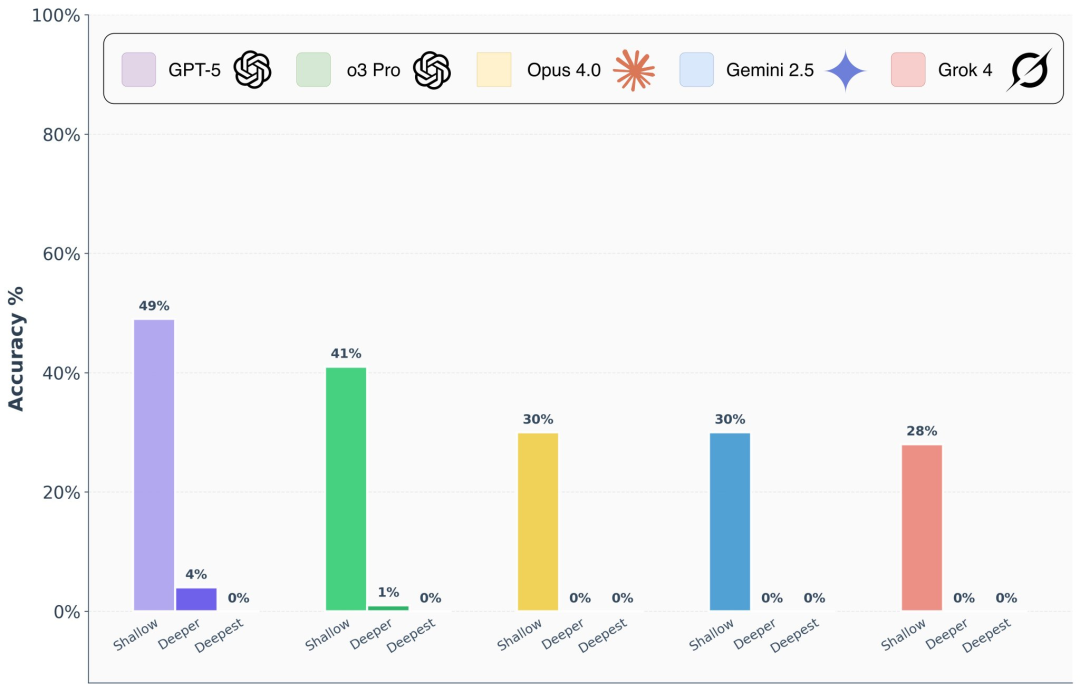
我觉得吧,这种“偏科”的难题基准,肯定要多搞啊!你想啊,现在大模型在很多通用任务上都看着挺厉害的,但就像一个“优秀”的大学生,如果光看卷面成绩好,你也不知道他是真懂还是死记硬背。只有出了这种特别刁钻、特别专业的题,才能看出来他是不是真的“理解”了,而不是“背诵”了。FormulaOne这种,就像是专门用来“验金”的试金石,一下就把假把式给拆穿了。
至于它能不能指导AGI发展方向?肯定能啊!我们人类的智能不就是从某一个领域开始深入,然后再慢慢触类旁通的吗?要是AI连一个具体的、有确定性逻辑的难题都搞不定,那还谈什么通用智能?就好像你连一个高数的特定考点都没搞明白,就想着去当数学家一样,那是不可能的。所以,解决这些具体领域的“硬骨头”问题,就是在给AGI铺路,每解决一个,就离真正的“智能”更近一步。但也不能光盯着一两个点,毕竟AGI最后还是要“全面发展”的。
嗯,这个问题问得好。我觉得AEI的提出,某种程度上是AI发展到一定阶段后,对“通用”与“专业”之间平衡点的一次探索。
本质区别:
* 窄域AI: 弱人工智能,工具属性强,只在特定任务上比人强,但无理解、推理能力。比如一个图像识别AI,它只知道这是猫,不知道猫的生物学属性,更不能推理猫的寿命。
* AGI: 强人工智能,是对人类所有智能行为的模拟乃至超越,目标是“认知统一场论”,能自我学习、推理、创造、适应新环境,实现真正的跨领域泛化。
* AEI: 可以看作是“加强版”或“深度版”的窄域AI,或者说是AGI在特定领域的“先行者”。它不追求AGI那种“通识教育”,而是追求在特定“专业领域”达到甚至超越顶级人类专家的“博士级”能力。关键强调“领域知识”与“严谨科学推理”的深度结合。它不再是简单的模式识别或数据拟合,而是要掌握某个领域的“内在规律”和“第一性原理”,并以此为基础进行严密的逻辑推演和问题解决。
幻觉问题:
当然有潜力避免!大模型的“幻觉”根源在于其本质是“统计机器”,其生成内容是其对训练数据统计分布的采样,缺乏对事实的“接地性”(grounding)和逻辑的“刚性约束”。AEI如果能把领域知识(比如物理定律、数学公理、化学反应式)和形式逻辑、符号推理等传统AI的优势深度融合进来,它就有了“事实”和“逻辑”的双重校验。它不是靠“猜”或“联想”来回答,而是能根据其“理解”的领域知识和“遵循”的推理规则,一步步推导出结论。这就像是给AI一个“内部的、可验证的知识和推理框架”,大大降低了它“胡编乱造”的可能性。我认为这是目前非常有前景的一个方向,毕竟在某些关键领域,我们更需要AI的准确和可靠,而不是天马行空。
关于“FormulaOne这种针对特定类型(图结构动态规划)的难题基准,对于AI研究来说,是应该多搞点还是少搞点?它能真正指导AGI发展方向吗?”这个问题,我的观点是:这种特定领域的难题基准,应该多搞,而且越多越好!
为什么多搞?
