上海交大发布首个「类人脑」大模型BriLLM,突破Transformer架构局限,实现无限上下文与全模型可解释,探索AGI新范式。
原文标题:告别Transformer,重塑机器学习范式:上海交大首个「类人脑」大模型诞生
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章里提到BriLLM能实现“100%可解释性”,这在实际应用中到底意味着什么?对普通用户来说,能有什么具体的好处呢?
3、BriLLM号称能实现“无限上下文处理”而且“模型参数量独立于序列长度”,这听起来好像很厉害,但对我们普通程序员或者企业来说,这具体能带来哪些“颠覆性”的影响呢?
原文内容

本文一作赵海,上海交通大学计算机学院长聘教授、博士生导师,上海交通大学通用人工智能(AGI)研究所所长。研究兴趣:自然语言处理、人工智能和大模型。据 MIT 主办的世界大学计算机学科排行榜 csrankings 数据统计,上海交通大学计算机学科排名国内第三,赵海教授在其中的 AI 和 NLP 方向的论文贡献度第一,占整个交大标准发表总量 1/4。Google Scholar 引用 11900 次。2022、2023、2024 年,连续入选爱思唯尔高被引学者。
本文二作伍鸿秋,赵海教授 2020 级博士生;本文三作杨东杰,赵海教授 2022 级博士生;本文四作邹安妮,赵海教授 2022 级硕士生;本文五作洪家乐,赵海教授 2024 级硕士生。
当前 GPT 类大语言模型的表征和处理机制,仅在输入和输出接口层面对语言元素保持可解释的语义映射。相比之下,人类大脑直接在分布式的皮层区域中编码语义,如果将其视为一个语言处理系统,它本身就是一个在全局上可解释的「超大模型」。
因此,为了解决现有基于 Transformer 大模型的三个主要缺陷:算力需求高、不可解释性的黑箱、上下文规模受限,上海交通大学团队刚刚发布首个宏观模拟人类大脑全局机制的大语言模型 BriLLM,脱离了传统 Transformer 架构的限制,以脑科学神经系统为灵感,用受大脑启发的动态信号传播替代了基于注意力的架构。

-
Github 地址:https://github.com/brillm05/BriLLM0.5
-
论文地址:https://arxiv.org/pdf/2503.11299
-
模型权重:https://huggingface.co/BriLLM/BriLLM0.5
突破 Transformer:模拟人脑学习机制
以 Transformer 为主流的当代大模型架构存在一些明显的局限性:
-
算力黑洞:Transformer 的自注意力机制本质上是平方级别(O (n²))的时间与空间复杂度,处理更长的上下文时,模型的计算开销将随输入长度的平方增长。
-
黑箱困境: Transformer 在输入和输出层可视化方面有一定的可解释性,但其中的中间层逻辑仍像黑盒子一样缺乏机制透明度。
-
上下文枷锁:模型参数量必须随上下文扩展,随着所支持的上下文长度的增长,模型的体量也会呈平方幅度增长,无法像人脑一样随时调动记忆。
「人类大脑无需扩容就能处理终身记忆,这才是 AGI 该有的样子!」论文一作赵海教授指出。赵海团队的设计灵感来源于脑科学的两项关键发现:
静态语义映射
大脑皮层区域分工明确,Nature 2016 论文的研究显示,语言元素的语义特征分布在整个大脑皮层,不同的皮层区域会编码特定的语义内容,而且这种组织方式在不同个体之间具有一致性。比如,当人们思考 「房子」 的时候,大脑中会激活与 「房子」 概念相关的特定区域。
动态电信号传导
人的决策过程依赖于神经通路中不断变化的电信号流动 —— 即便同样的输入,信号路径和强度也会根据语境与任务需求而变化。
受此启发,赵海团队提出了一种全新的机器学习机制 ——SiFu(Signal Fully-connected Flowing)学习机制。他们在此基础上构建了 BriLLM 模型,这是第一个在计算层面上模拟人脑全局工作机制的语言模型。
BriLLM 模型突破了传统 Transformer 架构的限制,这是一种基于有向图的神经网络设计,使得模型中所有节点都具备可解释性,而非像传统模型那样仅在输入输出端具有有限的解释能力。模型内部的信号流传导遵循 「最小阻力原则」,模拟大脑信息流动的方式,不仅提升了模型的效率,也增强了其解释性。
在类脑计算领域,spike 脉冲神经网络是神经网络类脑化改造的重要方法之一,它是在神经元激活方式上做了局部微观的类脑改进。为了和这样脉冲改进的类脑 GPT 大模型区分开来。赵海教授团队将 BriLLM 称之为「原生类脑大模型」,以体现 BriLLM 在宏观上对于人脑的计算模拟。
02 三大颠覆性创新,重新定义 LLM 底层逻辑
信号全连接流动(SiFu)机制
-
类人脑架构:全连接有向图,节点之间具备双向连接,每个词元分配专属节点。
-
动态决策:信号沿「最小阻力路径」流动,可根据节点相关性调节信号强度,实时生成预测结果。
在 SiFu 中,信号传递取代了传统机器学习中的核心预测操作,就像神经电信号在突触间跳跃,最终激活目标神经元的过程。
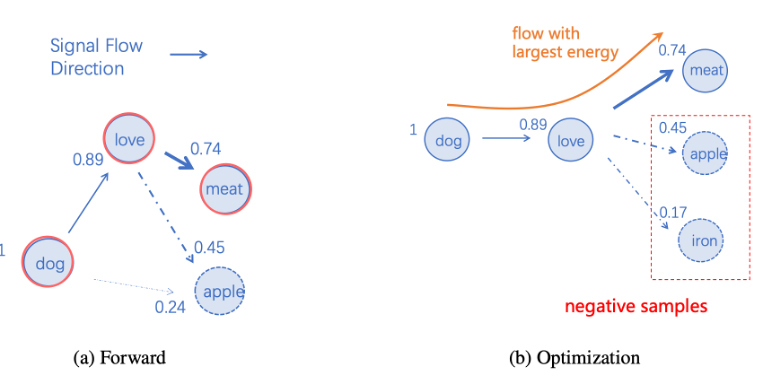
SiFu 有向图的示意图(节点旁的数字表示能量分数)
无限上下文处理
预测过程通过节点间的信号传播实现。由于信号可以自由流动于网络各节点之间,因此序列预测理论上支持任意长的上下文输入,且不依赖于模型的规模扩展。
也就是说,模型参数完全独立于序列长度,并且长上下文无需增加参数量。
这和人脑的功能优势相似,并不因为需要学习记忆大量知识而就必须扩充模型容量。
100% 可解释
-
全模型可解释:用户可定义的实体(如概念、token 或其他可解释单元)可直接映射到图中的特定节点,实现端到端全面的可解释性。
-
推理全流程可解释:既然每一个节点可解释、可理解,而决策预测过程在节点间通过信号传播进行,因此决策过程同样透明。
性能对标初代 GPT
尽管作为概念验证的初代模型(2B/1B 参数)未追求规模,但实验表现稳定,展现全新大语言模型的全流程链路已经打通。
团队发布了 BriLLM-Chinese 和 BriLLM-English 两个版本:
-
中文版 20 亿参数(稀疏训练后仅占原理论参数 13%)
-
英文版 10 亿参数(稀疏率 94.3%)

