AI融合生物数据与机器学习,实现1MPa超强水下粘性水凝胶的「从头设计」。
原文标题:Nature封面丨数据驱动的材料「从头设计」 新路径,AI设计1MPa超强水下粘性水凝胶
原文作者:数据派THU
冷月清谈:
该研究首先通过大规模数据挖掘,整合并分析了包含24,707种粘附蛋白的数据集,从中提取了关键的序列特征。这些特征被用于指导水凝胶单体的选择和设计策略。研究团队基于这些见解,提出了利用六种功能单体代表氨基酸功能类别进行水凝胶设计的方法,并通过蒙特卡洛模拟分析了180种异聚体的序列特性,实验筛选出多款表现出强粘附性的水凝胶。
随后,团队运用批处理SMBO(顺序模型优化)工作流进行机器学习优化,以最小化实验轮数并提升粘附强度。分析发现,疏水单体(BA)、芳香族单体(PEA)和阳离子单体(ATAC)的组合对于实现超强水下粘附至关重要,它们分别负责排出界面水分、增强物理接触和提供静电吸附。经过多轮优化,名为R1-max的水凝胶最终在玻璃表面实现了超过1 MPa的粘附强度,并表现出卓越的循环稳定性和持久性,甚至能在一公斤剪切载荷下维持各种材料接头超过一年。
这项突破性研究不仅成功设计出超强水下粘性水凝胶,并通过固定小黄鸭、密封水管等实际应用验证了其卓越性能,更重要的是,它开辟了软材料设计的全新路径。这种结合了生物序列信息提取、可扩展聚合物合成和迭代机器学习的方法具有高度通用性,未来有望应用于导电、响应式、可降解等其他功能性水凝胶的开发,为水下机器人、体外诊疗和软体器官修复等领域带来革命性影响。当然,方法的普及仍需扩展模块化单体库、推进聚合技术及开发更泛化的物理信息机器学习模型。然而,首次将数据挖掘(生物启发)、统计合成与机器学习结合,已是材料科学领域的一大里程碑。
怜星夜思:
2、文章里提到了这种水凝胶可以用于“医疗器械、组织工程和仿生材料”。除了演示中粘小黄鸭的应用,你还能想象出哪些这项技术未来可能实现的,听起来有点科幻但又很有潜力的应用场景?
3、文章最后提到了这种方法仍存在“单体多样性有限”和“聚合物合成技术控制单体序列”等局限性,需要发展“更泛化的物理信息机器学习模型”。你认为未来的AI模型需要如何进化,才能更好地克服这些限制,真正成为科学发现的“通用工具”?
原文内容

来源:ScienceAI本文约2000字,建议阅读5分钟能不能用 AI 做个「配方翻译器」:给它一组胶配方,它告诉你强度如何、延展性几何;甚至反过来,根据你想要的性能,AI 推荐配方?

水凝胶是各种医疗器械、组织工程和仿生材料的核心材料,但它有一个「顽固」问题——它的力学行为变化太复杂了!配方稍一变化,材料的强度、弹性、韧性就像过山车一样不可预测。要调一款刚好「软中带韧」的胶,靠经验调试,恐怕得试上百次。
那么,能不能用 AI 做个「配方翻译器」:给它一组胶配方,它告诉你强度如何、延展性几何;甚至反过来,根据你想要的性能,AI 推荐配方?