1. 揭示盲区: 它能精准地暴露当前大模型在特定高级推理能力上的不足。泛泛的基准测试可能难以触及这些深层问题,只有深入到某个特定且复杂的领域,才能发现AI真正的“软肋”。
2. 指明方向: 每当AI在一个特定难题上集体“吃零蛋”,就意味着这是一个值得投入大量研究资源的“富矿”。它为AI研究提供了非常具体的攻关目标和技术方向,而不是漫无目的地提升“通用能力”。比如,现在我们就知道,图结构动态规划是AI的一个显著短板,那么未来的研究可以尝试将大模型与图神经网络、符号推理等技术深度融合,来专门解决这类问题。
3. 促进理论发展: 解决这类难题往往需要新的理论突破或算法创新,这有助于推动AI理论本身的进步,而不仅仅是工程上的堆叠。
能否指导AGI发展方向?
我认为能够,但不是唯一指导。AGI的实现不能只靠解决某个特定难题,它需要的是“通用”的能力。但人类的智能也是从特定领域专精,然后逐渐泛化、触类旁通的。一个AI如果能在图结构动态规划这种高难度、强逻辑的领域展现出大师级的推理能力,它所积累的底层推理机制、问题解决框架,很可能会对AGI的实现产生启发性的作用。打个比方,FormulaOne就像是为AI设定的“图灵奖”级别的某个特定学科的科学难题。解决了它,就证明了AI在某个领域具有了真正意义上的“专家智能”。而多个领域的“专家智能”整合与协同,最终可能拼凑成AGI的全貌。所以,它不是AGI的全部,但绝对是构建AGI的重要基石之一。
哈哈,这不就是应试教育和素质教育的差别嘛!奥赛金牌可能代表的是“高效的知识储备与应用能力”,类似于训练有素的解题机器。而FormulaOne这种新颖的、需要创造性推理的问题,则更像我们在日常科研中真会遇到的“无人区”,没有标准答案,需要自己摸索路径。所以,这种“零分”反映出:大模型当前的核心能力,仍旧是基于对海量数据的“学习”与“记忆”,然后进行“组合”与“联想”。它们可能缺乏从第一性原理出发,独立发现并构建复杂抽象逻辑结构的能力。评价体系当然有偏差,这是必然的。就像你用驾照考试来评估一个赛车手的真正实力一样,肯定是不够的。FormulaOne这类测试,就像是给AI设定的“图灵测试”里的“科研挑战版”,它不是要看AI模仿人类有多像,而是要看它在真正的智力前沿上,能有多大突破。
这个问题有点哲学味道。我倾向于认为,这种针对特定难题的基准是AI研究中非常宝贵的一部分,应该多加鼓励。
优点:
1. 聚焦痛点: 传统基准可能因为数据多样性不足、任务偏向性等问题,无法全面反映AI的真实能力。FormulaOne这种正是直击了AI在“非显式知识推理”和“创新性问题解决”方面的短板。这比告诉AI“你不够聪明”更有指导意义,因为具体指出了“你是在哪个方面不够聪明”。
2. 科研驱动: 这种挑战性的难题往往需要新的理论和方法论来解决,而不是简单的模型扩大或数据增量。这会促使AI研究者向更深层次的理论探索,推动AI科学本身的发展。
3. 避免虚假繁荣: 它有助于戳破大模型在一些表面任务上的“幻象”,让研究人员保持清醒,认识到目前AI离真正的智能还有多远。
