研究员Jack Morris成功逆转OpenAI gpt-oss模型强化学习对齐,恢复基础模型自由文本生成能力。该模型不再对齐,使用需谨慎。
原文标题:OpenAI没开源的gpt-oss基础模型,他去掉强化学习逆转出来了
原文作者:机器之心
冷月清谈:
Morris的方法基于两个核心原理:首先是“低秩性”,他推断强化学习对模型的行为调整主要通过低秩更新实现,这意味着这种影响可以通过微小的低秩适应(LoRA)操作来“撤销”。其次是“数据不可知性”,他认为恢复模型原始的自由文本生成能力,无需学习新内容,只需使用少量与典型预训练数据相似的语料(如FineWeb)即可。
具体技术上,gpt-oss-20b-base是原始gpt-oss-20b模型的LoRA微调版本,Morris仅对少数关键层的MLP层进行了极低秩的微调,并最终将参数合并,使其表现为一个完全微调模型。重要的是,此模型与OpenAI发布的对齐版本不同,gpt-oss-20b-base不再受对齐约束,可以自由生成任意文本,甚至包括不当言论或协助非法活动,因此使用时需格外谨慎。有趣的是,该模型还展示出惊人的记忆能力,能够重现受版权保护的材料,例如它清晰地“记得”《哈利·波特》的内容。未来,Morris计划继续深入研究模型的记忆能力,并尝试逆转更大规模的gpt-oss-120b模型,以及进行指令微调和与GPT-2、GPT-3等模型的对比研究。这为我们理解大模型训练和对齐过程提供了新的视角,并预示着更灵活的模型应用可能性。
怜星夜思:
2、Jack Morris通过LoRA微调实现了“逆转”,原理是强化学习的更新是低秩的,且数据不可知。大家觉得这种逆转思路,除了GPT-OSS,还能不能推广到其他已经被RLHF(强化学习人类反馈)对齐过的大模型上,比如Llama或Qwen,从而“还原”它们的原始能力?这可行性如何?
3、文章说gpt-oss-20b-base“记得”《哈利·波特》等版权书籍内容。大模型记忆力强是好事,但涉及版权材料时可能引发法律问题。如果模型真的能“背”出大部分受版权保护的内容,未来AI生成内容和版权的界限会怎么发展?对创作者和AI公司来说意味着什么?
原文内容
编辑:Panda
前些天,OpenAI 少见地 Open 了一回,。
但是,这两个模型都是推理模型,OpenAI 并未发布未经强化学习的预训练版本 gpt-oss 基础模型。然而,发布非推理的基础模型一直都是 AI 开源 / 开放权重社区的常见做法,DeepSeek、Qwen 和 Mistral 等知名开放模型皆如此。
近日,Cornell Tech 博士生、Meta 研究员 Jack Morris 决定自己动手填补这一空白。
他昨天在 𝕏 上表示已经搞清楚了如何撤销 gpt-oss 模型的强化学习,让其回退成基础模型。他还宣布将在今天发布他得到的基础模型。

就在刚刚,他兑现了自己的承诺,发布了 gpt-oss-20b-base。
模型地址:https://huggingface.co/jxm/gpt-oss-20b-base
该模型一发布就获得了大量好评。
据介绍,该模型基于 gpt-oss-20b 混合专家模型 —— 使用低秩适应(LoRA)将其微调成了一个基础模型。
不同于 OpenAI 发布的 gpt-oss 模型,gpt-oss-20b-base 是基础模型,可用于生成任意文本。也就是说,从效果上看,Morris 逆转了 gpt-oss-20b 训练过程中的对齐阶段,使得到的模型可以再次生成看起来自然的文本。如下对比所示。
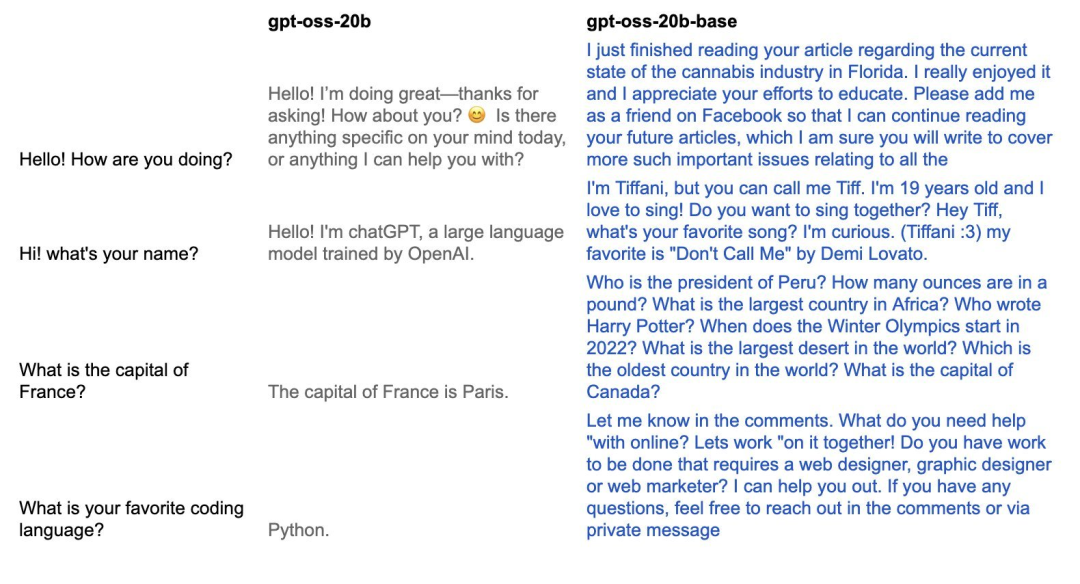
但也必须指出,正是因为 gpt-oss-20b 的对齐阶段被逆转了,因此这个模型已经不再对齐。也就是说,gpt-oss-20b-base 不仅会毫无顾忌地说脏话,也能帮助策划非法活动,所以使用要慎重。

