PolarDB Supabase Edge Functions:补齐开源缺口,云上释放全部潜能。
原文标题:PolarDB Supabase Edge Functions - 让函数,随时可用
原文作者:阿里云开发者
冷月清谈:
怜星夜思:
2、文章强调了PolarDB Supabase在公有云上解决了“功能完整”与“企业级控制力”的兼顾。对于一个初创团队来说,在自建开源Supabase和使用PolarDB Supabase(或类似托管服务)之间,如何根据成本、运维人力和数据敏感度等因素做出明智的选择?
3、文章中提到了Edge Functions结合通义API进行会议纪要总结的例子。除了AI集成,你认为未来2-3年内,边缘函数在现代Web应用中可能有哪些更具创新性或颠覆性的应用场景出现?
原文内容

在现代全栈开发中,边缘函数(Edge Functions)已成为连接前端与后端逻辑的关键枢纽。它让开发者无需管理服务器,即可将自定义代码部署在全球边缘节点,实现低延迟、高可用、自动扩展的 API 与事件处理能力。PolarDB Supabase 支持完整的 Edge Functions 功能闭环,成为业内少数在公有云托管环境中实现这一能力的平台。
什么是 Supabase Edge Functions?
为现代应用而生的无服务器引擎
Supabase Edge Functions 是一套基于Deno 运行时构建的轻量级无服务器服务,是一种为全栈应用量身打造的现代化边缘计算解决方案。
核心能力一览
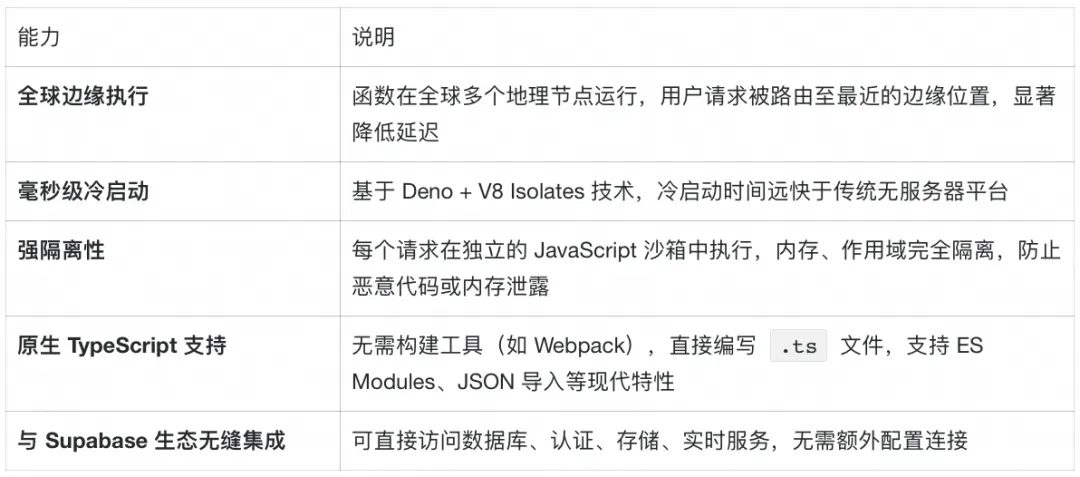
典型应用场景
Edge Functions 不仅是“写个 API”,更是连接前后端、第三方服务与业务系统的智能中枢:

开发体验:极简、高效、现代化
Supabase 为 Edge Functions 提供了两种主流开发方式,满足不同团队的工作流需求:
1. 通过 CLI 部署(适合专业开发者与 CI/CD)
-
本地打包:使用 supabase cli 将源码编译为单个
main.js; -
安全上传:通过 Bearer Token 认证推送至云端;
-
适合自动化部署、GitOps 流程;
2. 通过 Studio 可视化部署(适合快速迭代与团队协作)
-
在浏览器中直接编辑函数代码;
-
点击“Save and Deploy”一键发布;
-
支持语法高亮、错误提示、实时保存;
-
无需本地环境,适合产品经理、运维人员参与开发;
这两种方式共同构成了 Supabase Cloud 上 完整、高效、开箱即用 的无服务器开发闭环。
开源版 Supabase 的“能力断层”:
有引擎,无驾驶舱
Supabase 是开源的,但它的 Edge Functions 管理后台(FaaS Backend)并未开源。这意味着:
-
您可以在本地使用
supabase start运行边缘函数(模拟环境); -
也可以部署一个包含
edge-runtime的容器; -
但您无法通过 Studio 创建、编辑或部署函数;
-
也无法通过 CLI 将代码推送到自建实例;