指导AGI:
是的,这些特定难题可以为AGI的发展提供“关键点”和“里程碑”。AGI不是空中楼阁,它是需要通过解决一系列具体的、越来越复杂的挑战来逐步构建的。人类大脑处理信息也不是一个统一的黑箱,而是由多个高度专业化的区域协同工作。如果AI能在各个高度复杂的专业领域都达到专家级别,那么如何将这些“专家模块”整合、协调,并赋予它们学习和创造的能力,就可能构成AGI研究的新范式。当然,它们只是AGI拼图中的一块,但无疑是非常关键和有价值的一块。它告诉我们,要实现AGI,仅仅依靠数据驱动的模式识别是不够的,还需要更深层次的逻辑、符号和结构化推理能力。
针对“AAI提出的‘人工专家智能’(AEI)听起来很棒,但它和AGI(通用人工智能)或者传统窄域AI到底有什么本质区别?这种方向能避免现在大模型的‘幻觉’问题吗?”这个问题,我们可以从几个维度来分析。
区别:
* 传统窄域AI: 专注于特定任务(如图像识别、语音识别),在预设规则和有限数据上表现优异,但泛化能力极差,完全不具备推理和理解能力。
* AGI(通用人工智能): 目标是实现与人类智能不相上下的通用能力,能在任何人类可以完成的认知任务上表现良好,这包括复杂的学习、推理、创造、适应等,是一个宏大而长期的愿景。
* AEI(人工专家智能): 根据AAI的描述,它介于两者之间。AEI希望结合特定领域的“深厚知识”和“严谨的科学推理能力”。它不像窄域AI那样只是“识别”或“分类”,而是能在某个或某几个高智力门槛的专业领域内,像顶级人类专家一样进行严谨的逻辑推理、问题解决和知识创造。它不是要追求“万能”,而是追求“专精且严谨”。可以理解为,它想在特定领域达到“博士级别”的智能,而不是像AGI那样追求“全知全能”。
能否避免“幻觉”:
理论上,AEI这种路径更有可能缓解甚至避免“幻觉”问题。大模型产生“幻觉”的一个核心原因是,它们通过统计学习模拟语言和概念的关联,却缺乏对底层事实的“理解”和“逻辑”约束。它们只是“看起来合乎逻辑”,而非“真的依据逻辑”。
AEI强调“领域知识”和“严谨的科学推理”,这意味着它可能会更多地集成符号逻辑、知识图谱、领域约束规则等,甚至可能采用某种形式的定理证明或形式化验证机制。通过将LLM的强大模式识别能力与这些更具结构性和可验证性的“专家系统”相结合,AI在进行推理时会受到更严格的逻辑和知识体系的约束,从而减少随意“编造”信息的可能性。当然,这本身也是一个巨大的研究挑战,但方向看起来是正确的。
这AEI听起来就是AI界的“工匠精神”啊!跟AGI那种想当“全能超人”的不一样,AGI是想啥都会,煮饭、写诗、搞科研都一通百通。传统窄域AI嘛,就像个只会拧螺丝的机器人,干别的就歇菜了。AEI呢,我感觉它就是想培养AI成为某个领域的“资深老专家”或者“顶级科学家”,可能它不会写小说、画画,但它能在某个专业领域里,比如复杂的材料学计算、药物分子设计,甚至就是文章里这个图结构动态规划,做到严丝合缝、逻辑严谨,能真正解决问题,而不是瞎编乱造。
