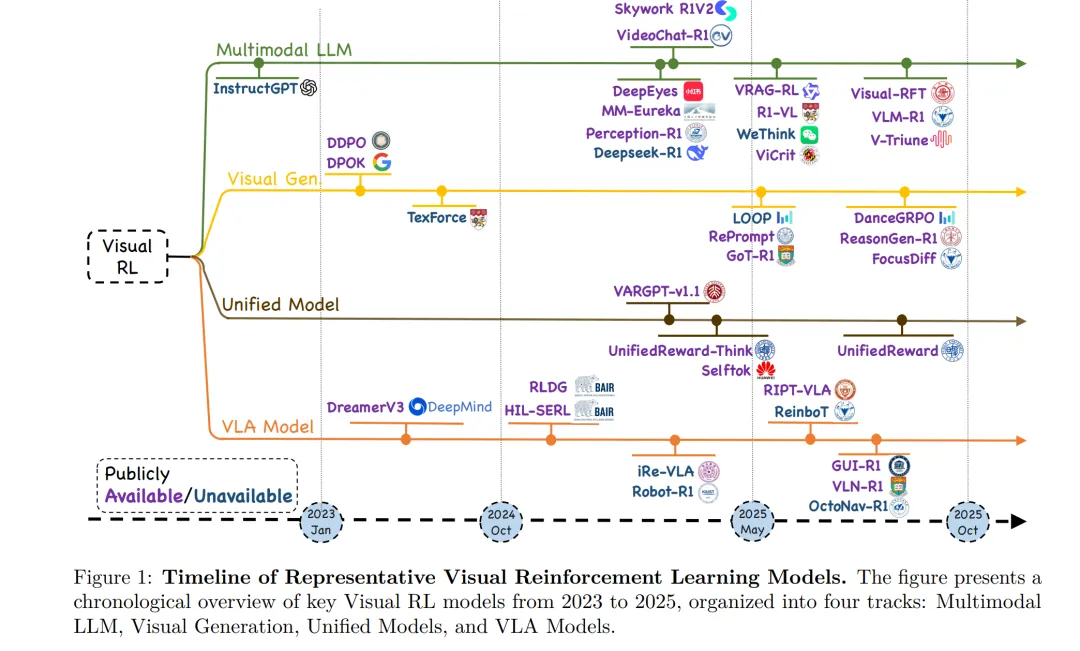
近年来,受 LLM 成就的启发,研究界对将这些在 LLM 上取得成功的 RL 方法扩展至多模态大模型产生了爆炸性兴趣,包括视觉-语言模型(Vision-Language Models,VLM)(Zhou 等,2025a;Zheng 等,2025;Zhang 等,2025f)、视觉-语言-动作模型(Vision-Language-Action,VLA)(Lu 等,2025b;Tan 等,2025b;Luo 等,2025;Yuan 等,2025b)、基于扩散的视觉生成模型(Fan 等,2023b;Black 等,2023;Zhou 等,2025c)以及统一多模态框架(Mao 等,2025;Wang 等,2024b;2025a)(如图 1 所示)。例如,Gemini 2.5(DeepMind,2025)等多模态模型利用 RL 来对齐视觉-文本推理过程,从而生成具有更高语义一致性且更契合人类判断的输出。同时,集成视觉与语言并生成面向动作输出的 VLA 模型,也已采用 RL 来优化交互式环境中的复杂序列决策过程,在 GUI 自动化(Yuan 等,2025b;Shi 等,2025)、机器人操作(Lu 等,2025b)以及具身导航(Kim 等,2025)等任务中显著提升了特定任务性能。
基于扩散的生成模型的快速发展进一步推动了这一 RL 驱动的创新浪潮。例如,ImageReward(Xu 等,2023)将强化学习引入生成过程,以提升生成结果的语义一致性与视觉质量,通过基于人类偏好或自动化奖励评估器的迭代反馈机制来优化扩散生成。此外,将理解与生成等多种任务统一到单一架构中的统一模型(Mao 等,2025;Jiang 等,2025b)也越来越多地依赖于 RL 驱动的微调,从而实现了此前被认为具有挑战性的泛化与任务迁移能力。
尽管 RL 与多模态大语言模型的结合已取得了重大进展,但仍存在若干核心挑战,包括:在复杂奖励信号下稳定策略优化、处理高维且多样化的视觉输入,以及设计可扩展的奖励函数以支持长时序决策。应对这些挑战,需要在算法设计与评估协议上同时进行方法学创新。
在本综述中,我们系统总结了 2024 年以来多模态大模型视觉强化学习领域的最新进展。我们首先回顾了 LLM 中奠定多模态适配基础的 RL 成功案例,如 RLHF(Ouyang 等,2022)与 DeepSeek-R1(Guo 等,2025a)。随后,我们讨论这些策略在视觉领域的演化过程,并将 200 余篇代表性工作划分为四大类别:(i)多模态大型语言模型,(ii)视觉生成,(iii)统一 RL 框架,以及(iv)视觉-语言-动作智能体(如图 1 所示)。在每个类别中,我们分析了算法设计、奖励建模以及基准测试方法的关键进展。最后,我们指出了开放挑战与未来研究方向,包括更高效的多模态推理、适用于 VLA 任务的稳健长时序学习策略,以及面向视觉生成的可扩展高保真奖励信号需求。
本文的主要贡献如下:
-
系统性与最新性:我们提供了一份涵盖 200 余篇视觉强化学习研究的系统化、最新综述,涵盖多模态大型语言模型、视觉生成、统一模型以及视觉-语言-动作智能体。
-
关键技术分析:我们分析了各子领域在策略优化、奖励建模和基准测试方面的进展,揭示了奖励设计在视觉生成中的挑战,以及推理和 VLA 任务中缺乏中间监督等问题。
-
方法学框架:我们提出了一种基于指标粒度与奖励监督的视觉 RL 方法分类体系,包括三种图像生成奖励范式。该框架阐明了跨领域设计的权衡,并为选择与开发 RL 策略提供了可操作的参考。