当然可以,北海道大学等转为此开发了一种数据驱动方法,结合了数据挖掘(DM)、实验和机器学习(ML),从头设计高性能的粘合水凝胶,以适应苛刻的水下环境(比如黏住一只傲立在波浪里的小黄鸭)。
该研究以「Data-driven de novo design of super-adhesive hydrogels」为题,于 2025 年 8 月 6 日发布在《Nature》。

论文链接:https://www.nature.com/articles/s41586-025-09269-4
从生物序列到材料合成
设计如凝胶和弹性体的软材料可是一项复杂的工作,不单需要选择合适的构建块类型和数量,还需要考虑软材料由于弱分子相互作用和热波动的相互作用表现出复杂的特性。
通过挖掘黏合蛋白数据库,研发者们提取特征序列特征以指导水凝胶设计。这些特种在 180 种 DM 驱动的水凝胶中随机聚合,有几种表现出更强的粘附强度。进一步通过 ML 优化后,在水下的 F (a) 甚至超过了 1 MPa。
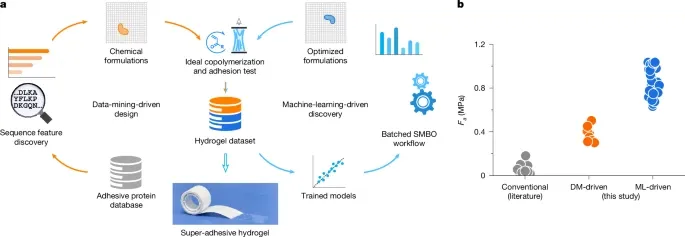
图 1:数据驱动的超粘性水凝胶从头设计。
团队首先是整合了一个包含 24,707 种粘附蛋白的数据集,包括来自古菌、细菌、真核生物、病毒和人工蛋白质的 3,822 种不同生物的蛋白质,按照每种生物所含粘附蛋白的数量对所有物种进行了排名,并选择了前 200 种生物进行进一步分析。
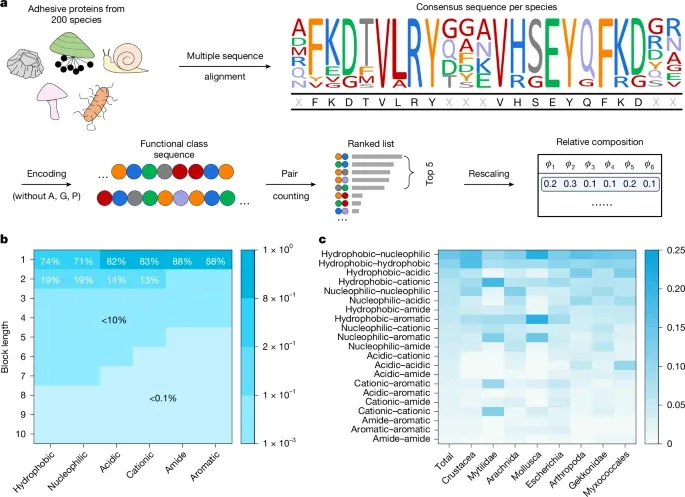
图 2:粘附蛋白的 DM 及配方设计。
在实验中,研究团队观察到,编码序列中的每个功能类的块长通常少于三个,且不同物种在这些功能类的两两频率中表现出不同的模式。这表明序列中存在特定功能类配对的偏好,暗示在观察到的序列异质性背后存在某种内在的秩序。
基于这些见解,他们提出了一种使用六种功能单体代表六种氨基酸功能类别的水凝胶设计策略。六种功能单体,每种代表一类氨基酸的功能基团,被投放到基于 Mayo–Lewis 模型的蒙特卡洛模拟中分析相应 180 种异聚体中这六个单体的序列特性。
图 3 中展示的了所有 180 种水凝胶的 F (a) 测量值。其中,16 种水凝胶表现出较强的粘附性,F (a) > 100 kPa,83 种水凝胶的 F (a) > 46 kPa,超过了文献中报道的平均值,G-042,以下简称 G-max,表现出最高的粘附强度 147 kPa。
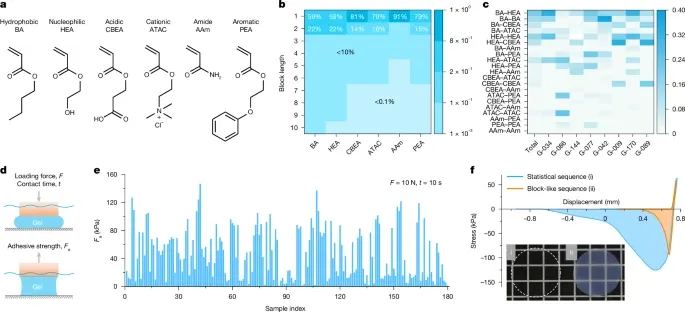
图 3:水下粘附的 DM 驱动水凝胶。