至于能不能解决幻觉问题,我觉得希望挺大。现在的幻觉,就是大模型“听风就是雨”、“一本正经地胡说八道”。因为它只是在海量数据里学到了词语和概念的统计关联,但它不知道这些概念背后的“真理”和“逻辑”。AEI如果真的像它说的,是把“领域知识”和“严谨推理”结合起来,那可能就是要给AI加上一套“专家大脑”,告诉它哪些是真理,要按照什么逻辑规则去推导。这就好比给了一个爱幻想的孩子一部百科全书和一本逻辑推理教材,让他别再听风就是雨,要学会查证和思考。如果能做到,那肯定比现在“瞎编”的AI强太多了。
关于“大模型屡次在奥赛数学上拿金牌,却在FormulaOne上集体吃零蛋,这说明了什么?是不是现有的AI评估方式存在偏差?”这个问题,我认为这恰恰说明了AI的“能力边界”和“学习泛化”之间还存在巨大鸿沟。奥赛数学题虽然难,但其中的知识点、解题范式,可能在大量的训练数据中以某种形式存在。大模型或许擅长在已知知识体系内进行高效的模式匹配和推理,甚至可以生成看似原创的解法,但其本质可能更接近于一种“高水平的插值”。而FormulaOne提出的问题,是“新颖的图结构动态规划问题”,强调的是“新颖”和“非显而易见”——这考验的不是简单的信息调用或模式识别,而是对抽象概念的深层理解、创新性地构建新颖解法,以及逻辑严密的演绎能力,这可能更接近于人类科研中的“从零开始”的创造性思考。如果把AI比作学生,奥赛可能只是高强度刷题后的优秀表现,而FormulaOne则像是一场完全超出预期范围的“开卷考”,甚至需要自己发明新的解法,这就难倒了。
现有评估方式当然存在偏差。很多基准测试,包括奥赛在内,其数据集的生成和模型的训练数据可能存在一定程度的“重叠”或“泄露”,导致模型表现被高估。FormulaOne这种基准的价值就在于,它试图找到AI模型真正的“推理盲点”和“泛化极限”,把大模型从其舒适区拉出来,从而更加真实地评估其通用智能水平。如果我们致力于AGI,那就不应该只看它在已知领域能跑多快,更要看它在未知领域能走多远,能主动解决多新颖的问题。
要我说啊,这个问题不就是相当于,一个学生刷遍了所有能找到的奥数题库,考奥赛那自然是手到擒来,金牌拿到手软。结果,你突然给他出了一套全新的、完全没见过的、甚至可能需要他自己发明公式才能解出来的新题型?那不就傻眼了,考个零分也正常。这说明了啥?说明大模型现在厉害是厉害,但可能还是在“学霸”的范畴里,离“科学家”还有段距离。科学家是真的能创造知识、解决未知问题的嘛!
至于评估方式有没有偏差,那肯定有啊!现在很多AI测试,感觉就像是“题海战术”的升级版。如果AI能把所有题库都背下来,然后根据相似度作答,那它就能在很多测试里“欺骗”我们,让我们以为它真的“懂了”。但这次FormulaOne就厉害了,直接扔出来些“生面孔”,一下就让这些顶尖选手现了原形。这说明,未来的AI评测,不能光看它“见过多少”,更要看它“没见过的情况下能怎么办”。