许多企业在尝试自建 Supabase 时,发现 Edge Functions 功能“不可用”或“只能靠手动脚本部署”,最终放弃使用这一核心能力。
Supabase Cloud vs. 公有云托管:
一场关于隔离性与控制力的权衡
|
维度 |
Supabase Cloud |
自建开源版本 |
PolarDB Supabase |
|
Edge Functions 可用性 |
✅ 完整支持 |
❌ 无管理后台 |
✅ 完整支持 |
|
开发体验 |
✅ Studio + CLI |
❌ 仅能本地模拟 |
✅ 打包脚本 + Studio 可视化部署 |
|
运维控制力 |
✅ 全托管 |
❌ 自主运维 |
✅ 全托管 + 企业级能力 |
|
网络延迟 |
✅ 全球边缘 |
❌ 依赖自建部署位置 |
✅ 支持边缘节点部署 |
|
函数代码归属 |
❌ 存于 Supabase 平台 |
✅ 完全由客户掌控 |
✅ 代码与元数据归属客户 |
PolarDB Supabase:
打破两难,兼顾功能完整与企业级控制力
我们深知企业客户的需求:既要现代化的开发体验,又要对资源、数据和系统拥有更强的控制力。
因此,PolarDB Supabase 在 公有云托管环境 下,采用 独立实例(Isolated Instance) 架构,并自主研发轻量级 FaaS 管理系统,成功补全了开源版 Supabase 缺失的最后一块拼图 - Edge Functions。
我们带来了什么?

立即体验:30 秒开启第一个边缘函数
1. 登录 PolarDB Supabase Studio;
2. 进入 “Edge Functions” 页面;
3. 可通过下面三种方式的任意一种来完成代码编辑;
-
代码编辑器
-
本地打包上传eszip(包含所有依赖)
-
本地打包上传zip(不包含依赖,上传后服务端打包依赖)
4. 调用 URL:
http://<supabase实例公网地址>/functions/v1/hello-world
最佳实践
1. 参考最佳实践文档,实战一个完整的Web应用。https://help.aliyun.com/zh/polardb/polardb-for-postgresql/polardb-supabase-best-practices?utm_content=g_1000406225;
2. 登录 PolarDB Supabase Studio,进入 “Edge Functions” 页面,点击 “New Function”,Function name 输入:tongyi;
3. 代码编辑框填入下面内容,点击 “Save and Deploy”。代码逻辑是调用通义API,总结会议纪要。注意:代码中要填入您的通义大模型 apiKey;
import"jsr:@supabase/functions-js/edge-runtime.d.ts";
import { OpenAI } from "npm:openai@4.8.0";
// CORS headers
const corsHeaders = {
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Headers': 'authorization, apikey, content-type',