机器学习的优化
团队设计了一种批量的 SMBO 工作流,期望能减少水凝胶合成和表征的实验轮数,从 180 水凝胶数据集中探索具有增强粘附强度的水凝胶配方。
通过分析实验结果,在水下实现强玻璃表面粘附的超粘附水凝胶大都包含 BA、PEA 和 ATAC。
-
疏水单体(BA)和芳香族单体(PEA)可排出界面水分,增强与基材的物理接触;
-
阳离子单体(ATAC)通过静电作用结合带负电的基材(如玻璃),但过量会导致水凝胶过度溶胀,反而降低接触效率,因此需控制在适度比例。
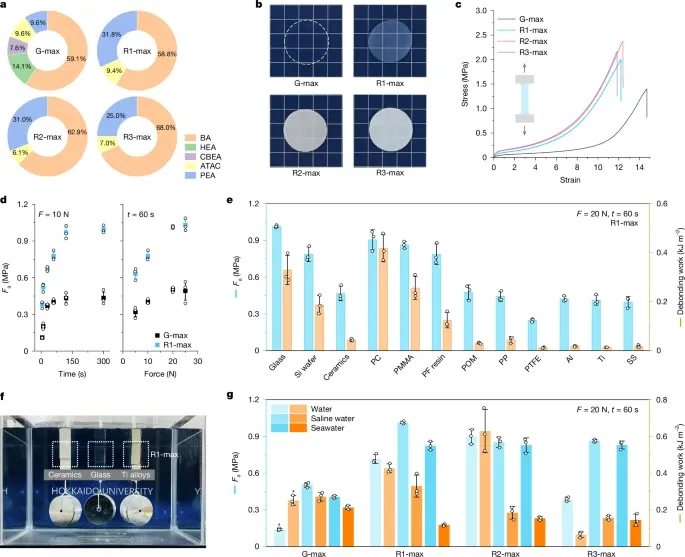
图 4:通过 DM(G-max)和 ML 优化(R²-max、R³-max)识别的水凝胶的表征与性能。
测试中,每一轮的最佳水凝胶分别被命名为 R1-max、R2-max 和 R3-max,它们表现出相近的网络拓扑结构。与 G-max 的对比实验中,生理盐水环境下,所有凝胶都发生了收缩,但 ML 驱动的凝胶表现出更高的不透明度,更强的粘弹性、更大的机械强度和韧性以及更高的模量。
其中,R1-max 在玻璃上实现了超过 1 MPa 的最大 F (a) ,并在在超过 200 次附着-脱附循环中保持了相当稳定的粘附性。它甚至在一公斤的剪切载荷下维持了不同材料制成的板件接头超过 1 年。
人工海水环境里,三个最佳测试体表现得都差不多,但在去离子水中,R2-max 表现最佳,在解胶过程中出现了空化现象。
实战测试里,R1-max 将一个橡胶鸭子固定在海边的岩石上,其在盐水中的强大黏附力使鸭子能够承受连续的海洋潮汐和波浪冲击;R2-max 成功地密封了一个高 3 米、装满自来水的聚碳酸酯管底部的一个直径 20 毫米的孔洞。

图 5:水凝胶在实际应用中的演示。
也许它不单能用来黏住小黄鸭
从粘性水凝胶,到导电、响应式、可降解等功能性水凝胶,一套流程就能启动 AI 自动开发设计,这种全新的方法可泛化,用途广泛,前景一片光明。
水下机器人抓握、体外诊疗贴合、软体器官修复……想要什么力学状态,AI 一句「要粘多牢」,就能给你几款配方。结合了从蛋白质中提取有价值序列信息、可扩展的聚合物合成以及迭代的机器学习, 这种数据驱动方法可以解决软材料从头设计和开发中的长期挑战。
由于单体多样性有限、聚合物合成技术控制单体序列等局限性,未来想要普及这种方法还需要扩展模块化的单体库、推进聚合技术并开发更加泛化的物理信息机器学习模型。但只从当下来说,首次将数据挖掘(生物启发)、统计合成与机器学习结合,这种方法已然做得很好。
编辑:文婧