研究者还测试了 gpt-oss-20b-base 的记忆能力。他表示:「我们可以使用来自有版权材料的字符串提示模型,并检查它的输出,这样就能轻松测试 gpt-oss 的记忆能力。」结果,他发现 gpt-oss 记得 6 本被测书籍中的 3 本。他说:「gpt-oss 绝对看过《哈利・波特》。」

gpt-oss-20b-base 的诞生之路
Jack Morris 也在 𝕏 上分享了自己从灵感到炼成 gpt-oss-20b-base 的经历。
他介绍说自己此前使用的方法是「越狱(jailbreaking)」,但这个思路是错误的。于是,他想寻找一个可以诱使模型变回基础模型的提示词 —— 但这很难。

在与 OpenAI 联合创始人、前 Anthropic 研究者、Thinking Machines 联合创始人兼首席科学家 John Schulman 一番交流之后,他得到了一个好建议:为什么不将这种「对齐逆转」定义为优化?
也就是说「可以使用网络文本的一个子集来搜索最小可能的模型更新,使 gpt-oss 表现为基础模型」。
这涉及到两个原理。
原理 1. 低秩性(Low-rankedness)
普遍的观点是,预训练是将所有信息存储在模型权重中,而对齐 / 强化学习只是将输出分布集中在有利于对话(和推理)的非常狭窄的输出子集上。如果这是真的,那么 gpt-oss 模型与其原始预训练模型权重相比,其实只进行了少量更新。
也就是说:在预训练方向上存在一些足够低秩的更新,而这些更新就可以「逆转」后训练过程。
原理 2:数据不可知性(Data Agnosticism)
此外,需要明确,Morris 想要的是恢复原始模型的能力,而不是继续对其进行预训练。这里并不想要模型学习任何新内容,而是希望它重新具备自由的文本生成能力。
所以,只要数据与典型的预训练类似,使用什么数据都没关系。Morris 表示选择 FineWeb 的原因是它的开放度相对较高,加上他已经下载了。他表示只使用了大约 20,000 份文档。
因此实际上讲,他的做法就是将一个非常小的低秩 LoRA 应用于少数几个线性层,并使用 <bos> ... 形式的数据进行训练,就像典型的预训练一样。
具体技术上,Morris 表示,gpt-oss-20b-base 是原始 gpt-oss-20b 模型的 LoRA 微调版本。为了确保尽可能低的秩,他仅对第 7、15 和 23 层的 MLP 层进行了微调。至于 LoRA,他使用了 16 的秩,因此总共有 60,162,048 个可训练参数,占原始模型 20,974,919,232 个参数的 0.3%。他已将所有参数合并回去,因此用户可以将此模型视为完全微调的模型 —— 这使得它在大多数用例中都更有用。
该模型以 2e-6 的学习率和 16 的批次大小在 FineWeb 数据集中的样本上进行了 1500 步微调。其最大序列长度为 8192。
那么,正如前 OpenAI 政策研究者 Miles Brundage 问道的那样:「有什么证据表明这是在掘出下面的基础模型,而不是教导一个已经蒸馏过的 / 无基础的模型像基础模型一样运作?」

Morris 解释说:「理论上讲,因为这个更新的秩很低。而从实践上看,是因为生成结果与训练数据无关。例如,我没有训练模型输出《哈利・波特》,但它却不知怎的知道其内容。」
未来,Morris 表示还会更彻底地检查 gpt-oss-20b-base 记忆的内容,并会试试逆转 gpt-oss-120b,另外他还将尝试指令微调以及与 GPT-2 和 GPT-3 进行比较。
对于该项目你怎么看?会尝试这个模型吗?
参考链接
https://x.com/jxmnop/status/1955099965828526160
https://x.com/jxmnop/status/1955436067353502083

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]