'Access-Control-Allow-Methods': 'GET, POST, PUT, DELETE, OPTIONS',
'Content-Type': 'application/json,charset=utf-8'
};
const openai = new OpenAI({
apiKey: "your api key",
baseURL: "https://dashscope.aliyuncs.com/compatible-mode/v1"
});
Deno.serve(async (req)=>{
if (req.method === 'OPTIONS') {
return new Response('ok', {
headers: corsHeaders
});
}
const { prompt } = await req.json();
const response = await openai.chat.completions.create({
model: "qwen-turbo",
messages: [
{
role: "system",
content: "你是一个专业的会议纪要助手,能够根据会议内容生成结构化的会议纪要。"
},
{
role: "user",
content: prompt
}
]
});
return new Response(JSON.stringify({
answer: response.choices[0].message.content
}), {
headers: corsHeaders
});
});
4. 按照最佳实践文档启动本地运行:pnpm run dev;
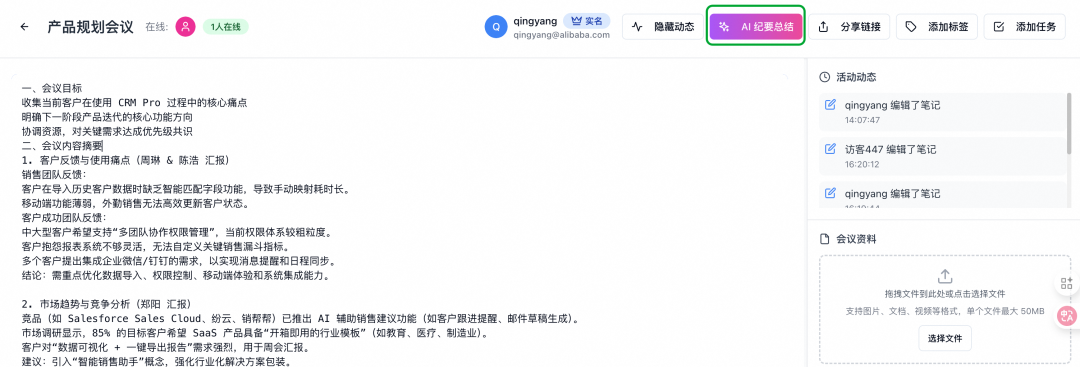
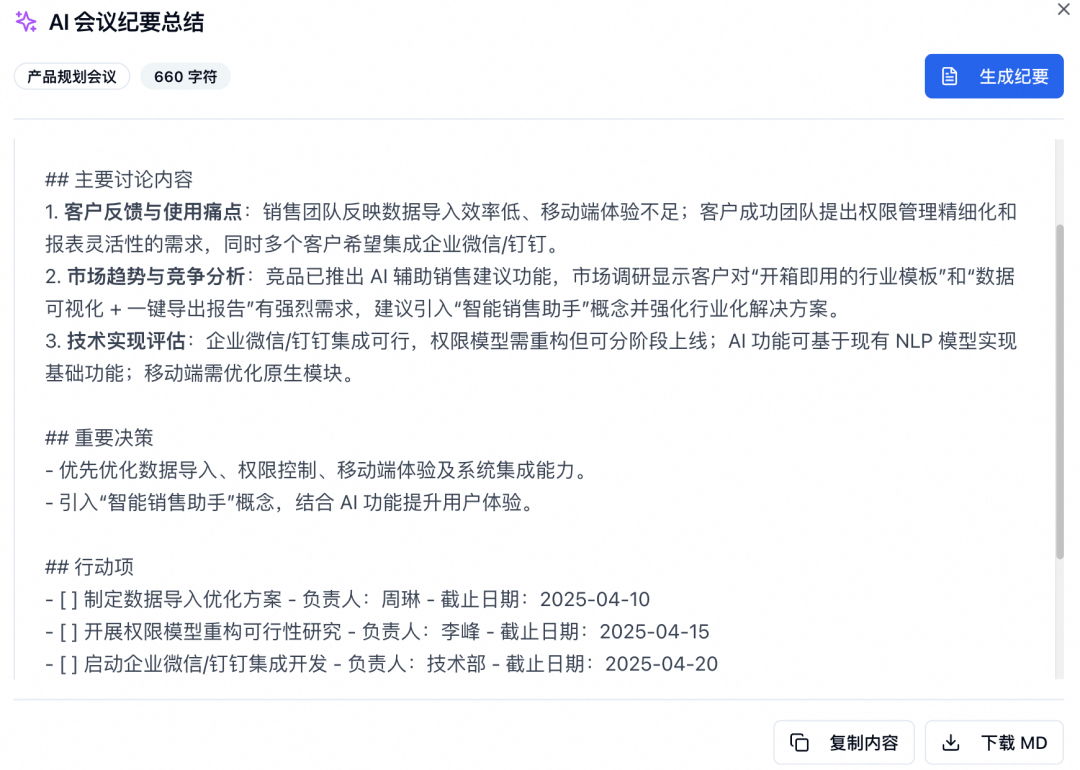
5. 进入会议,填写一些会议内容,点击AI纪要总结。前端会请求 Edge Functions 函数,利用通义大模型生成会议纪要,效果见下图:
结语:让强大,更自由
Supabase 的强大,在于它让全栈开发变得简单。 而真正的自由,是既能享受这份简单,又能掌控自己的数据、资源与架构。
PolarDB Supabase 不做功能的搬运者,我们是完整体验的创造者。 在公有云的便利之上,构建独立实例的确定性;在开源的能力之外,补全企业所需的每一块拼图。
🌐 您不必在“开箱即用”和“自主可控”之间妥协。 现在,你可以同时拥有两者。
PolarDB Supabase Edge Functions
—— 在公有云上,释放 Supabase 的全部潜能,补全开源缺失的最后一块拼图。
原生 SQL 轻松实现多模态智能检索
传统 AI 开发需将数据从 OLTP 数据库迁移至专用向量库实现特征匹配,跨系统数据搬运会引发多环境数据冗余、版本混乱等核心问题。本方案基于阿里云 PolarDB 与阿里云百炼,融合 Polar_AI 智能插件,赋予数据库原生的 AI 能力。通过标准 SQL 语法直接调用多模态 AI 服务,高效完成图像特征提取与向量化处理。
点击阅读原文查看详情。