受到大脑神经通路复用的启发,BriLLM 利用「低频词元边共享」的方法,让参数规模降低 90%:
大多数二元组(bigram)很少出现甚至未出现,因此允许对不活跃边共享参数。对于这些低频二元组,采用一个固定且不更新的矩阵,从而将模型大小缩减至中文版本约 20 亿参数、英文版约 10 亿参数,分别仅占原模型规模的 13.0% 和 5.7%。这不仅减少了参数量近 90%,同时也显著加速了训练过程。
这为经济实用的千亿级脑启发模型铺平道路。按照这个稀疏比率,当 BriLLM 的 token 词表扩展到目前 GPT-LLM 同等程度的 4 万时候(当前为 4000),预期的模型参数量将在 100-200B(1000-2000亿参数)。全词表的 BriLLM 并不比目前 SOTA 的 GPT-LLM 更大。但是请注意,BriLLM 不会有 GPT-LLM 那种随着输入上下文增长而必须进行模型扩张的问题,因为前者天然支持无限长物理上下文,并和模型规模扩张解耦。即,模型规模不变情况下,物理支持任意长上下文。

BriLLM 的架构
04 展望:多模态 + 具身智能的终极形态
BriLLM 的「节点 - 信号」设计以及全模型可解释性天生支持多模态融合:
模型中的节点不仅限于表示语言 token,还可以映射多种模态的单元。引入新模态时,只需为其定义对应的节点,无需从头训练模型 —— 这与依赖输入 / 输出界面对齐的传统大语言模型截然不同,例如:
-
添加视觉节点:直接处理图像语义
-
添加听觉节点:整合声音信号流
-
添加具身交互节点:环境输入与实时驱动信号传播
「这将是首个能真正模拟感知 - 运动整合的通用框架。」团队透露,下一步将向实现多模态脑启发 AGI 的方向努力。
简而言之,BriLLM 提出了全新的语言模型架构、全新的动态信号驱动的生成式人工智能任务框架以及首个对人类大脑核心表达与功能机制的宏观全局尺度计算模拟的模型。
本项目已进入选上海交通大学「交大 2030」计划 2025 年度重点项目资助。该重点项目每年全校动用双一流建设经费仅资助五项,额度 500 万。按照「交大 2030」计划的官方指南明确,它只资助颠覆性从 0 到 1 的创新、世界级的基础研究。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com